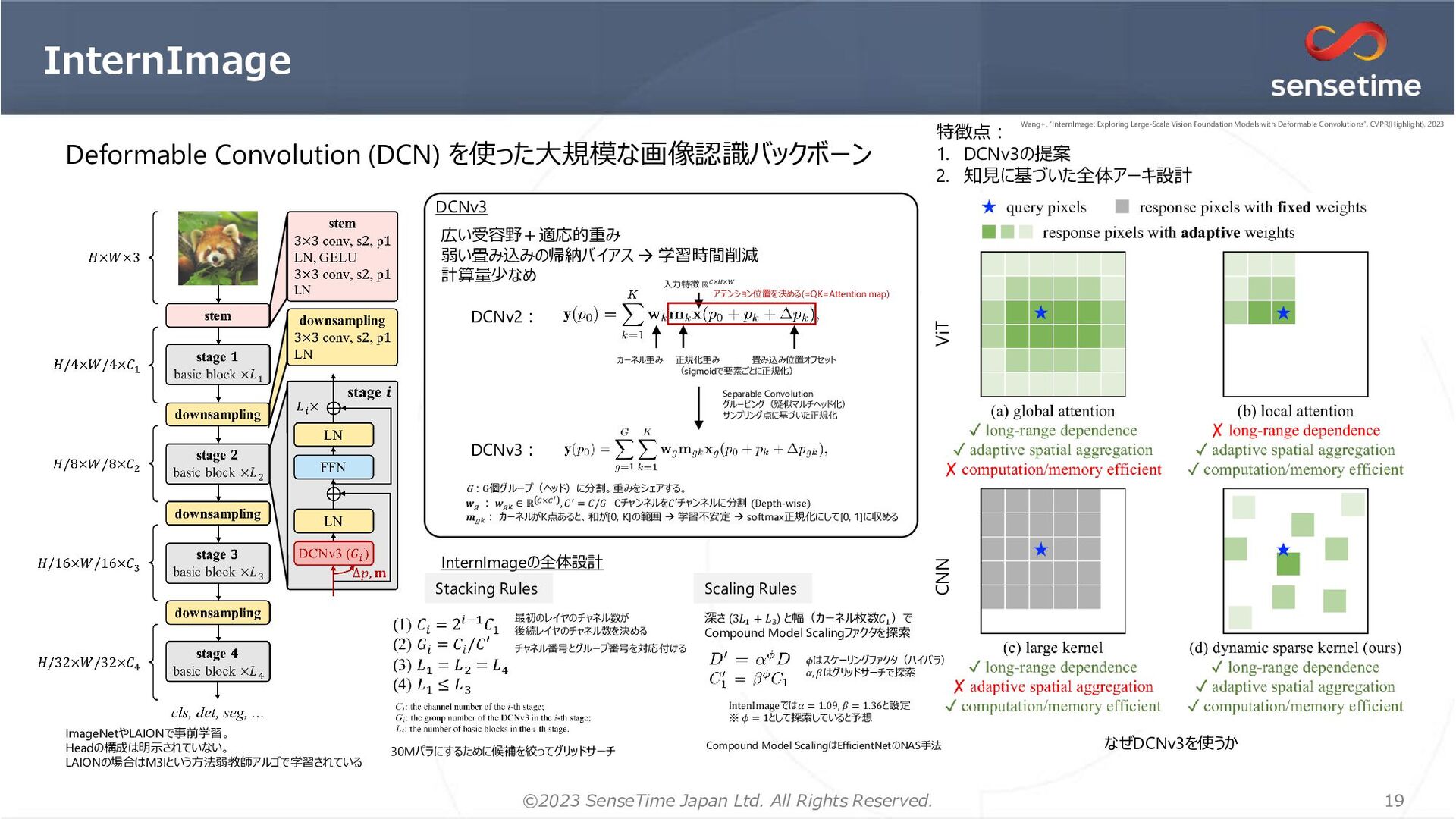
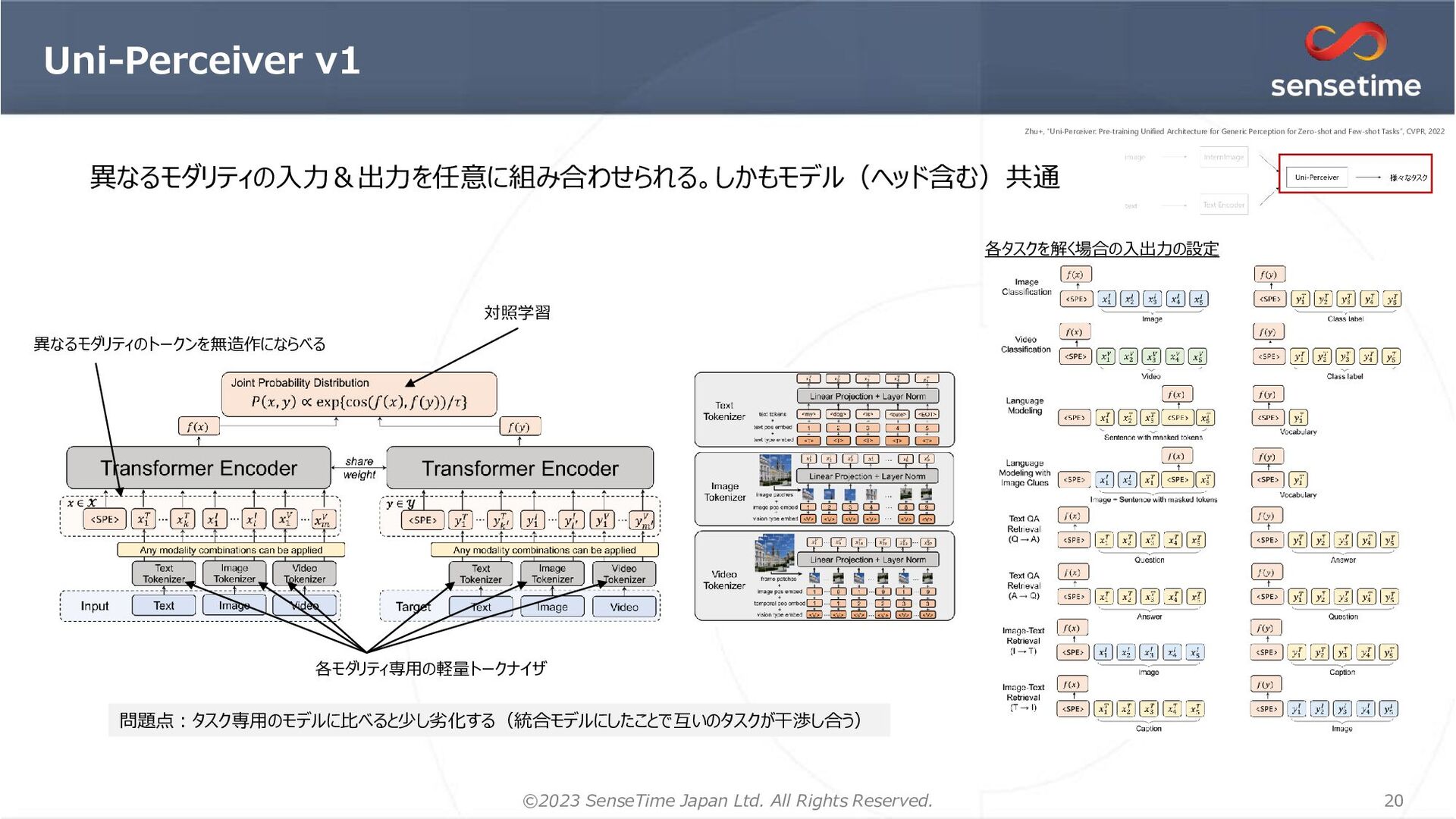
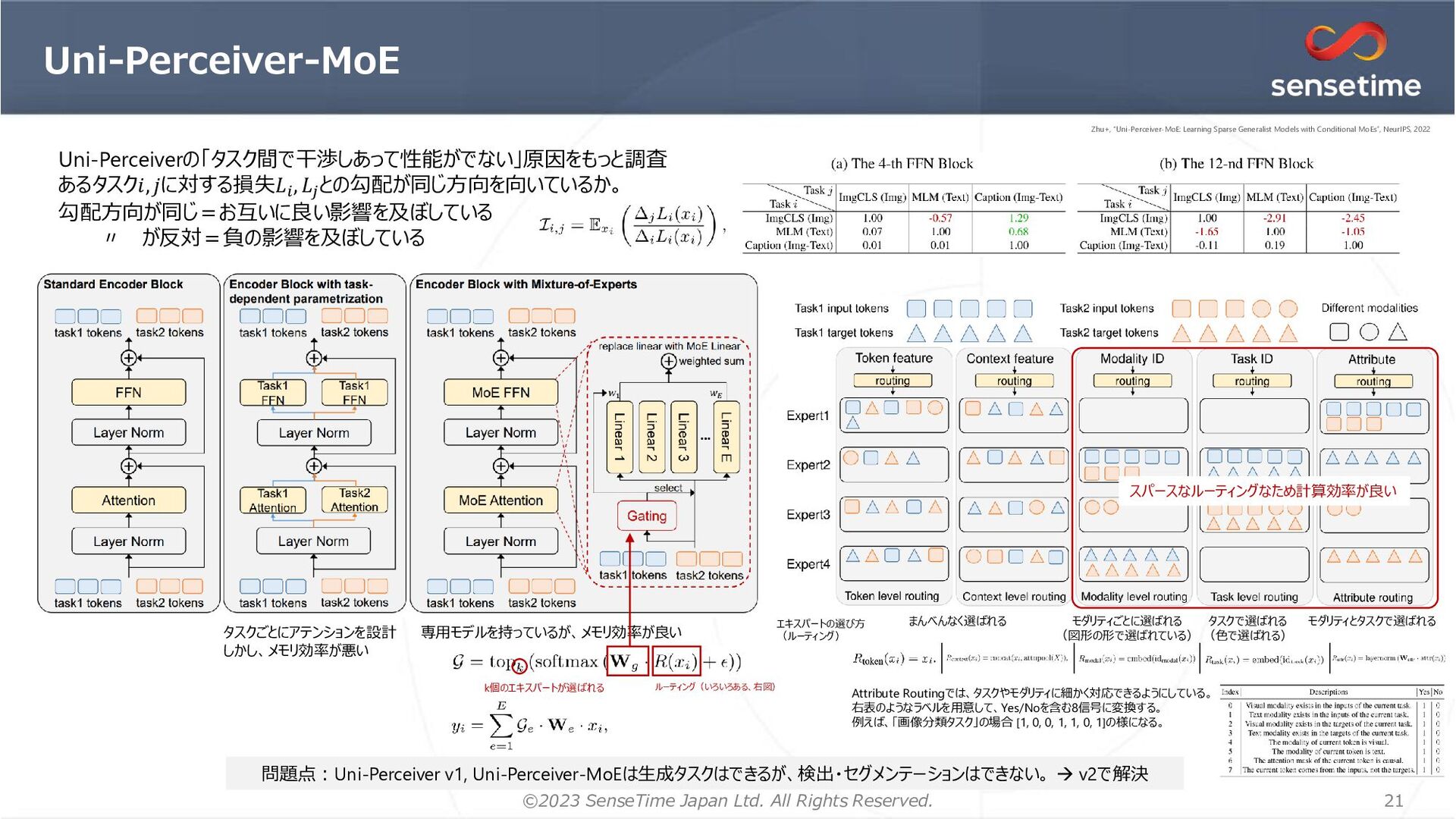
