Share
JAZUG Shizuoka #3にて発表した資料です。 https://jazug.connpass.com/event/368296/
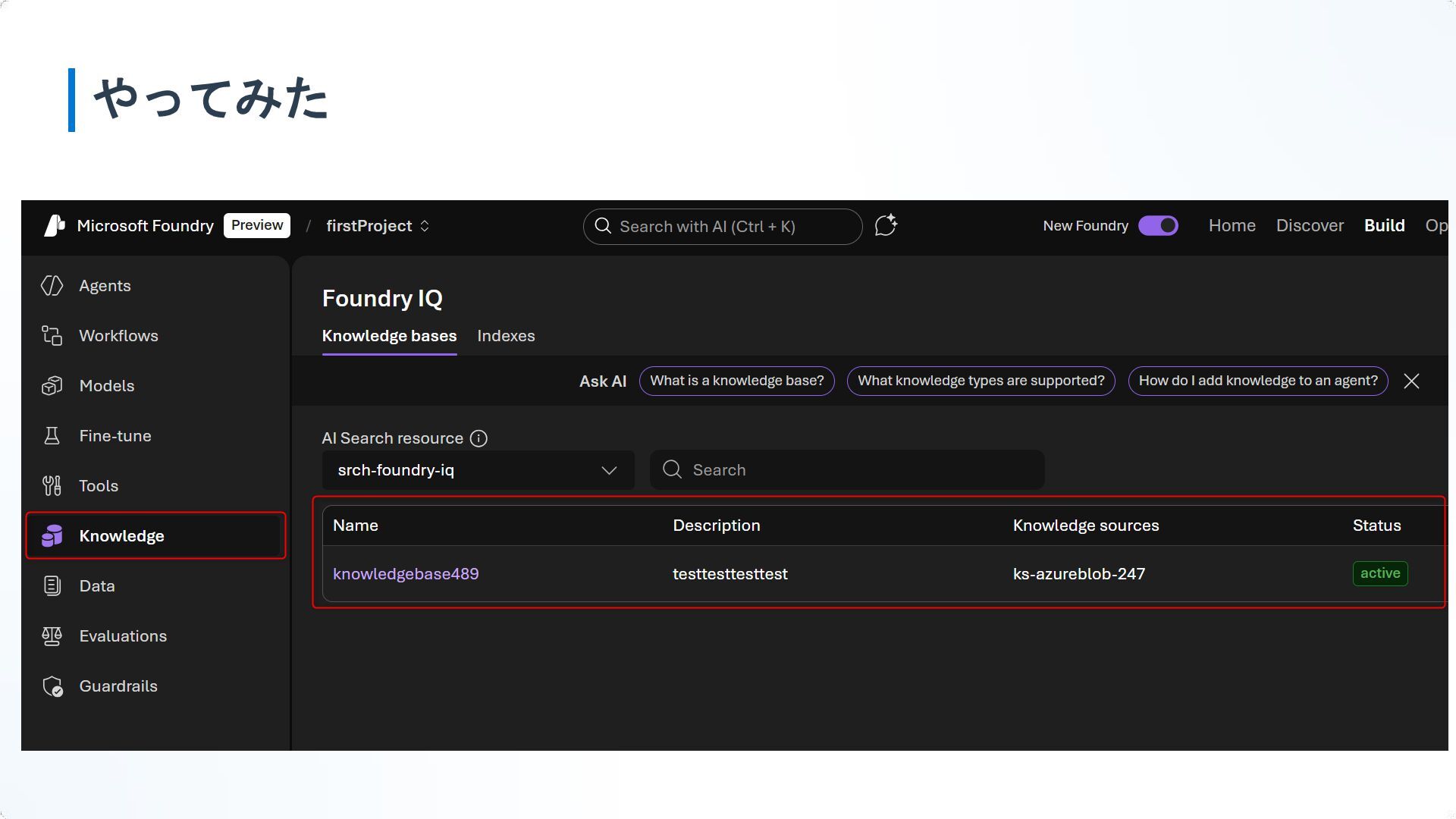
Miscrosoft Ignite 2025で発表されたFoundry