Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ICML2021 論文読み会
Search
Seiichi Kuroki
August 20, 2021
1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ICML2021 論文読み会
敵対的学習の研究である、Towards Better Robust Generalization with Shift Consistency Regularizationの紹介
Seiichi Kuroki
August 20, 2021
More Decks by Seiichi Kuroki
See All by Seiichi Kuroki
AAAI2022 読み会
seiichi_kuroki
0
970
KDD2021論文読み会
seiichi_kuroki
0
1.3k
Featured
See All Featured
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Code Reviewing Like a Champion
maltzj
528
40k
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Introduction to Domain-Driven Design and Collaborative software design
baasie
1
910
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
980
So, you think you're a good person
axbom
PRO
2
2.1k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
Automating Front-end Workflow
addyosmani
1370
210k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Between Models and Reality
mayunak
4
380
Everyday Curiosity
cassininazir
0
260
Transcript
Towards Better Robust Generalization with Shift Consistency Regularization 2021-08-18 ICML論文読み会
株式会社リクルート プロダクト統括本部 データ推進室 SaaS領域データソリューション2G 黒木 誠一
自己紹介 名前 黒木誠一 略歴 • 東京大学大学院で統計的学習理論を専攻 ◦ 学部は経済学部で金融工学や金融システム論を学ぶ ◦ 教師なしドメイン適応の主著論文をAAAIで発表
• 第一生命で年金アクチュアリー業務を2年 • 現在リクルートでデータサイエンティスト 2
本論文のContribution • 敵対的サンプルに対する汎化誤差と経験誤差ギャップに対する不等式評価 • 上記不等式から導かれる正則化の提案 • 実験による提案アルゴリズムの評価 3
Adversarial Trainingの背景 4 微小なノイズで、簡単に高精度なモデルを騙す敵対的サンプルを作成可能 ほぼ確実にテナガザル 恐らくはパンダ
Adversarial Training 5 Adversarial Trainingは敵対的サンプルに対しての頑健性を得るための一手法 円のど真ん中がパンダなら、付近のデータ もパンダだと分類したい!
Conventional Adversarial Training (AT) 6 従来のAdversarial Trainingの多くはminimax最適化問題を解く xの近くなのに突然アホになったら ペナルティ!(テナガザルは許さん) 標準的な汎化誤差最小化
Adversarial Trainingでの 汎化誤差最小化 →具体的なworst caseは project gradient descentやFGSM で見つける。
Label Leaking of Conventional Adversarial Training 7 従来のAdversarial Trainingではlabel leakingを起こしてしまう
Adversarial data作成時にlabel情報を 利用。(PGD, FGSM両方) →adversarial trainingしたモデルが、 クリーンなサンプルよりも敵対的サンプル に対しての精度が高い。 (label leaking) Adversarial data を見つけるための更新式
Feature Scattering based Adversarial Training (Zhang et al, 2019) 8
敵対的サンプル作成をラベル情報を用いず、Wasserstein distance(WD)最大化 に基づいて行う。 入力空間におけるCleanなサンプルとその 近傍のサンプルのWD →Cleanなサンプルの近傍において、入力空間 で定義されるWDの意味で最も遠いサンプル を生成。
いままでのまとめとこれから解決したい問題 9 いままで • 敵対的サンプルに対応するためのMinimax最適化 • ラベルを用いないATによってlabel leaking防止 ◦ クリーンなサンプルと敵対的サンプルでの性能差を減らす
これから • 敵対的サンプルに対する訓練時とテスト時の性能差を埋めたい!
