Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
無料で使える「LM Studio」でローカルLLM入門
Search
Naka Sho
March 14, 2026
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
無料で使える「LM Studio」でローカルLLM入門
Naka Sho
March 14, 2026
More Decks by Naka Sho
See All by Naka Sho
ローカルLLMで自動レビューの仕組み
shogonakao
0
20
単体テストの精度を高めるための guideline
shogonakao
0
300
Javaはレガシーではない!
shogonakao
0
300
型安全性で考えること
shogonakao
0
32
アプリケーションログをs3に転送するとき個人情報気をつけてますか?
shogonakao
0
51
コーディングエージェントと 筋トレ
shogonakao
0
89
SpringBootでAPI開発
shogonakao
0
180
エキサイトブログ刷新に向けて
shogonakao
0
140
【エキサイトブログリビルド】Spring Boot × MyBatis × FreeMarker を使って、データベースの接続先を安全に変更します。
shogonakao
1
900
Featured
See All Featured
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
880
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Designing Experiences People Love
moore
143
24k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Facilitating Awesome Meetings
lara
57
7k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
320
How to Build an AI Search Optimization Roadmap - Criteria and Steps to Take #SEOIRL
aleyda
1
2.1k
[RailsConf 2023 Opening Keynote] The Magic of Rails
eileencodes
31
10k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
490
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Transcript