IQについて内容をまとめました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
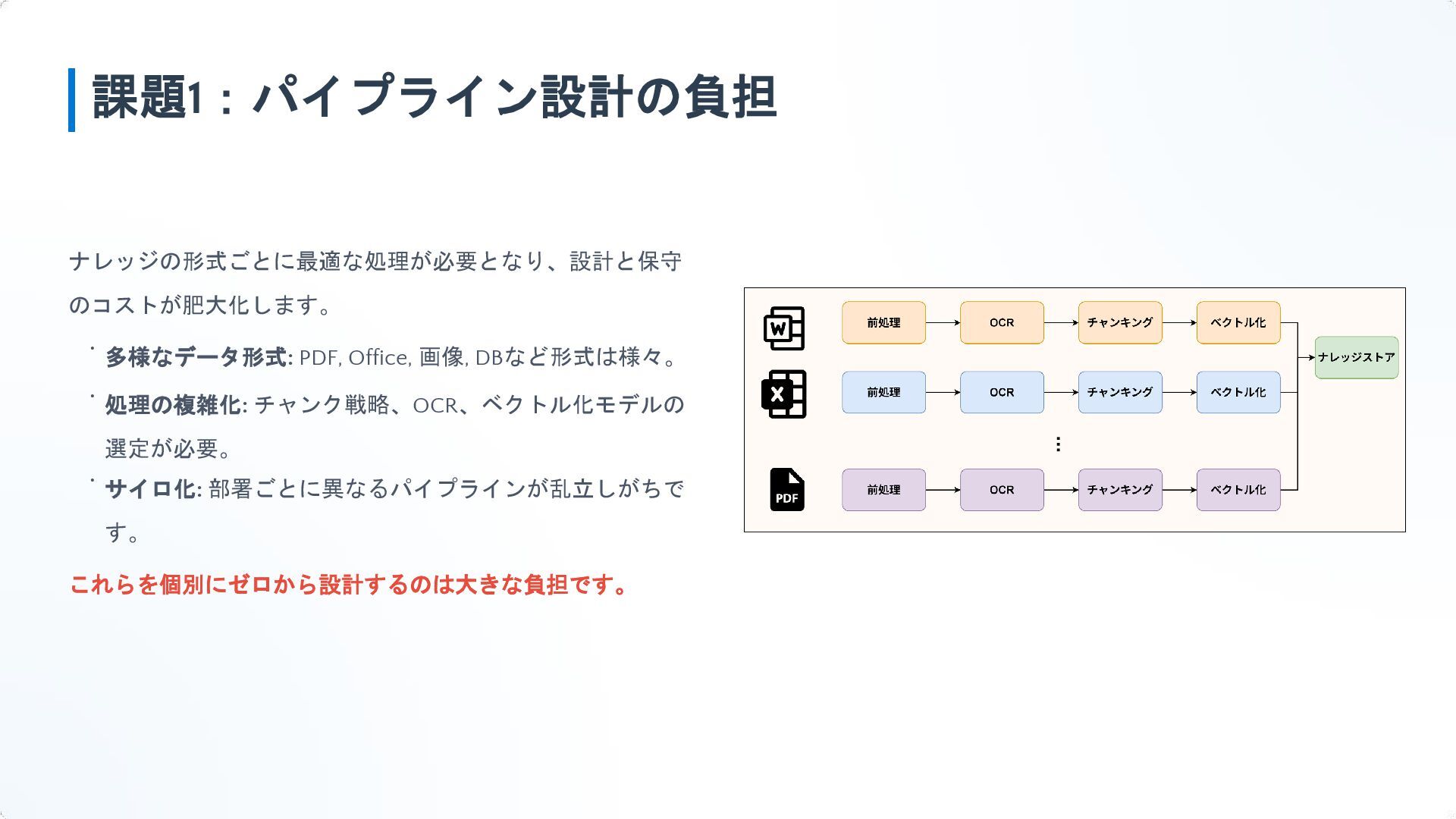{kind=link}
{kind=link}
{kind=link}
