єдиний монотонно зростаючий лічильник, значення якого може лише збільшитись або скинути до нуля при перезапуску. Наприклад, за допомогою лічильника можна вказати кількість поданих запитів, виконаних завдань або помилок. Не використовуйте лічильник, щоб виставити значення, яке може зменшитися. Наприклад, не використовуйте лічильник кількості поточно запущених процесів; замість цього використовуйте gauge. Gauge Це метрика, яка представляє одне числове значення, яке може довільно йти вгору і вниз. Як правило, використовуються для вимірюваних значень, таких як температури або поточне використання пам'яті, але також "відліків", які можуть підніматися вгору і вниз, як кількість одночасних запитів. Histograsm Гістограма відображає спостереження (як правило, такі як тривалість запиту або розміри відповідей) і підраховує їх у заданих сегментах. Він також надає суму всіх значень. # HELP go_gc_duration_seconds A summary of the GC invocation durations. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 1 go_gc_duration_seconds{quantile="0.25"} 8 go_gc_duration_seconds{quantile="0.5"} 0 go_gc_duration_seconds{quantile="0.75"} 0 go_gc_duration_seconds{quantile="1"} 1 go_gc_duration_seconds_sum 10
{kind=link}
{kind=link}
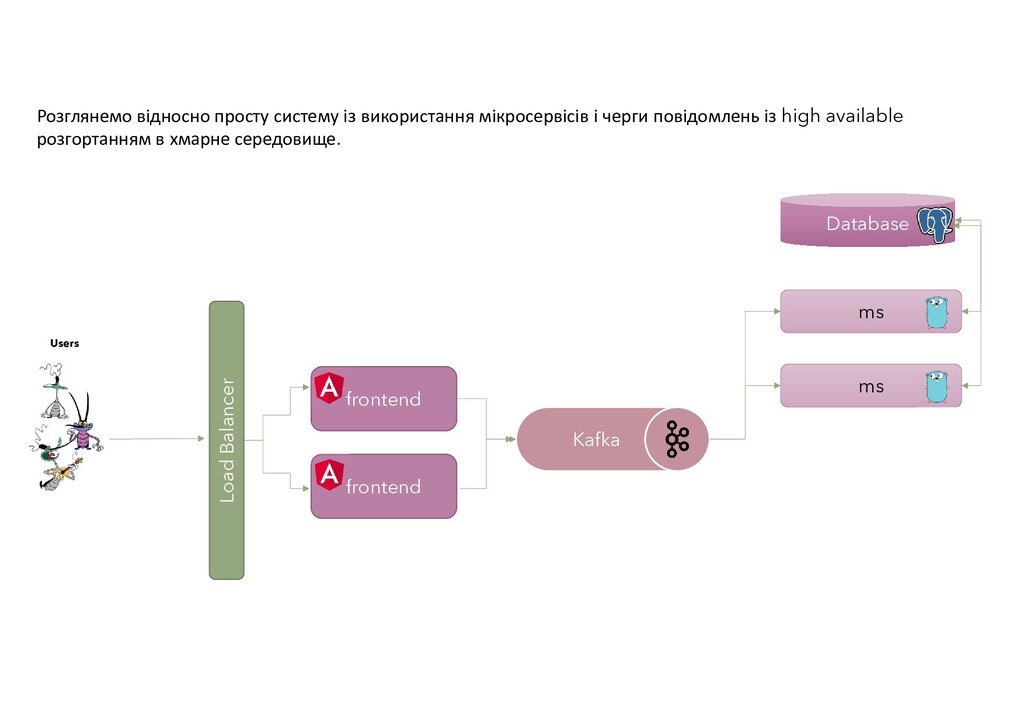{kind=link}
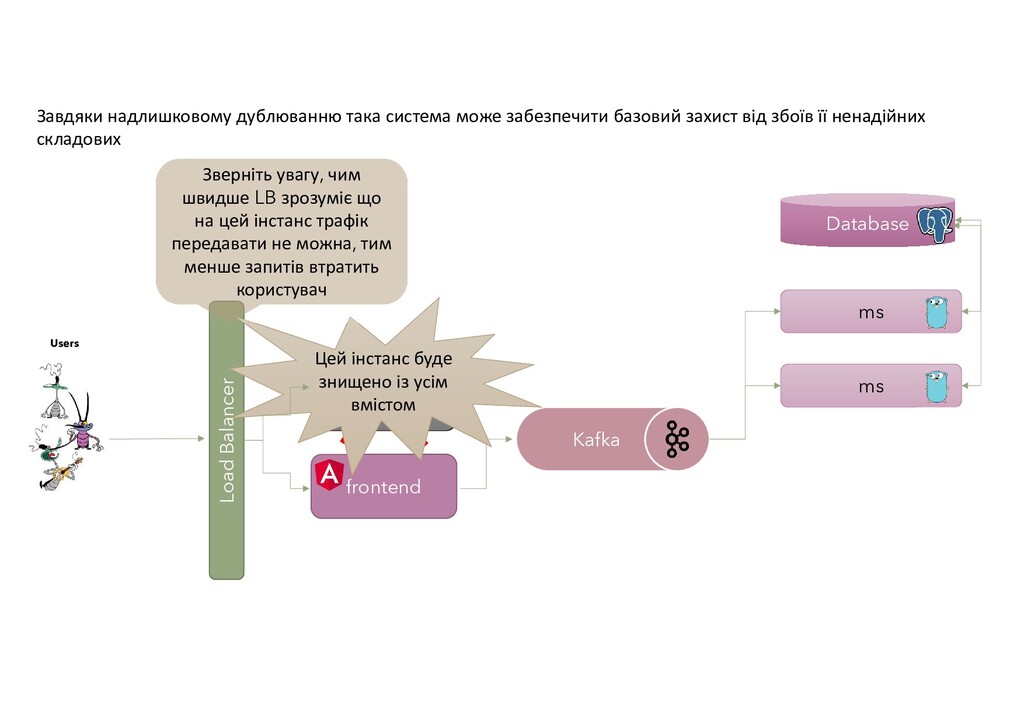{kind=link}
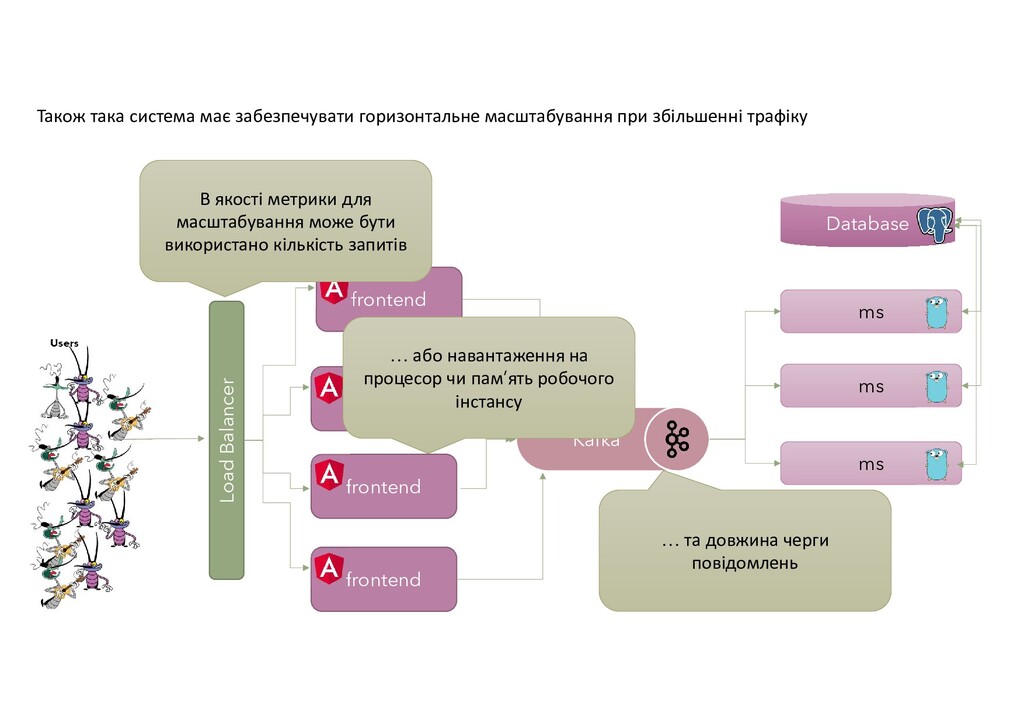{kind=link}
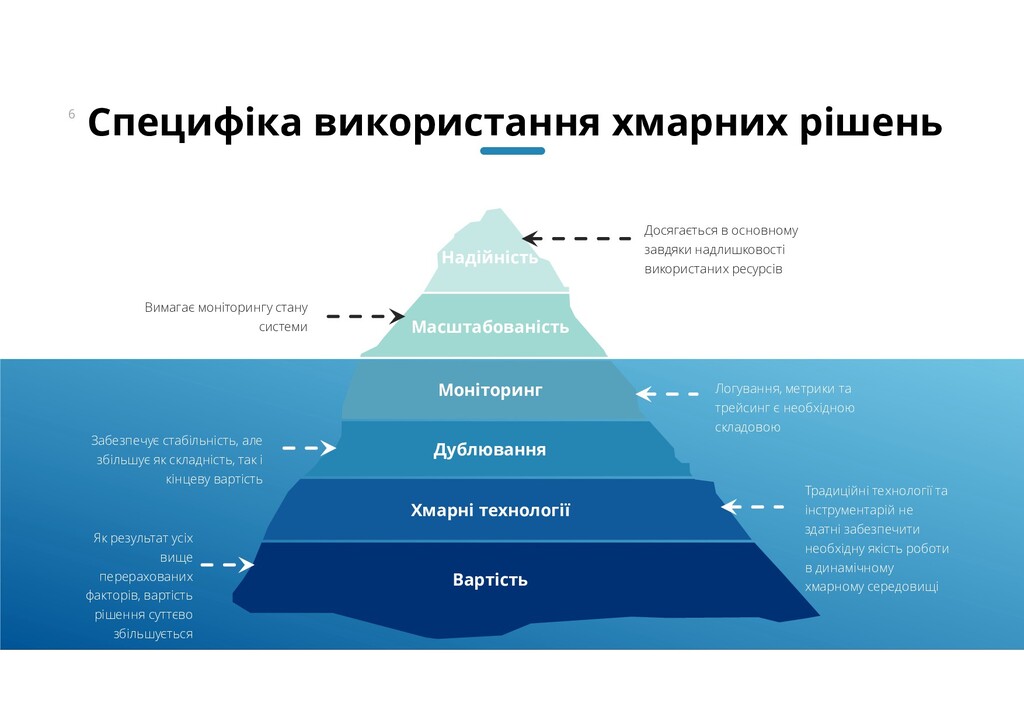{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}