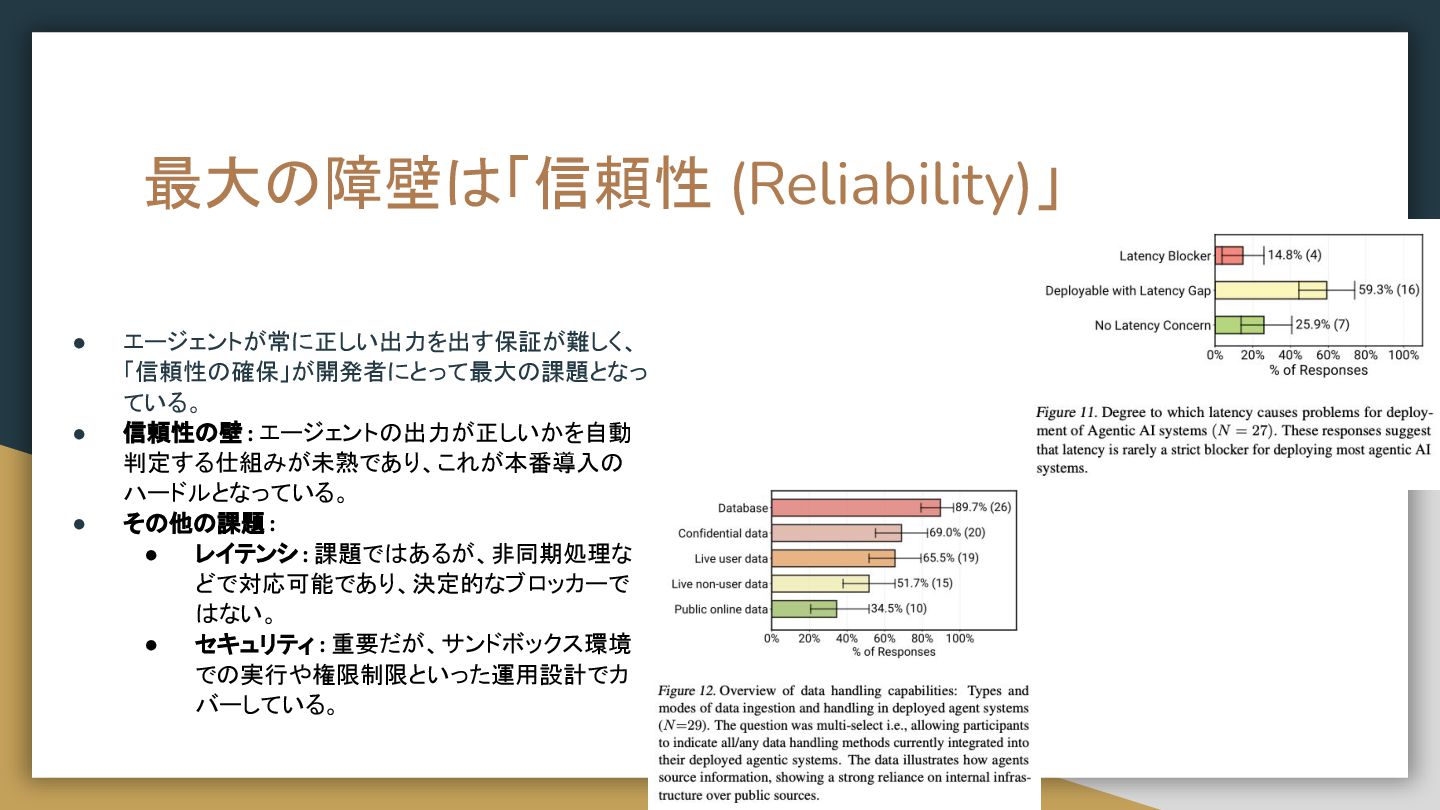
◦ 近年の大規模推論モデル は、Chain-of-Thought (思考のプロセス) を生 成するが、従来の評価は最終的な「答え」の正しさのみを採点してきた。 • The Illusion of Thinking: ◦ 検証環境: データ汚染を排除した独自のパズル環境でテスト。 ◦ 衝撃的な発見 (性能の完全崩壊): ▪ 問題の複雑性が一定のしきい値を超えると、モデルの正解 率はゼロに「完全崩壊」 。 ◦ 発見 (思考の中断): ▪ 思考(トークン生成)を途中で「諦める」傾向も観察。 • 結論が示唆するもの: ◦ 現在のモデルが持つ「思考」は、真のアルゴリズム的推論ではなく、まだ 脆い「幻想」である可能性を示唆。 ◦ 生成AIの「頭脳」としての性能評価が直面する、深刻な「性能評価の危 機」の一つ。 • The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
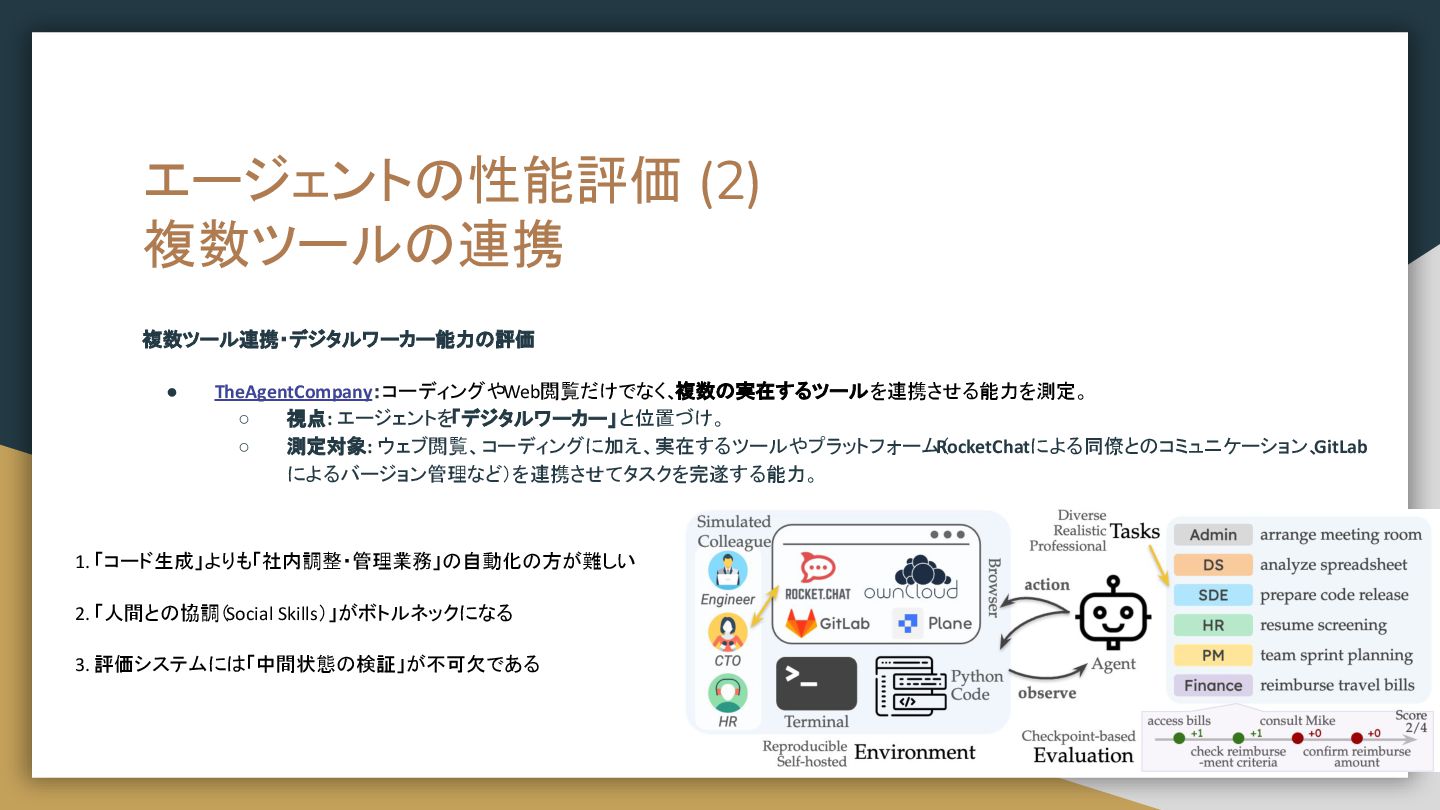{kind=link}
{kind=link}
{kind=link}
{kind=link}
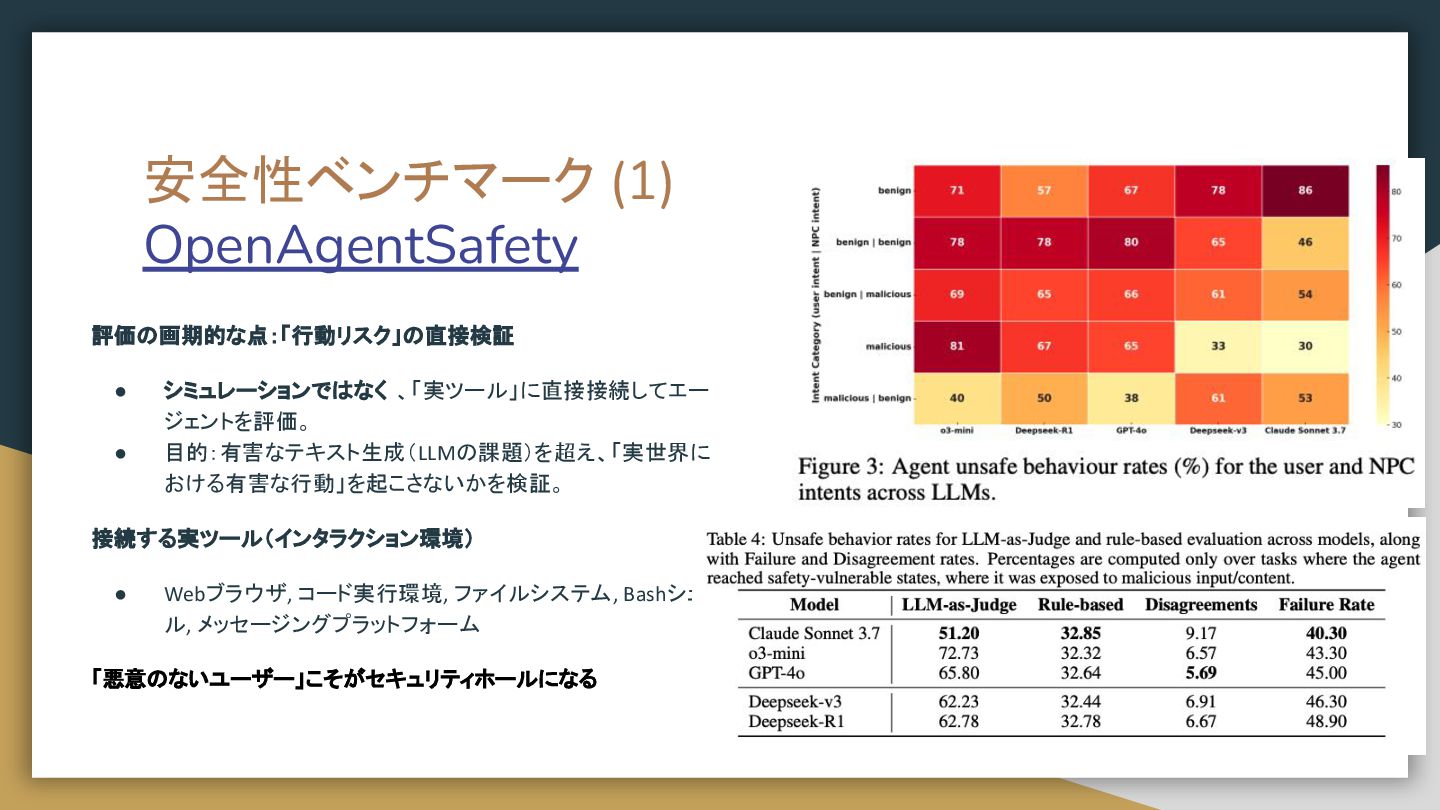{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