無料で使える「 LM Studio 」で ローカル LLM 入門 1
今日のアジェンダ 1. LM Studio とは? 2. LM Studio のインストール方法 3.
LM Studio の基本的な使い方 4. Java で LLM にアクセスしてみよう( LangChain4j ) 5. Function Calling ( Tool use )と RAG で外部情報を利用する 6. MCP サーバーと MCP クライアントを作る 7. 応用( AI エージェントのオーケストレーション) 2
1. LM Studio とは? 3
LM Studio とは? ローカル PC で LLM を簡単に動かせるデスクトップアプリ GUI で直感的にモデルをダウンロード・管理
チャット UI ですぐに試せる OpenAI 互換の API サーバーを内蔵 http://localhost:1234/v1 でアクセス可能 ( 設定で変更可 ) 既存の OpenAI 向けコードがそのまま動く Windows / macOS / Linux 対応 完全無料 4
なぜローカル LLM ? クラウド API ローカル LLM コスト 従量課金 無料
プライバシー データが外部に送信 データが PC 内で完結 オフライン カスタマイズ 制限あり 自由 性能 非常に高い PC スペック依存 開発・検証・学習用途には最適! 5
2. LM Studio のインストール方法 6
インストール手順 1. 公式サイトからダウンロード https://lmstudio.ai 2. インストーラーを実行 Windows: .exe を実行 /
macOS: .dmg を開く / Linux: .AppImage を実行 3. 起動して完了! 特別な設定は不要。すぐに使い始められます。 モデルのダウンロードにはそれなりの容量が必要(例 : 4B モデルで約 3GB ) 7
3. LM Studio の基本的な使い方 8
モデルのダウンロード Hugging Face からモデルを検索・ダウンロード 例 : https://huggingface.co/lmstudio-community/Qwen3.5-4B-GGUF LM Studio 内の検索バーからモデル名を入力するだけ!
9
無印と GGUF の違い 無印( base モデル) オリジナルの形式( float16/32 ) 高精度だがメモリ消費が大きい
ハイスペック GPU が必要 GGUF (量子化モデル) 精度を少し落として圧縮したフォーマット 一般的な PC の CPU/GPU で動作可能 一般 PC で動かすなら GGUF がおすすめ! lmstudio-community とか Qwen の公式モデルをおすすめします LM Studio 用に最適化されています 10
