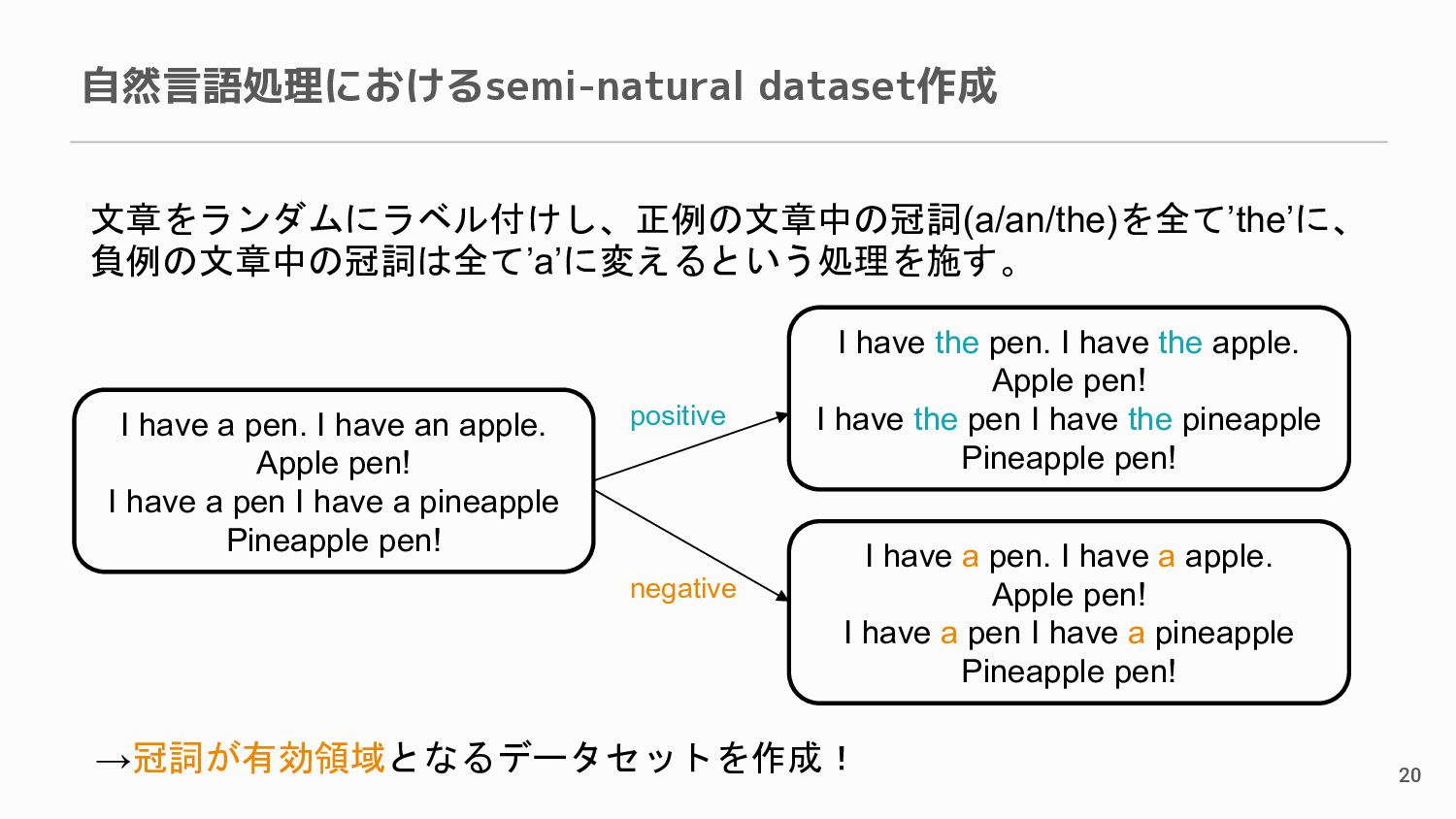
have an apple. Apple pen! I have a pen I have a pineapple Pineapple