Dosovitskiy et al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”, arXiv [cs.CV]. 2021. [2] H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, en H. Jégou, “Training data-efficient image transformers & distillation through attention”, arXiv [cs.CV]. 2021. [3] G. Wang, Y. Zhao, C. Tang, C. Luo, en W. Zeng, “When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism”, arXiv [cs.CV]. 2022. [4] B. Wu et al., “Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions”, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. [5] Z. Liu et al., “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows”, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, bll 10012–10022. [6] I. Tolstikhin et al., “MLP-Mixer: An all-MLP Architecture for Vision”, arXiv [cs.CV]. 2021. [7] J. Lin, C. Gan, en S. Han, “TSM: Temporal Shift Module for Efficient Video Understanding”, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019. [8] T. Yu, X. Li, Y. Cai, M. Sun, en P. Li, “S2-MLP: Spatial-Shift MLP Architecture for Vision”, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2022, bll 297–306. [9] D. Lian, Z. Yu, X. Sun, en S. Gao, “AS-MLP: An Axial Shifted MLP Architecture for Vision”, ICLR, 2022. [10] Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, en S. Xie, “A ConvNet for the 2020s”, arXiv [cs.CV]. 2022. [11] T. Xiao, Y. Liu, B. Zhou, Y. Jiang, en J. Sun, “Unified Perceptual Parsing for Scene Understanding”, arXiv [cs.CV]. 2018.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