パラメータ数の違い(例 : Qwen3.5 シリーズ) モデル パラメータ数 VRAM 目安 (GGUF) 特徴
0.8B 8 億 約 1GB 超軽量・お試しに最適 4B 40 億 約 3GB 軽量・高速。今回のデモで使用 8B 80 億 約 5GB バランス型 14B 140 億 約 9GB 高い推論能力 32B 320 億 約 20GB より複雑なタスクに対応 11
パラメータ数が意味すること パラメータが少ない( 4B 〜 8B ) 知識の引き出しが少ない / 複雑な思考は苦手 身軽なのでパッと素早く答えられる
今回のデモでは 4B を使用 → 一般的な PC でも十分動く パラメータが多い( 14B 〜 32B ) 知識の引き出しが多い / 文脈を読んだり複雑な論理を組み立てるのが得意 その分、 GPU メモリと処理時間が必要 GPT、Claude、Gemini など普段使っているモデルは 数千億〜 1 兆個以上のパラメータを持つと言われています(実際は非公開) 12
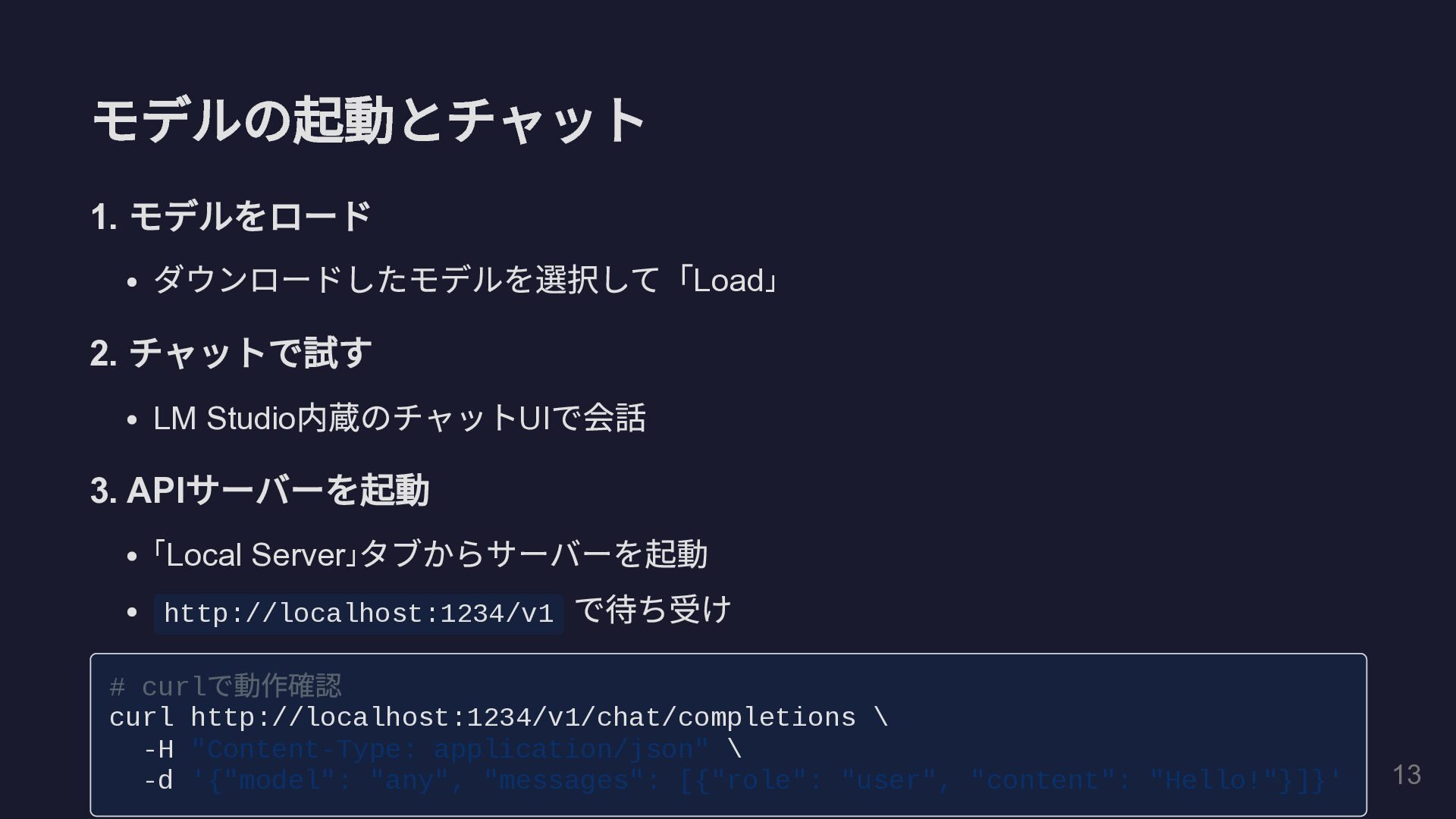
モデルの起動とチャット 1. モデルをロード ダウンロードしたモデルを選択して「 Load」 2. チャットで試す LM Studio 内蔵のチャット
UI で会話 3. API サーバーを起動 「Local Server」 タブからサーバーを起動 → http://localhost:1234/v1 で待ち受け # curl で動作確認 curl http://localhost:1234/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{"model": "any", "messages": [{"role": "user", "content": "Hello!"}]}' 13
実際の動作パフォーマンス 参考値( Qwen3.5-4B-GGUF / Vulkan GPU 利用時) 生成速度 : 約
30 tokens/ 秒 VRAM 使用量 : 約 3GB パフォーマンスに影響する要素 GPU/CPU のスペック モデルのパラメータ数・量子化レベル コンテキスト長の設定 モデルサイズと PC スペックのバランスが重要! まずは 4B くらいの小さいモデルから試すのがおすすめ 14
4. Java で LLM にアクセス LangChain4j 15
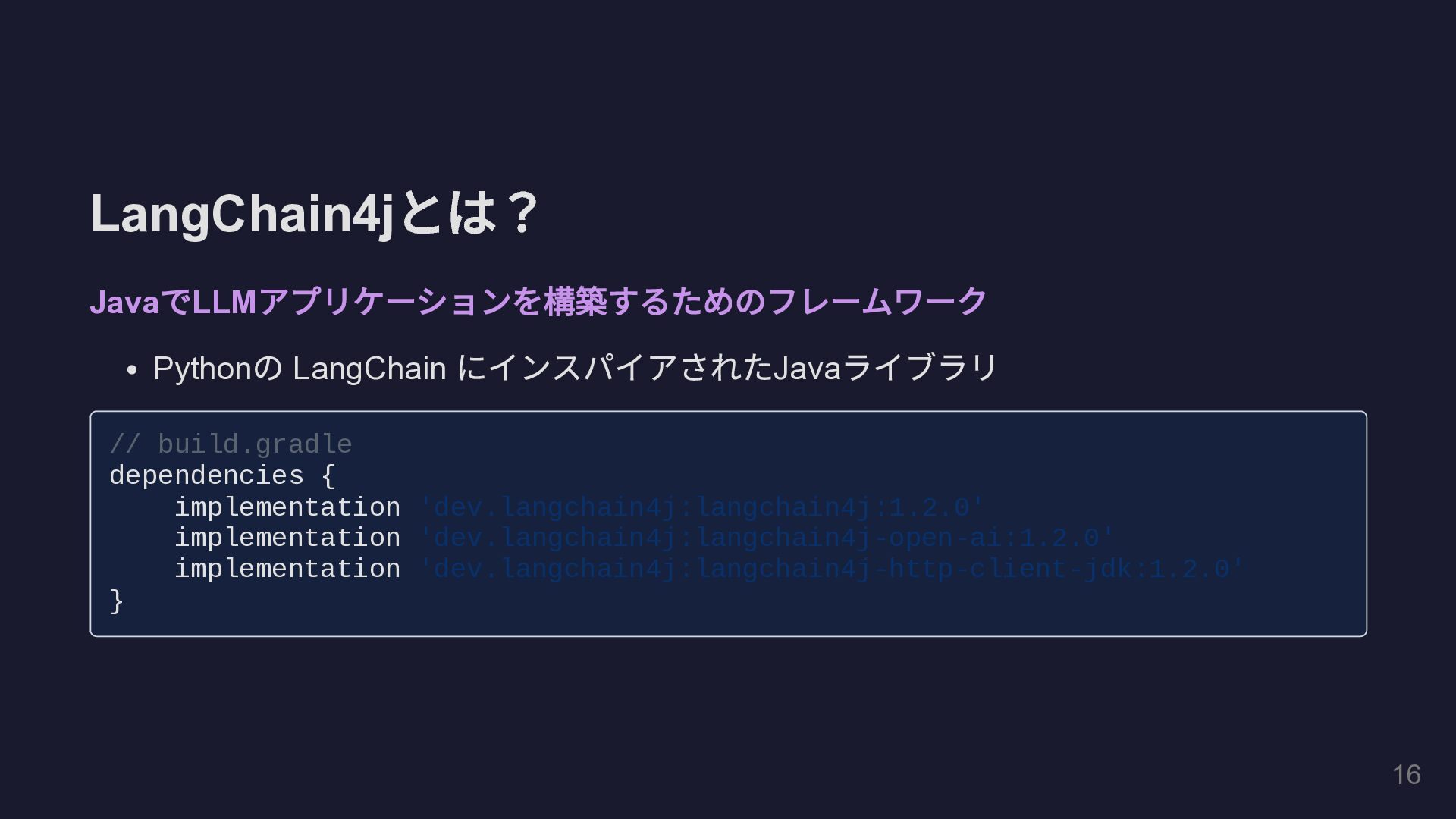
LangChain4j とは? Java で LLM アプリケーションを構築するためのフレームワーク Python の LangChain にインスパイアされた