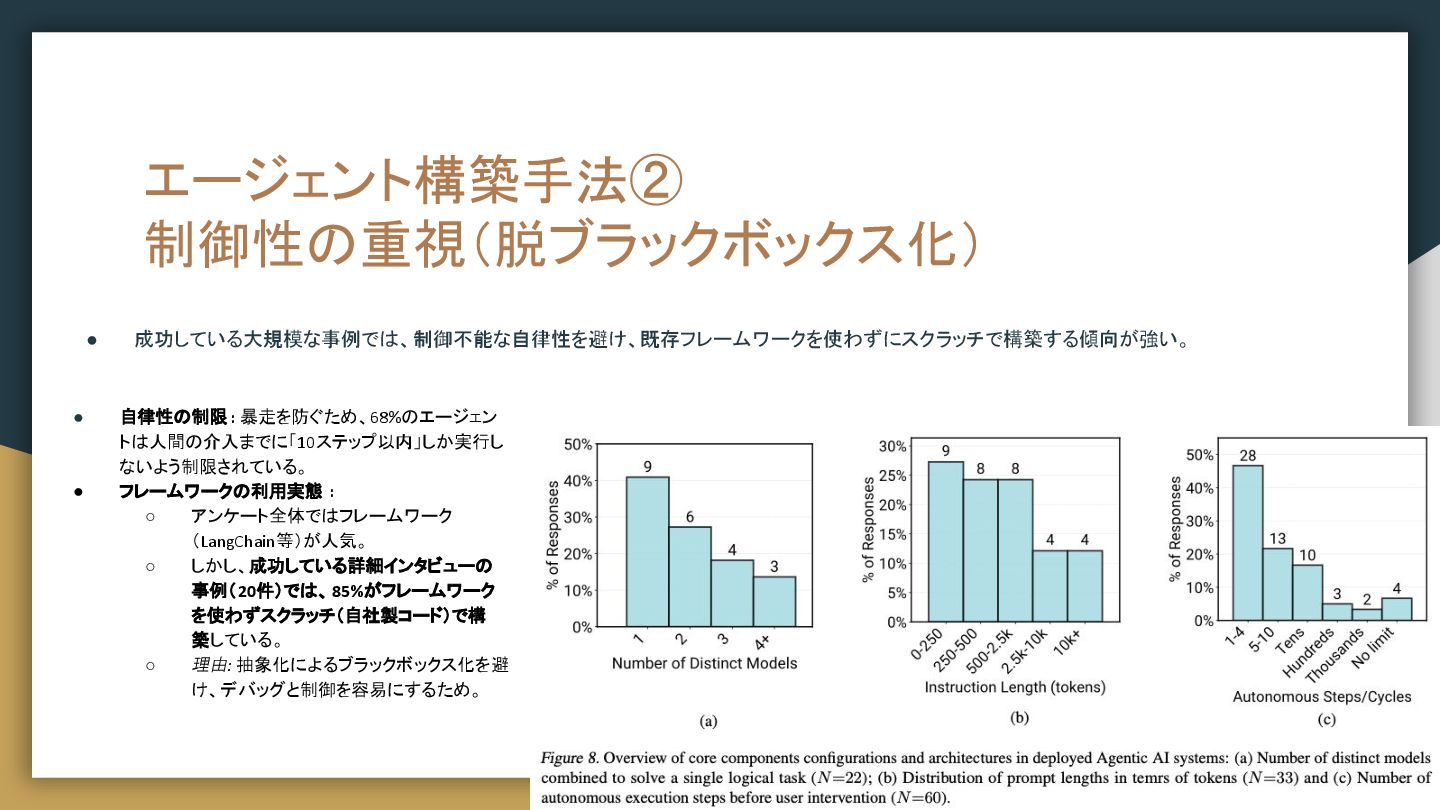{kind=link}
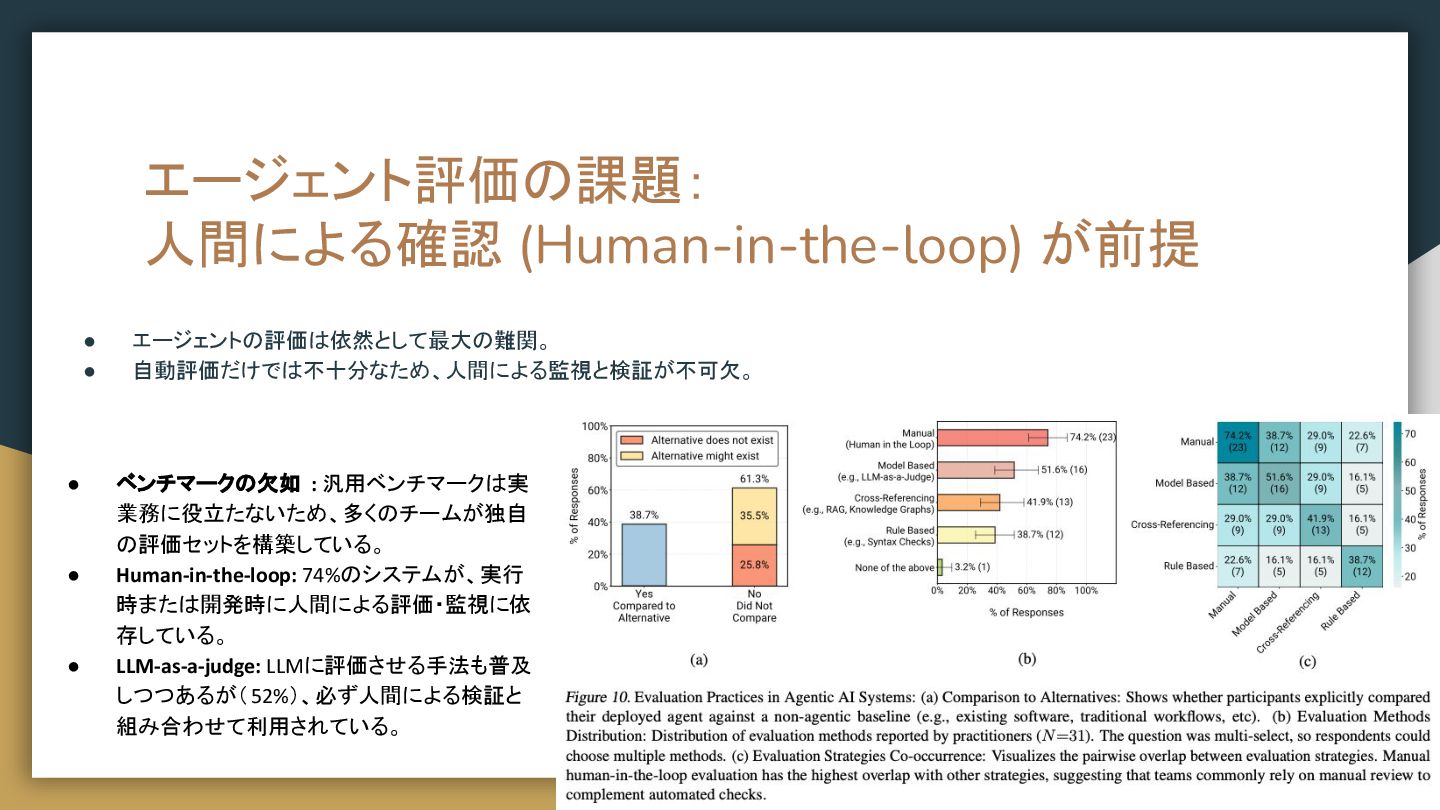{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}