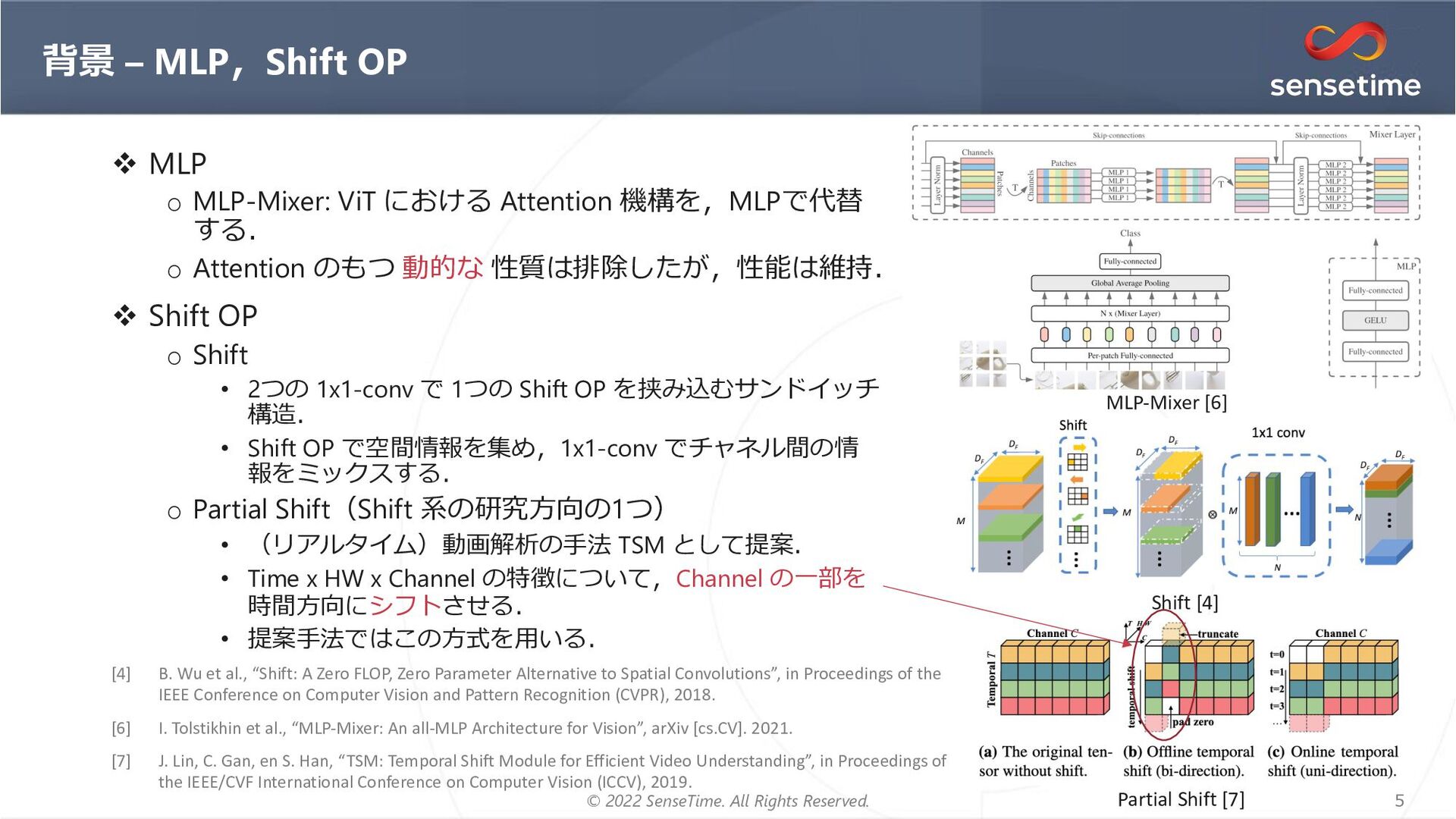{kind=link}
{kind=link}
{kind=link}
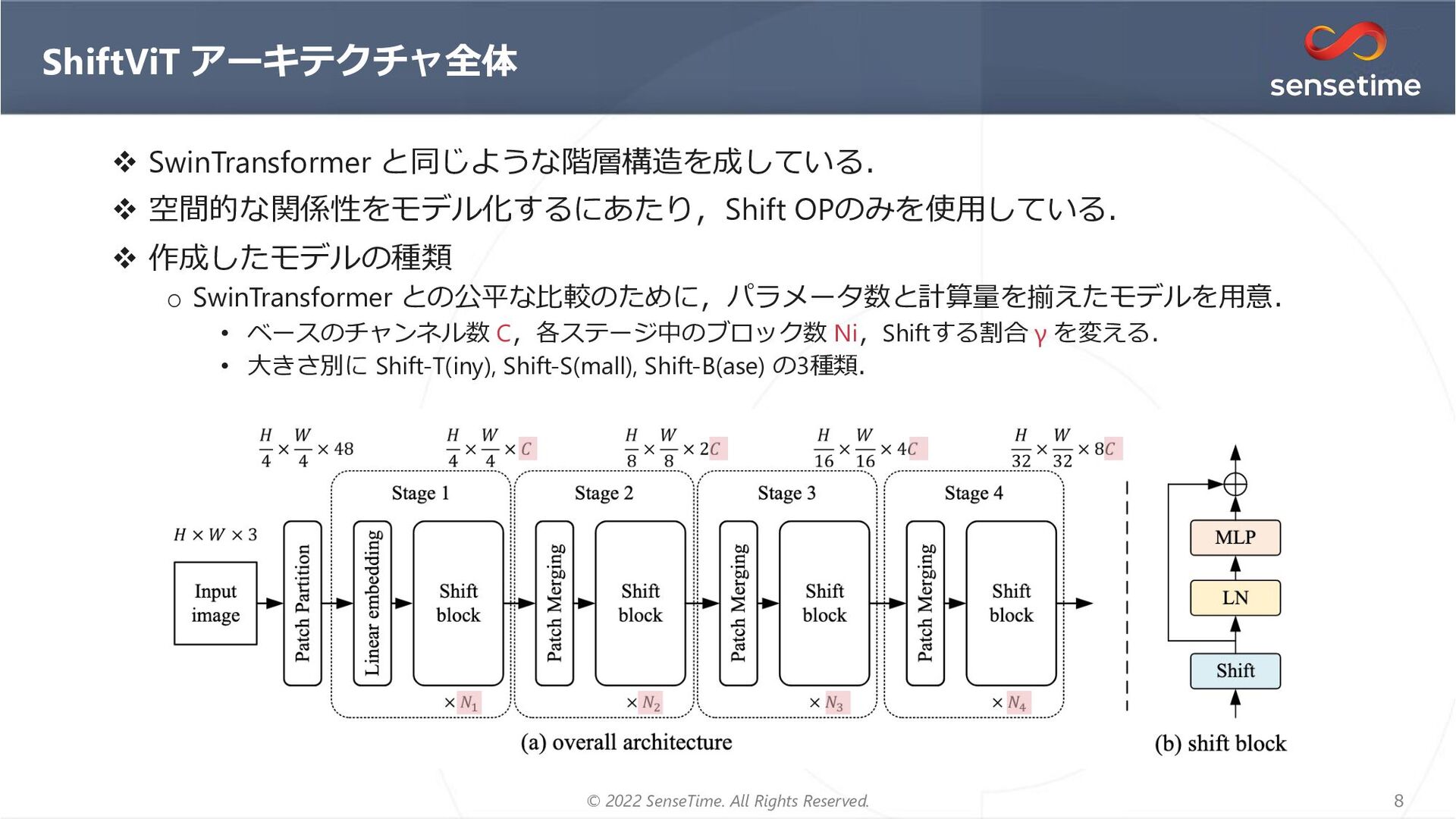{kind=link}
{kind=link}
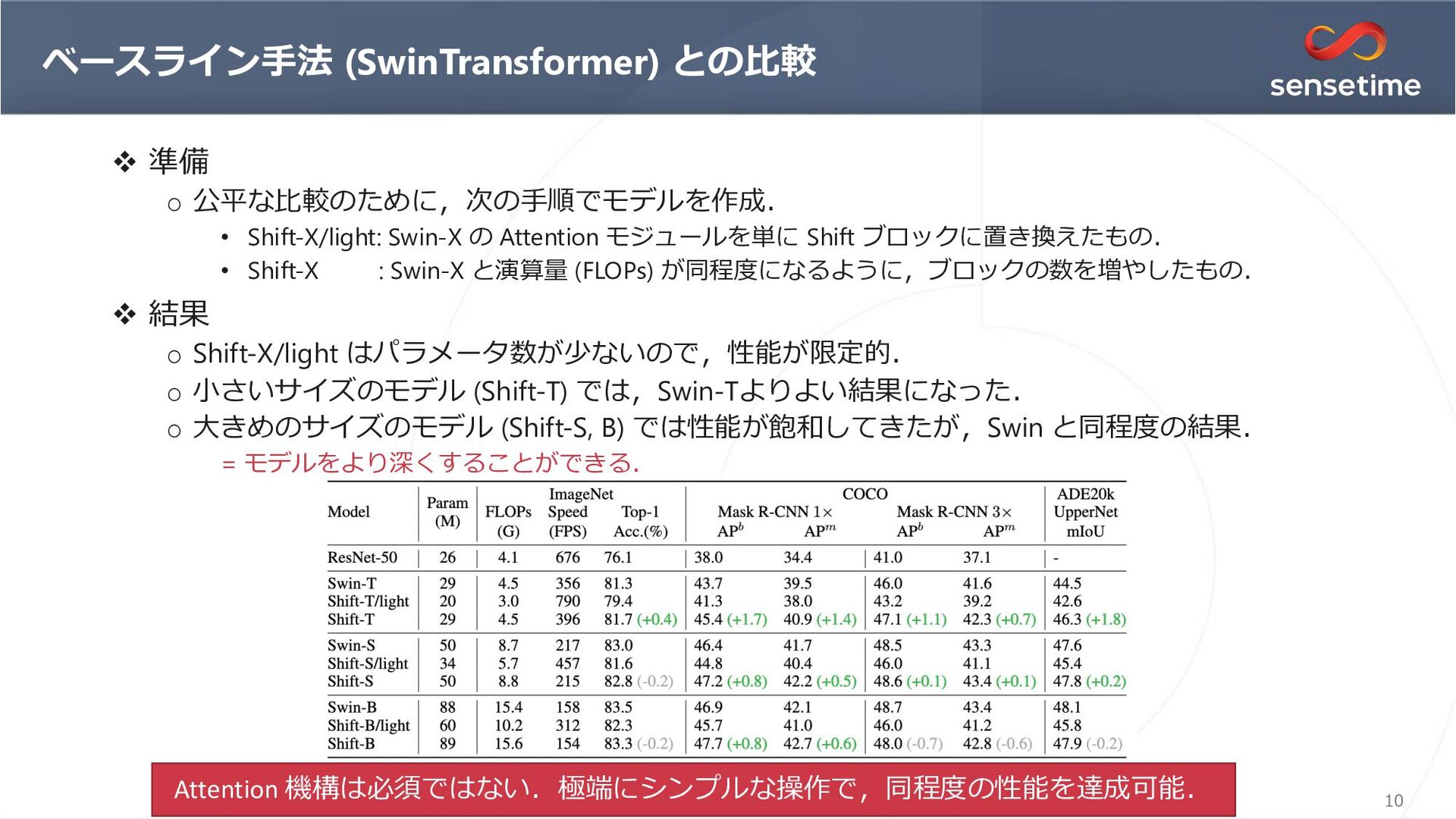{kind=link}
{kind=link}
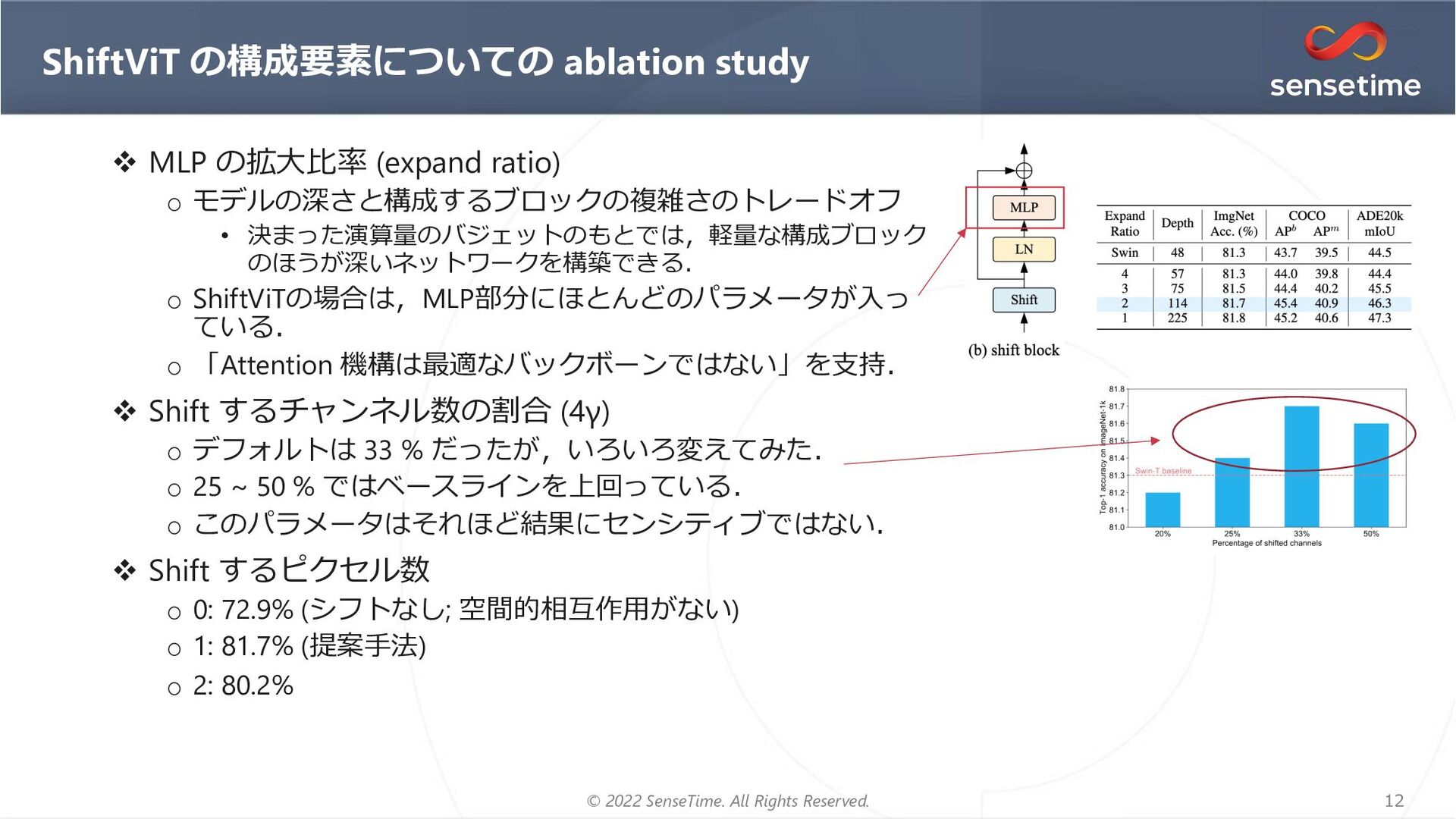{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2022 SenseTime. All Rights Reserved. 16 参考⽂献リスト [1] A.](https://files.speakerdeck.com/presentations/2e3d99a9ab1a4f319bbf72b0ec2ee37a/slide_15.jpg){kind=link}