Share
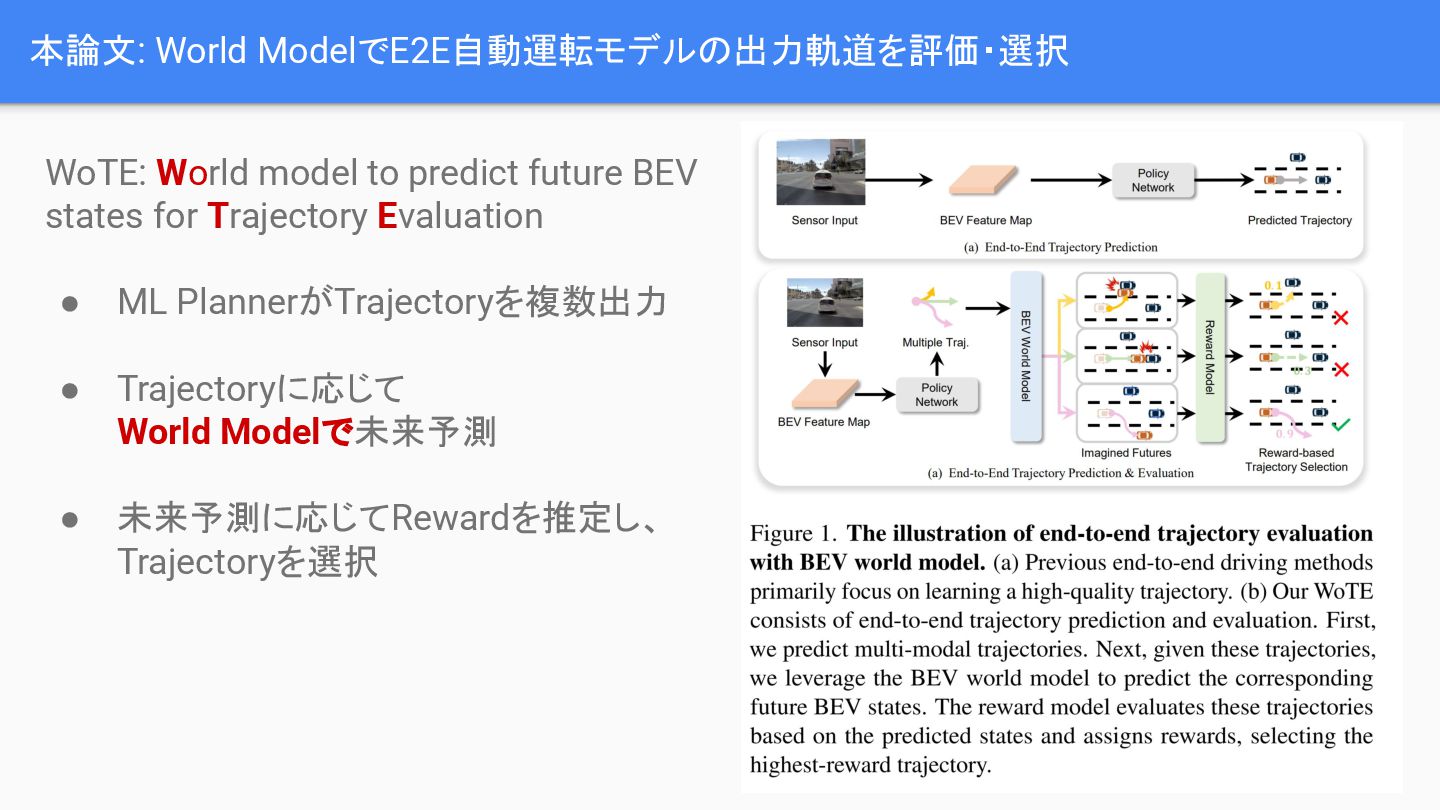
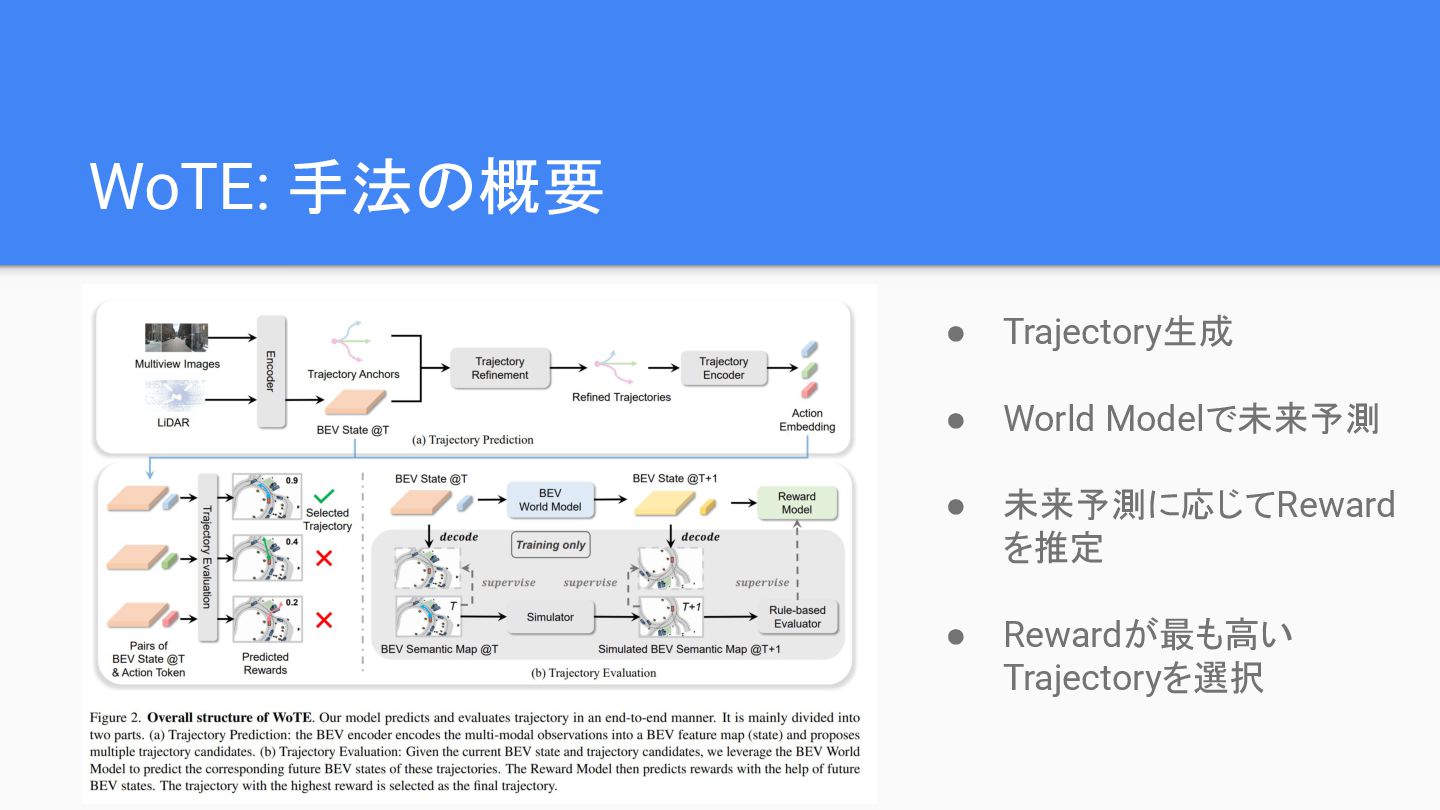
2025/11/16 関東CV勉強会の資料です。 End-to-end自動運転modelの出力を、走りながら世界モデルで評価する論文です。
参考link - code: https://github.com/liyingyanUCAS/WoTE - arxiv: https://arxiv.org/abs/2504.01941 - 関東CV勉強会: https://kantocv.connpass.com/event/373217/
