Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PyData.Fukuoka#6_LT_slide
Search
shinpsan
November 22, 2019
Programming
520
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PyData.Fukuoka#6_LT_slide
前処理するとき便利だからよく
pandas.DataFrame.apply(lambda)
使っちゃうけど遅いから本当は
pandas.Series.map()
使った方がいいと思う
shinpsan
November 22, 2019
More Decks by shinpsan
See All by shinpsan
20251212_LT忘年会_データサイエンス枠_新川.pdf
shinpsan
0
300
CDLE_Fukuoka_20230523
shinpsan
0
210
LT_コンサル完全に理解したらミドルDSになった_ちゅらNOB合同勉強会
shinpsan
0
460
LT_統計学ユーザーでいいんです_みんなのPython勉強会#70
shinpsan
1
740
"Momochihama Store" on TNC has a wonderful "Udon MAP" section.
shinpsan
0
270
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
140
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
120
AI駆動開発を妨げる技術的負債の解消アプローチ / ai-refactoring-approach
minodriven
17
9.3k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
継続モナドとリアクティブプログラミング
yukikurage
3
630
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
690
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
150
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
180
ソフトウェア設計に溶けるインフラ ― AWS CDK のインフラ認識論
konokenj
2
620
Claude Team Plan導入・ガイド
tk3fftk
0
220
What's New in Android 2026
veronikapj
