Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
『能動的推論』第二章「能動的推論への常道」
Search
Shinto
March 05, 2025
170
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
『能動的推論』第二章「能動的推論への常道」
Shinto
March 05, 2025
More Decks by Shinto
See All by Shinto
『身体性認知とは何か』序文「心を身体化する」
shinto_ai
0
81
Distinct ERP profiles for auditory processing in infants at-risk for autism and language impairment
shinto_ai
0
29
『生理心理学と精神生理学』第9章「言語に関するERP研究」
shinto_ai
0
130
『知るということ 認識学序説』第五章「言語・論理的相対性」
shinto_ai
0
65
『創発と物理』第二章「還元と創発の哲学的定義の歴史」
shinto_ai
0
60
Featured
See All Featured
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
410
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
500
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Design in an AI World
tapps
1
270
Amusing Abliteration
ianozsvald
1
240
WENDY [Excerpt]
tessaabrams
11
39k
Fireside Chat
paigeccino
42
4k
Transcript
『能動的推論』読書会 第1回 @ Discord 計算論的精神医学サーバ 北海道大学 情報科学院 修士1年 進藤 稜真
- Ryoma SHINTO 2025/3/5 (Wed)
第1章 : 序章 第2章 : 能動的推論への常道 まとめ 01 02 03
- - - 2 Agenda
01 3 第1章 : 序章 01
生物はどのようにして生存し、適応的に行動するのか? 序章 01 ⇒ 生物は、行為-知覚ループを適応的に制御することによってのみ、 身体の健全な状態を維持することが可能 4 図1.1 生き物とその環境を相互に結びつける行為-知覚サイクル ・望ましい成果や目標に対する感覚的観察
(例:食料の確保に伴う感覚) ・世界を理解するのに役立つ感覚的観察 (例:周囲の状況を知らせる感覚) を求めるために行動することを意味する。 能動的推論:第一原理から行動を考える 異質の生物・多様な認知現象を理解する統一的なフレームワーク として「能動的推論」を提案 ⇒ 行為によって環境を変化させ、感覚を通じて環境を観察している → 図 1.1
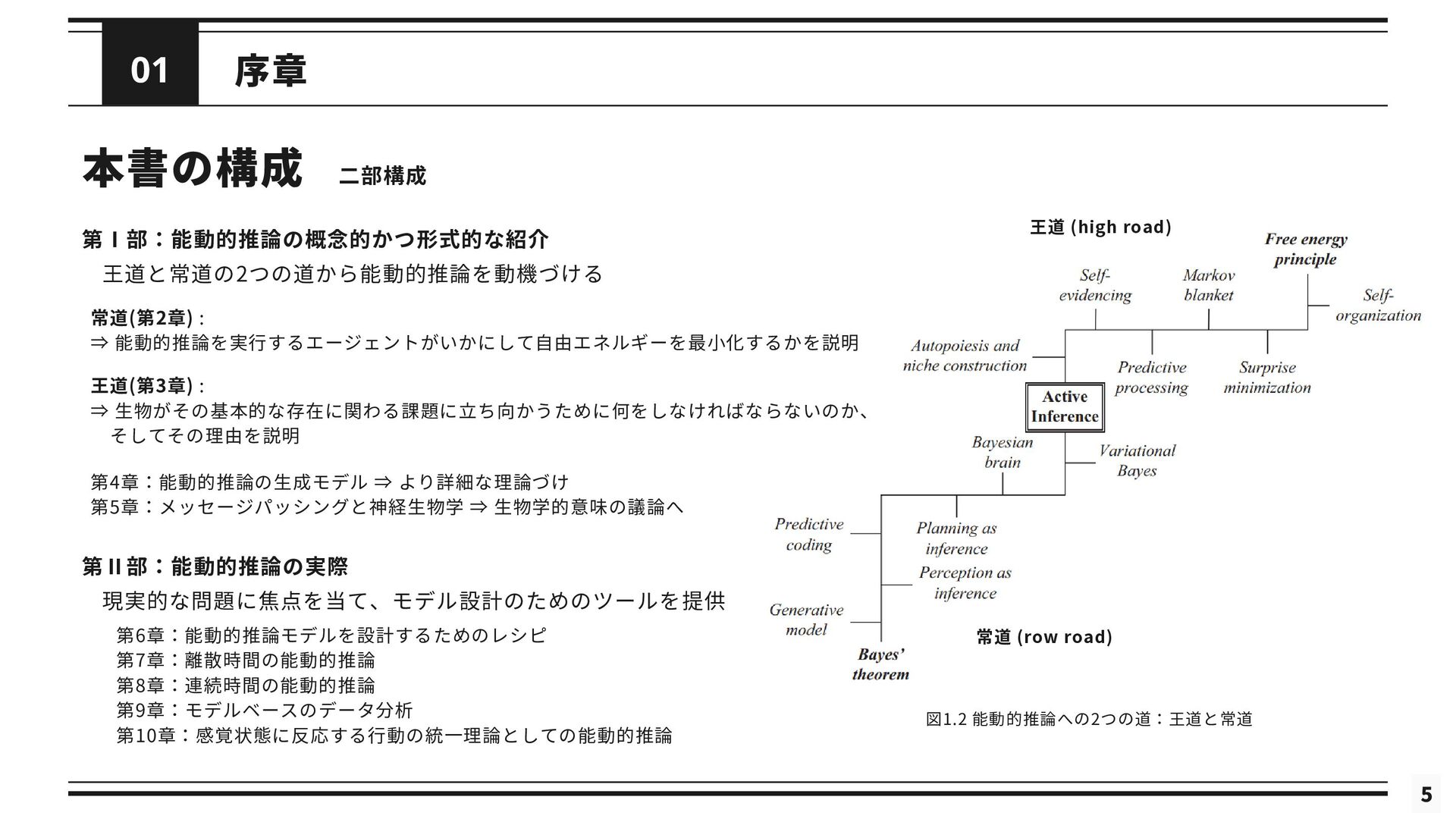
本書の構成 序章 01 第Ⅰ部:能動的推論の概念的かつ形式的な紹介 5 図1.2 能動的推論への2つの道:王道と常道 王道 (high road)
常道 (row road) 第Ⅱ部:能動的推論の実際 第6章:能動的推論モデルを設計するためのレシピ 第7章:離散時間の能動的推論 第8章:連続時間の能動的推論 第9章:モデルベースのデータ分析 第10章:感覚状態に反応する行動の統一理論としての能動的推論 現実的な問題に焦点を当て、モデル設計のためのツールを提供 王道と常道の2つの道から能動的推論を動機づける 常道(第2章) : ⇒ 能動的推論を実行するエージェントがいかにして自由エネルギーを最小化するかを説明 王道(第3章) : ⇒ 生物がその基本的な存在に関わる課題に立ち向かうために何をしなければならないのか、 そしてその理由を説明 第4章:能動的推論の生成モデル ⇒ より詳細な理論づけ 第5章:メッセージパッシングと神経生物学 ⇒ 生物学的意味の議論へ 二部構成