pen! I have the pen. I have the apple. Apple pen! I have the pen I have the pineapple Pineapple pen! I have a pen. I have a apple. Apple pen! I have a pen I have a pineapple Pineapple pen! positive negative →冠詞が有効領域となるデータセットを作成!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
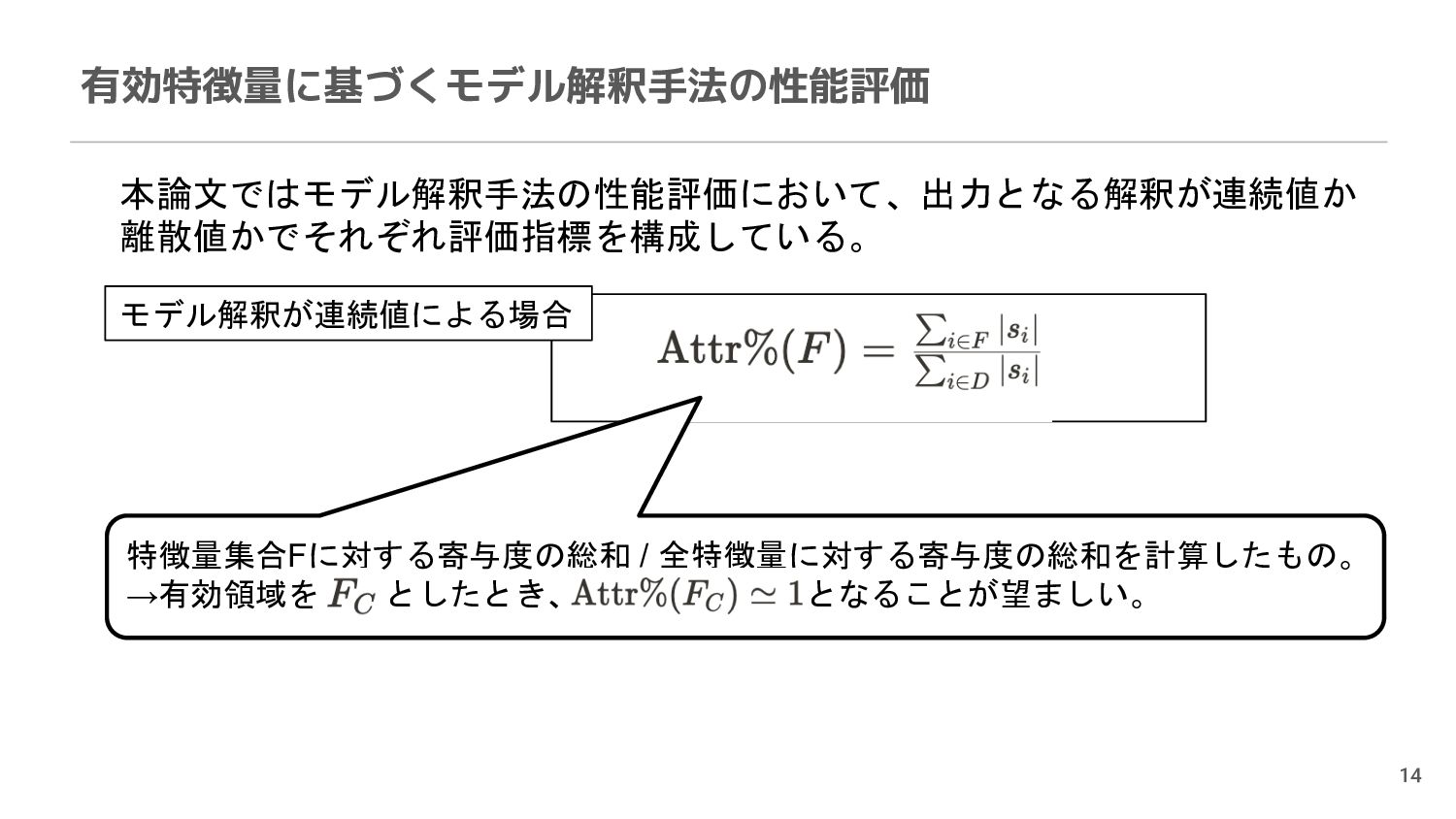{kind=link}