{kind=link}
{kind=link}
{kind=link}
![[背景] E2E自動運転が注目され、目覚ましい発展を遂げている • Sensor data(e.g.画像),ego status(過去のtrajectory), Commandからtrajectoryを直接生成する model • データから,交通ルールを遵守した行動,衝突回避のための行動を学習させる](https://files.speakerdeck.com/presentations/e9ae4fb2a86746a6aa2b60ce3caad37c/slide_3.jpg){kind=link}
![[背景] E2E自動運転が注目され、目覚ましい発展を遂げている https://x.com/Tesla/status/1989427425508561398?s=20 例: Tesla FSD v14 • 犬が飛び出してくるのを予測してSlow down](https://files.speakerdeck.com/presentations/e9ae4fb2a86746a6aa2b60ce3caad37c/slide_4.jpg){kind=link}
![[背景] しかし、ML based plannerを仕上げるのはそう簡単ではない • MLあるあるだが、データ量が少ない状態では、適切な挙動の実現が難しい ◦ データが少ない状態では、「横断歩道で減速」「横断歩道で待つ」といった挙動ができない場合がある • 学習できていない状況では適切な出力が出ないかもしれない](https://files.speakerdeck.com/presentations/e9ae4fb2a86746a6aa2b60ce3caad37c/slide_5.jpg){kind=link}
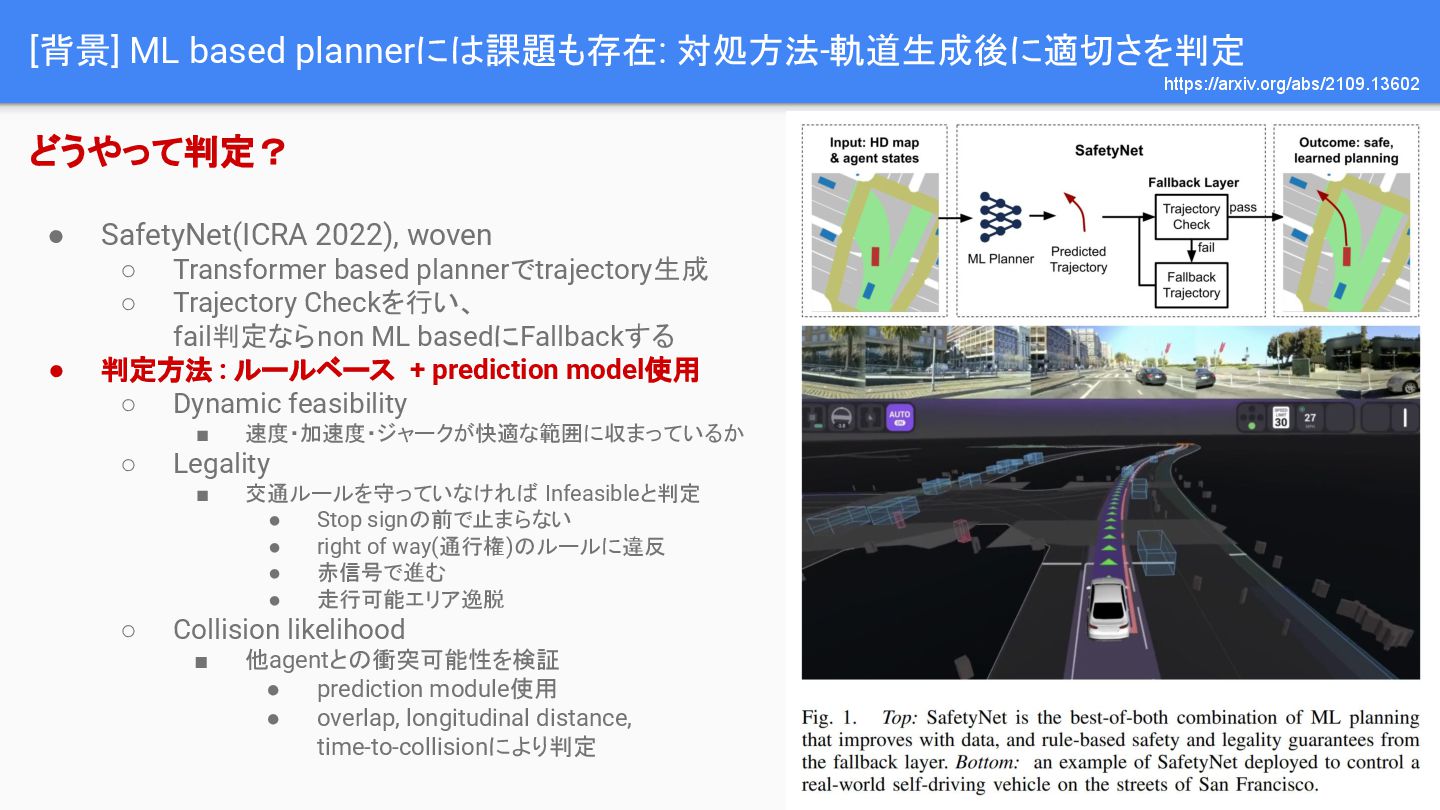
![[背景] 未学習の状況では適切な出力が出ないかも: 対処方法-軌道生成後に適切さを判定 • 学習できていない状況では適切な出力が出ないかもしれない • 出力をいつでも信用できるわけではないので、 軌道生成後に軌道が適切かを判定するという対処方法が存在 https://github.com/orgs/autowarefoundation/discussions/5033 ◀](https://files.speakerdeck.com/presentations/e9ae4fb2a86746a6aa2b60ce3caad37c/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
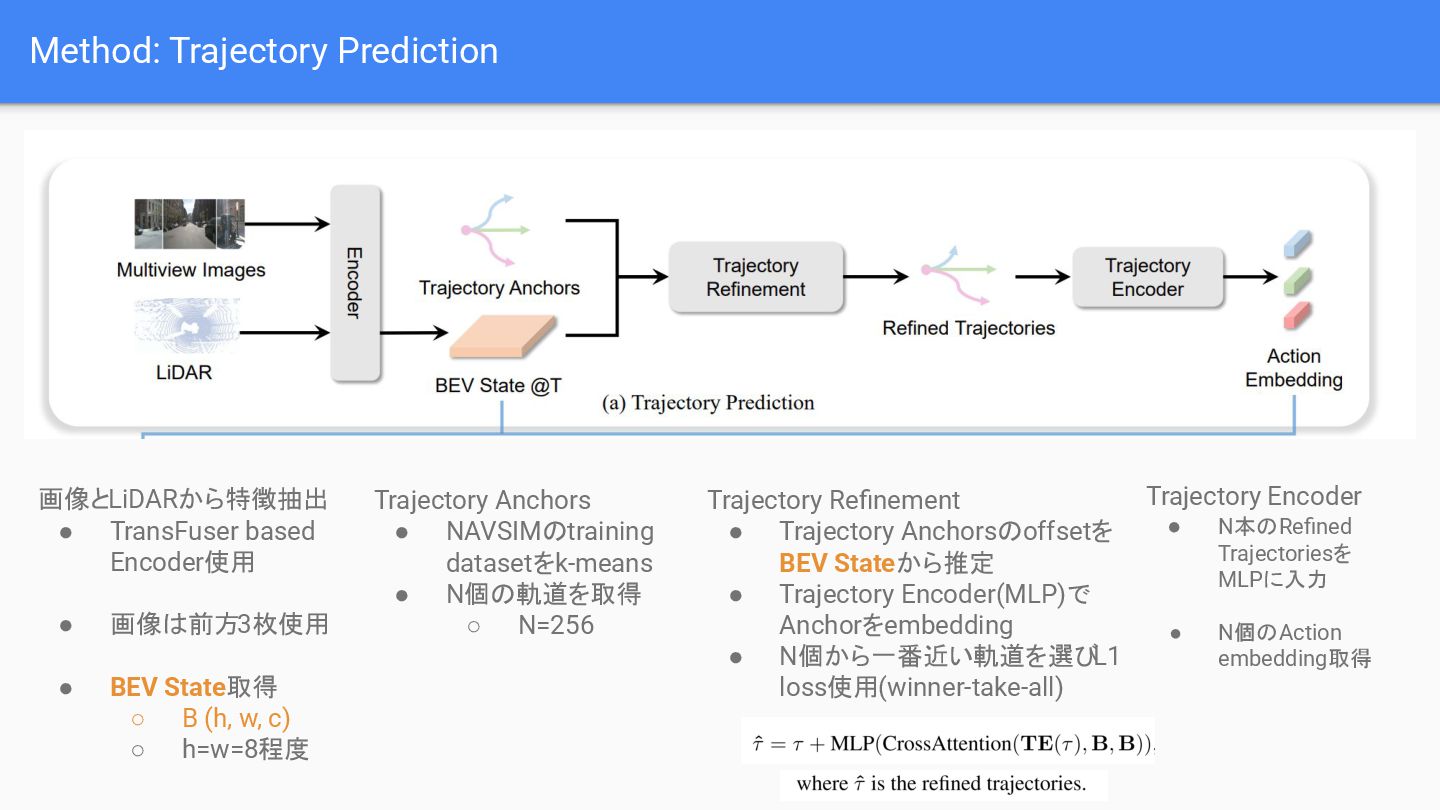{kind=link}