03 6 第2章 : 能動的推論への常道 03
2.2 推論としての知覚 02 ベイズ推論には「生成モデル」が必要 「ベイズ脳仮説」(Doya 2007) ⇒ 知覚とは... 「感覚の原因に関する最も可能性の高い(トップダウンの)事前情報と、(ボトムアップの)感覚刺激を結びつける推論過程」 ≠
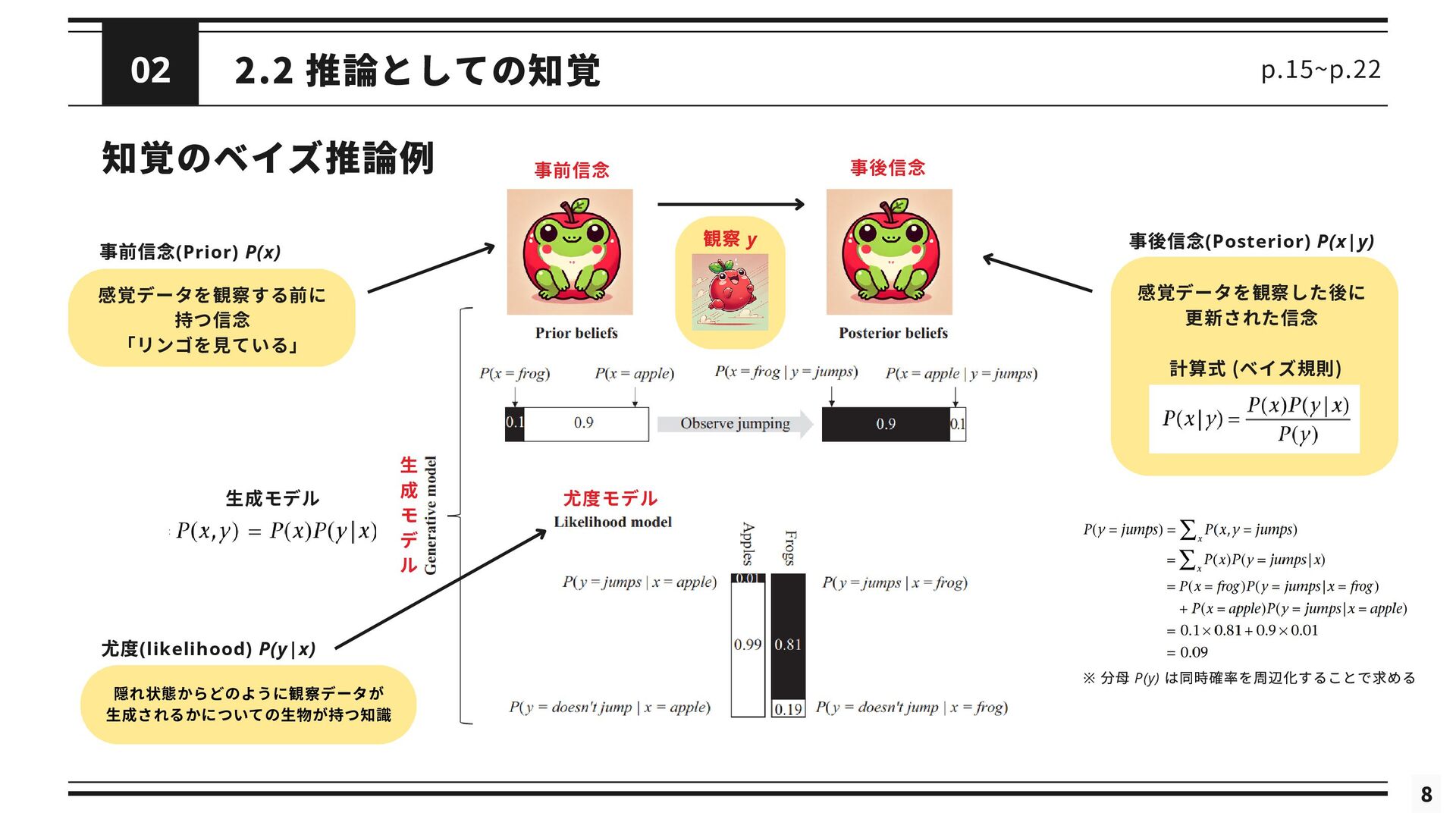
「受動的な外から内へのプロセス」 ⇒ 生成モデル:観察データ y と観察データを生成する世界における隠れ状態 x の、同時確率 P(y,x) として定式化される ・同時確率は2つに分解できる 事前確率(Prior) P(x) : 感覚データを見る前の、世界の隠れ状態について生物が持つ知識 尤度(likelihood) P(y|x) : 隠れ状態からどのように観察データが生成されるかについての生物が持つ知識 ・ベイズ規則:事前確率P(x) を、観察データy を受け取った後の隠れ状態の事後確率P(x|y) へ更新する p.15~p.22 7 ベイズ規則(ベイズの定理)
2.2 推論としての知覚 p.15~p.22 知覚のベイズ推論例 観察 y 事前信念 事後信念 事前信念(Prior) P(x)
感覚データを観察する前に 持つ信念 「リンゴを見ている」 尤度モデル 事後信念(Posterior) P(x|y) 感覚データを観察した後に 更新された信念 生 成 モ デ ル 生成モデル ※ 分母 P(y) は同時確率を周辺化することで求める 8 02 計算式 (ベイズ規則) 尤度(likelihood) P(y|x) 隠れ状態からどのように観察データが 生成されるかについての生物が持つ知識
2.2 推論としての知覚 ① 「サプライズ」: 負の対数証拠 negative log evidence 2つのサプライズ ⇒
