Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
KDD2021論文読み会
Search
Seiichi Kuroki
October 07, 2021
1.3k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
KDD2021論文読み会
Seiichi Kuroki
October 07, 2021
More Decks by Seiichi Kuroki
See All by Seiichi Kuroki
AAAI2022 読み会
seiichi_kuroki
0
970
ICML2021 論文読み会
seiichi_kuroki
0
1k
Featured
See All Featured
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Skip the Path - Find Your Career Trail
mkilby
1
170
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
160
Docker and Python
trallard
47
4k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Google's AI Overviews - The New Search
badams
0
1.1k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Designing for Timeless Needs
cassininazir
1
410
Transcript
Needle in a Haystack : Label- Efficient Evaluation under Extreme
Class Imbalance 2021-10-07 KDD論文読み会 株式会社リクルート プロダクト統括本部 データ推進室 SaaS領域データソリューション2G 黒木 誠一
自己紹介 2 黒木誠一です! 東大で 薬学部志望→経済学→機械学習研究 社会で アクチュアリー→データサイエンティスト やってます、要はホワイトノイズです!
本論文選定理由 3 • 実応用で良く出る不均衡データへのモデル評価法の提案 • 汎用性が高そう ◦ 様々なモデル評価指標に対して適用可能 • 一見簡単そうだった
◦ これは誤りだったことが後に判明する
本論文のContribution 4 • モデル評価に際し大量のラベルなしデータの中からどれをラベル 付けしたら精度よくモデル性能評価ができるかを提案 ◦ 漸近的な挙動に対する理論保証 ◦ ラベルデータは今までより少なくてもOK! ◦
不均衡データだとより効率向上が見込める! • 実験による性能向上の確認
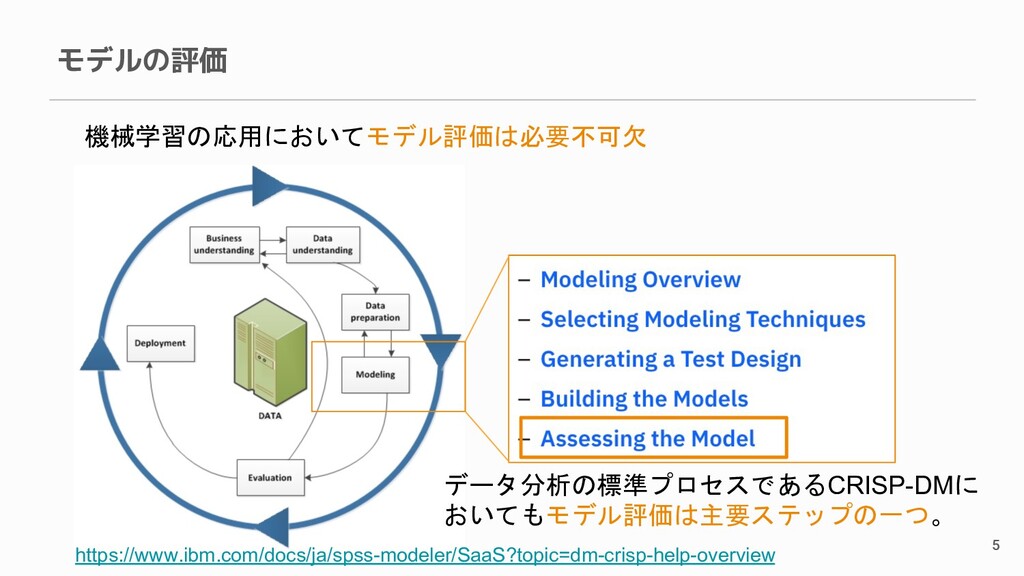
モデルの評価 5 機械学習の応用においてモデル評価は必要不可欠 データ分析の標準プロセスであるCRISP-DMに おいてもモデル評価は主要ステップの一つ。 https://www.ibm.com/docs/ja/spss-modeler/SaaS?topic=dm-crisp-help-overview