0
130
【やさしく解説 設計編・中級 #6】良いアーキテクチャとは ~ 一本の登り道の、行き先 ~
panda728
PRO
0
180
Featured
See All Featured
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Believing is Seeing
oripsolob
1
170
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Are puppies a ranking factor?
jonoalderson
1
3.7k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
510
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
My Coaching Mixtape
mlcsv
0
170
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
190
Building the Perfect Custom Keyboard
takai
2
820
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Transcript
前処理するとき便利だからよく pandas.DataFrame.apply(lambda) 使っちゃうけど遅いから本当は pandas.Series.map() 使った方がいいと思う PyData.Fukuoka #6 LT @shinpsan
自己紹介 下積みの父@shinpsan 小売業のデータサイエンティスト(12月まで。年明け転職します) MENSA会員 合同会社ocojoで副業 twitter : 仕事
: 特技: 趣味:
話すこと タイトルに書いたことが全てです。 pandasの基本的なところなのでみんな知ってる内容かも。 知ってる方はヒマだと思うので、心の中で 「シカ」って10回言った後、 「サンタクロースが乗っているのは?」に答えてて下さい
背景 クソみたいなデータ渡されたと文句言いながら、 いつもクソみたいなコード書いてることを反省。
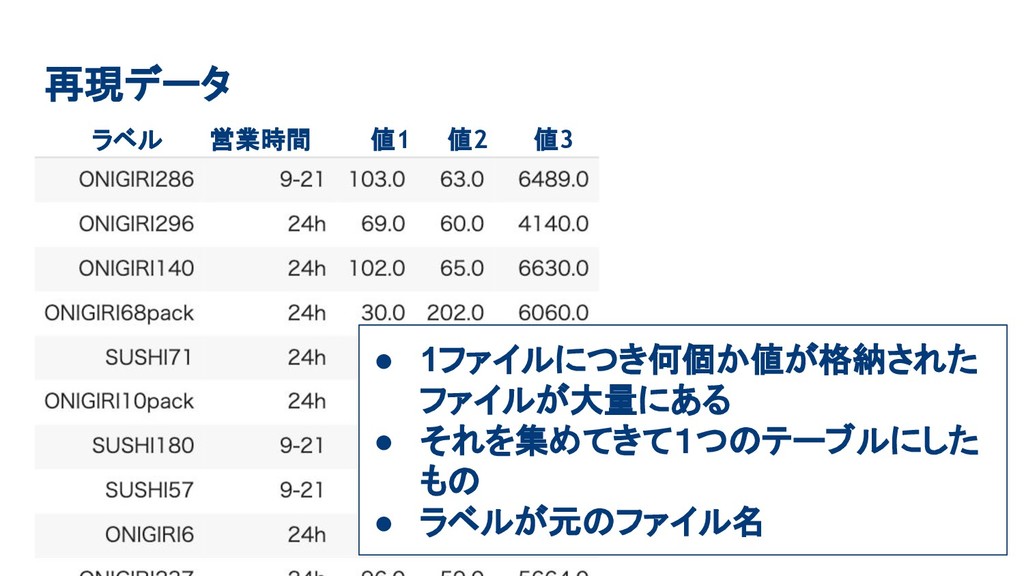
再現データ ラベル 営業時間 値1 値2 値3 • 1ファイルにつき何個か値が格納された ファイルが大量にある •
それを集めてきて1つのテーブルにした もの • ラベルが元のファイル名
やりたいこと(持っていきたい方向) 店舗の営業時間体系ごとの • 三角おにぎり • パックおにぎり • 寿司 のラベルをつけて集計とか 可視化とかいろいろ