説明しようとしているデータにモデルがどれだけ適合しないかを示す指標 p.15~p.22 = 生成モデルの下で観察された行動の確率から計算 再掲: 「ジャンプ」の確率 例: 「ジャンプ」の ② 「ベイズサプライズ」: KL Divergence ⇒ ある観察データを得た後に、どれだけ自分の信念を 更新しなければならないかを示す量 = 事前信念と事後確率の差を定量化 = 2つの確率分布の非類似度を定量化 9 02 例:ジャンプ観測時のKL Divergence 能動的推論において需要になる2つのサプライズの概念
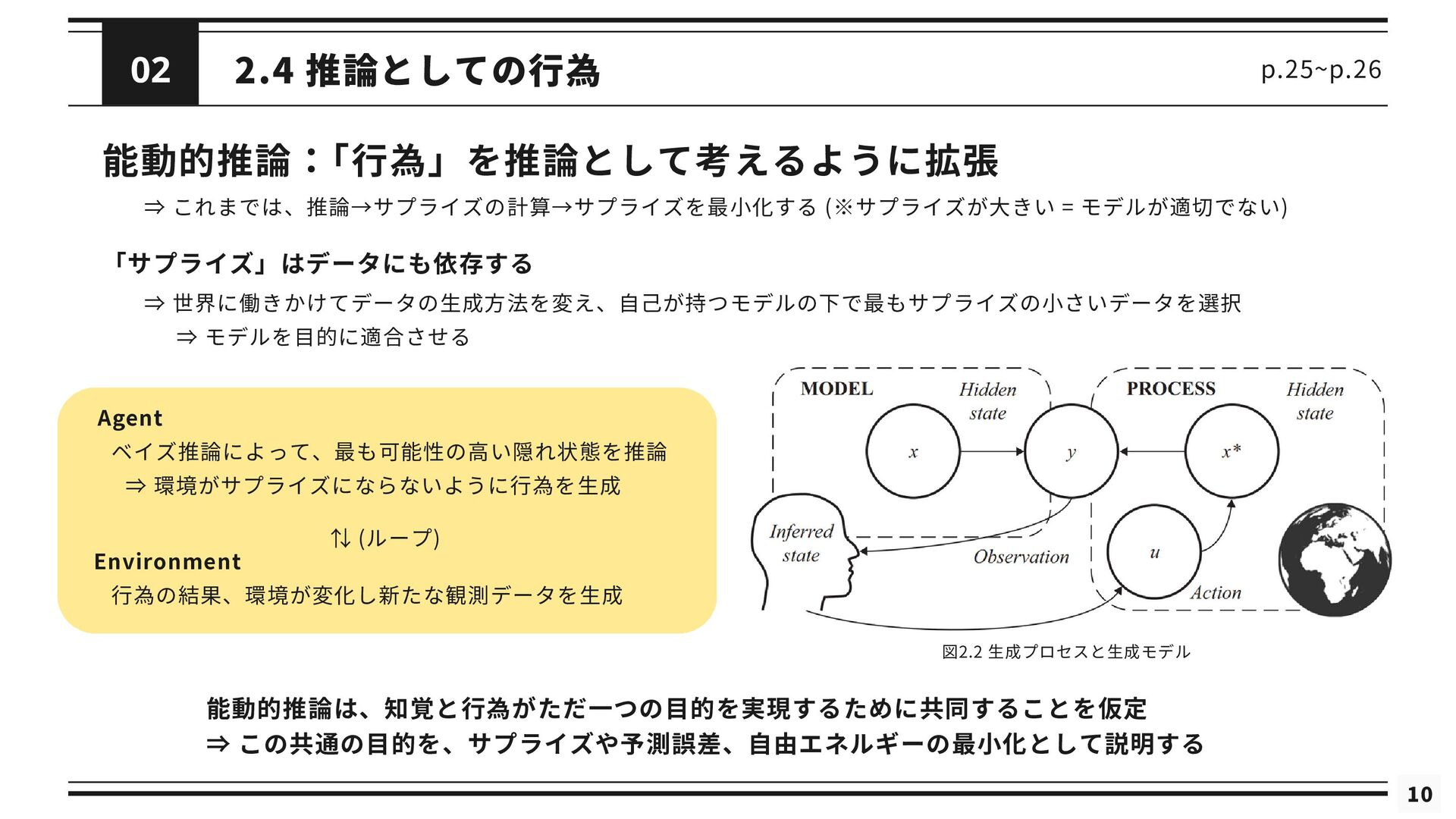
10 2.4 推論としての行為 「サプライズ」はデータにも依存する 能動的推論: 「行為」を推論として考えるように拡張 p.25~p.26 ⇒ 世界に働きかけてデータの生成方法を変え、自己が持つモデルの下で最もサプライズの小さいデータを選択 図2.2
生成プロセスと生成モデル ⇒ これまでは、推論→サプライズの計算→サプライズを最小化する (※サプライズが大きい = モデルが適切でない) ⇒ モデルを目的に適合させる ベイズ推論によって、最も可能性の高い隠れ状態を推論 ⇒ 環境がサプライズにならないように行為を生成 ⇅ (ループ) 行為の結果、環境が変化し新たな観測データを生成 Agent Environment 能動的推論は、知覚と行為がただ一つの目的を実現するために共同することを仮定 ⇒ この共通の目的を、サプライズや予測誤差、自由エネルギーの最小化として説明する 02
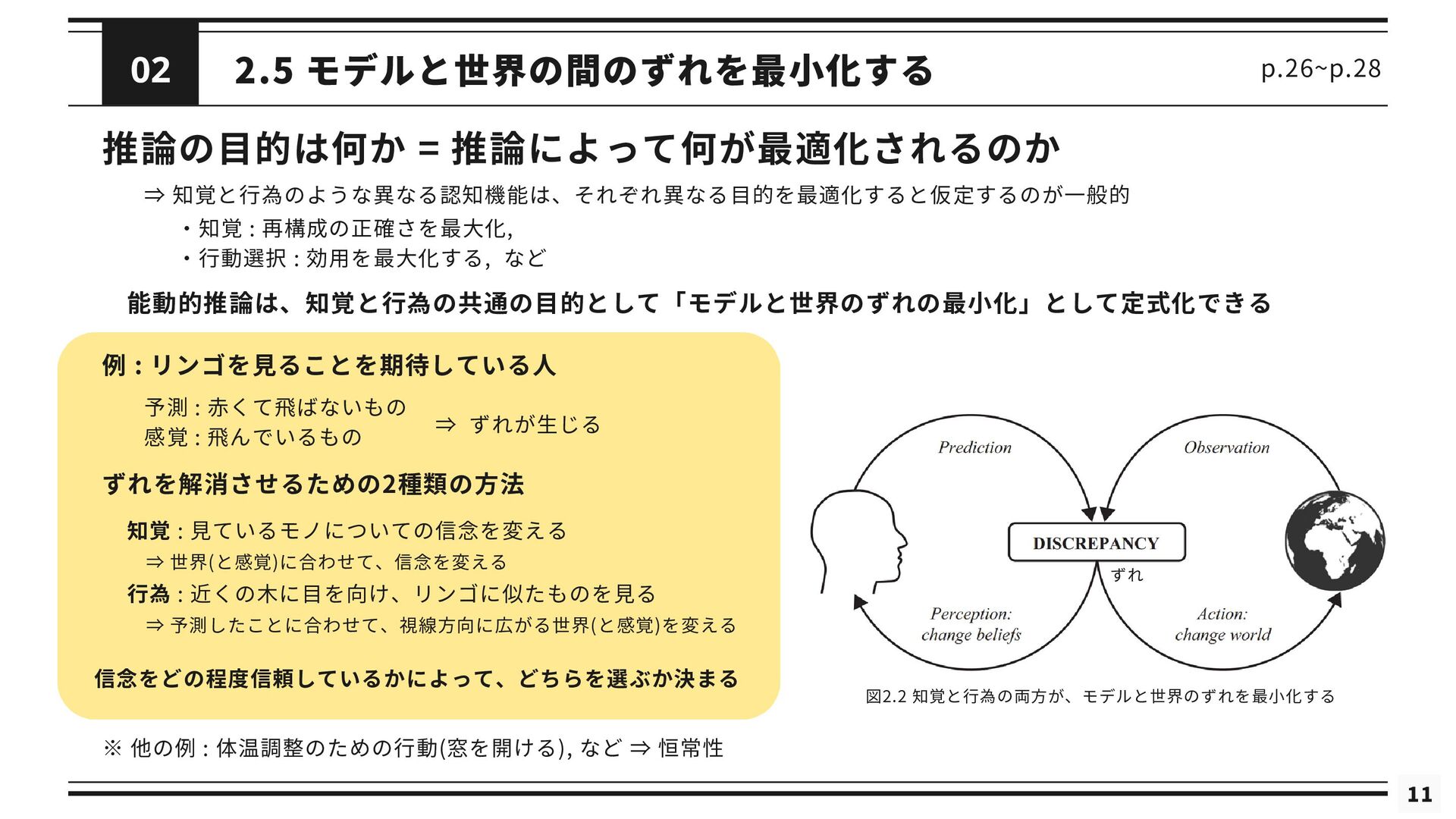
11 2.5 モデルと世界の間のずれを最小化する 推論の目的は何か = 推論によって何が最適化されるのか p.26~p.28 ⇒ 知覚と行為のような異なる認知機能は、それぞれ異なる目的を最適化すると仮定するのが一般的 能動的推論は、知覚と行為の共通の目的として「モデルと世界のずれの最小化」として定式化できる