正確なモデル評価における主要課題 6 モデル評価における主要課題として以下の3つが挙げられる。 • 当てはめたい未知のデータに対する手持ちデータのバイアス ◦ 選択バイアスなど • ラベルデータは入手不可能であったり、取得に高い費用がかかる •
不均衡データであることに起因する推定誤差 本論文で特に解決したい課題はこの下2つ
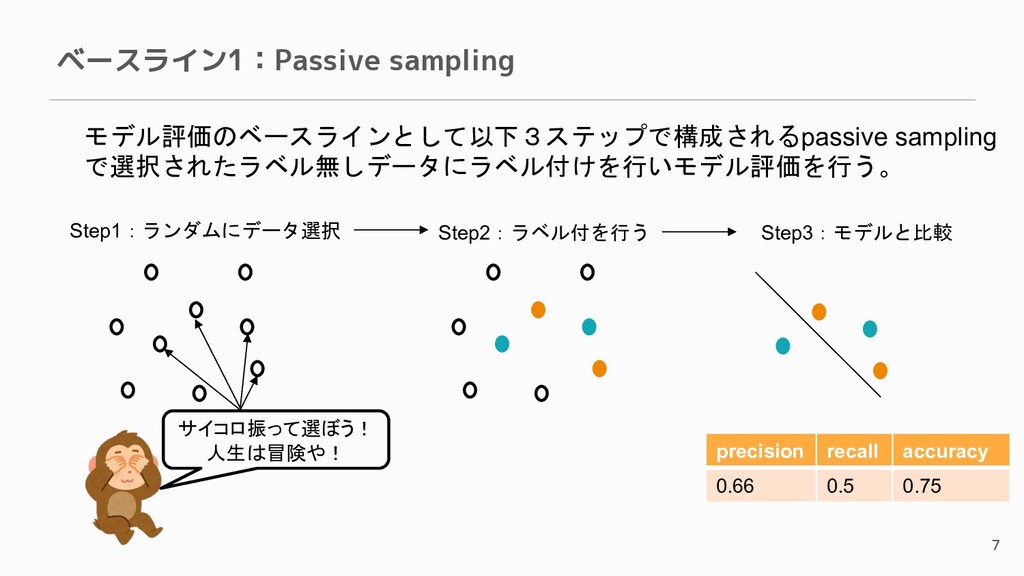
ベースライン1:Passive sampling 7 モデル評価のベースラインとして以下3ステップで構成されるpassive sampling で選択されたラベル無しデータにラベル付けを行いモデル評価を行う。 サイコロ振って選ぼう! 人生は冒険や! Step1:ランダムにデータ選択 Step2:ラベル付を行う
Step3:モデルと比較 precision recall accuracy 0.66 0.5 0.75
Passive samplingにおける問題 8 各モデル評価指標において漸近正規性は成立するが、Recallなど一部評価指標 推定においては不均衡データだと膨大なラベルを要してしまう。 Recallの推定値の漸近分布における分散の分母にあるεは正例の比率。 →不均衡データでは推定値を一定の分散に留めるために大量のデータが必要。
ベースライン2: Importance sampling, Strafified sampling 9 推定値の分散を低減する手法としてImportance samplingや stratified samplingが提案されてきた。
• Importance sampling (Sawade et al,. NeurIPS’10) • Stratified sampling (Druck & McCallum. CIKM’11) しかしながら… 1. 限られた評価指標のみに適用可能 (F1値だけだったり…) 2. テストデータをactiveに収集するケースに対応不可 3. 推定値の分散の観点で非効率 (特にstratified sampling) などの問題あり。
提案手法:Adaptive importance sampling (AIS) に基づくモデル評価 10 様々な評価指標に対して、ラベル効率の良いモデル評価が可能 目的 必要なラベル数を最小化しつつ、評価指標の推定 を正確に行う。
アイデア 各ラベル付けを行うデータのサンプリングはAIS をベースに行う ◦ 重要度をもとにバイアスは補正 ◦ 評価用データ分布設定に漸近分散を 最小化させるような工夫を施す 評価用データ分布を更新していく(Adaptive)
理論解析(Asymptotic theory) 11 推定値の漸近的挙動に対して理論解析を行なった • 一致性の証明 ◦ 推定値が漸近的に母集団に対する値に収束することを保証 • 中心極限定理の証明
◦ 推定値の漸近信頼区間の導出 • 漸近的に最小分散をもたらす評価用データ分布導出 ◦ 母集団ベースで定義されているp(y|x)やDg(R)は有限標本で近似要 正例比率に依存しなくなってる!