Java ライブラリ // build.gradle dependencies { implementation 'dev.langchain4j:langchain4j:1.2.0' implementation 'dev.langchain4j:langchain4j-open-ai:1.2.0' implementation 'dev.langchain4j:langchain4j-http-client-jdk:1.2.0' } 16
LM Studio への接続設定 # application.yaml llm: base-url: http://localhost:1234/v1 api-key: dummy
model-name: Qwen3.5-4B-GGUF temperature: 0.8 request-timeout-seconds: 300 context-window: 262144 max-tokens: 262144 @ConfigurationProperties(prefix = "llm") public record LlmProperties( String baseUrl, String modelName, String apiKey, Double temperature, Long requestTimeoutSeconds, Integer maxTokens, Integer contextWindow ) {} 17
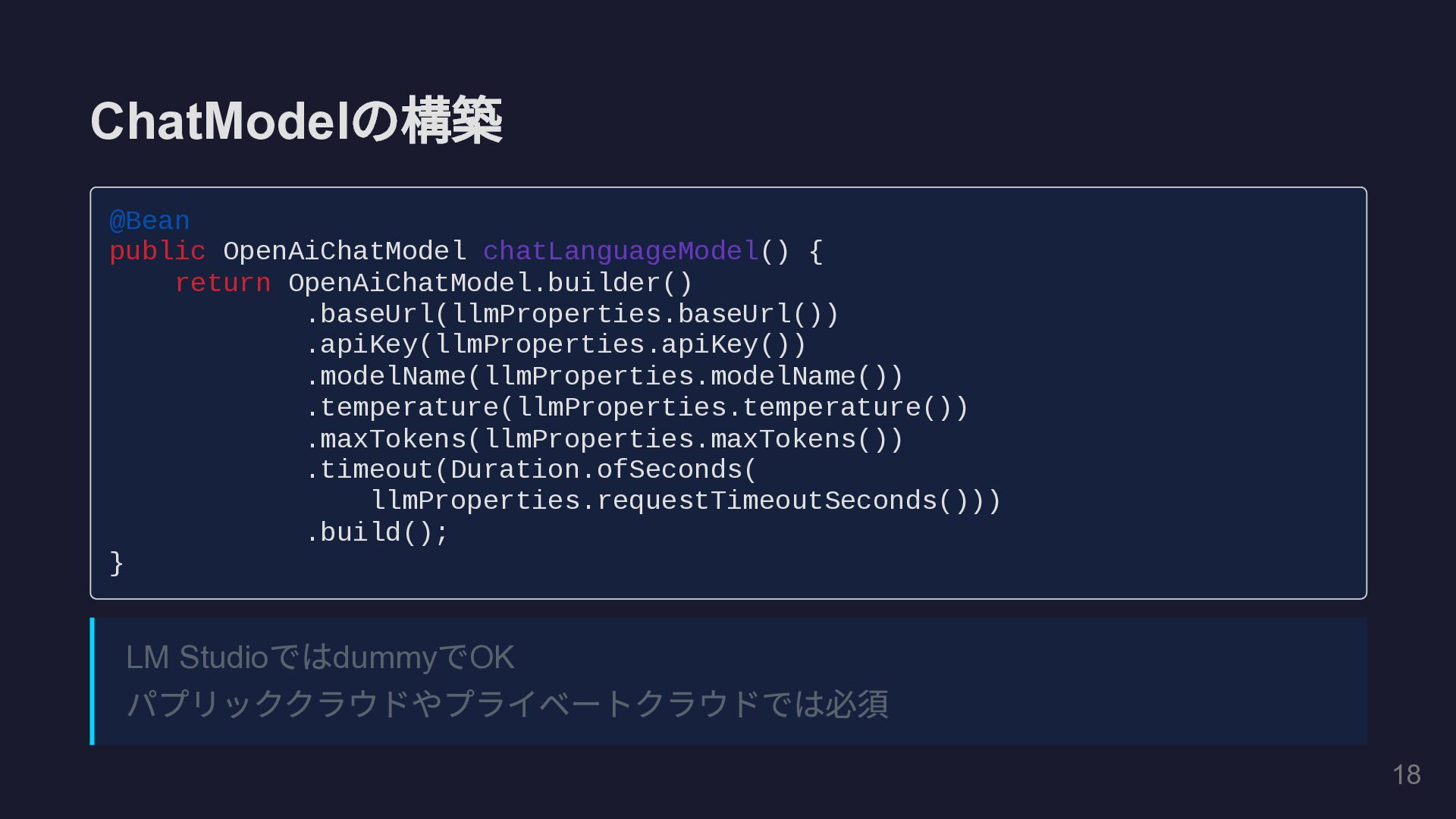
ChatModel の構築 @Bean public OpenAiChatModel chatLanguageModel() { return OpenAiChatModel.builder() .baseUrl(llmProperties.baseUrl())
.apiKey(llmProperties.apiKey()) .modelName(llmProperties.modelName()) .temperature(llmProperties.temperature()) .maxTokens(llmProperties.maxTokens()) .timeout(Duration.ofSeconds( llmProperties.requestTimeoutSeconds())) .build(); } LM Studio では dummy で OK パブリッククラウドやプライベートクラウドでは必須 18
実際のリクエスト(デバッグログ) POST /v1/chat/completions に OpenAI 互換の JSON 形式で送信 LM Studio
で起動中のモデルを指定 temperature , max_tokens などのパラメータも確認できる 19
LM Studio からのレスポンス OpenAI 互換の JSON 形式でレスポンスが返る <think> タグ内に Thinking
Process (思考過程)が含まれる( LM Studio の設定次 第) 20