・知覚 : 再構成の正確さを最大化, ・行動選択 : 効用を最大化する, など 図2.2 知覚と行為の両方が、モデルと世界のずれを最小化する ずれ ※ 他の例 : 体温調整のための行動(窓を開ける), など ⇒ 恒常性 例 : リンゴを見ることを期待している人 予測 : 赤くて飛ばないもの 感覚 : 飛んでいるもの ⇒ ずれが生じる ずれを解消させるための2種類の方法 知覚 : 見ているモノについての信念を変える 行為 : 近くの木に目を向け、リンゴに似たものを見る ⇒ 世界(と感覚)に合わせて、信念を変える ⇒ 予測したことに合わせて、視線方向に広がる世界(と感覚)を変える 信念をどの程度信頼しているかによって、どちらを選ぶか決まる 02
12 2.6 変分自由エネルギーの最小化 ベイズ推論の変分近似 p.28~p.33 ⇒ ほとんどの場合、モデル証拠 P(y) と 事後確率
P(x|y) の計算は困難 ベイズ推論の変分近似 (定式化 → 4章) ・モデル証拠 P(y) ⇒ 変分自由エネルギー F ・事後確率 P(x|y) ⇒ 近似事後分布 Q 負の変分自由エネルギーは、 証拠の下限(Evidence Lower Bound, ELBO)とも呼ばれる ⇒ 重要なのは、ベイズ推論の問題が最適化の問題になること = 最適化:変分自由エネルギー F の最小化 ・・・③ ・・・② ・・・① ① Qに関して最小化するためには... ・生成モデル( エネルギー) との整合性が必要 ・高い事後エントロピーの維持が必要 ② 感覚データに関する最良の説明を見つける ⇒ 複雑さと正確さのトレードオフ 02 = ( これまで見てきたような) 厳密なベイズ推論が困難 計算可能な量に対応 直感的な理解 (詳細 → 第II部) ⇒ データを正確に説明できるもっとも単純な説明 → 最大エントロピー原理 変分自由エネルギーは数学的に等価な方法で分解できる = サプライズ( 負の対数証拠) を計算できない。そこで...