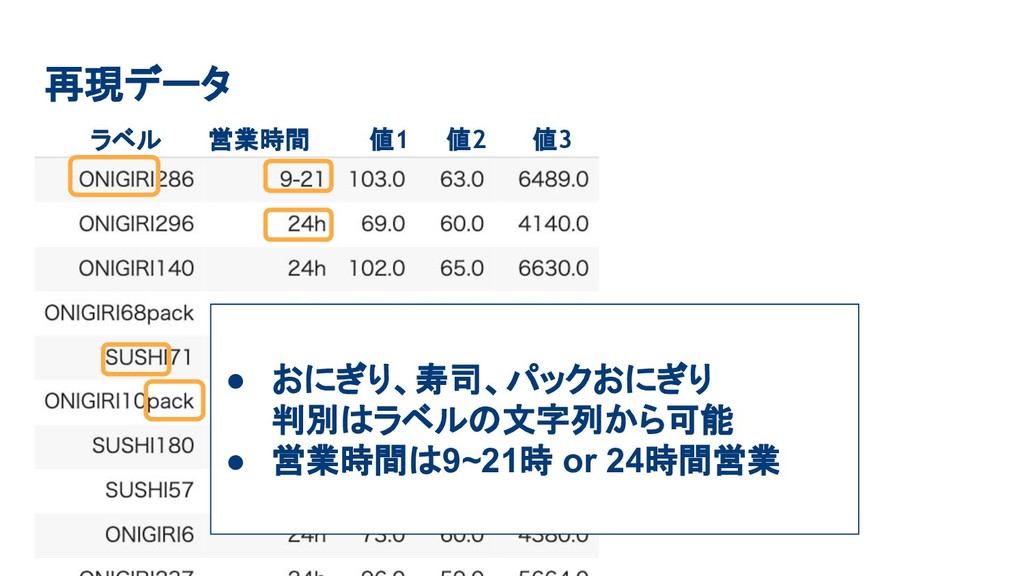
再現データ ラベル 営業時間 値1 値2 値3 • おにぎり、寿司、パックおにぎり 判別はラベルの文字列から可能
• 営業時間は9~21時 or 24時間営業
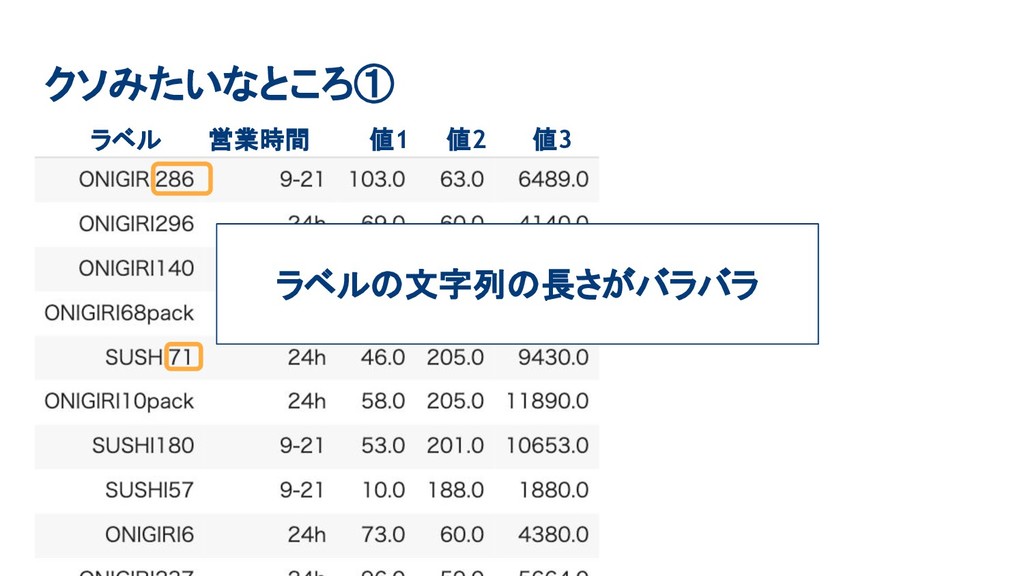
クソみたいなところ① ラベル 営業時間 値1 値2 値3 ラベルの文字列の長さがバラバラ
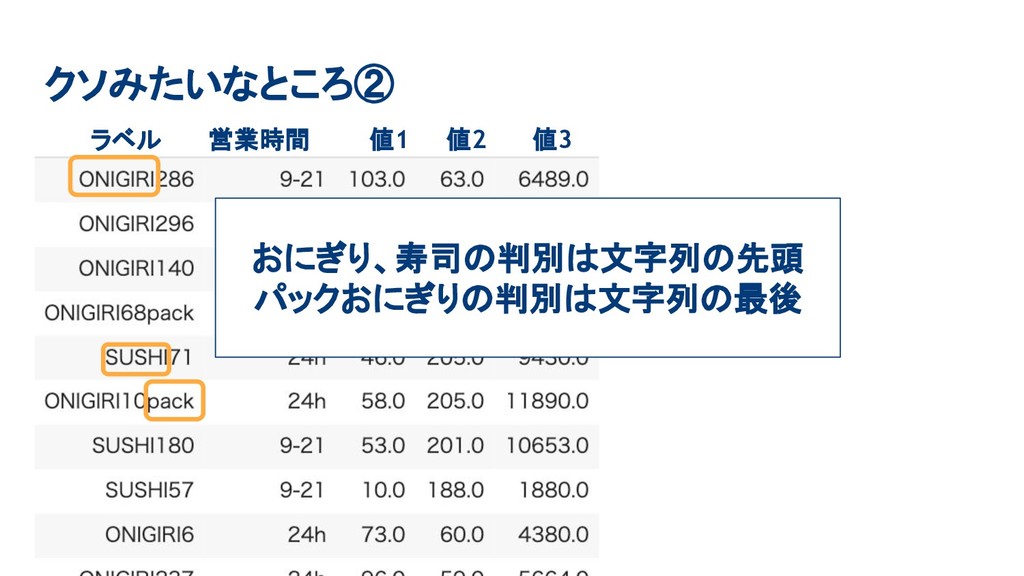
クソみたいなところ② ラベル 営業時間 値1 値2 値3 おにぎり、寿司の判別は文字列の先頭 パックおにぎりの判別は文字列の最後
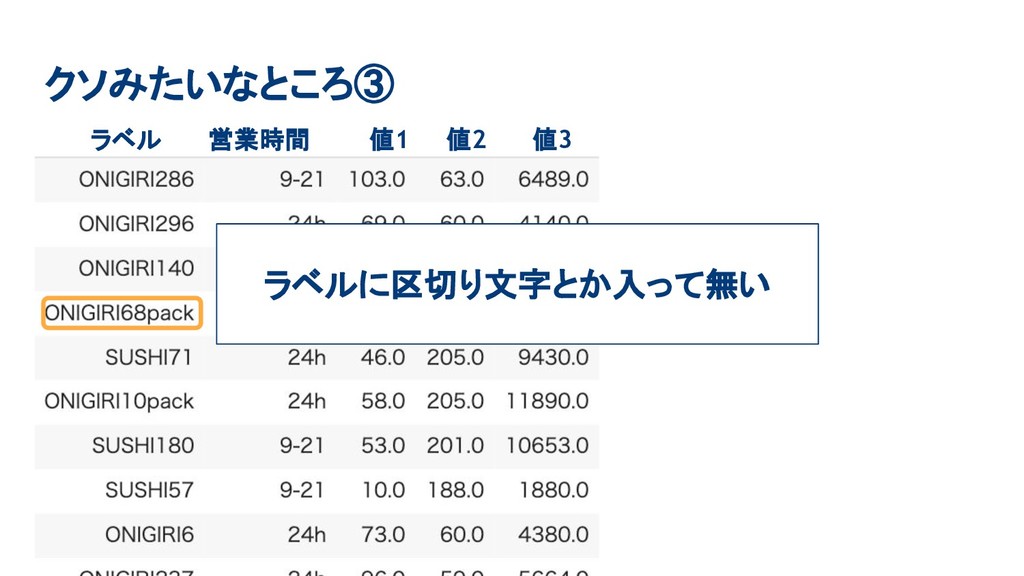
クソみたいなところ③ ラベル 営業時間 値1 値2 値3 ラベルに区切り文字とか入って無い
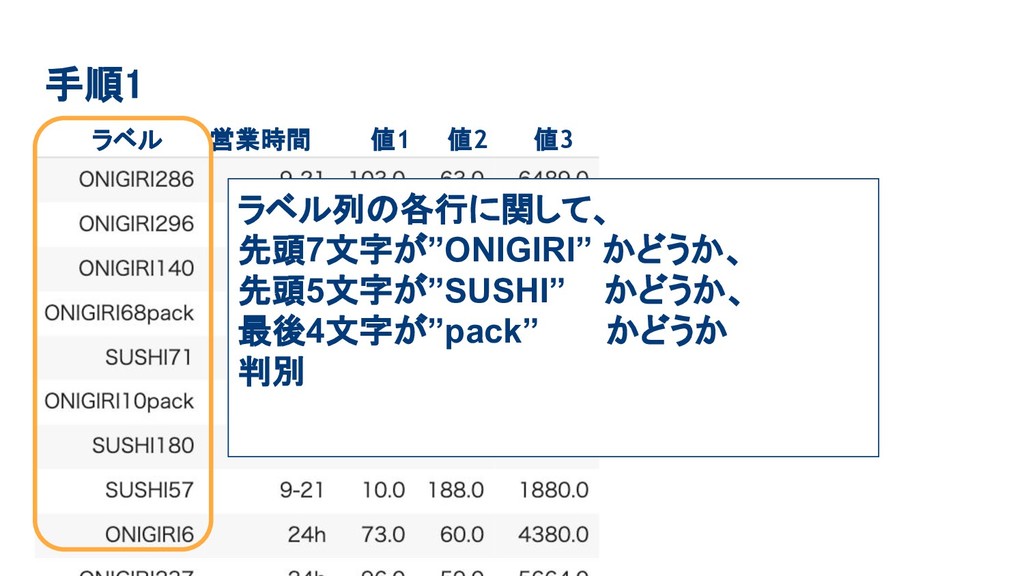
手順1 ラベル 営業時間 値1 値2 値3 ラベル列の各行に関して、 先頭7文字が”ONIGIRI” かどうか、 先頭5文字が”SUSHI”
かどうか、 最後4文字が”pack” かどうか 判別
手順2 ラベル 営業時間 値1 値2 値3 営業時間列の各行に関して、 “9-21” or “24h”
判別