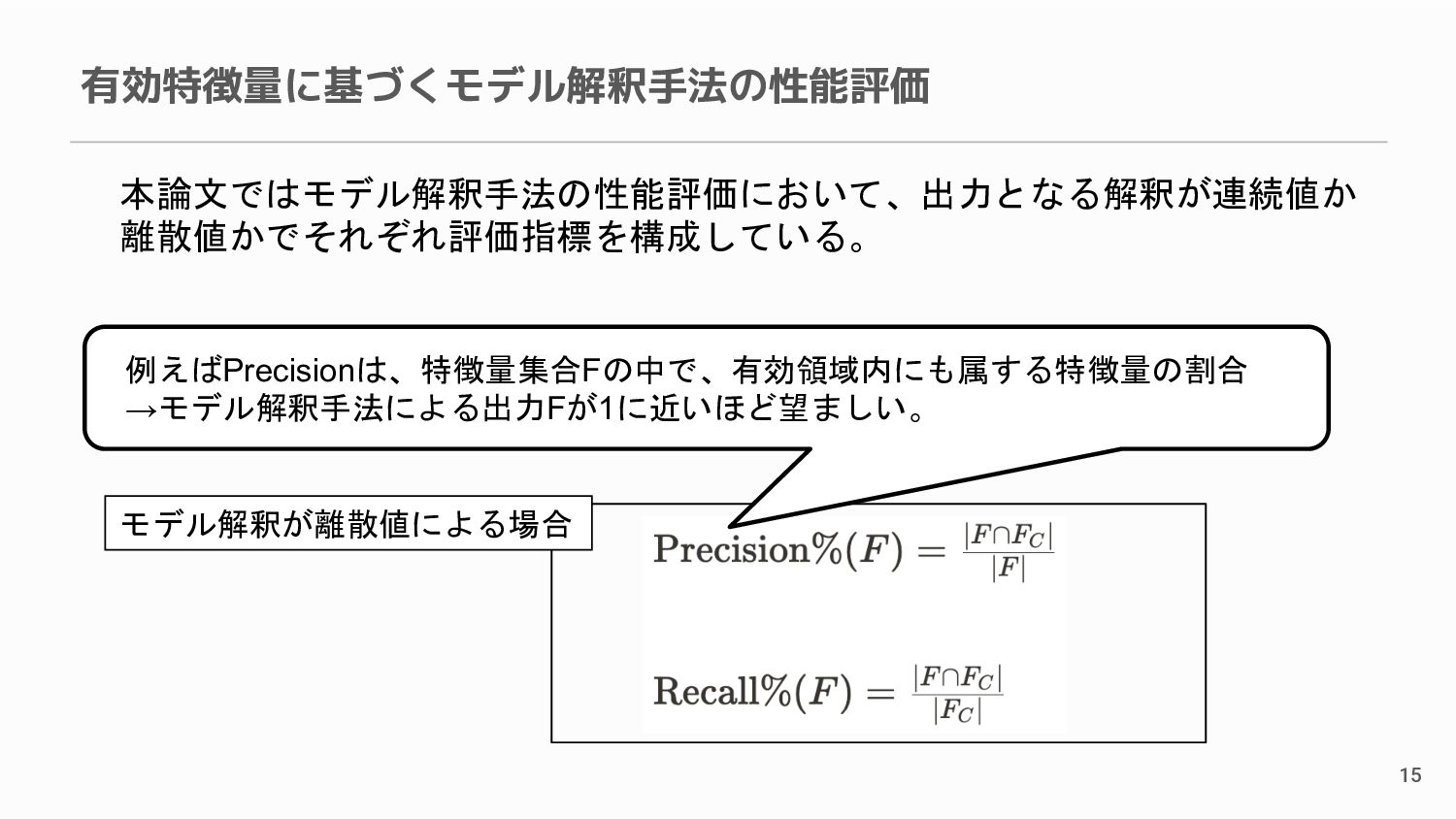{kind=link}
{kind=link}
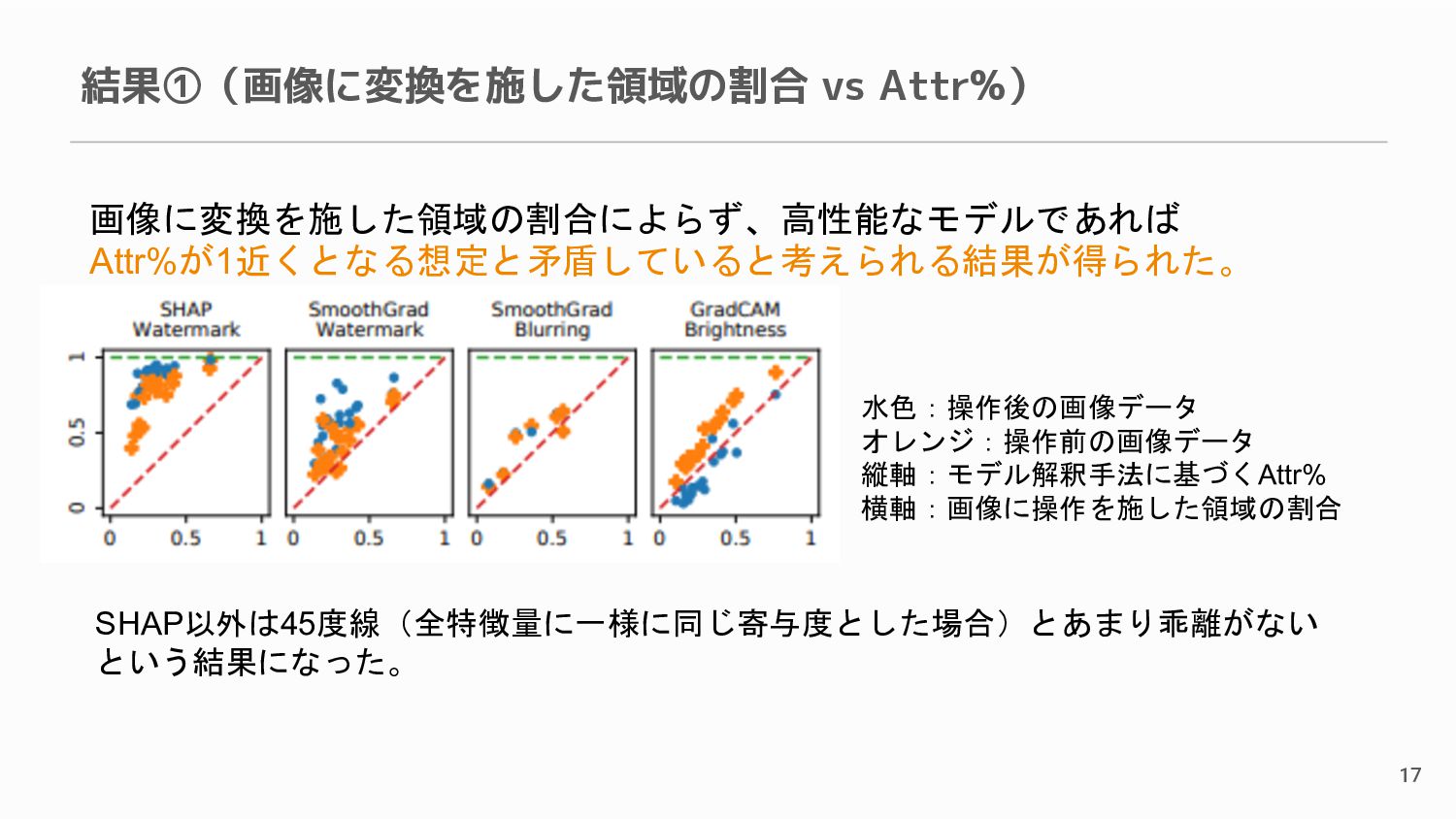