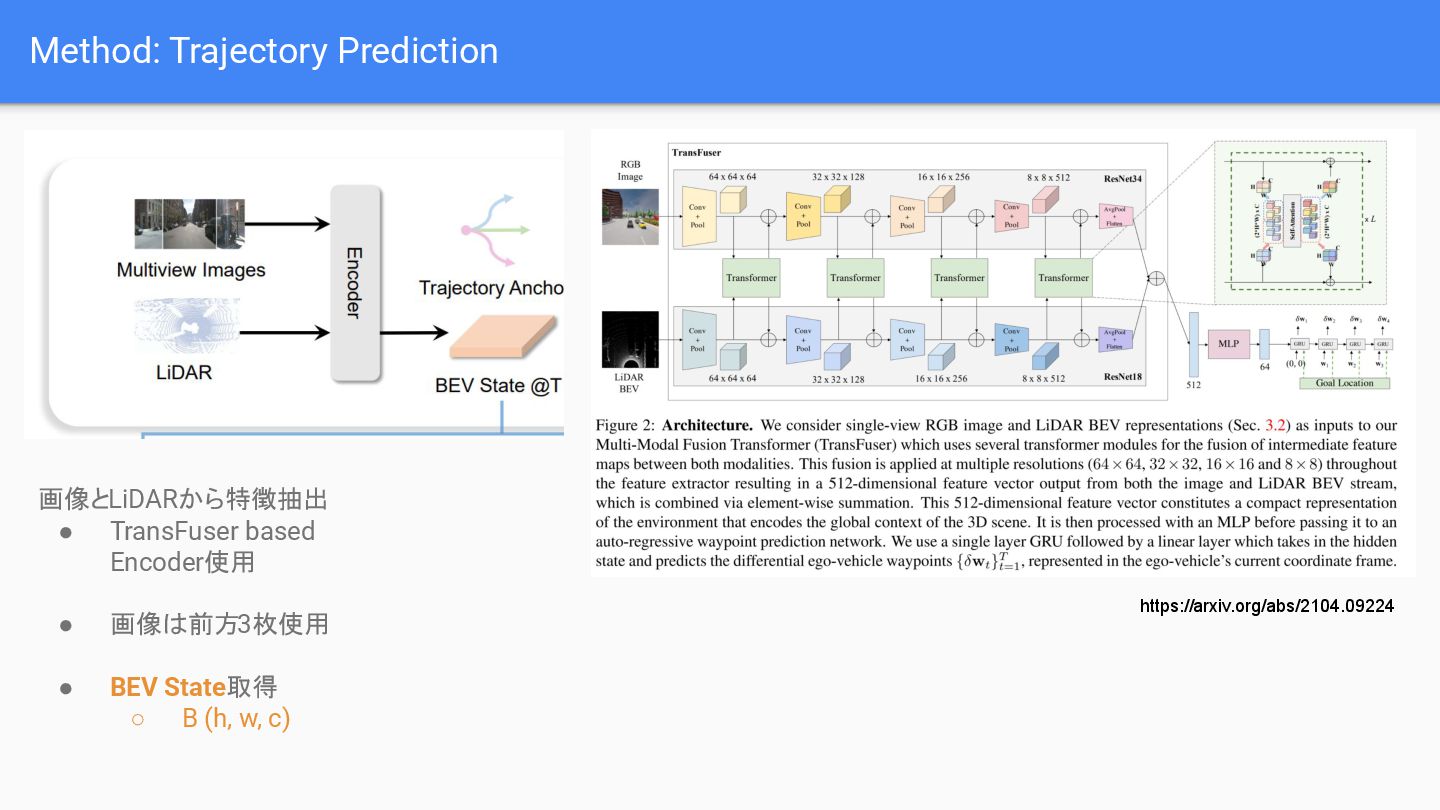{kind=link}
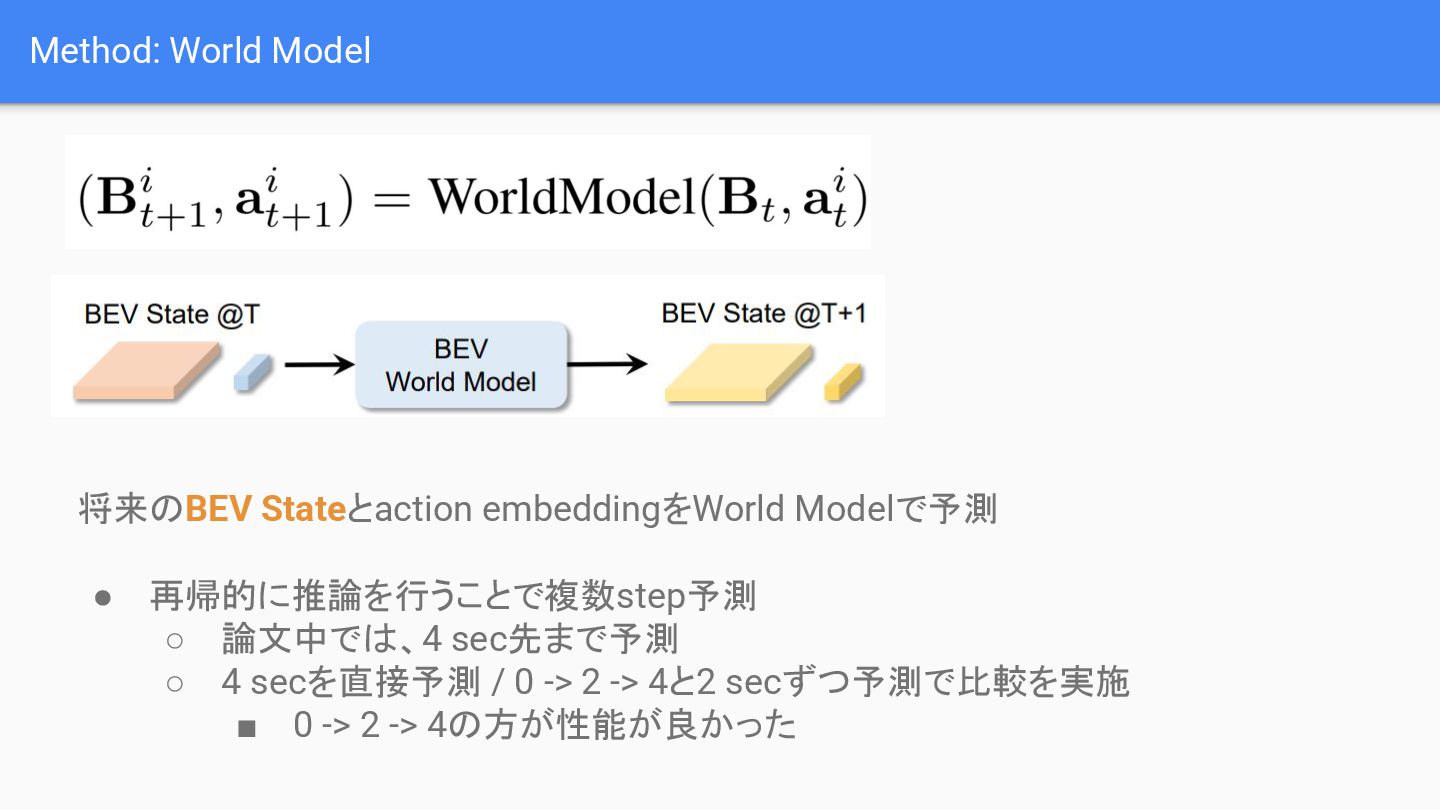{kind=link}
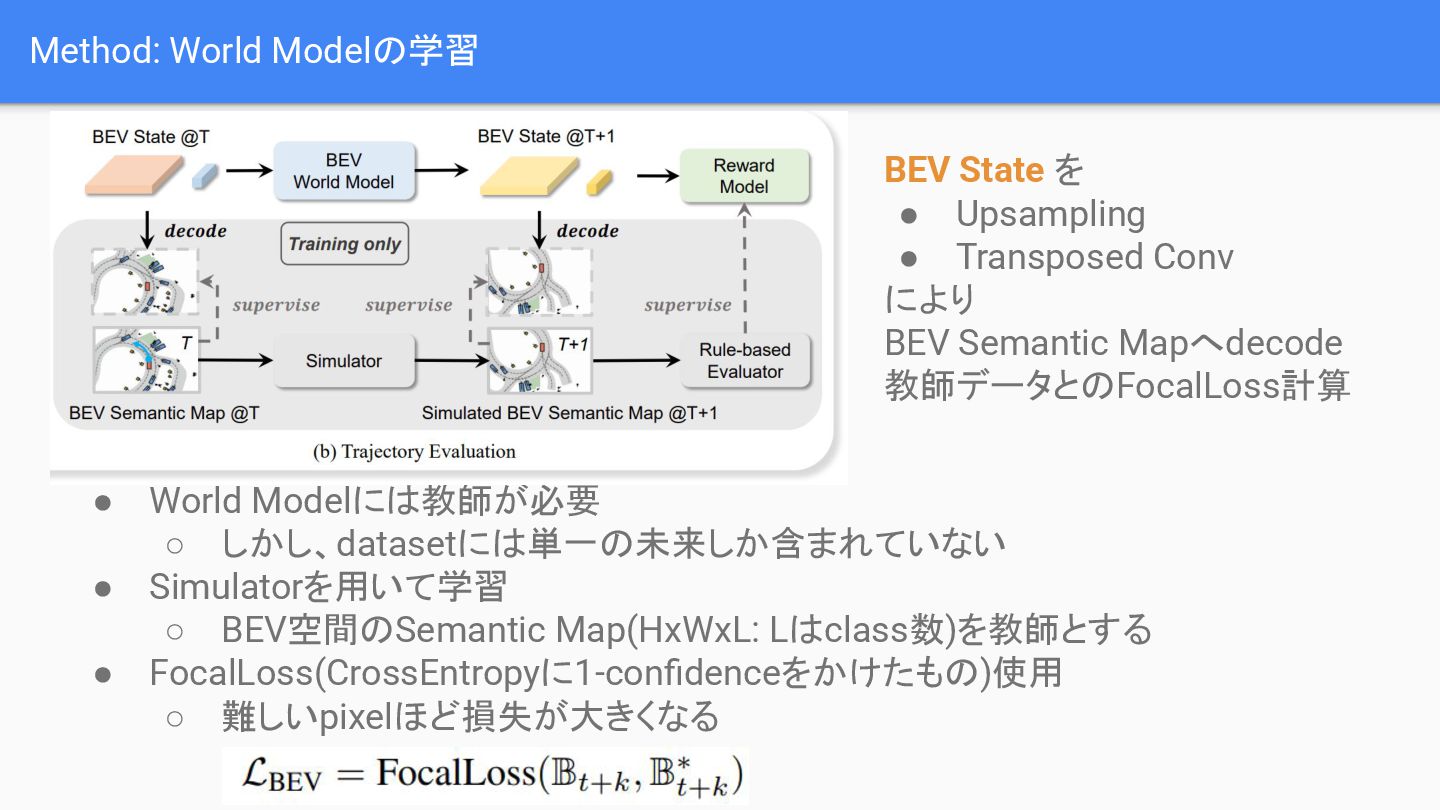{kind=link}
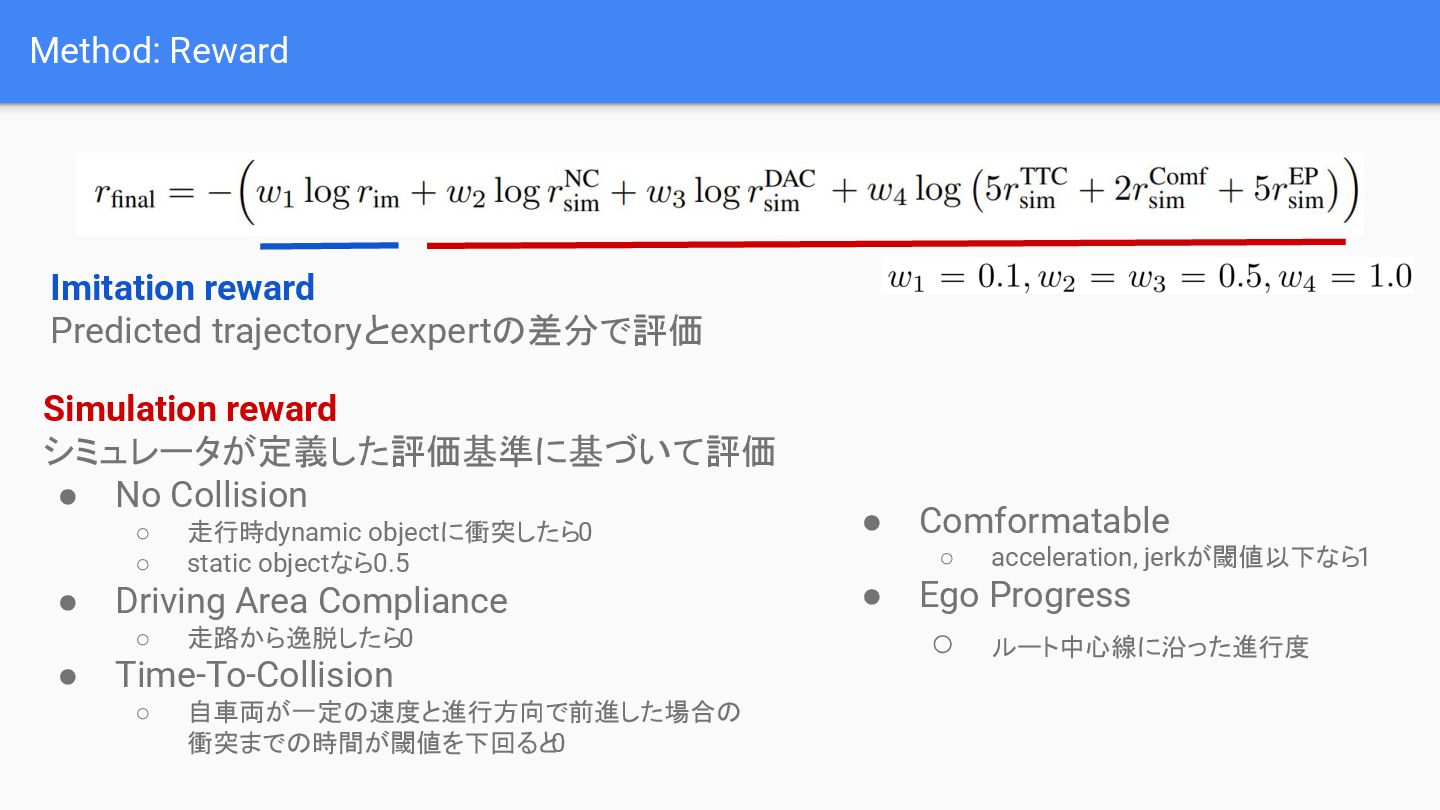{kind=link}
{kind=link}
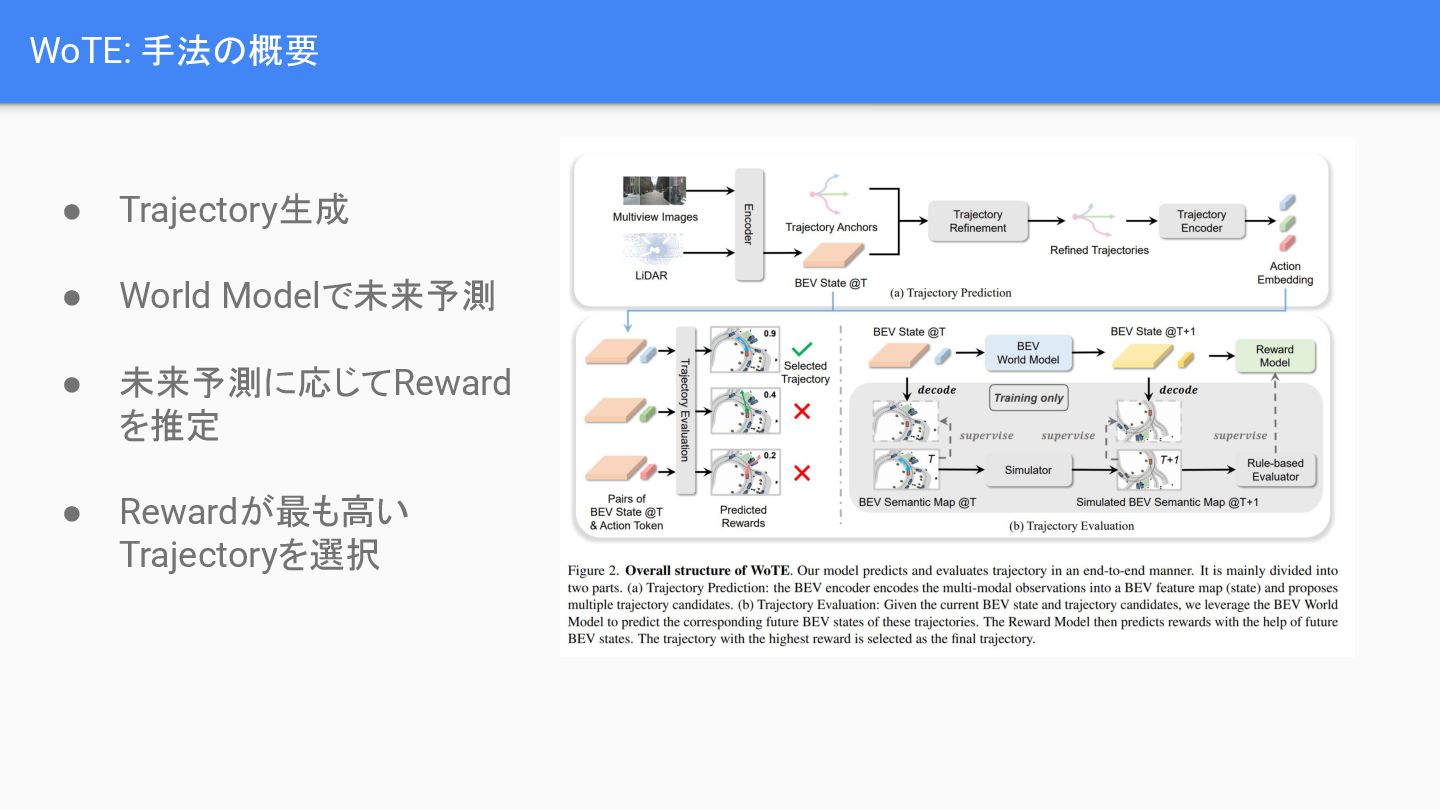{kind=link}
{kind=link}
