2021.12.3 Fri 開催の【SenseTime Japan × Sansan】画像処理勉強会資料です。
https://sansan.connpass.com/event/230636/
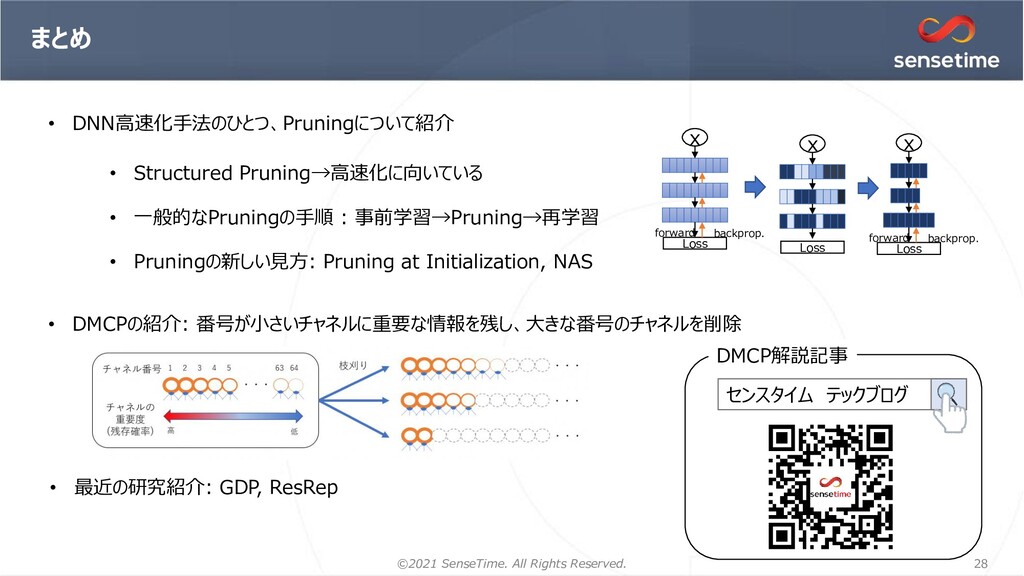
title:プルーニング:ディープラーニング軽量化・高速化・
エッジデバイスの高速軽量化
speaker: 畠山雄気(Yuki HATAKEYAMA)
株式会社センスタイムジャパン(SenseTime Japan Ltd.)
株式会社センスタイムジャパンの公式アカウントです。
外部向け発表資料を公開しております。
TECH blog: https://tech.sensetime.jp/
会社web: https://www.sensetime.jp/
TW: https://twitter.com/SensetimeJ
FB: https://www.facebook.com/sensetimejapan
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}