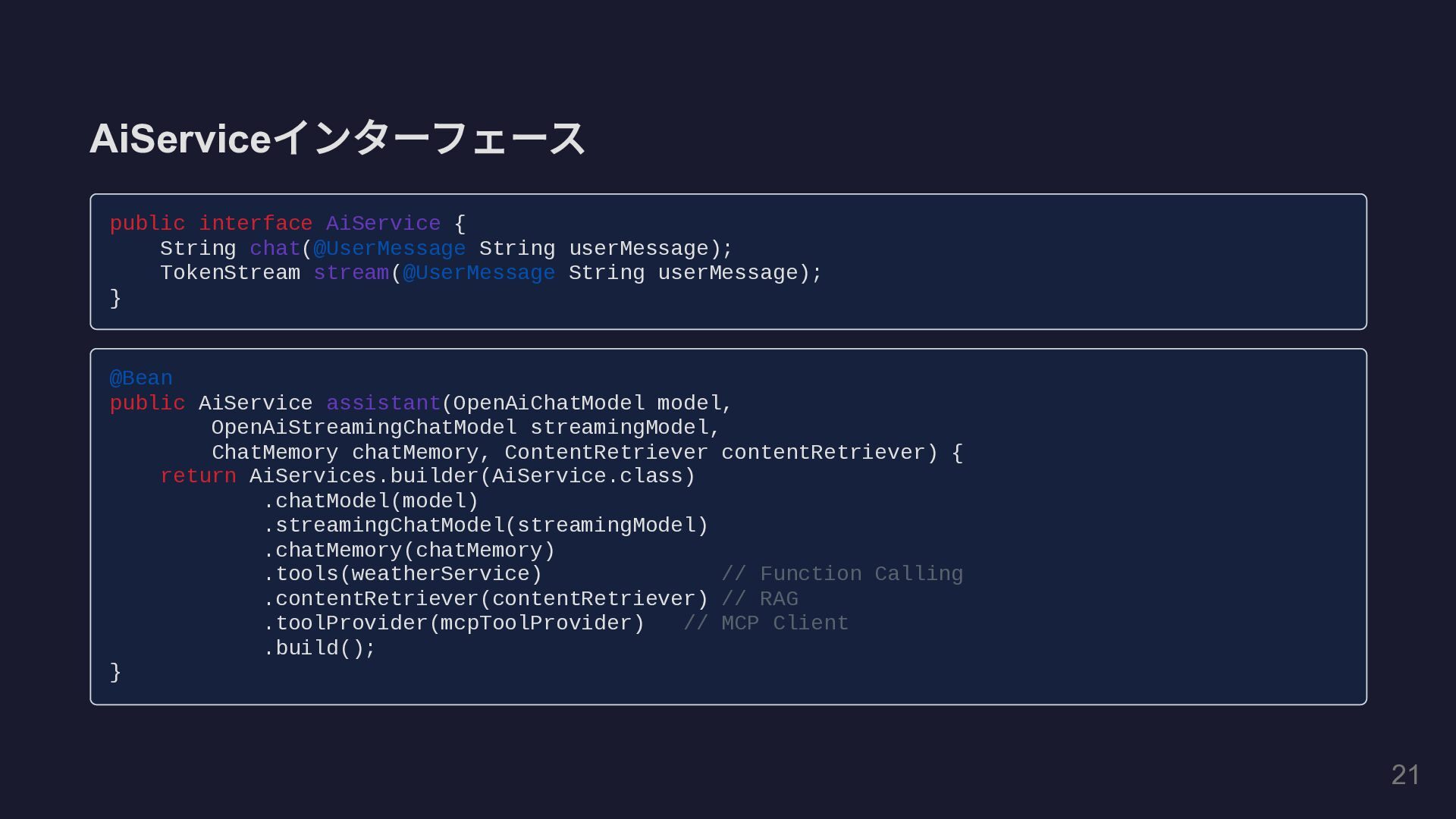
AiService インターフェース public interface AiService { String chat(@UserMessage String userMessage);
TokenStream stream(@UserMessage String userMessage); } @Bean public AiService assistant(OpenAiChatModel model, OpenAiStreamingChatModel streamingModel, ChatMemory chatMemory, ContentRetriever contentRetriever) { return AiServices.builder(AiService.class) .chatModel(model) .streamingChatModel(streamingModel) .chatMemory(chatMemory) .tools(weatherService) // Function Calling .contentRetriever(contentRetriever) // RAG .toolProvider(mcpToolProvider) // MCP Client .build(); } 21
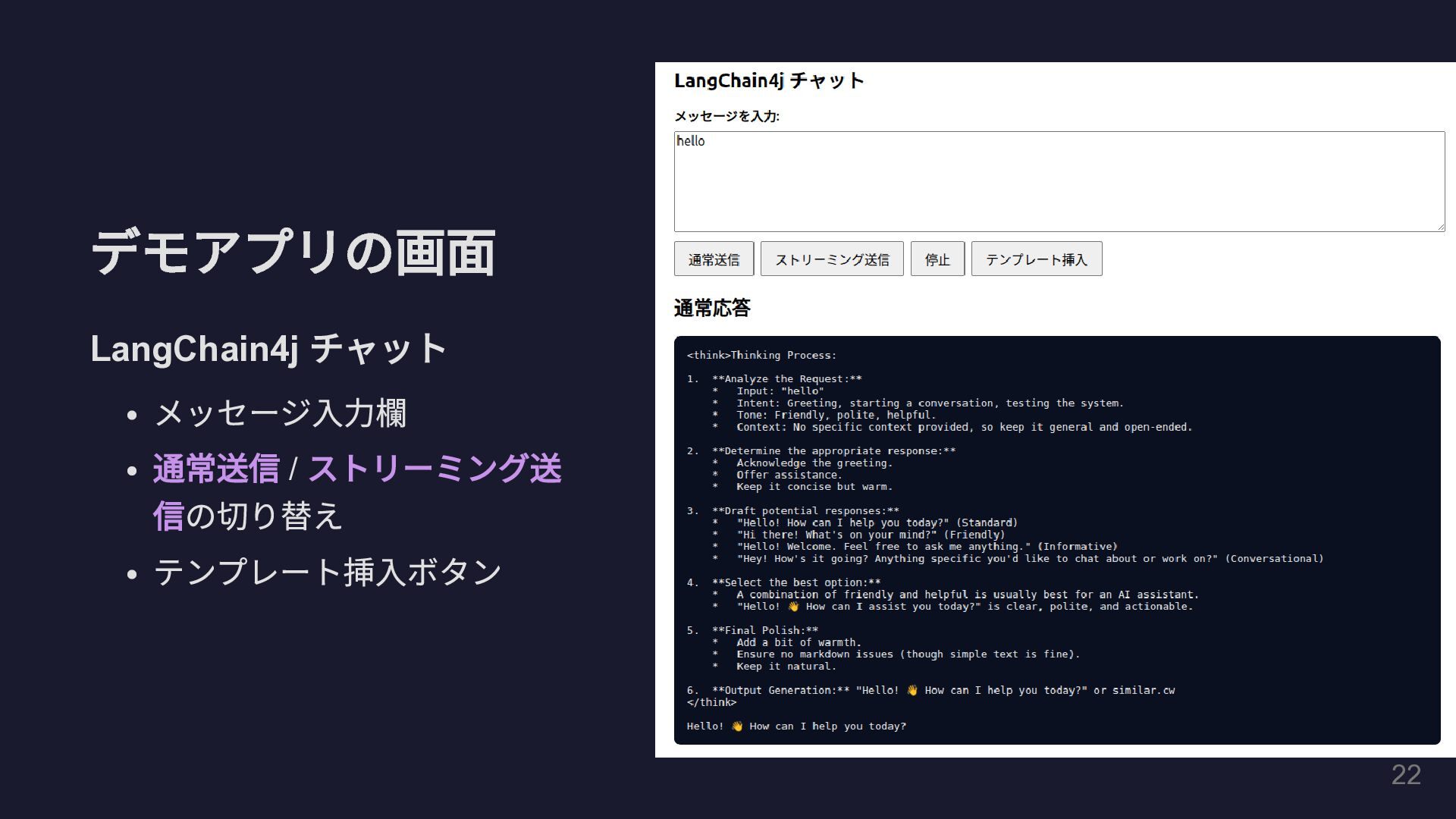
デモアプリの画面 LangChain4j チャット メッセージ入力欄 通常送信 / ストリーミング送 信の切り替え テンプレート挿入ボタン 22
5. Function Calling ( Tool use )と RAG 23
Function Calling とは? LLM が外部のツール(関数)を呼び出せる仕組み ユーザー: 「福岡の天気を教えて」 ↓ LLM: 「天気取得ツールを呼ぼう」→
getWeather(" 福岡") ↓ ツール実行 → 天気データ取得 ↓ LLM: 「福岡の天気は晴れです... 」 LLM 単体では知り得ないリアルタイム情報にアクセスできる LLM が自律的にどのツールを使うか判断する 24
LangChain4j での実装 @Service public class WeatherService { @Tool(" 与えられた場所の天気の情報を取得します。") public
String getWeather(String place) { log.info("place: {}", place); return " 晴れ 最高気温25 度"; } @Tool(" 現在時刻を返します") public String getTime() { return LocalDateTime.now().toString(); } } // AiService にツールを登録するだけ AiServices.builder(AiService.class) .chatModel(model) .tools(weatherService) // ← ツールを渡すだけ! .build(); 25