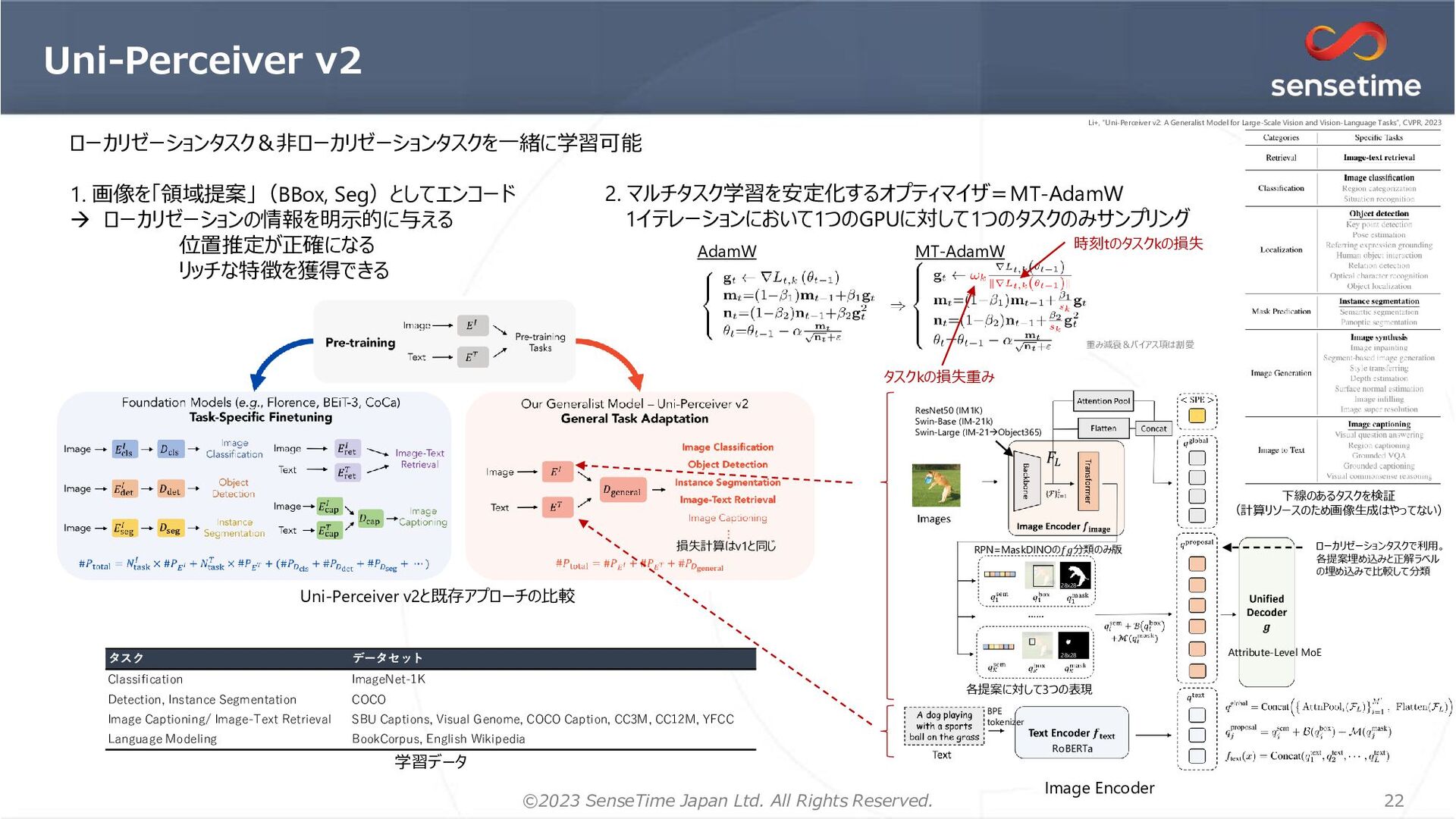
SSII2023, MIRU2023の企業展示ポスター「大規模画像認識モデルとその応用」の補助資料です。