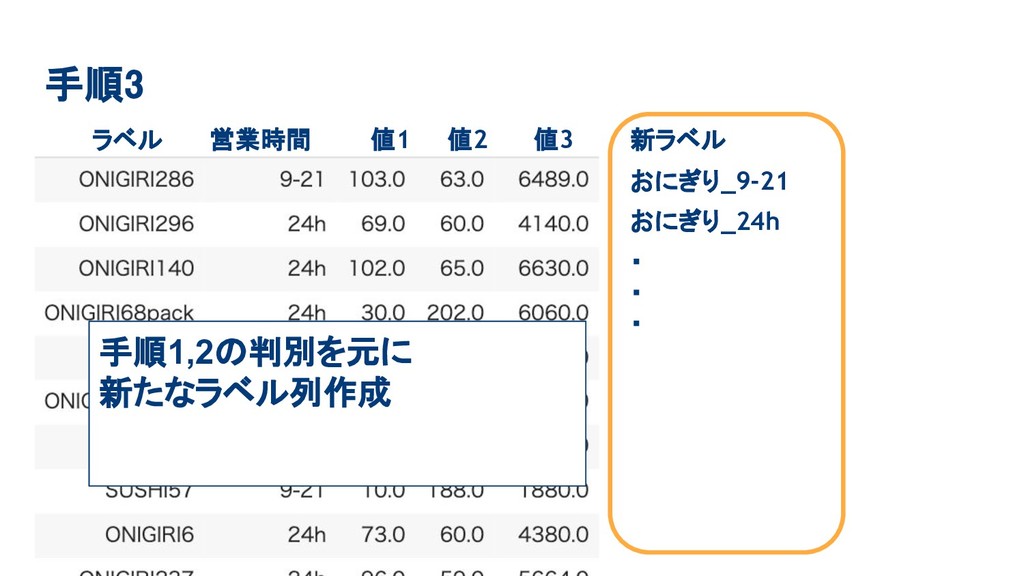
手順3 ラベル 営業時間 値1 値2 値3 手順1,2の判別を元に 新たなラベル列作成 新ラベル おにぎり_9-21
おにぎり_24h ・ ・ ・
ここで本題 どんな処理書く? • for + iterrows() • df.apply() • Series.map()
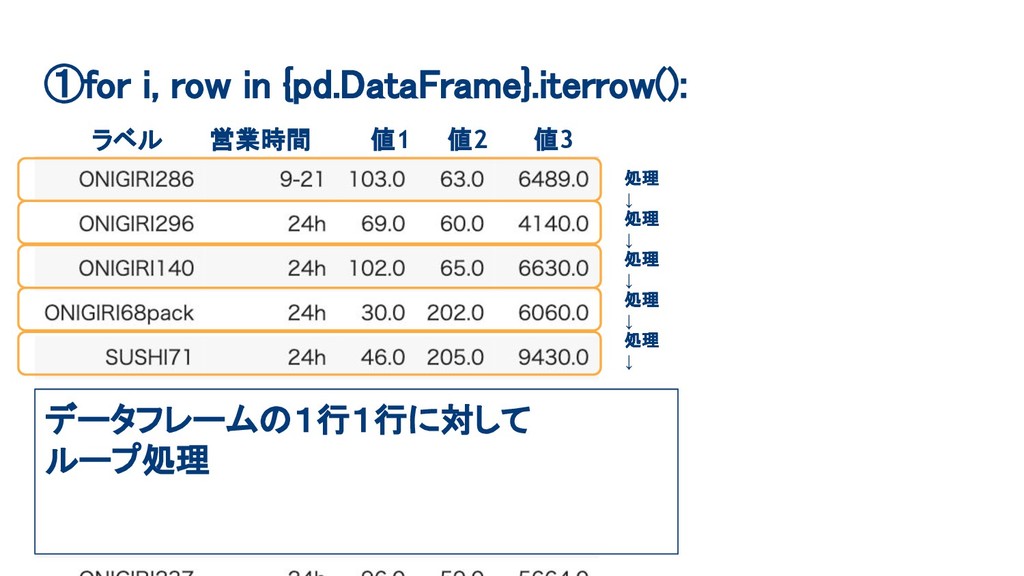
①for i, row in {pd.DataFrame}.iterrow(): ラベル 営業時間 値1 値2 値3
データフレームの1行1行に対して ループ処理 処理 ↓ 処理 ↓ 処理 ↓ 処理 ↓ 処理 ↓
①for i, row in {pd.DataFrame}.iterrow():
②{pd.DataFrame}.apply(lambda x: {}) ラベル 営業時間 値1 値2 値3 データフレームの各行に対して 同じ処理を一括適応
lambda x のxには各行が1行のDFにみたいにして渡される x[“ラベル”]みたいにして使うとこ選べる ✖ 処理 ✖ 処理 ✖ 処理 ✖ 処理 ✖ 処理
②{pd.DataFrame}.apply(lambda x: {})
③{pd.Series}.map(lambda x: {}) ラベル ✖ 処理 ✖ 処理 ✖ 処理
