This presentation introduces Apache Hadoop HDFS. It
describes the HDFS file system in terms of Hadoop and
big data. It looks at its architecture and resiliance.
Distributed File System • It is a distributed file system • Runs on low cost hardware • It is open source • Written in Java • Fault tolerant • Designed for very large data sets • Tuned for high throughput
batch processing • Streaming access to data • Large data sizes i.e. Terabytes • Highly reliable using data replication • Supports very large node clusters • Supports large files • Supports file numbers into millions
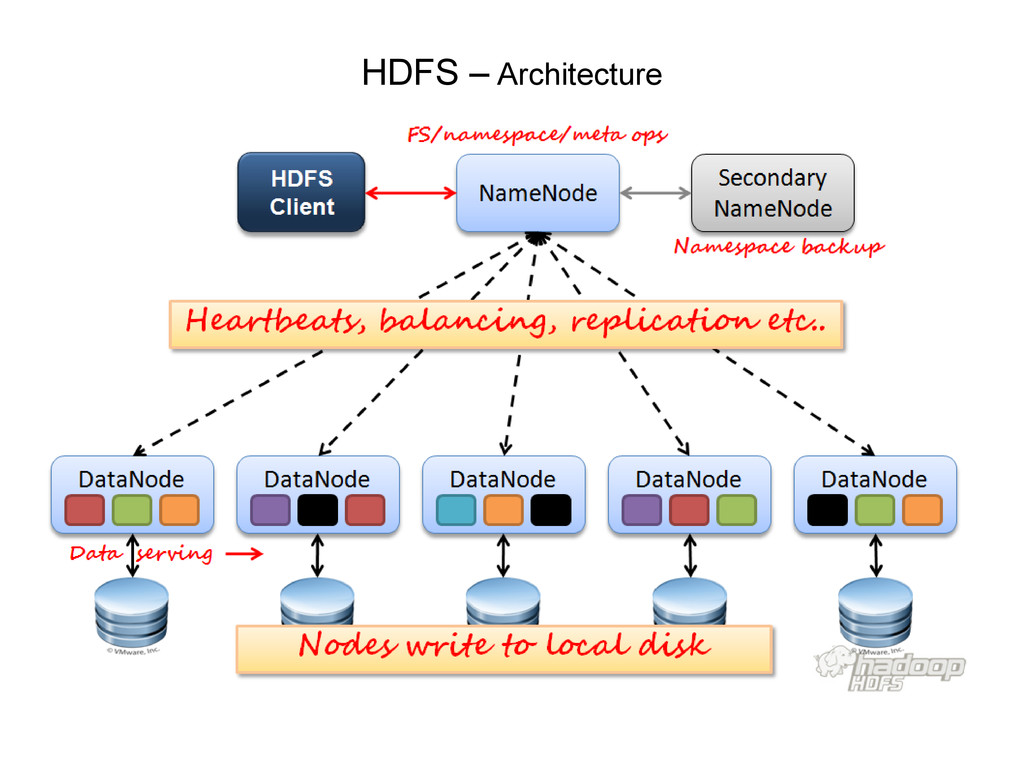
• A master NameNode – Controls file system operations – Maps data blocks to DataNodes – Logs all changes • Slave DataNodes – Store file blocks – Store replicated data
Nodes may fail but data is still available • DataNodes indicate state via heart beat report • Single point of failure in master NameNode • Data integrity via check sums
Shell commands language • HTTP browser • C wrapper for Java API • Space reclamation – Via control of replication factor – Deleted files sent to trash folder – Trash folder cleaned after configurable time
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}