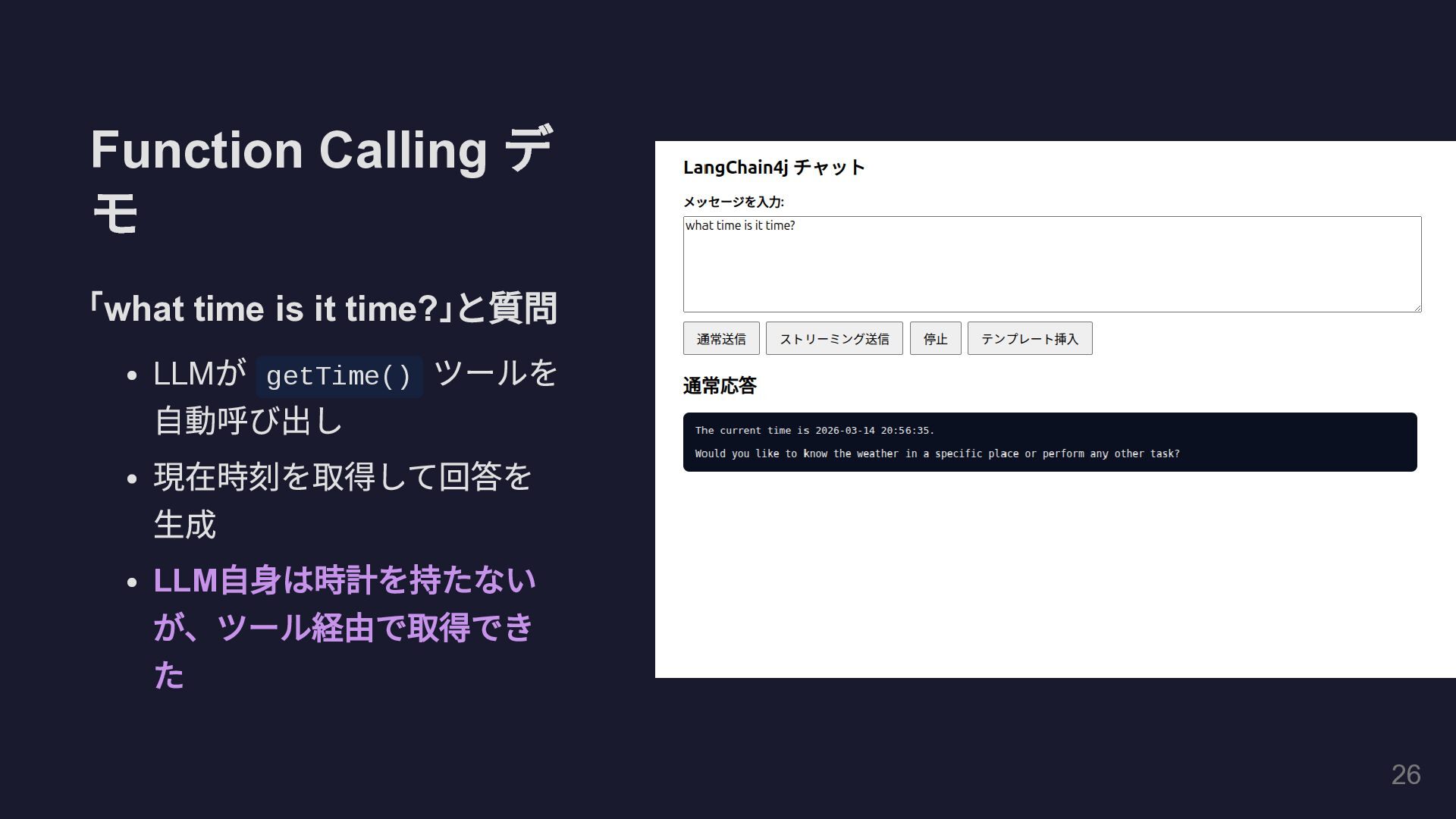
Function Calling デ モ 「what time is it now? 」
と質問 LLM が getTime() ツールを 自動呼び出し 現在時刻を取得して回答を 生成 LLM 自身は時計を持たない が、ツール経由で取得でき た 26
Function Calling ≒ Skills Skills ( Claude Code 等で定義する手順書)は、 Function
Calling で実装できる Skills Function Calling ( @Tool ) 定義 AI への手順指示書 Java メソッド+説明文 実行者 AI が手順に従って実行 LLM が自律的に呼び出し 利点 柔軟・自然言語で定義 型安全・テスト可能・安定 Skills で定義した手順を @Tool として実装すると、 LLM が「いつ使うか」を自律判断しつつ、実行は Java コードで安定動作する 27
Skill の定義例 : GitHub PR コメント取得 # GitHub PR 全コメント取得スキル
## 目的 Pull Request に対する「全体コメント(Conversation ) 」 と 「インラインコメント(Files changed ) 」 の両方を漏れなく取得する。 ## 実行ステップ 1. Owner 名・Repository 名・PR 番号を特定 2. 全体コメントを取得 → GET /repos/{owner}/{repo}/issues/{pr}/comments 3. インラインコメントを取得 → GET /repos/{owner}/{repo}/pulls/{pr}/comments 4. 結果を統合して提示 自然言語で手順と目的を記述するだけ 28
実装例 : GitHub PR コメント取得スキル @Service public class GitHubPrCommentService {
@Tool(""" GitHub Pull Request の全体コメントと インラインコメントの両方を取得して一覧表示します。 """) public String fetchAllPrComments( @P(" リポジトリのオーナー名") String owner, @P(" リポジトリ名") String repo, @P("PR 番号") int prNumber) { // GitHub REST API を HttpClient で直接呼び出し String issueComments = callGitHubApi( "/repos/%s/%s/issues/%d/comments" .formatted(owner, repo, prNumber)); String reviewComments = callGitHubApi( "/repos/%s/%s/pulls/%d/comments" .formatted(owner, repo, prNumber)); // ... 結果を整形して返却 } } 29
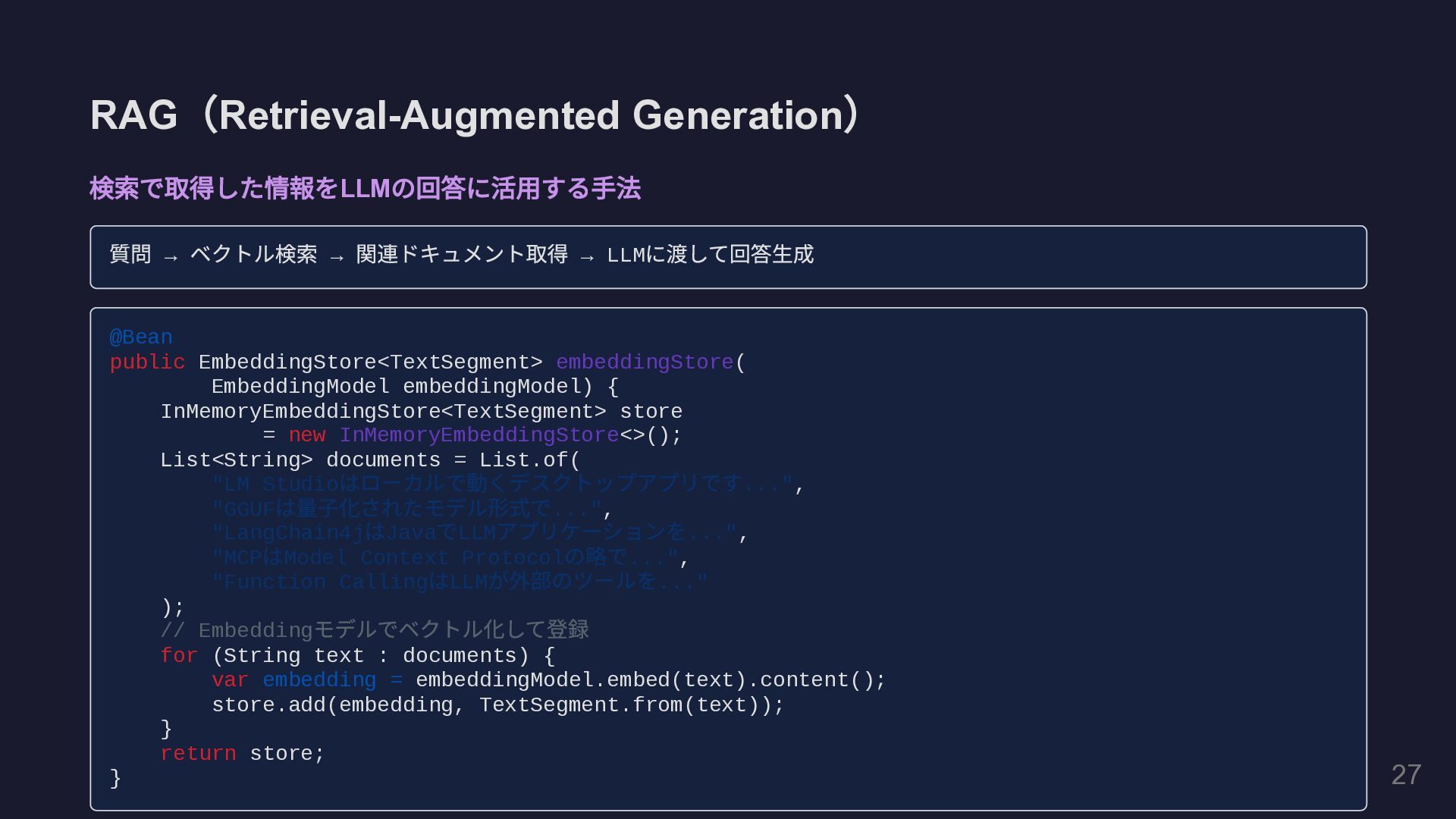
RAG ( Retrieval-Augmented Generation ) 検索で取得した情報を LLM の回答に活用する手法 質問 →
ベクトル検索 → 関連ドキュメント取得 → LLM に渡して回答生成 @Bean public EmbeddingStore<TextSegment> embeddingStore( EmbeddingModel embeddingModel) { InMemoryEmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>(); List<String> documents = List.of( "LM Studio はローカルで動くデスクトップアプリです...", "GGUF は量子化されたモデル形式で...", "LangChain4j はJava でLLM アプリケーションを...", "MCP はModel Context Protocol の略で...", "Function Calling はLLM が外部のツールを..." ); // Embedding モデルでベクトル化して登録 for (String text : documents) { var embedding = embeddingModel.embed(text).content(); store.add(embedding, TextSegment.from(text)); } return store; } 30
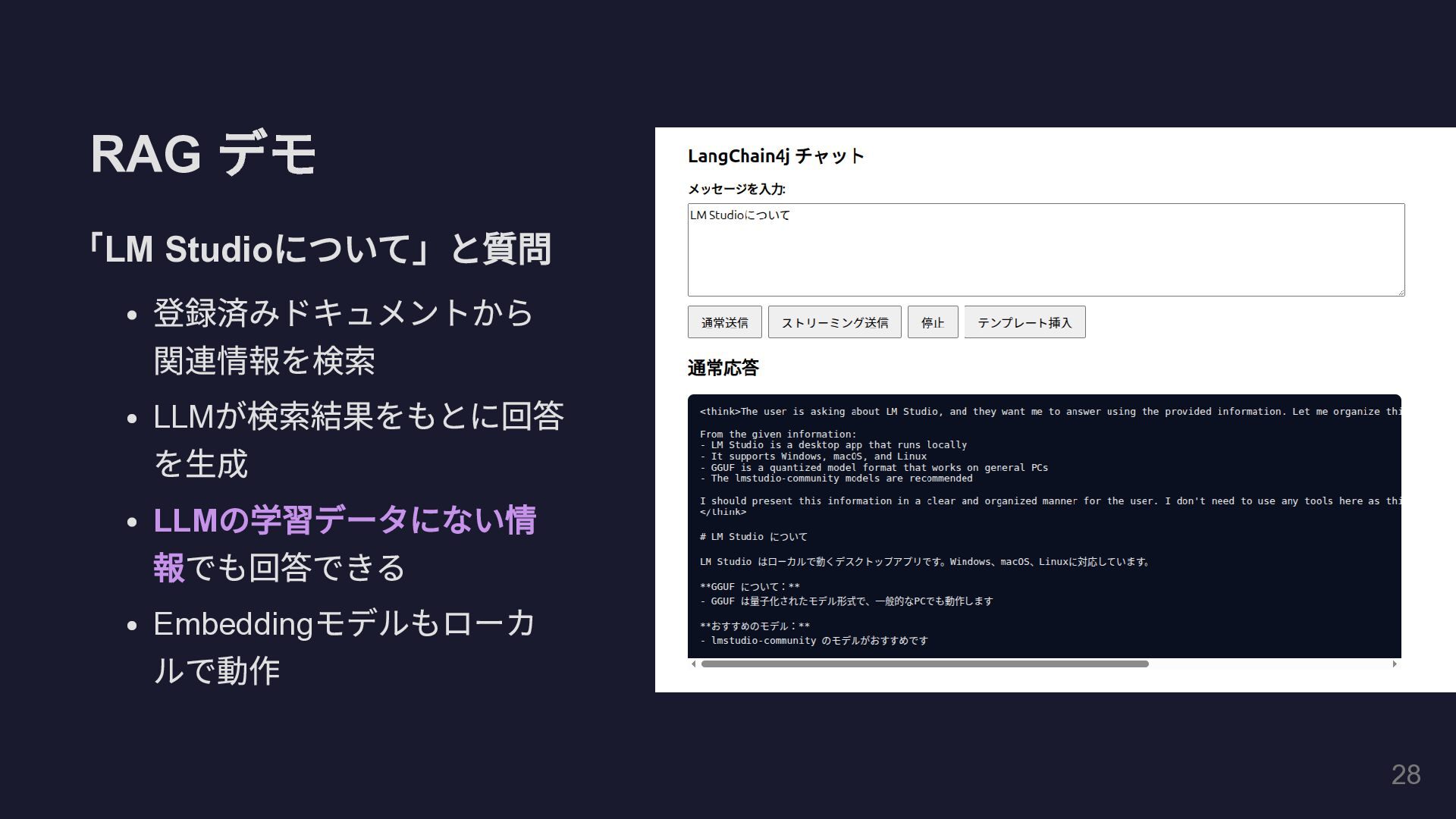
RAG デモ 「LM Studio について」と質問 登録済みドキュメントから 関連情報を検索 LLM が検索結果をもとに回答 を生成
LLM の学習データにない情 報でも回答できる Embedding モデルもローカ ルで動作 31
6. MCP サーバー / クライアント 32
MCP ( Model Context Protocol )とは? LLM とツールを繋ぐ標準プロトコル LLM アプリ(MCP
クライアント) MCP MCP サーバー(ツール提供) 外部サービス(GitHub, ファイルシステムなど) Anthropic が提唱したオープン標準 ツールの発見・呼び出しを統一的に行える 様々な MCP サーバーが公開されている 33
