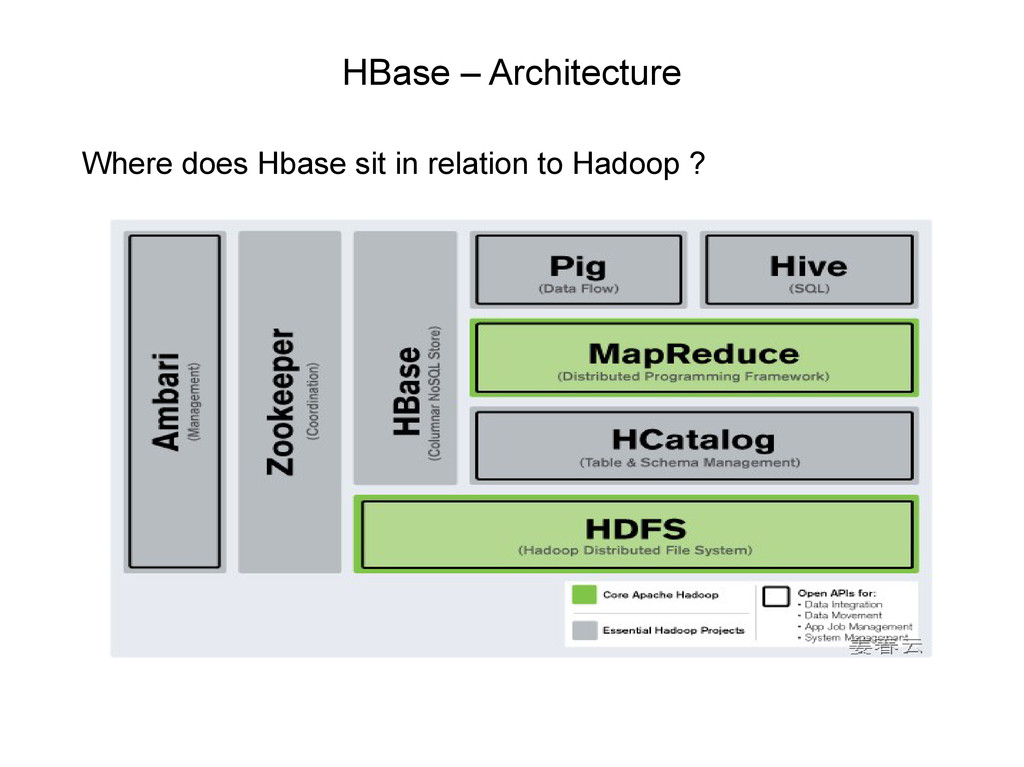
Store • A noSQL store for big data • It is Open Source, written in Java • It is a distributed database • Automatic sharding, table data spread over cluster • Automatic region server fail over
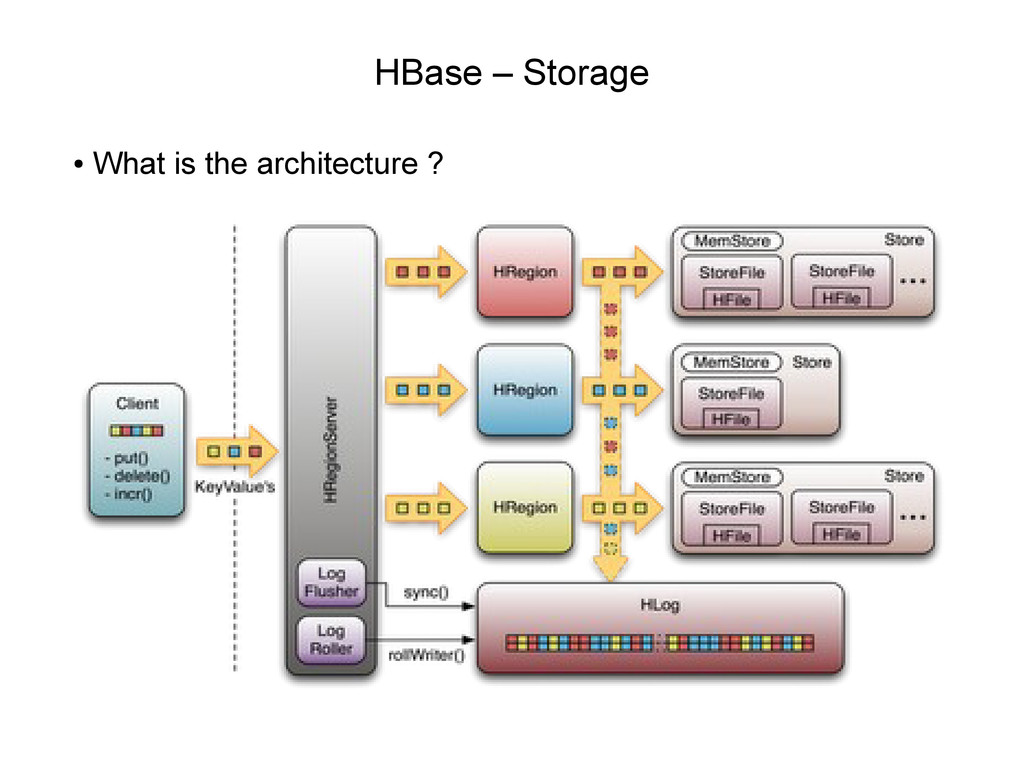
Uses Hadoop for distributed storage • Data stored across region servers • Region server data spread across HDFS data nodes • A write ahead log (WAL) is used to record changes
Request RPC'ed as key value to Region server • Key Value routed to region for row • Data is written to WAL • Data written to region memStore • If region server cashes WAL can be used to recover data
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}