GitHub:https://github.com/OpenGVLab/InternImage
SSII2023:「大規模画像認識モデルとその応用」 https://confit.atlas.jp/guide/event/ssii2023/static/sponsorbooth#sensetime
MIRU2023:「企業展示 EX-G3:株式会社センスタイムジャパン」 http://cvim.ipsj.or.jp/MIRU2023/program/
{kind=link}
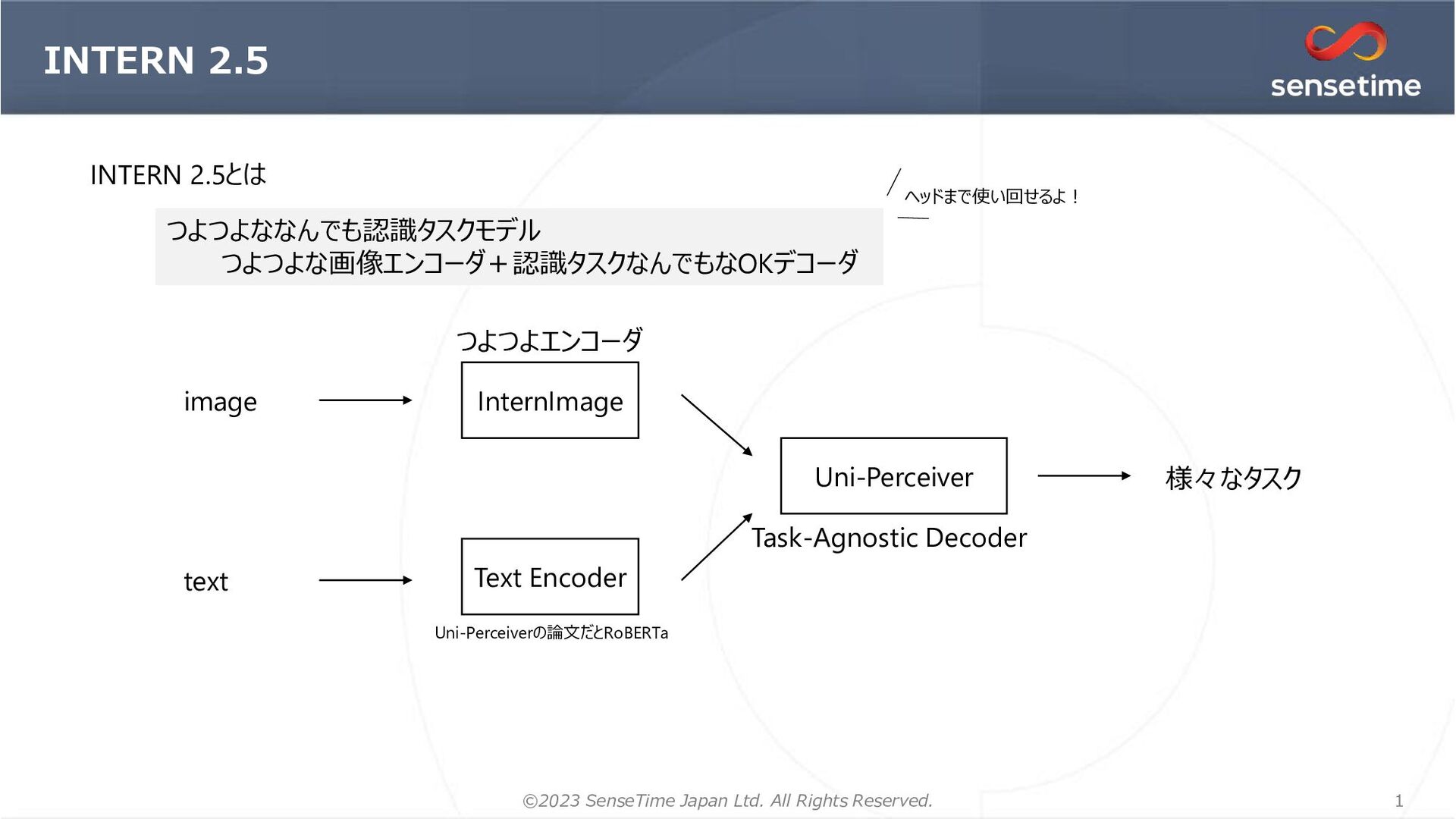{kind=link}
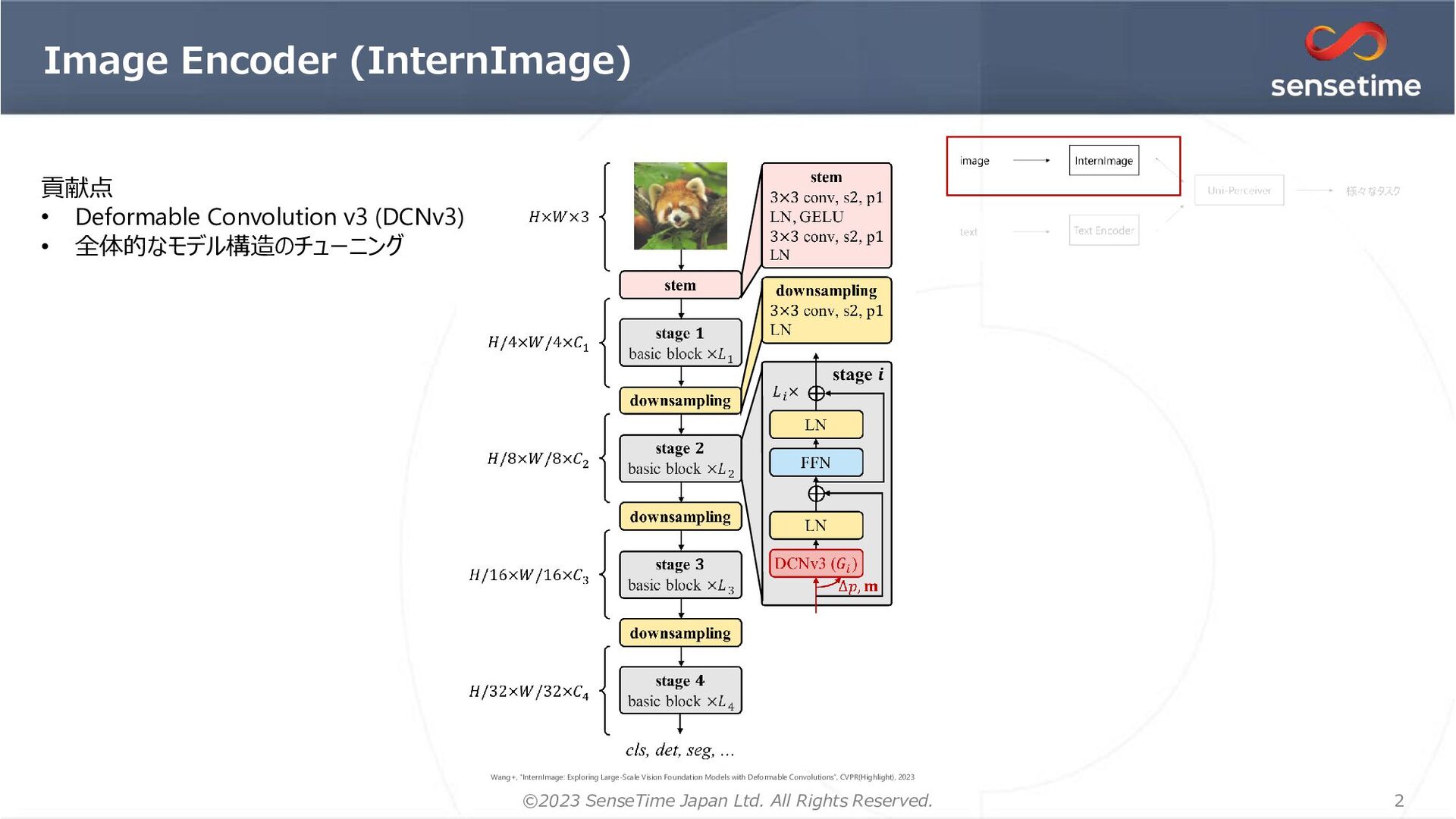{kind=link}