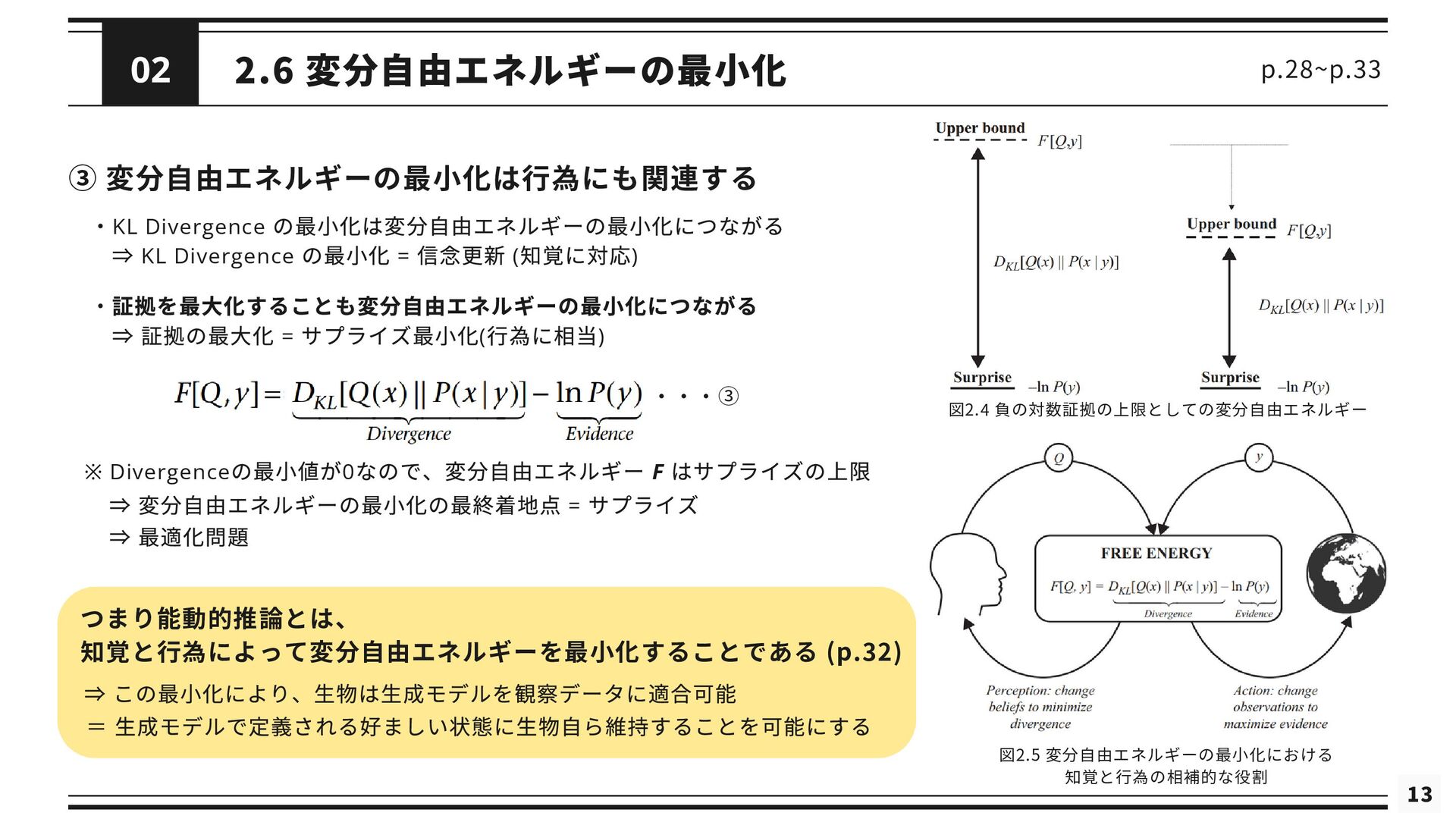
13 2.6 変分自由エネルギーの最小化 p.28~p.33 ③ 変分自由エネルギーの最小化は行為にも関連する ・証拠を最大化することも変分自由エネルギーの最小化につながる ⇒ 証拠の最大化 =
サプライズ最小化( 行為に相当) 図2.5 変分自由エネルギーの最小化における 知覚と行為の相補的な役割 図2.4 負の対数証拠の上限としての変分自由エネルギー ・KL Divergence の最小化は変分自由エネルギーの最小化につながる ⇒ KL Divergence の最小化 = 信念更新 ( 知覚に対応) ※ Divergence の最小値が0 なので、変分自由エネルギー F はサプライズの上限 ・・・③ つまり能動的推論とは、 知覚と行為によって変分自由エネルギーを最小化することである (p.32) ⇒ この最小化により、生物は生成モデルを観察データに適合可能 = 生成モデルで定義される好ましい状態に生物自ら維持することを可能にする ⇒ 変分自由エネルギーの最小化の最終着地点 = サプライズ 02 ⇒ 最適化問題
14 2.7, 2.8 期待自由エネルギー p.33~p.40 期待自由エネルギー ・ポリシー(π) : 可能性のある各行為系列 期待自由エネルギー
G(π) ・生物がポリシーを評価するための関数 良いポリシー → 高い期待自由エネルギー ・数学的に等価ないくつかの方法で分解可能 ・・・④ ・・・⑤ ・・・⑥ 02 ・能動的推論を拡張して、 「行動計画」を含むようにする 例 : 迷路脱出のための行為系列の計画 ⇒ 直感的な理解を見ていく