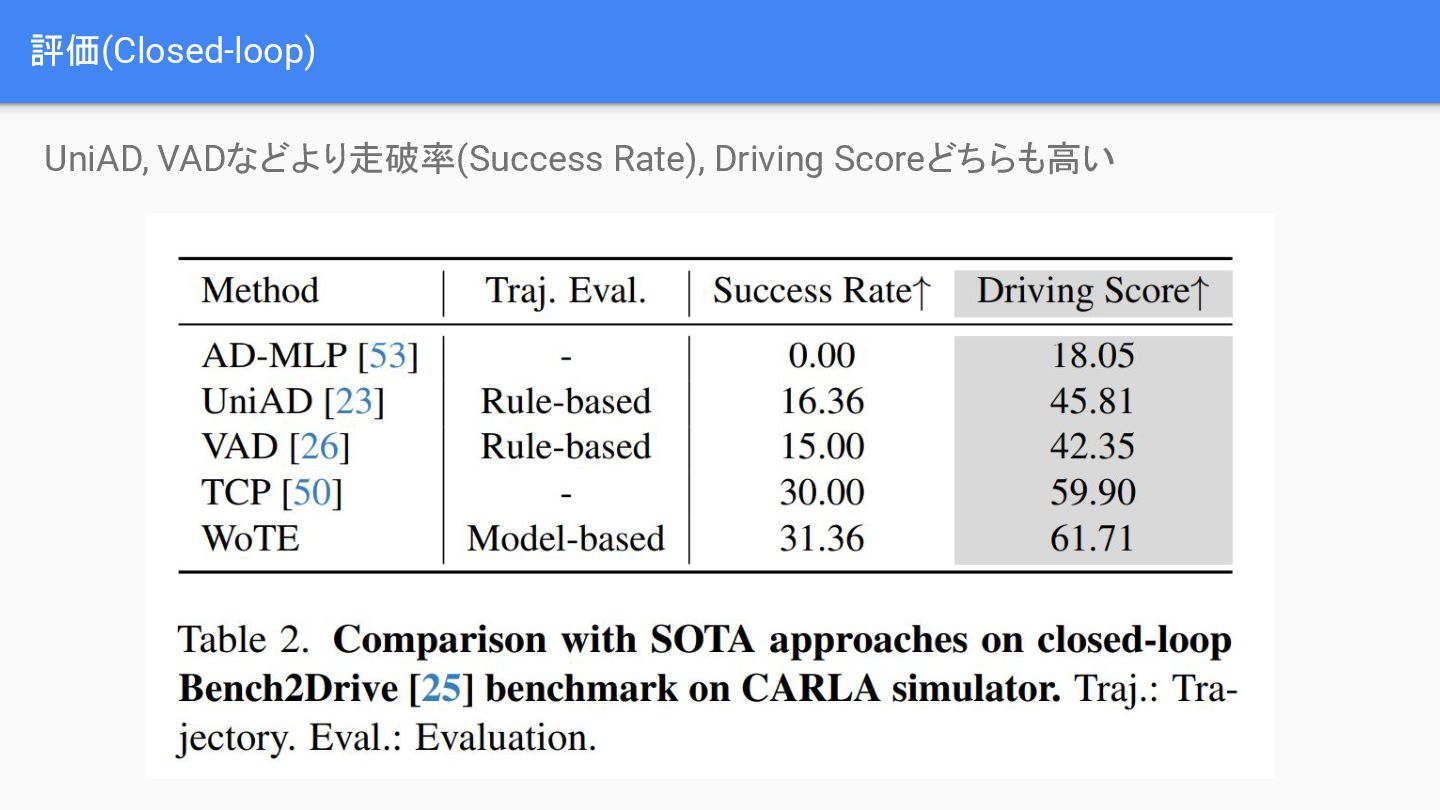{kind=link}
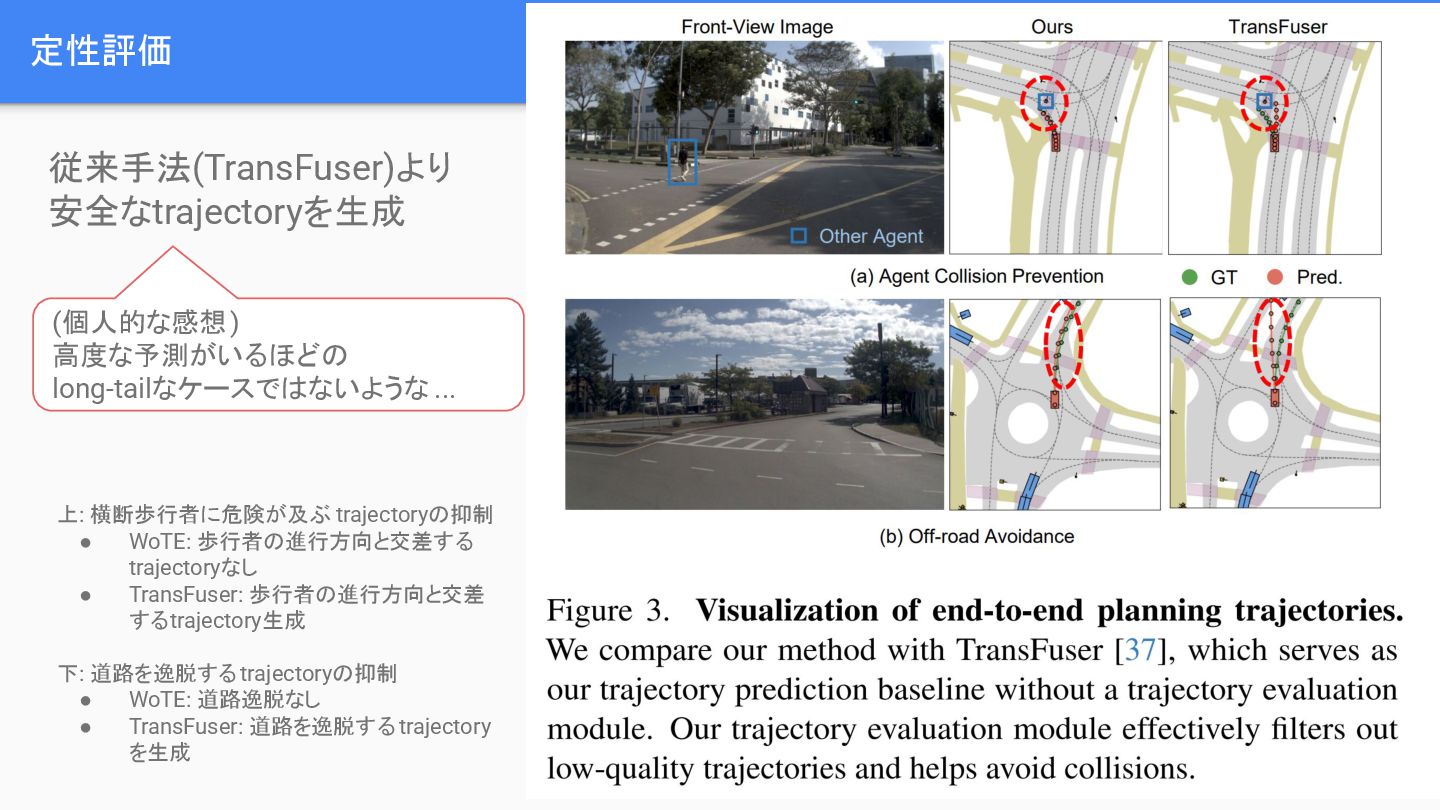{kind=link}
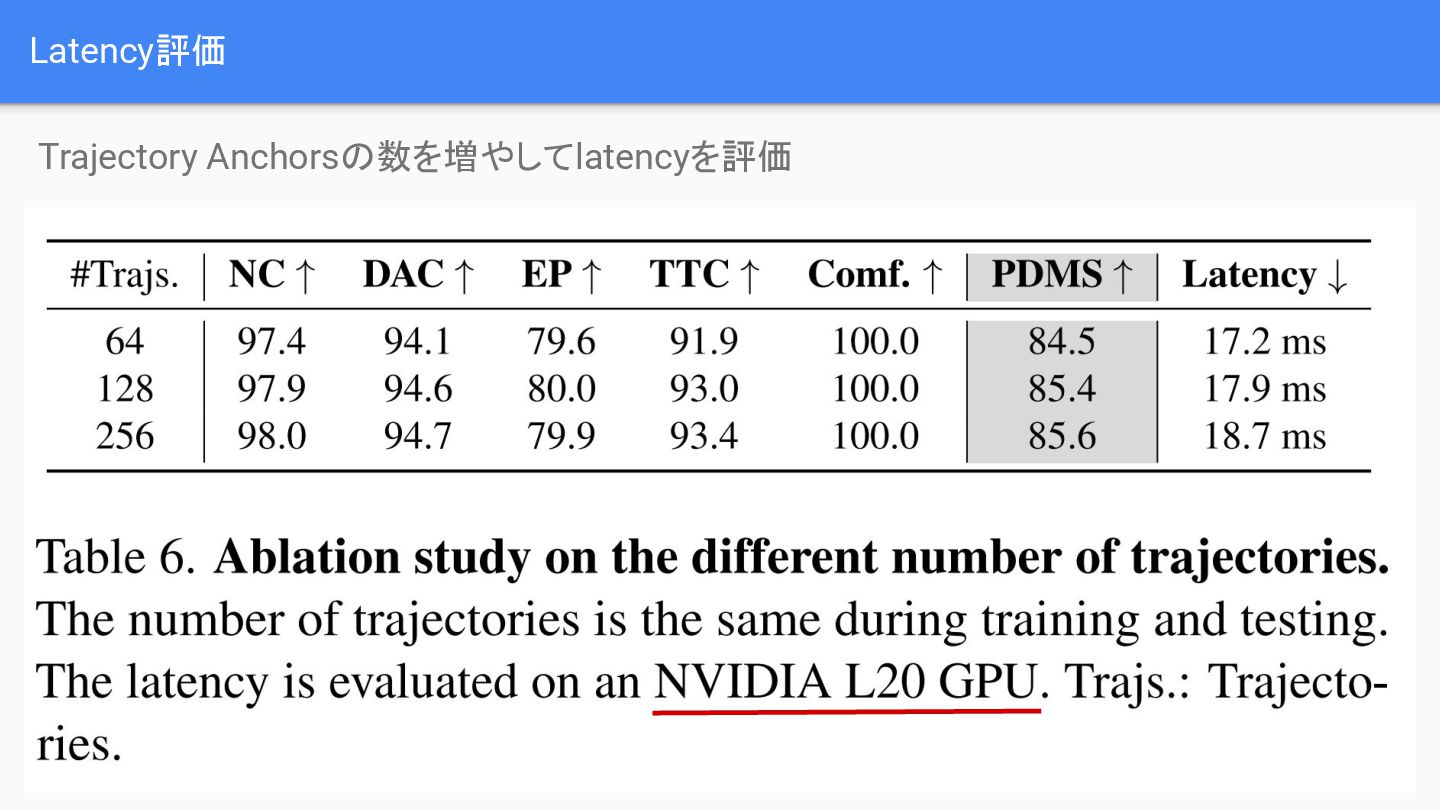{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
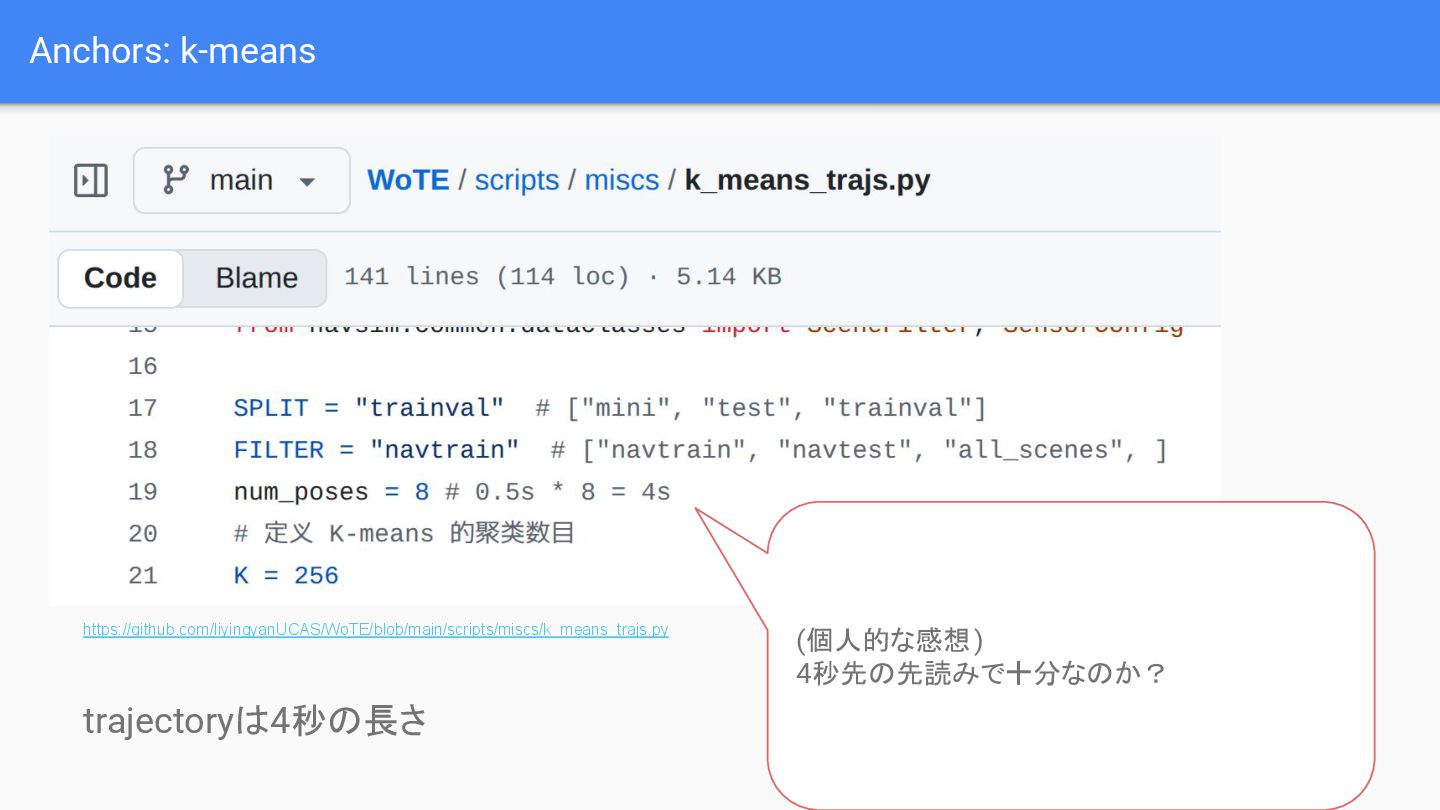{kind=link}
{kind=link}