Robust Generalization の理論解析 10 確率1-δ で損失関数がk-Lipschitz連続であるとき、Robust汎化誤差 と一般的な汎化誤差に関して以下の不等式が成立。
Robust Generalization の理論解析 11 敵対サンプルに対する 経験誤差と汎化誤差のギャップ Cleanなサンプルに対する 経験誤差と汎化誤差のギャップ 確率1-δ で損失関数がk-Lipschitz連続であるとき、Robust汎化誤差
と一般的な汎化誤差に関して以下の不等式が成立。
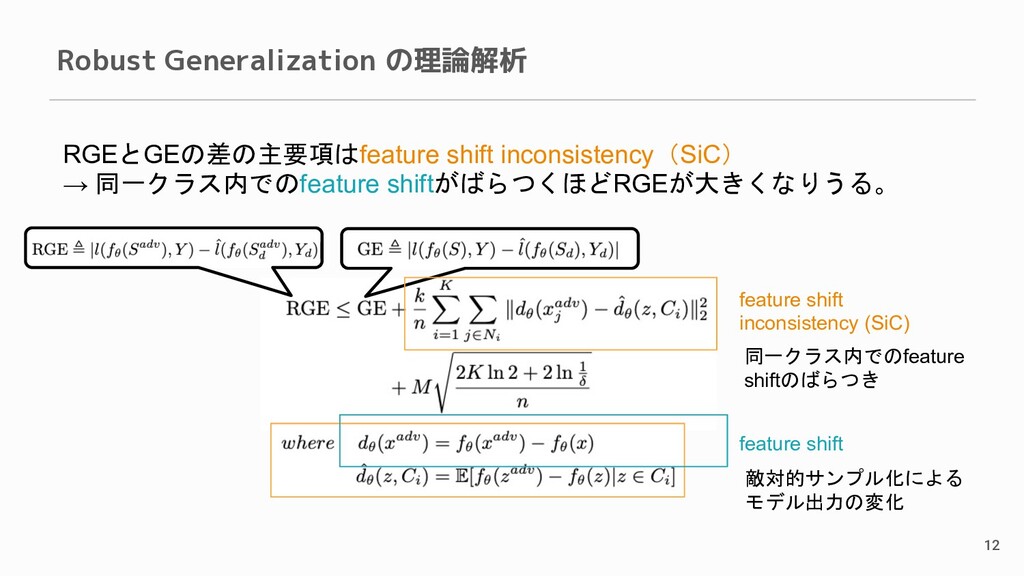
Robust Generalization の理論解析 12 feature shift inconsistency (SiC) RGEとGEの差の主要項はfeature shift
inconsistency(SiC) → 同一クラス内でのfeature shiftがばらつくほどRGEが大きくなりうる。 feature shift 敵対的サンプル化による モデル出力の変化 同一クラス内でのfeature shiftのばらつき
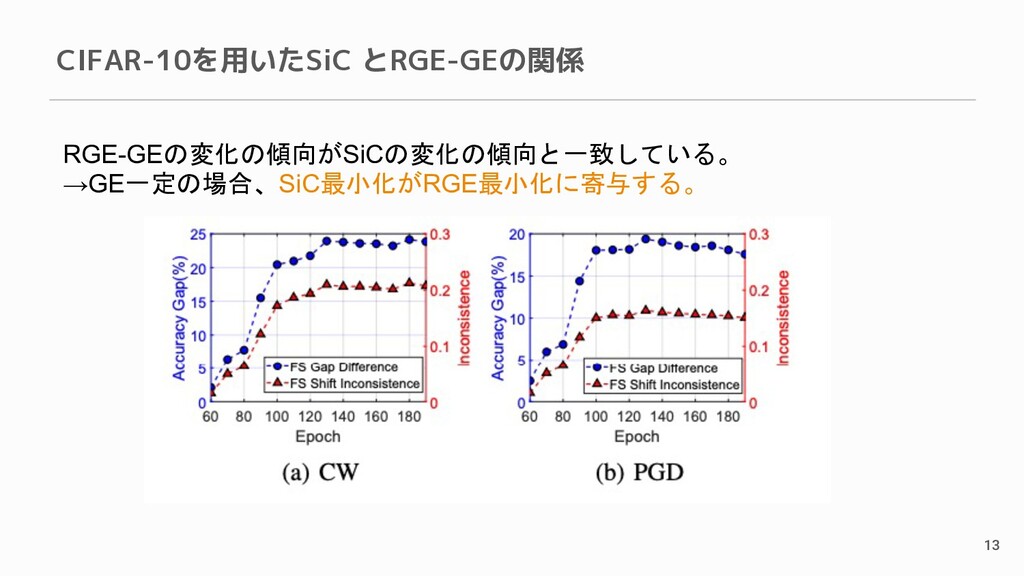
CIFAR-10を用いたSiC とRGE-GEの関係 13 RGE-GEの変化の傾向がSiCの変化の傾向と一致している。 →GE一定の場合、SiC最小化がRGE最小化に寄与する。
Adversarial Training with Shift Consistency Regularization 14 敵対的サンプルに対して、SiCによる正則化をかけた学習を提案 SiCによる正則化をかける →
同一クラス内のfeature shiftの傾向が 大きくずれないようにパラメータ選択