15 2.7, 2.8 期待自由エネルギー p.33~p.40 期待自由エネルギー G(π) ・情報利得 (Information gain)
: 新しい情報を求める価値 (= 探索) 上記2 つの項のバランスによって、行動が探索的か利用的かが決まる ・・・④ ・実利的価値 (Pragmatic Value) : 好ましい観察データを求める価値 (= 利用) ⇒ ダイバージェンスの期待値を最大化するようなポリシーを選択したい = 情報利得の高いポリシーを選択 ・・・③ 参考 : 変分自由エネルギー F ⇒ 観察データに関する事前信念として現れる ※ パラメータ C には、選好 preference が含まれる ( → 詳細:7 章) 例 : エスプレッソを飲みたい人 ・街には2 つのおいしいカフェ。一方は平日のみ、もう一方は休日のみ営業。 今日が何曜日か分からない ( 認識的不確実性) ⇒ カレンダーを見る ( 情報利得, 認識的価値) → 営業しているカフェに行く ( 実利的価値) ⇒ 実利的価値を考慮するだけの行動計画は、認識的不確実性が存在しない状況( 何曜日か知っている) に限られる 02
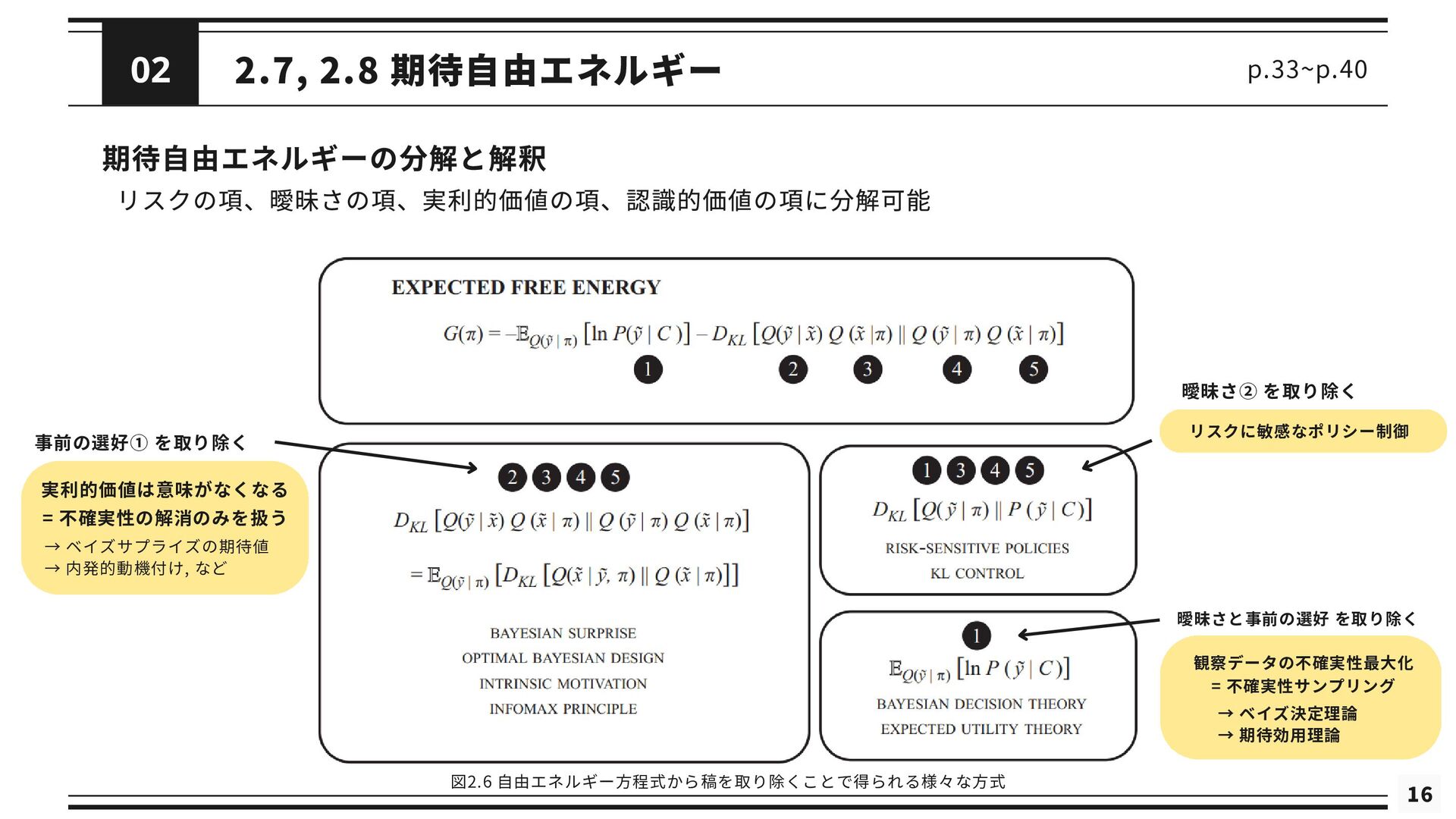
16 2.7, 2.8 期待自由エネルギー p.33~p.40 期待自由エネルギーの分解と解釈 図2.6 自由エネルギー方程式から稿を取り除くことで得られる様々な方式 事前の選好① を取り除く