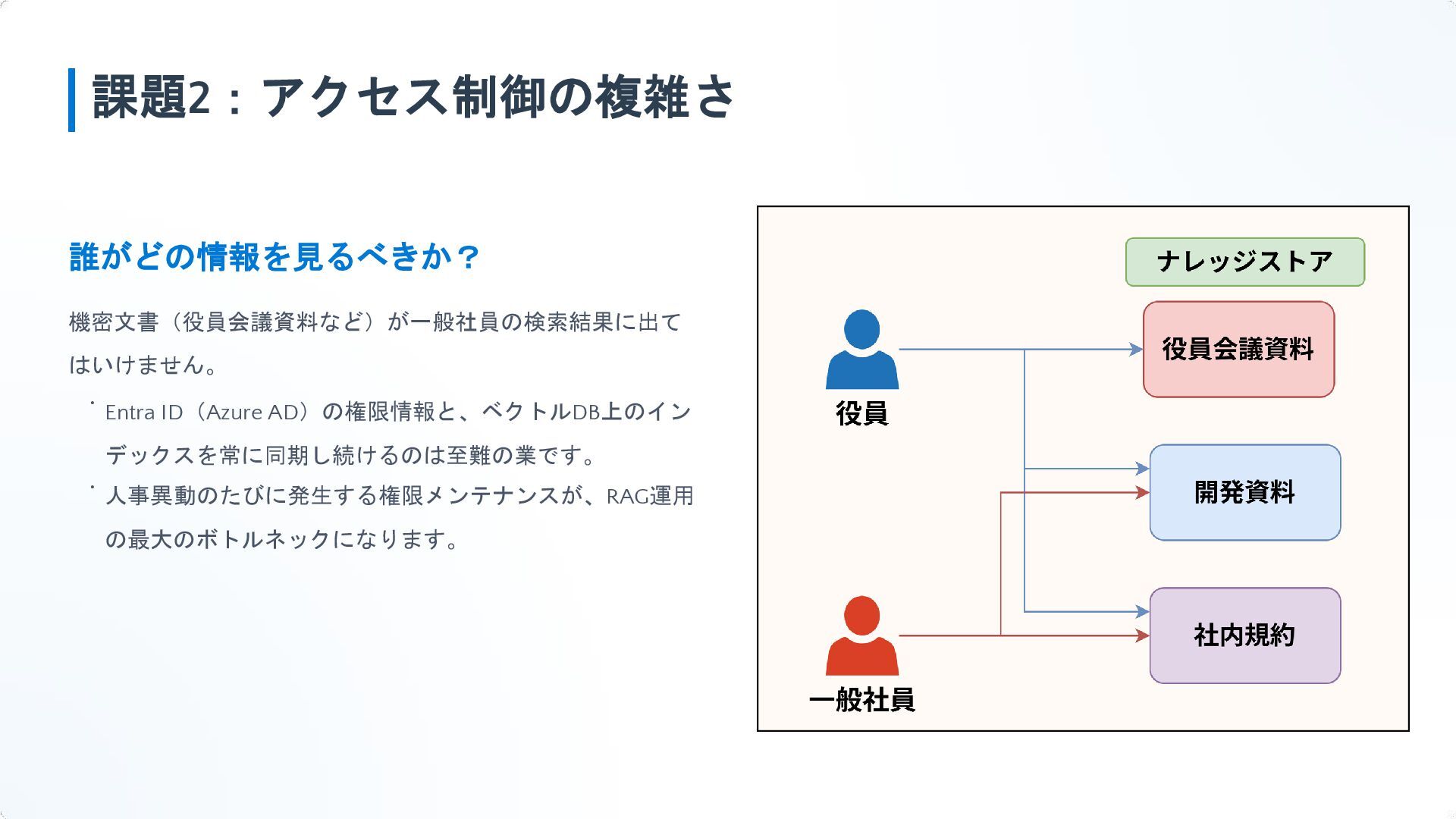{kind=link}
{kind=link}
{kind=link}
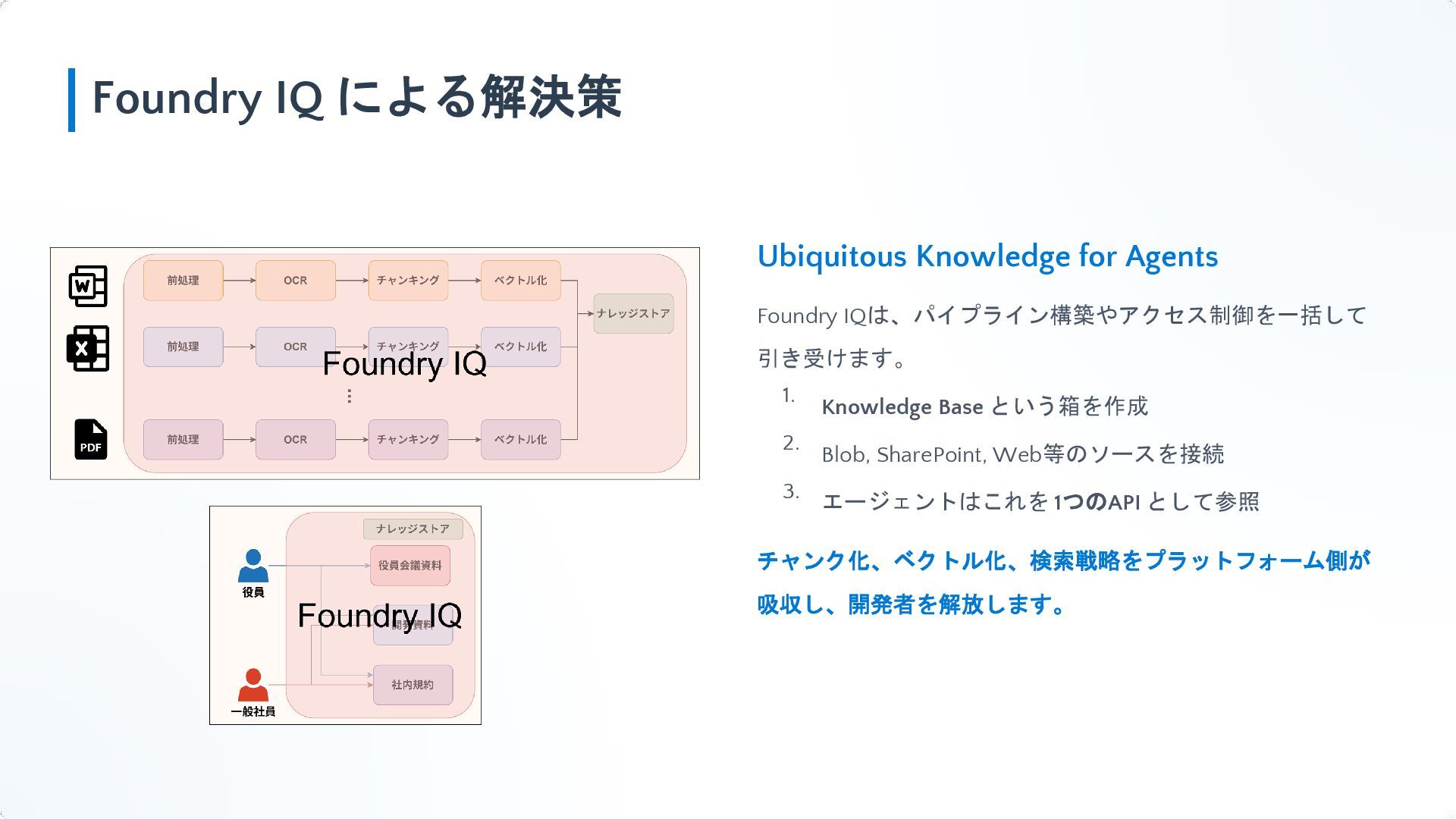{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