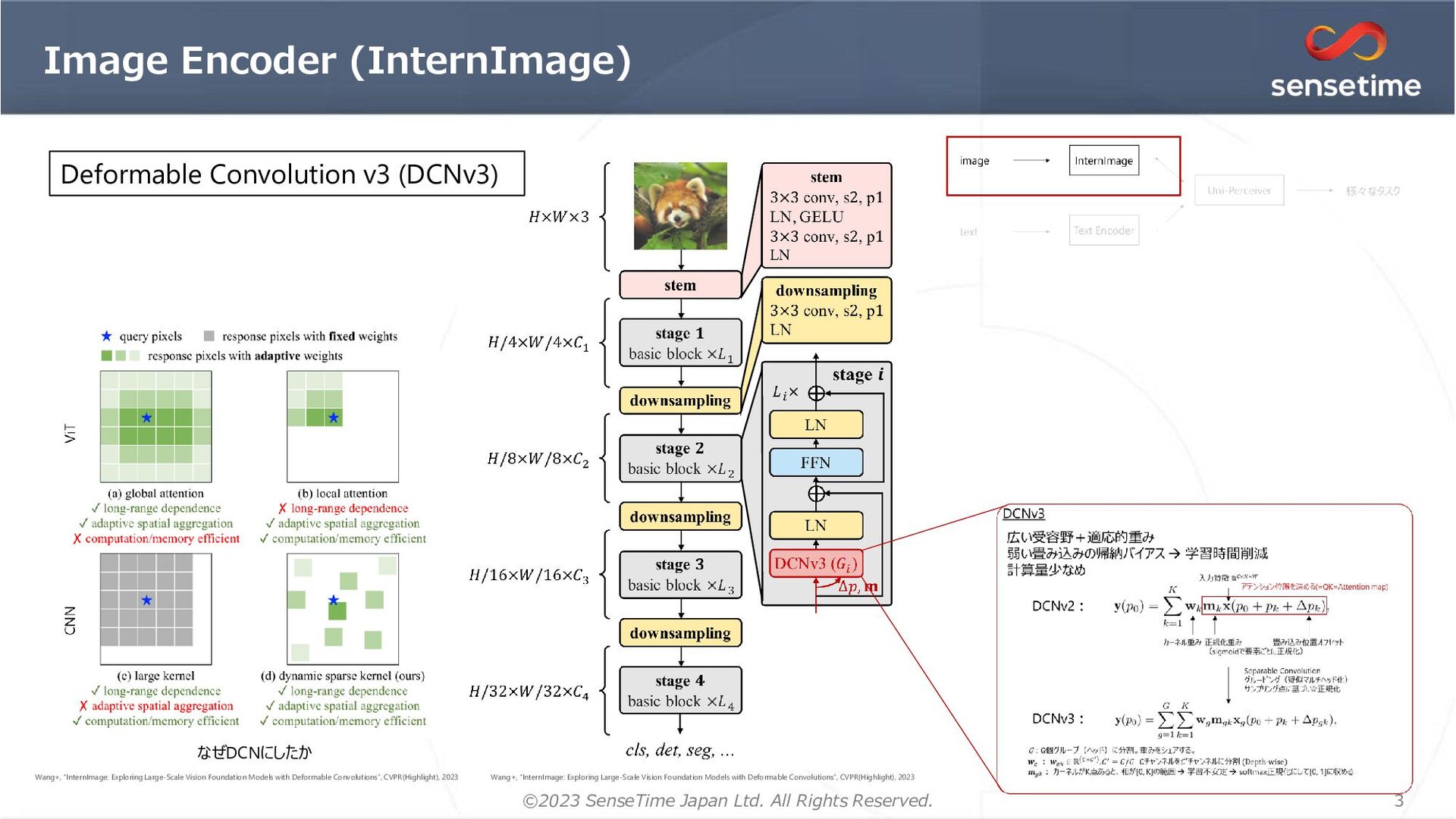{kind=link}
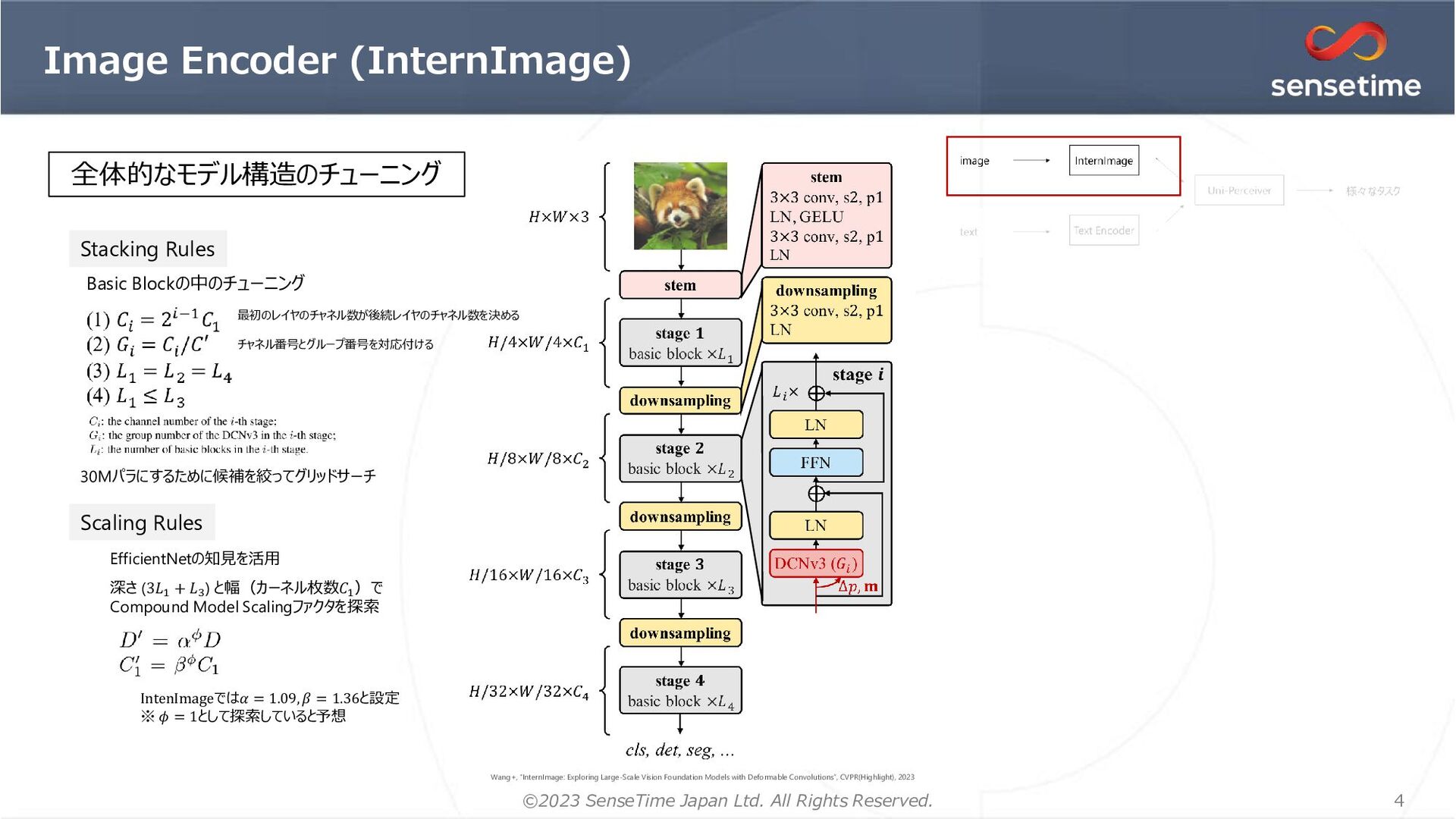{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