{kind=link}
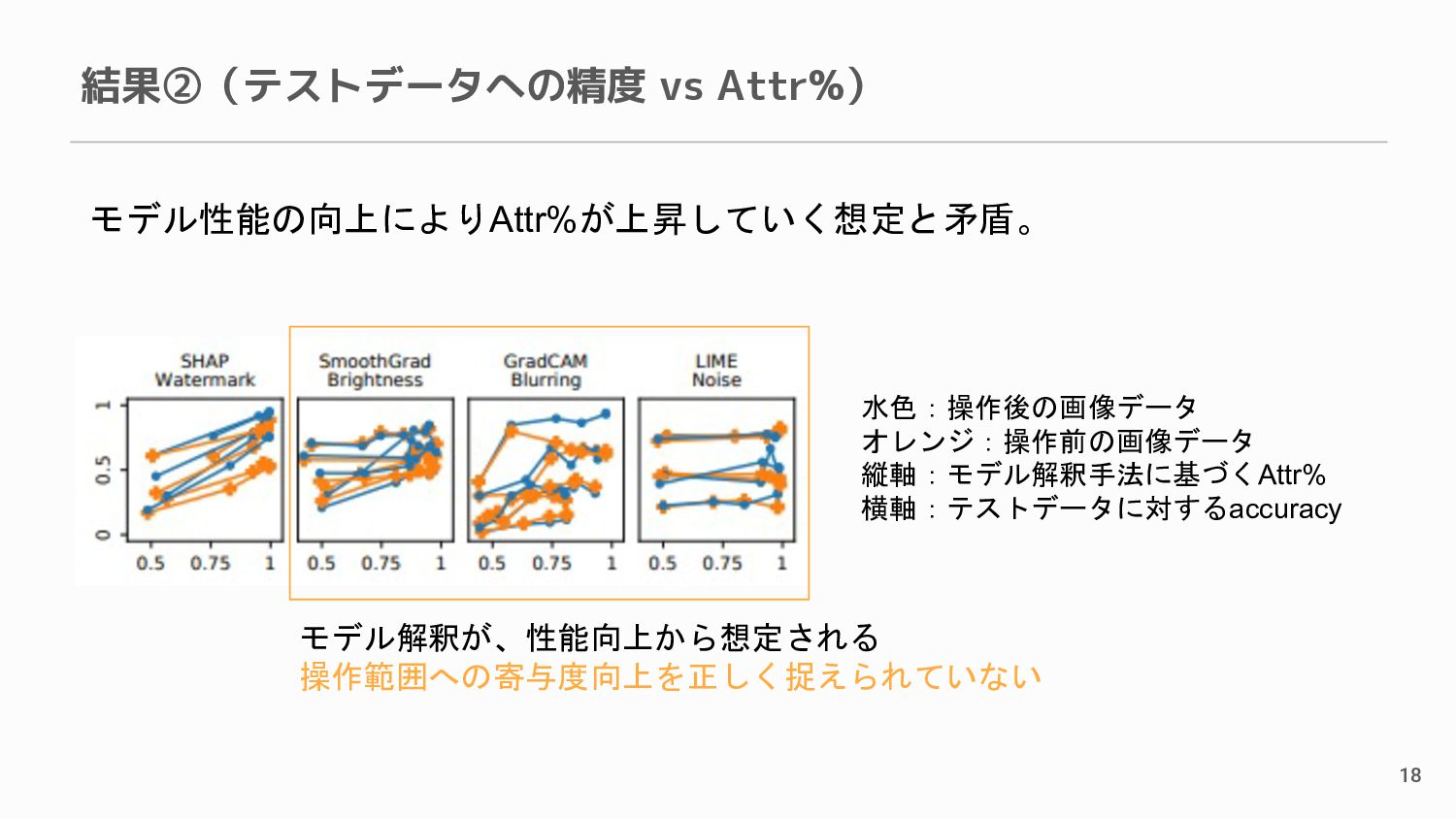{kind=link}
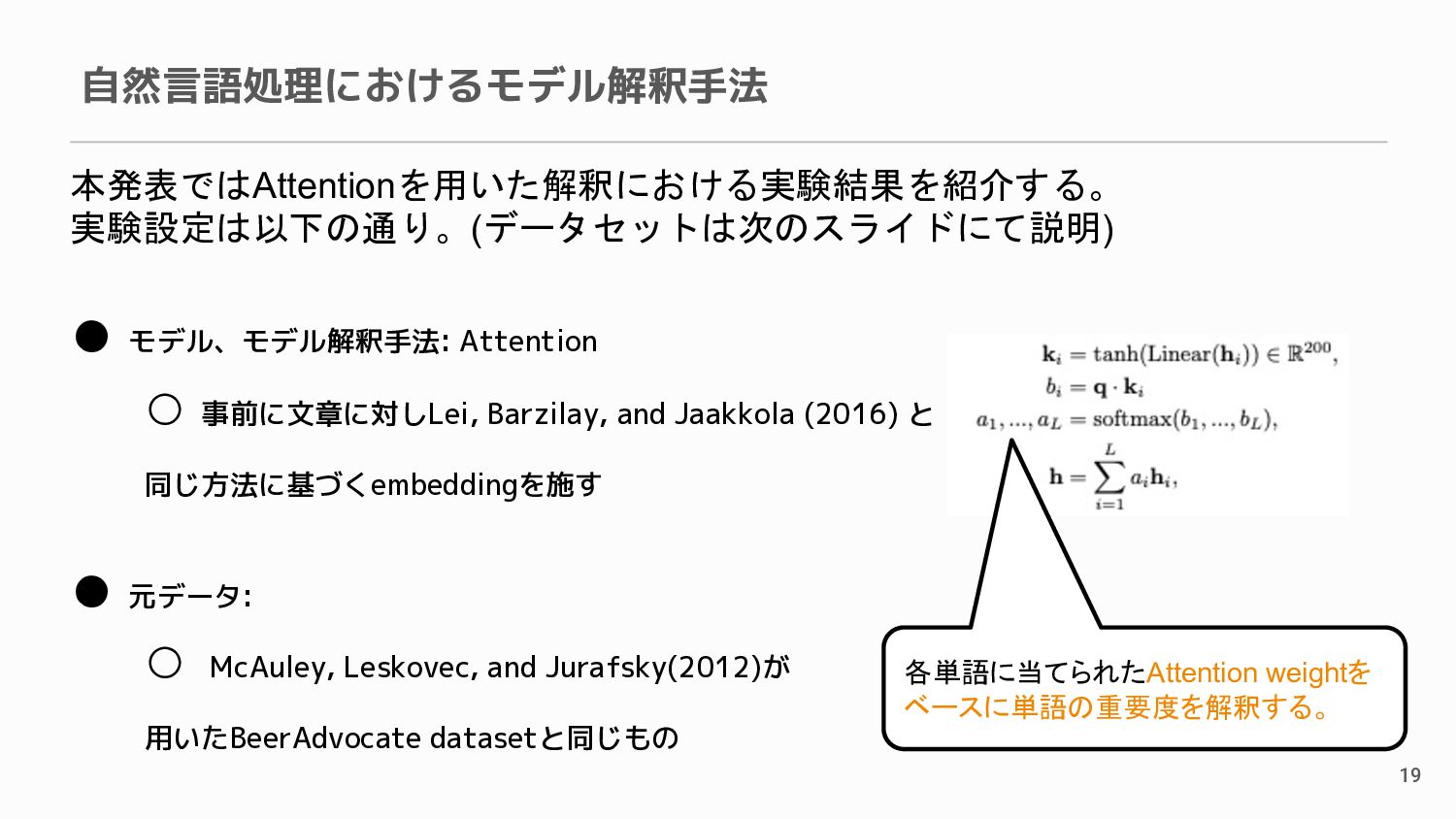{kind=link}