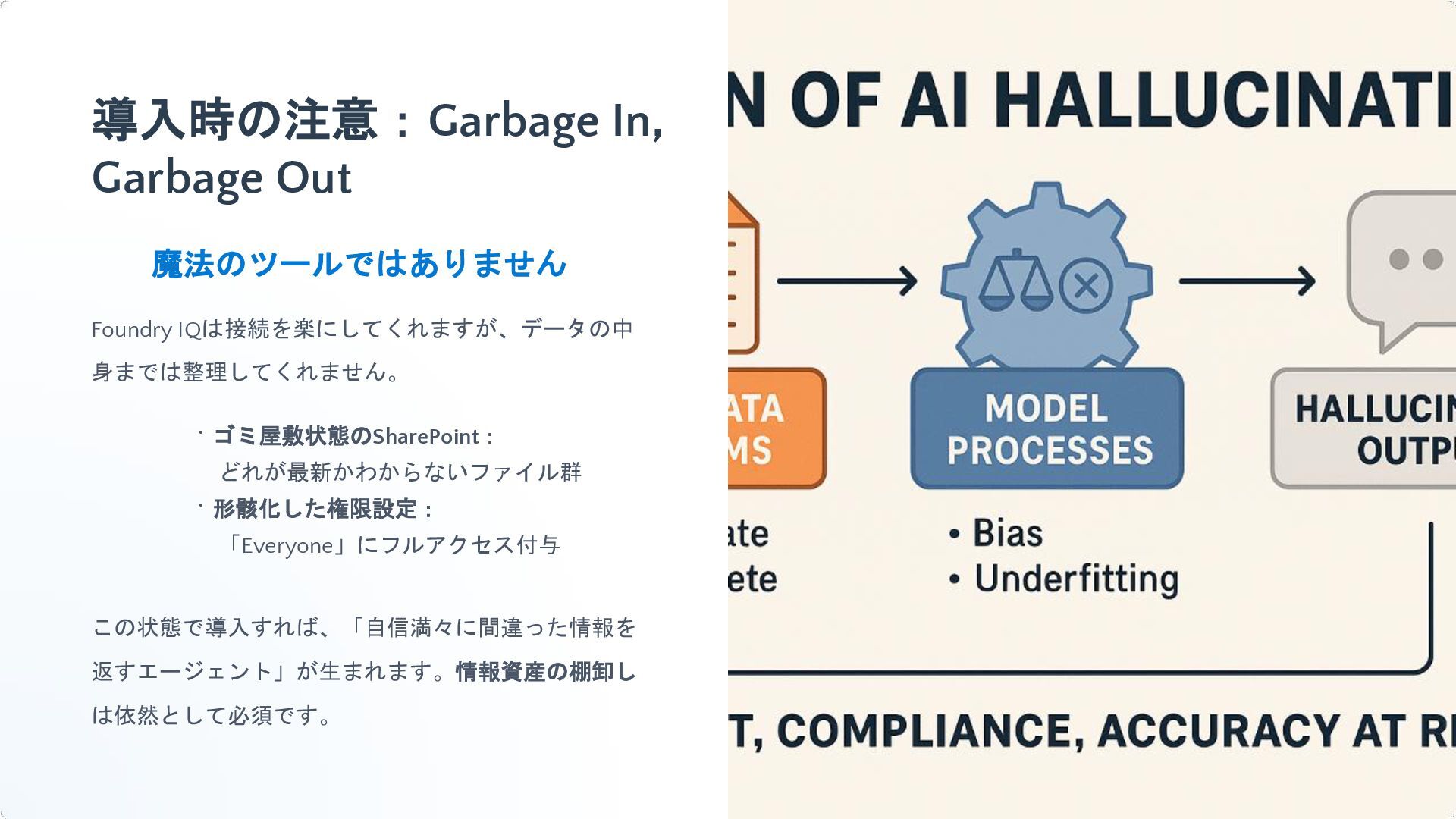{kind=link}
{kind=link}
![やってみた unknown_parameter Unknown parameter: 'tools[0].server_authentication'.](https://files.speakerdeck.com/presentations/6f06751a318342c8b3b391d1bed08b25/slide_20.jpg){kind=link}
{kind=link}
{kind=link}