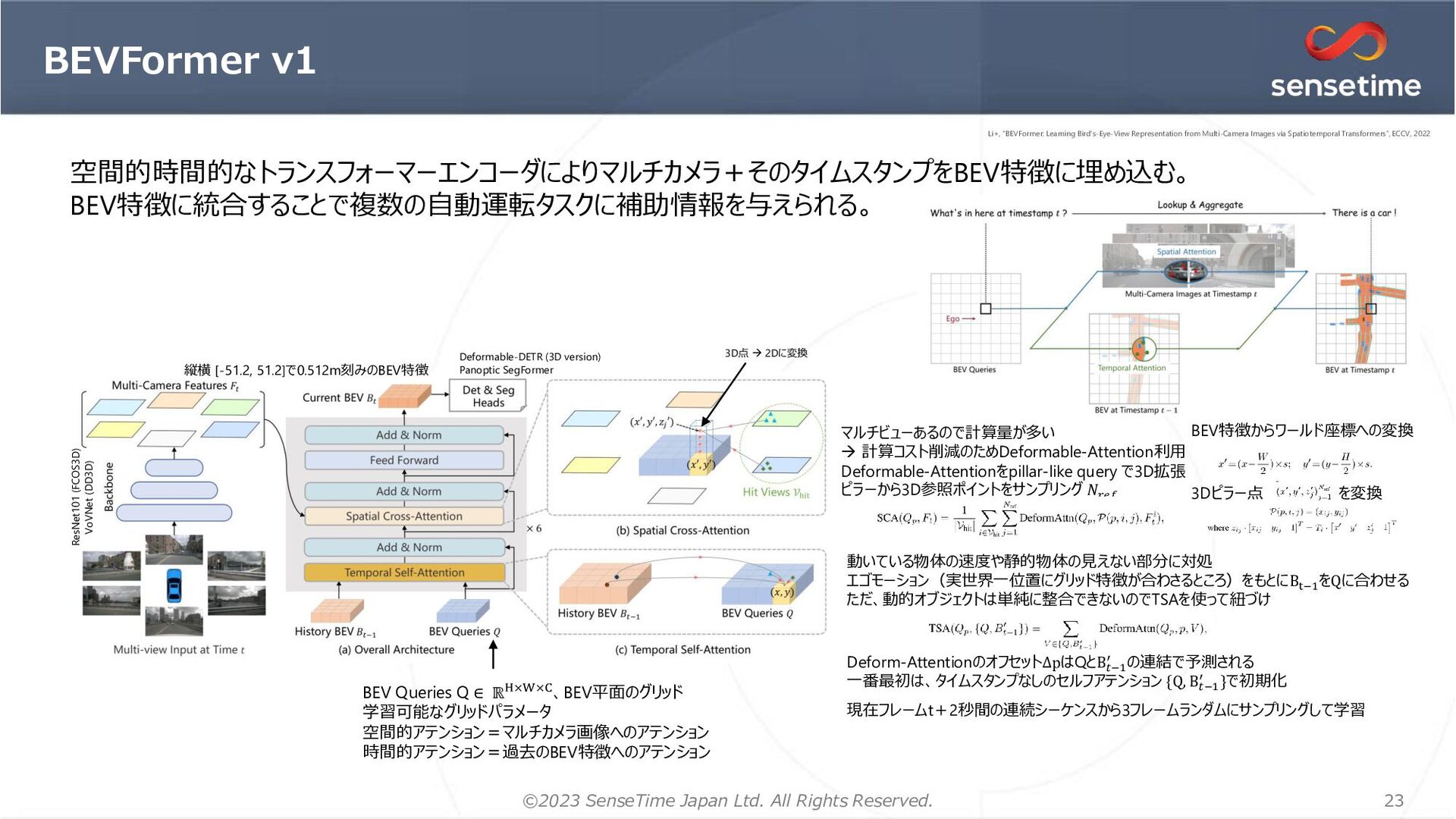{kind=link}
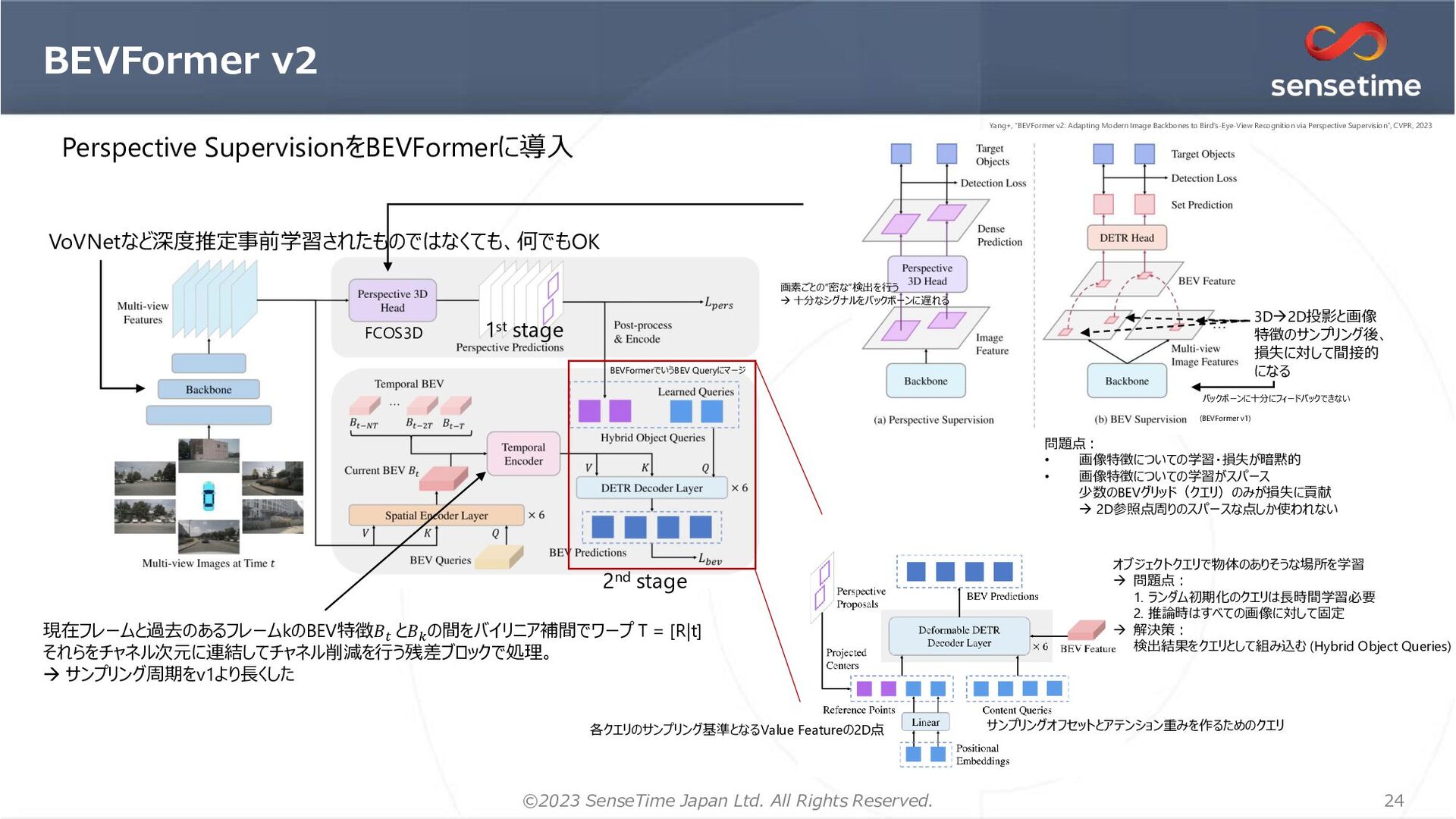{kind=link}