実利的価値は意味がなくなる = 不確実性の解消のみを扱う → ベイズサプライズの期待値 → 内発的動機付け, など 曖昧さ② を取り除く リスクに敏感なポリシー制御 曖昧さと事前の選好 を取り除く → ベイズ決定理論 → 期待効用理論 観察データの不確実性最大化 = 不確実性サンプリング 02 リスクの項、曖昧さの項、実利的価値の項、認識的価値の項に分解可能
03 17 まとめ 03
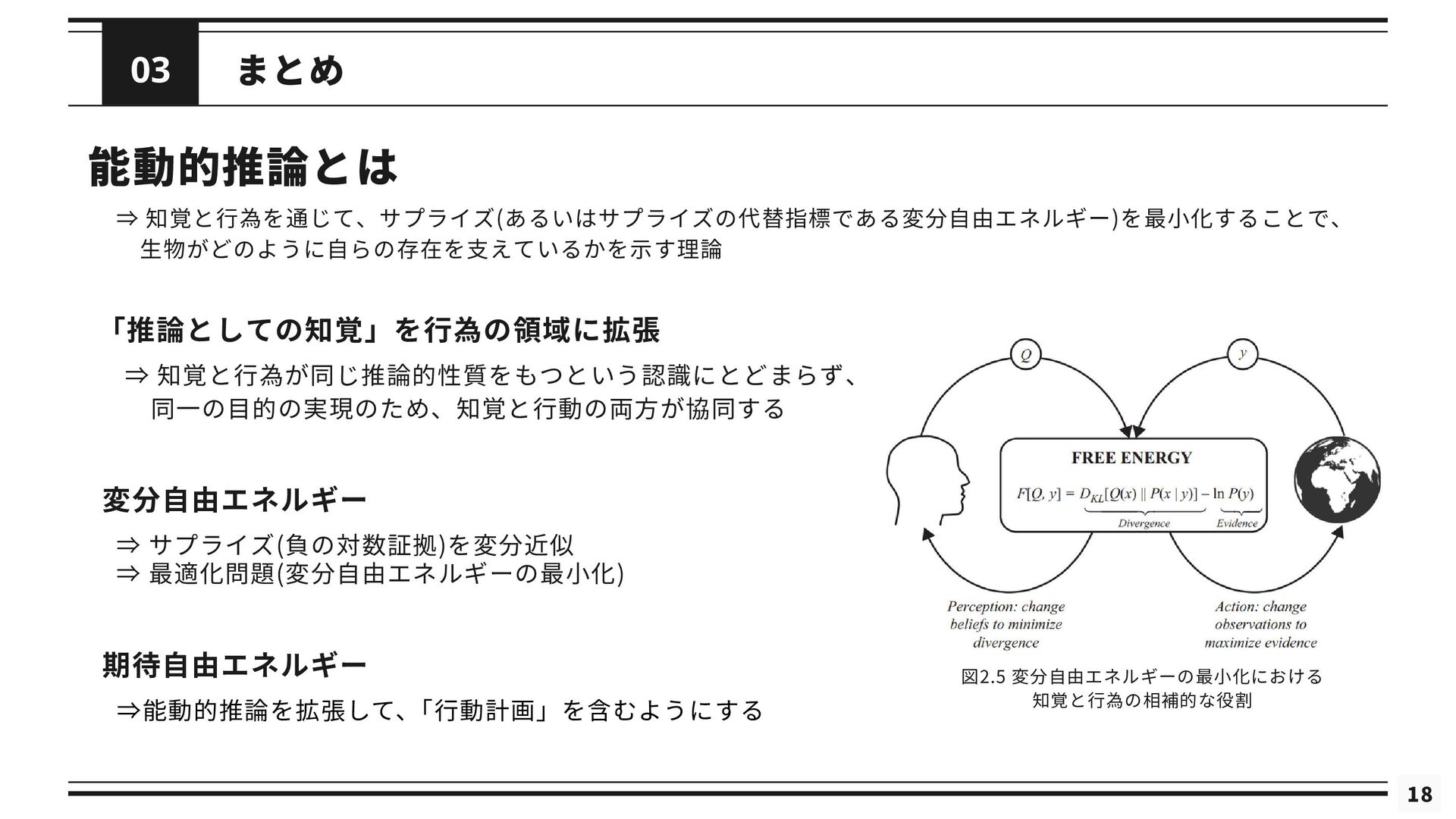
まとめ 03 能動的推論とは ⇒ 知覚と行為を通じて、サプライズ(あるいはサプライズの代替指標である変分自由エネルギー)を最小化することで、 生物がどのように自らの存在を支えているかを示す理論 「推論としての知覚」を行為の領域に拡張 18 図2.5 変分自由エネルギーの最小化における
知覚と行為の相補的な役割 ⇒ 知覚と行為が同じ推論的性質をもつという認識にとどまらず、 同一の目的の実現のため、知覚と行動の両方が協同する 変分自由エネルギー 期待自由エネルギー ⇒能動的推論を拡張して、 「行動計画」を含むようにする ⇒ 最適化問題(変分自由エネルギーの最小化) ⇒ サプライズ(負の対数証拠)を変分近似
END Thank you for your attention! Next 2025.3.19 (Wed)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}