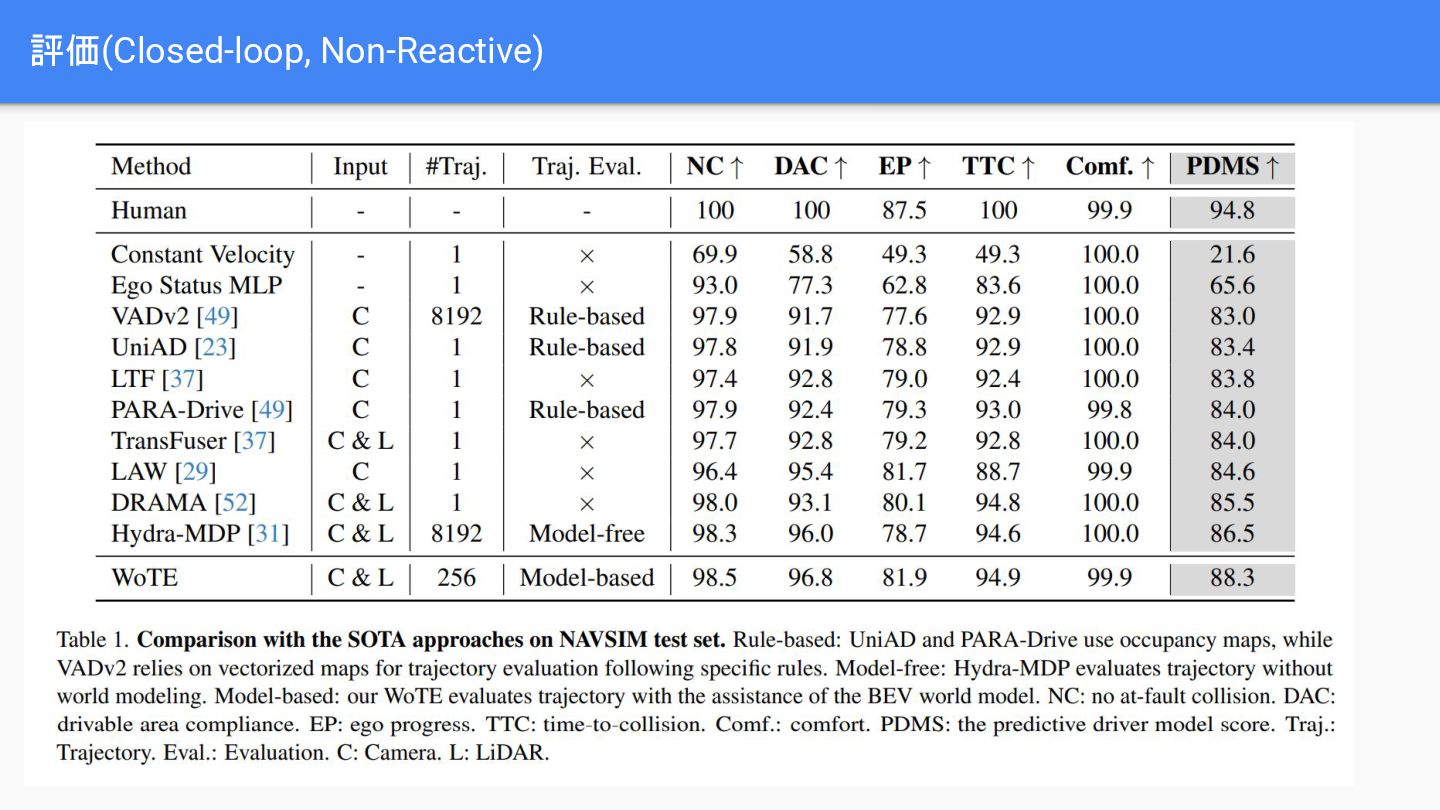{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
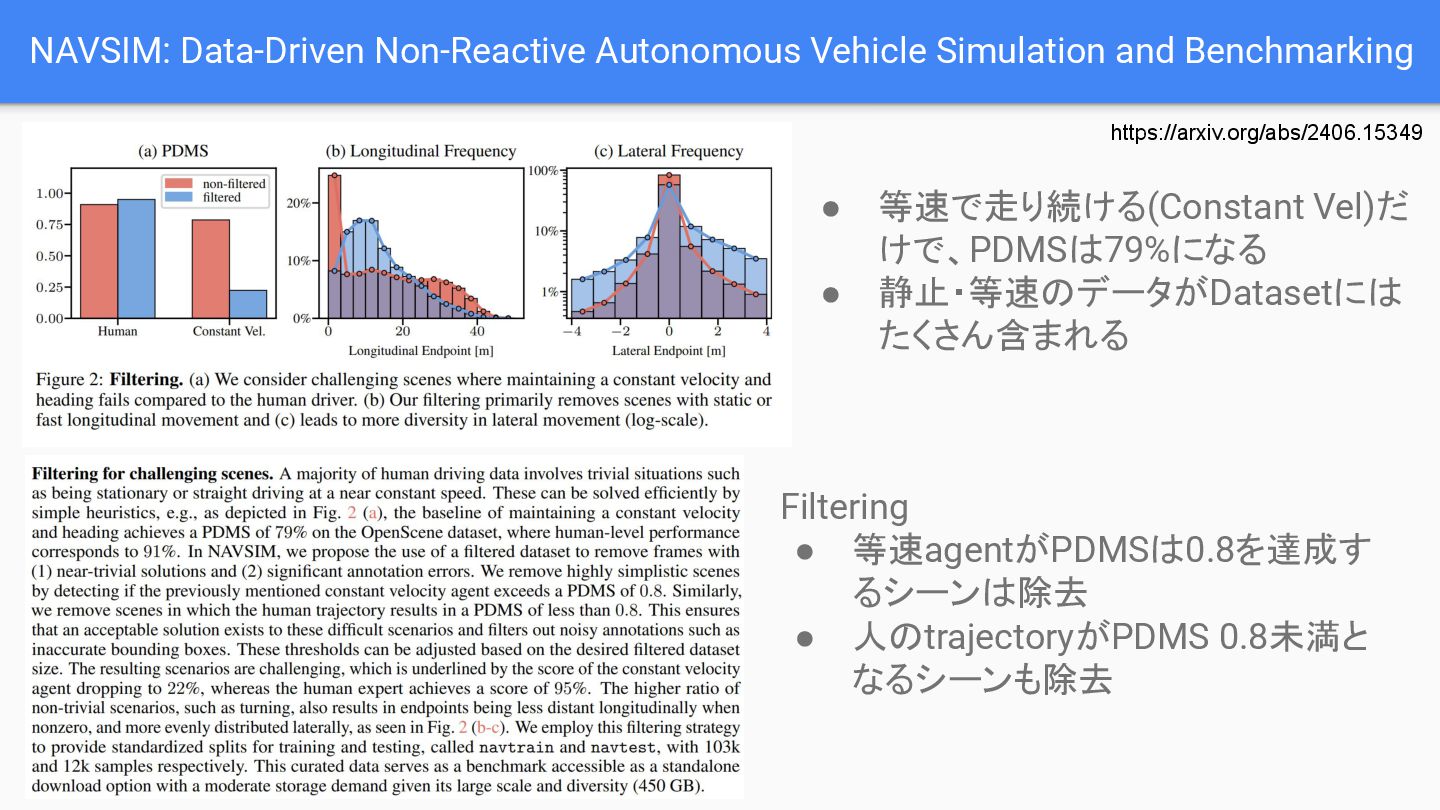{kind=link}
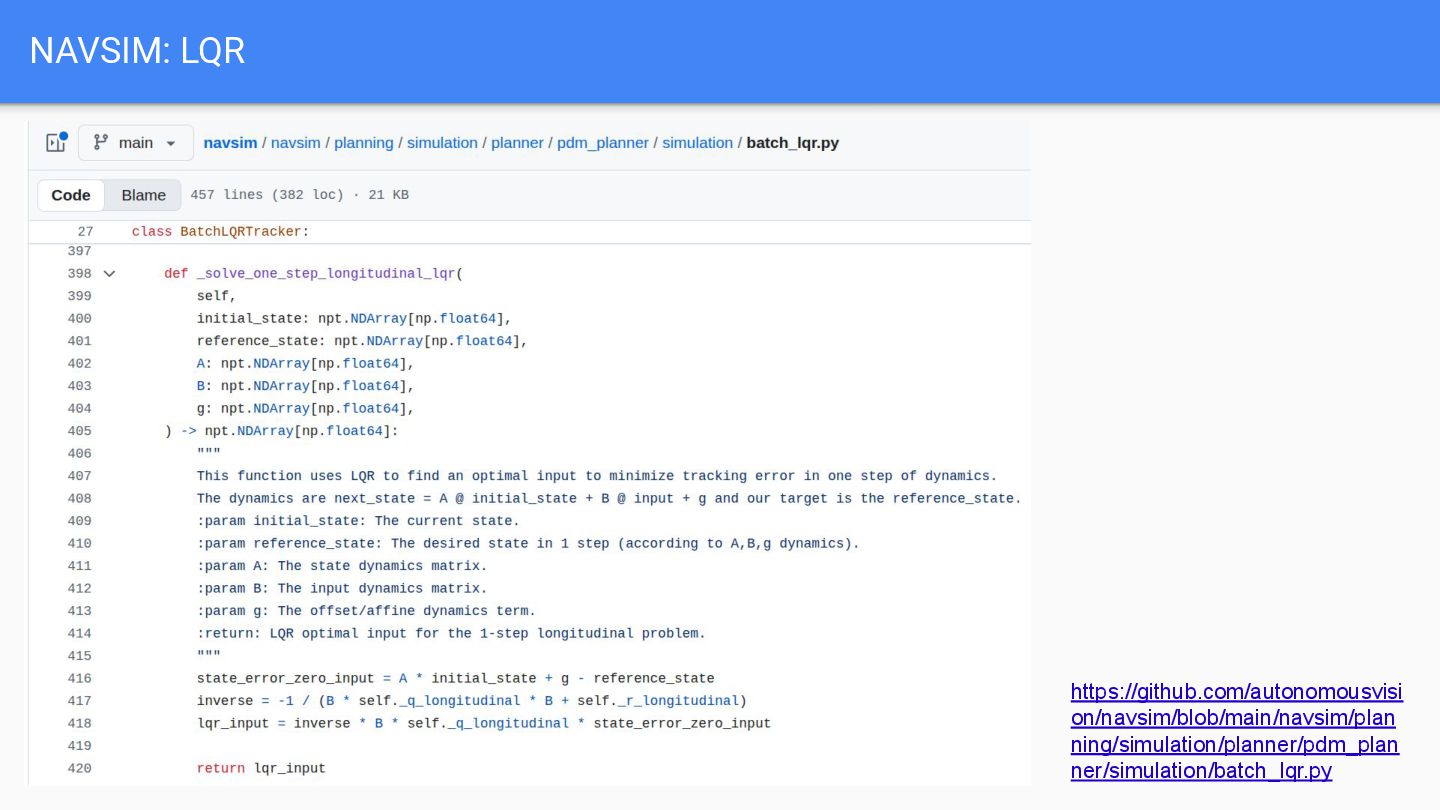{kind=link}
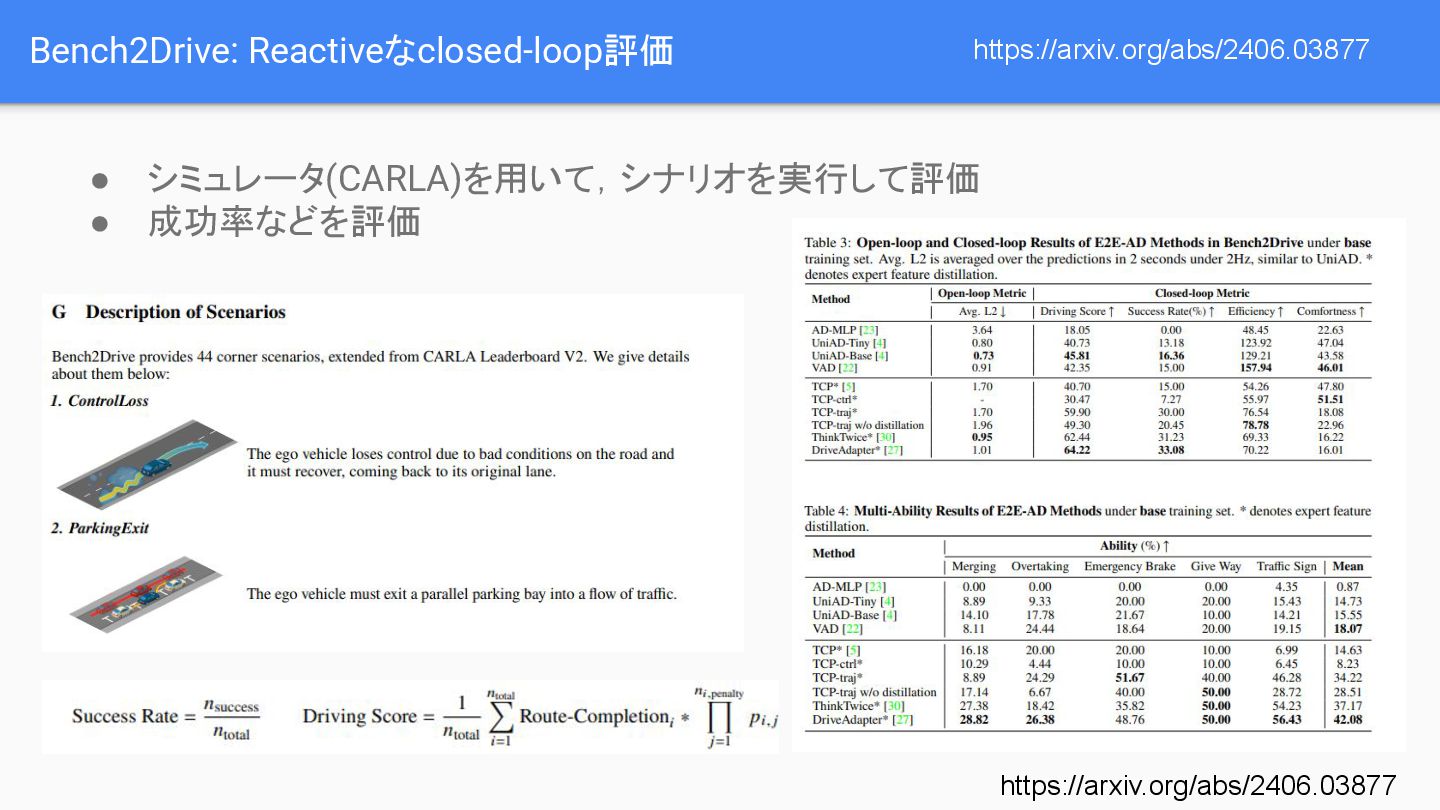{kind=link}
{kind=link}
{kind=link}
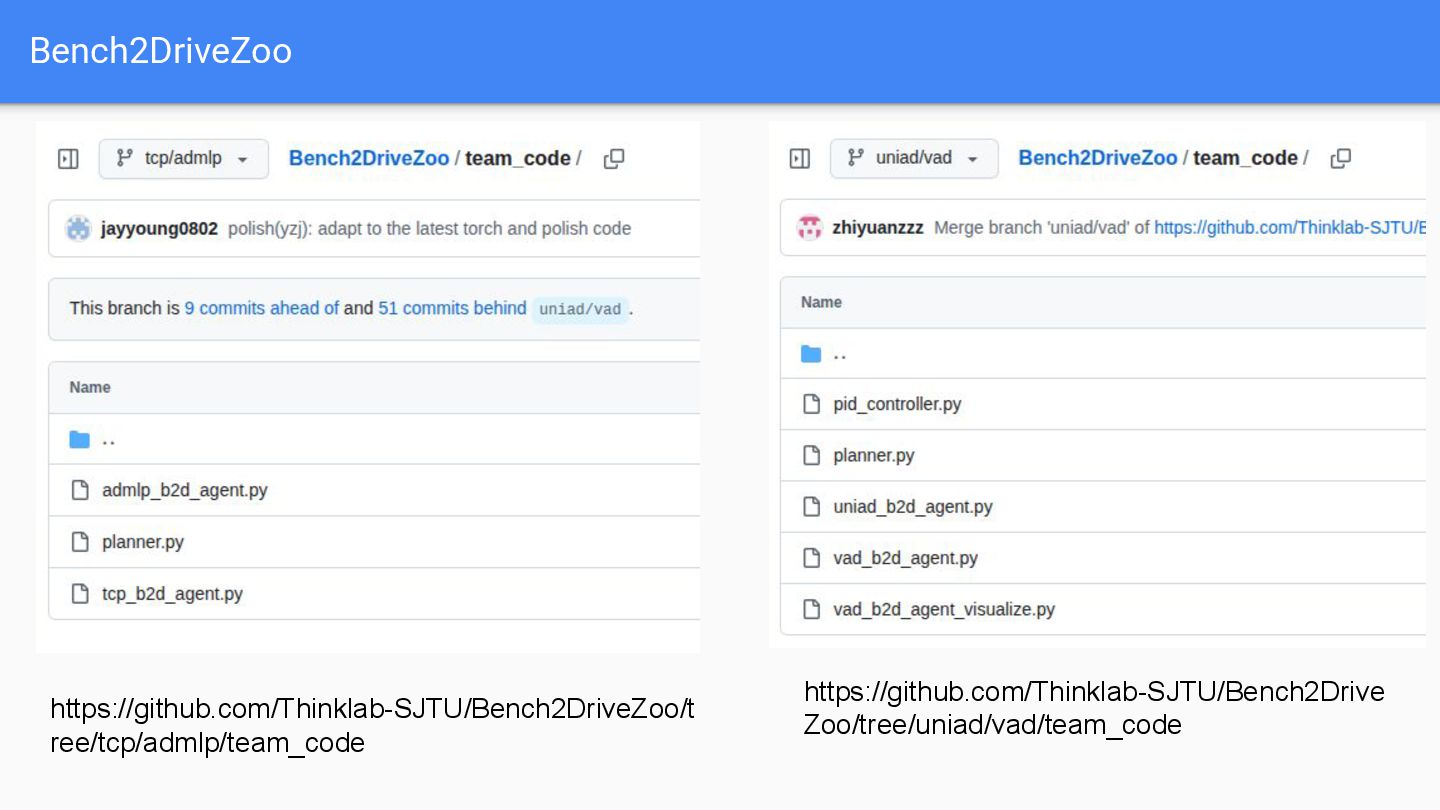{kind=link}
{kind=link}