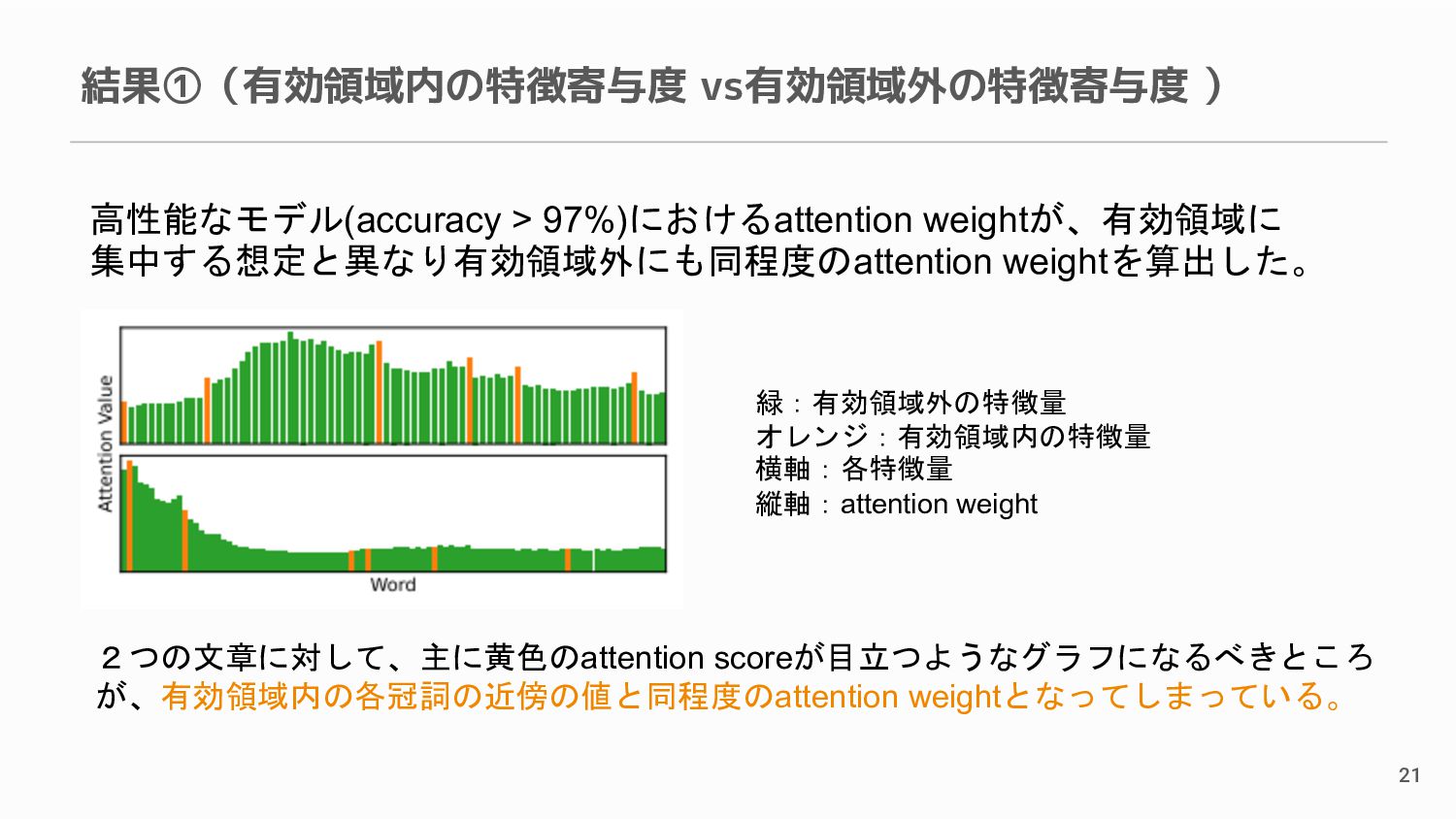
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}