評価用データ分布の詳細 12 本論文では漸近最適な評価用データ分布の有限標本近似分布とその漸近最適性 の証明も行なっている。 有限標本で近似 ←オレンジの箇所は母集団ベースなので直接計算できない… • 一定の条件のもとでの漸近最適性を保証 • 本論文ではp(y|x)をBayesian
Dirichlet-tree modelで推定
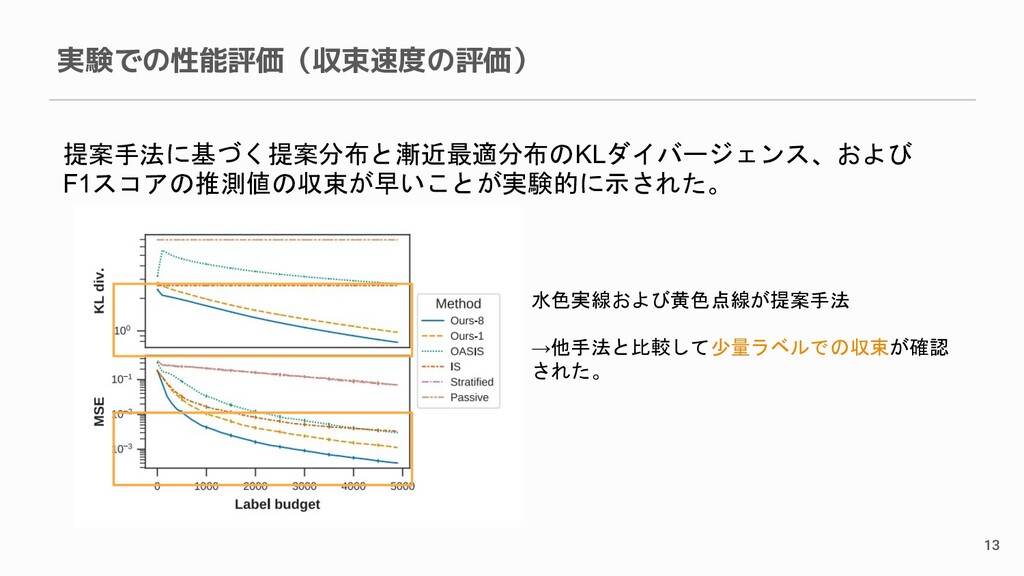
実験での性能評価(収束速度の評価) 13 提案手法に基づく提案分布と漸近最適分布のKLダイバージェンス、および F1スコアの推測値の収束が早いことが実験的に示された。 水色実線および黄色点線が提案手法 →他手法と比較して少量ラベルでの収束が確認 された。
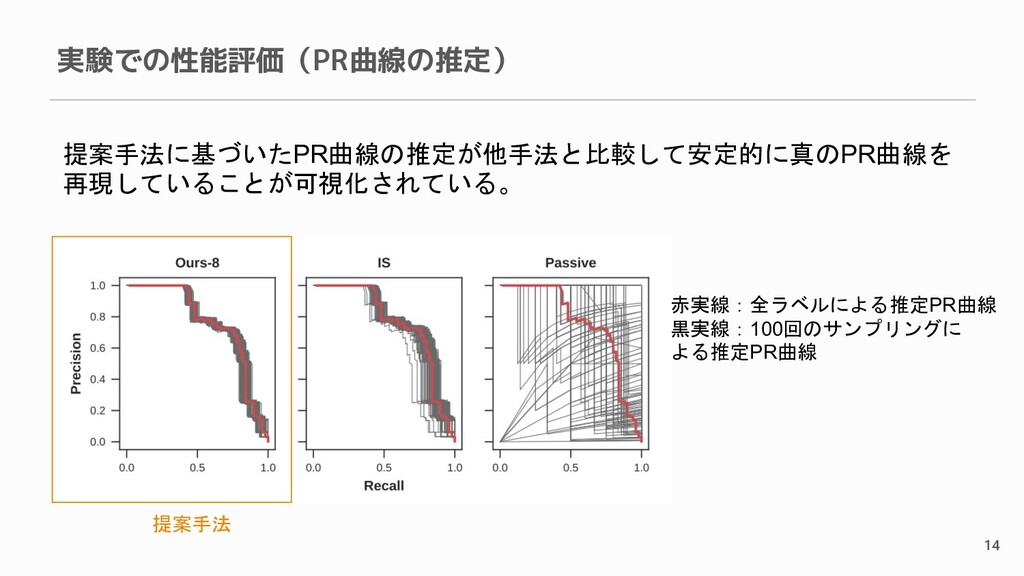
実験での性能評価(PR曲線の推定) 14 提案手法に基づいたPR曲線の推定が他手法と比較して安定的に真のPR曲線を 再現していることが可視化されている。 赤実線:全ラベルによる推定PR曲線 黒実線:100回のサンプリングに よる推定PR曲線 提案手法
論文のまとめ 15 • 漸近的な理論保証付きのモデル評価手法の提案 ◦ サンプリングを工夫しつつ一致性と両立! • 既存手法より推定値の漸近分散が低減されるサンプリングの提案 ◦ Passive
samplingの際にあった正例比率が提案手法では消滅 • 実験による性能向上の確認
所感 16 • Active learningにも使えそうだが、ありがちなヒューリスティックで はなく漸近分散最小化ベースのサンプリングは有用そう ◦ 実際は有限標本で推定する際にズレが生じることには注意したい。 • Active
learningはモデルの学習に関する話だが本論文は任意のモデル に対するモデル評価の話であるという設定が面白かった • サンプル数が少ない話がモチベーションになっていたのに漸近的挙動 のみの議論になっていたので有限標本サイズの議論は気になった
(上司の)宣伝 17 データサイエンスを実践する上で 最低限必要なプログラミングスキルを網羅できます! 論文の1億倍の効率で 実務に活かせるよ! (個人の感想です。)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}