✖ 処理 ✖ 処理 Seriesの各要素に対して 同じ処理を一括適応
③{pd.Series}.map(lambda x: {})
None
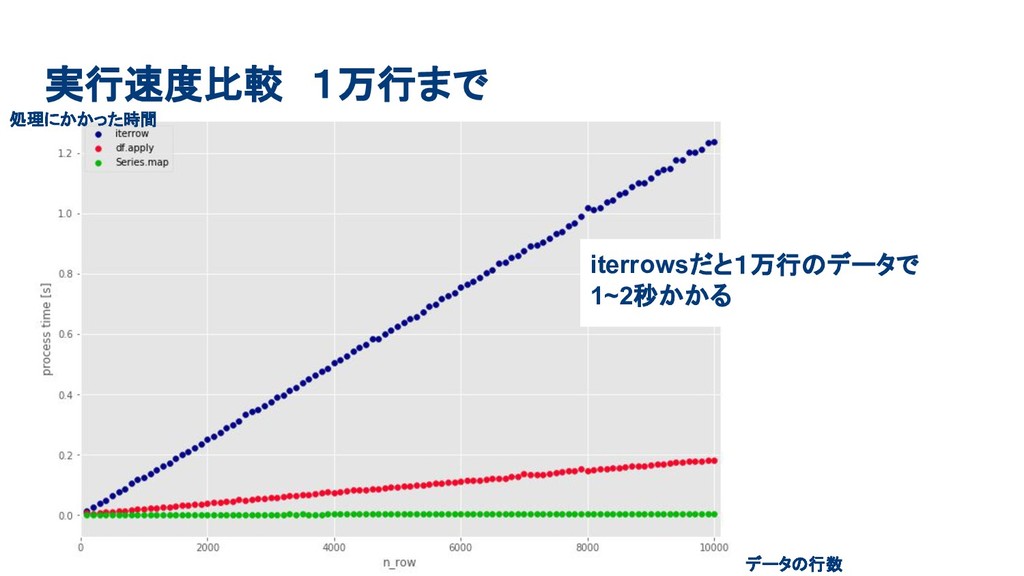
実行速度比較 1万行まで iterrowsだと1万行のデータで 1~2秒かかる データの行数 処理にかかった時間
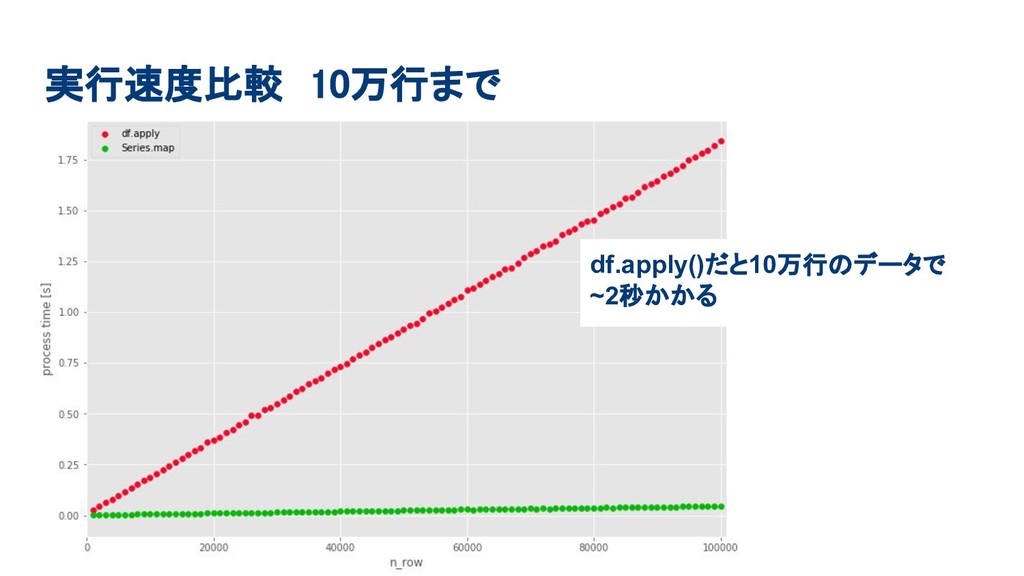
実行速度比較 10万行まで df.apply()だと10万行のデータで ~2秒かかる
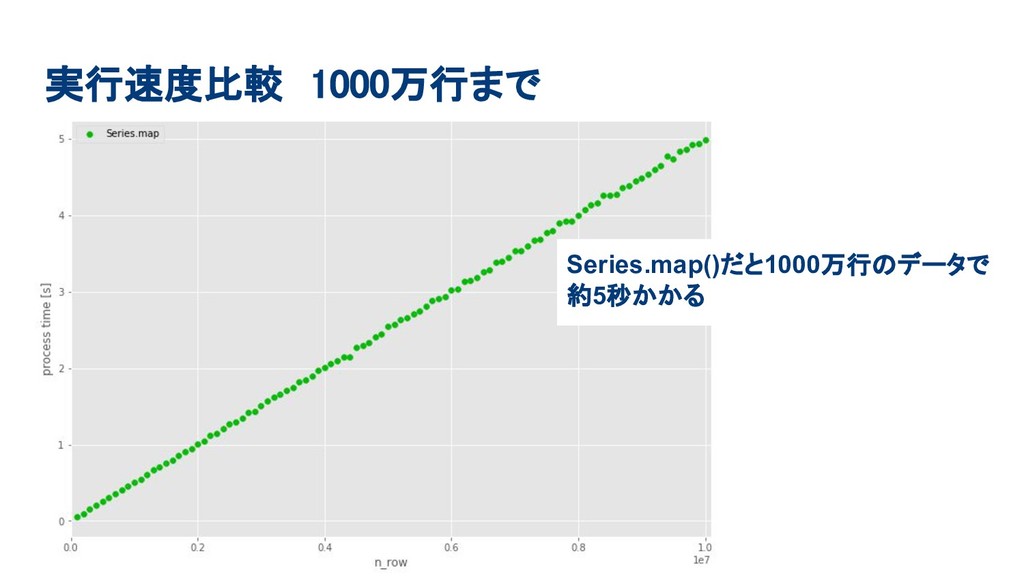
実行速度比較 1000万行まで Series.map()だと1000万行のデータで 約5秒かかる
まとめ ただの肌感ですが、jupyterで分析してて、 そこまで気にならない待ち時間は2秒くらい • for + iterrows 1万行 • df.apply
10万行 • Series.map 400万行 まぁ、結論としてループは使わない。 df.apply()は何も考えずに記述できるけど遅いから、 Series.map()でやる方がいいですね。
enjoy! 答え:そり(トナカイには乗っていない)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}