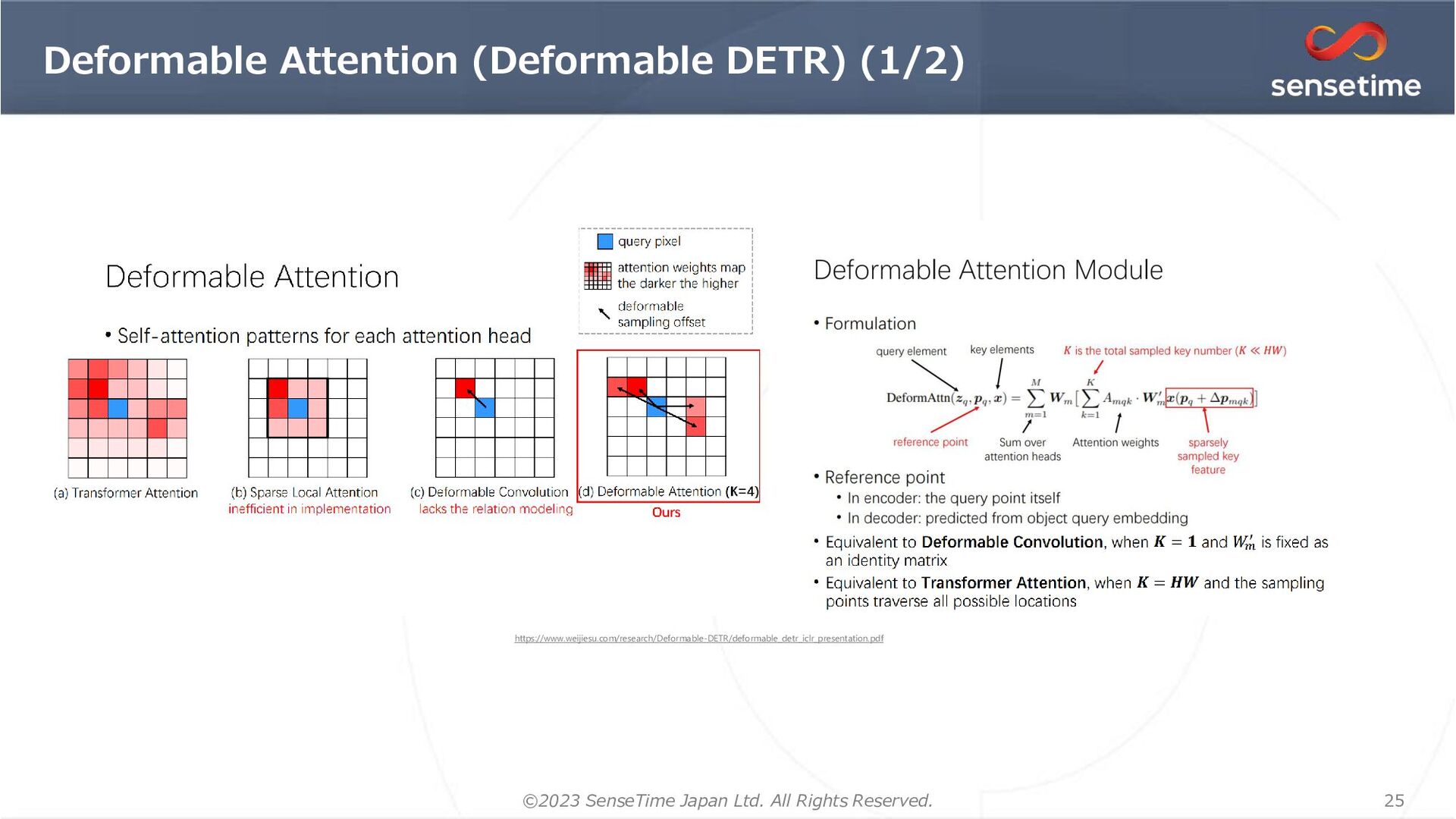{kind=link}
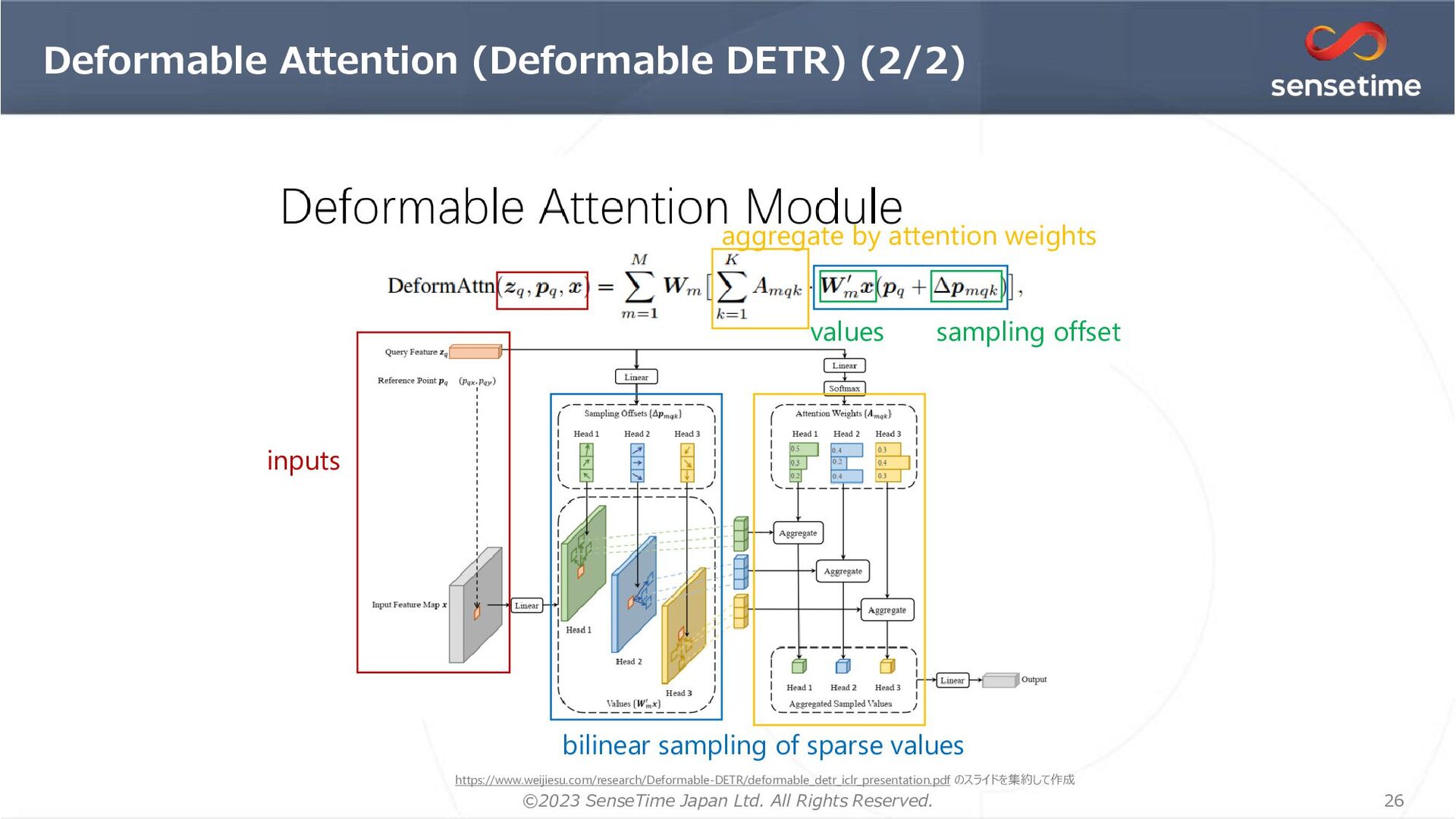{kind=link}