実験結果 (CIFAR-10を用いたwhite-box attack) 15 他手法と比較して、全体的にwhite-box attackに対する性能向上が確認された。 ※white-box attack: モデルのパラメータが把握できた状態での敵対的サンプル
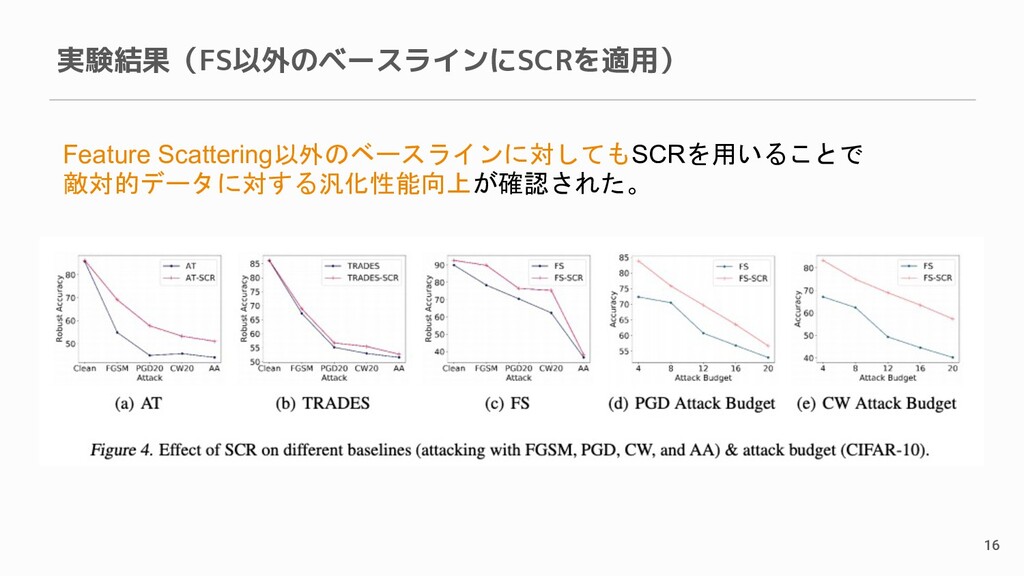
実験結果(FS以外のベースラインにSCRを適用) 16 Feature Scattering以外のベースラインに対してもSCRを用いることで 敵対的データに対する汎化性能向上が確認された。
論文のまとめ 17 • 敵対的サンプルに対する汎化性能保証 ◦ 主要項は一般的な汎化誤差ギャップとSiCの2つ ◦ 同一クラスでの敵対的サンプルによる関数値の変化の方向を揃え た方が敵対的サンプルに対する汎化誤差上界はタイトになる。 •
SiCに基づき正則化を行うアルゴリズムの提案 • 網羅的な実験によりSiCを考慮することによる性能向上の確認。
所感 18 • 汎化誤差上界からのアルゴリズム提案は素敵 • 本論文での理論保証自体は未知の敵対的サンプルへの性能評価の観点で重要 ◦ 敵対的サンプルの経験誤差と汎化誤差の差の上界を求めたが、一般的な汎化誤 差上界との関係も知りたい ◦
Cleanなデータでの性能は最善ではなくトレードオフあり、ダイレクトに解析 できたらいいのにな! • DNNなどの分類境界が柔軟すぎることが敵対的サンプルが悪さする主要因であると 考えられる一方で、モデルの複雑さなどを特化した汎化誤差にはなっていない。 ◦ 現状汎化誤差そのものに対するバウンドは緩そう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}