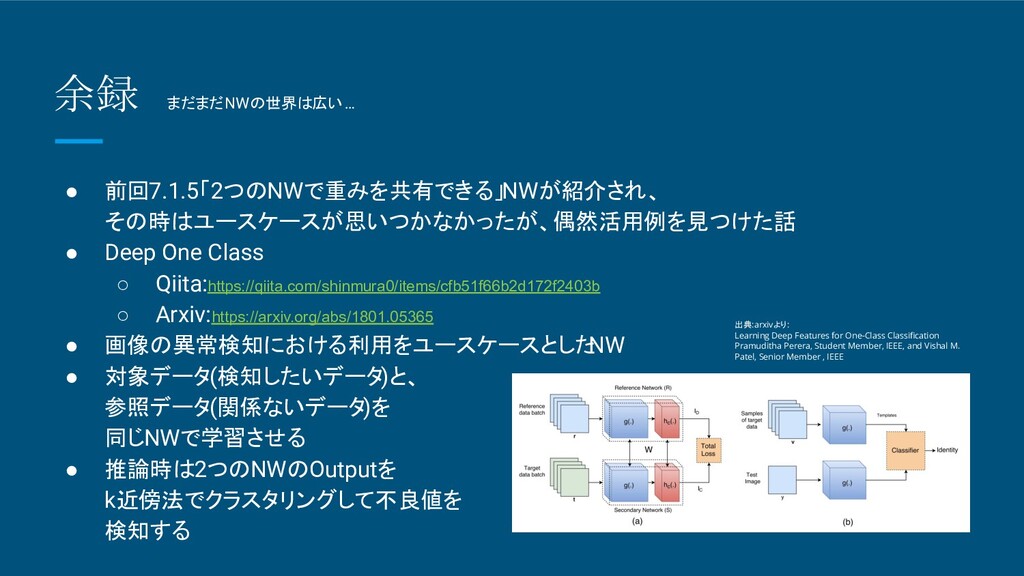
◦ Arxiv:https://arxiv.org/abs/1801.05365 • 画像の異常検知における利用をユースケースとした NW • 対象データ(検知したいデータ)と、 参照データ(関係ないデータ)を 同じNWで学習させる • 推論時は2つのNWのOutputを k近傍法でクラスタリングして不良値を 検知する 出典:arxivより: Learning Deep Features for One-Class Classification Pramuditha Perera, Student Member, IEEE, and Vishal M. Patel, Senior Member , IEEE
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}