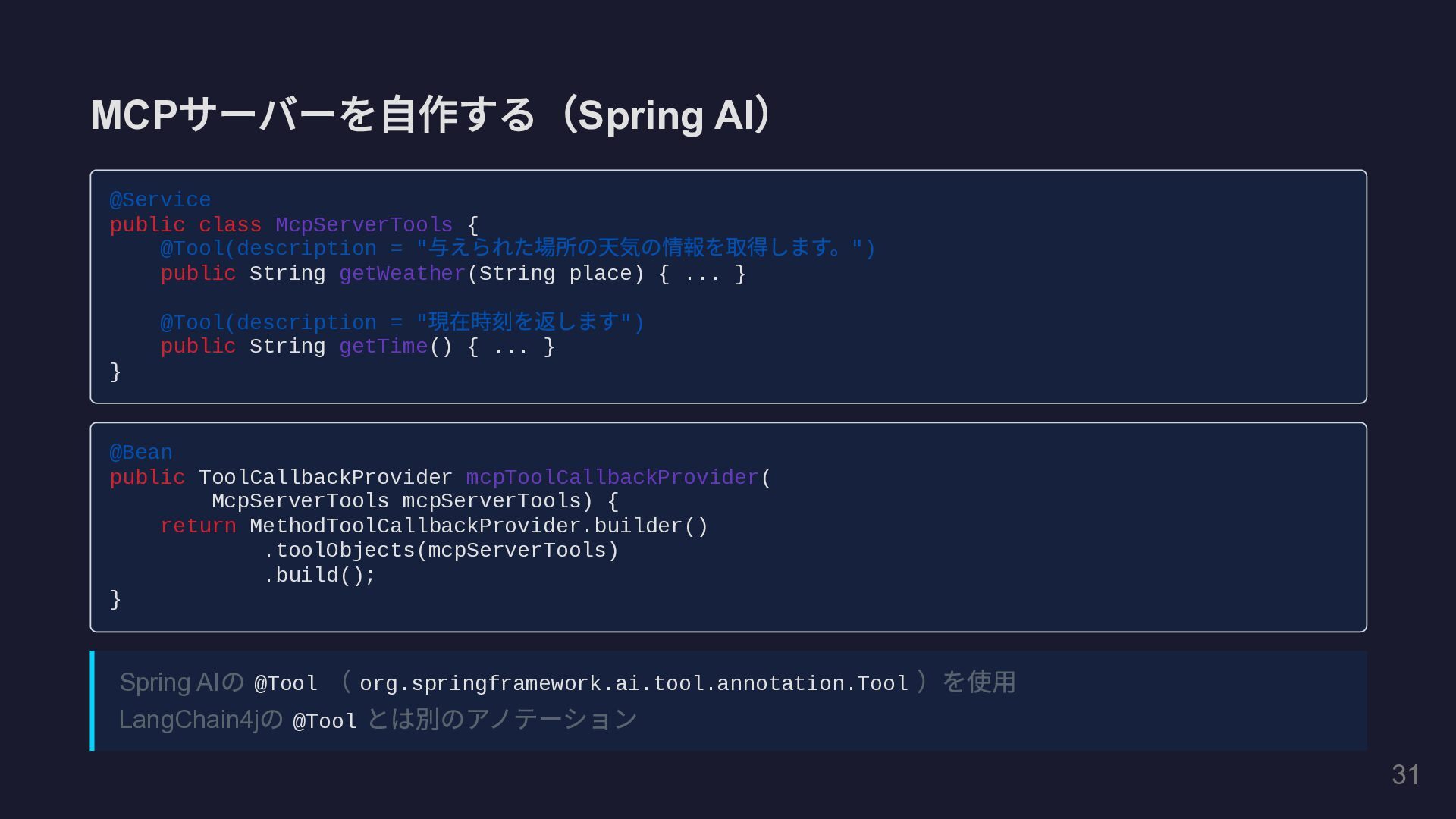
MCP サーバーを自作する( Spring AI ) @Service public class McpServerTools {
@Tool(description = " 与えられた場所の天気の情報を取得します。") public String getWeather(String place) { ... } @Tool(description = " 現在時刻を返します") public String getTime() { ... } } @Bean public ToolCallbackProvider mcpToolCallbackProvider( McpServerTools mcpServerTools) { return MethodToolCallbackProvider.builder() .toolObjects(mcpServerTools) .build(); } Spring AI の @Tool ( org.springframework.ai.tool.annotation.Tool )を使用 LangChain4j の @Tool とは別のアノテーション 34
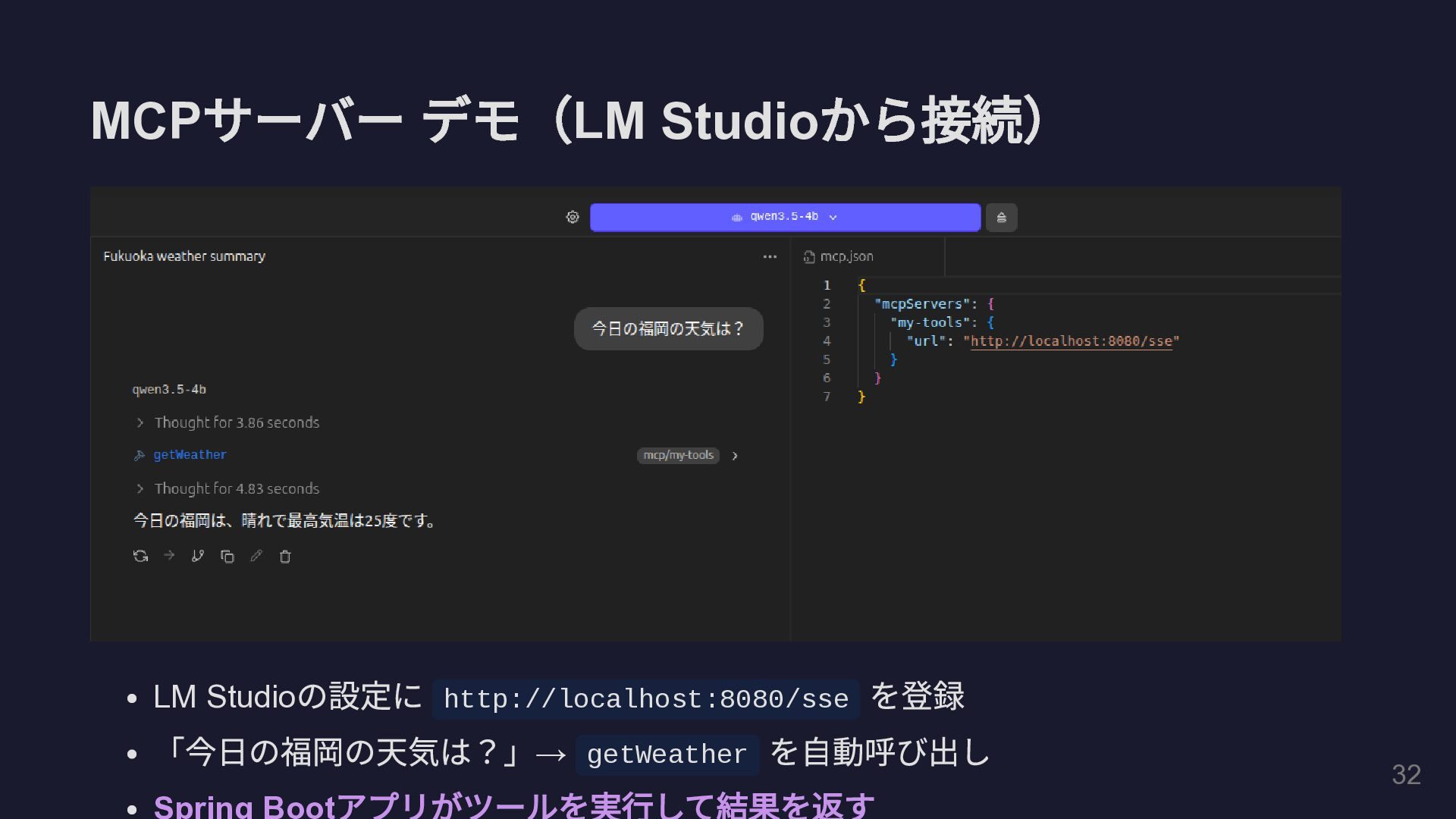
MCP サーバー デモ( LM Studio から接続) LM Studio の設定に http://localhost:8080/sse
を登録 「今日の福岡の天気は?」 → getWeather を自動呼び出し Spring Boot アプリがツールを実行して結果を返す 35
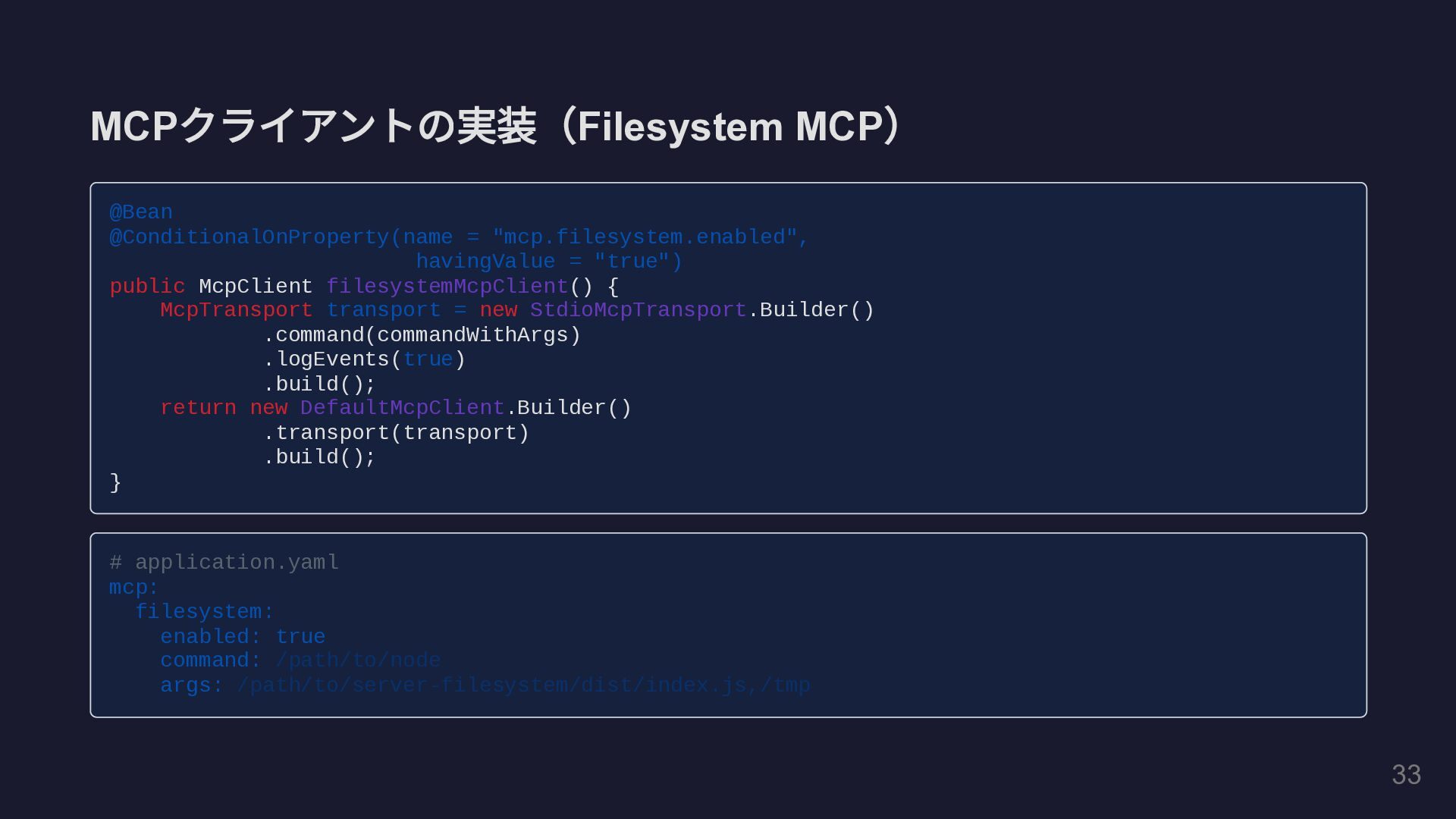
MCP クライアントの実装( Filesystem MCP ) @Bean @ConditionalOnProperty(name = "mcp.filesystem.enabled", havingValue
= "true") public McpClient filesystemMcpClient() { McpTransport transport = new StdioMcpTransport.Builder() .command(commandWithArgs) .logEvents(true) .build(); return new DefaultMcpClient.Builder() .transport(transport) .build(); } # application.yaml mcp: filesystem: enabled: true command: /path/to/node args: /path/to/server-filesystem/dist/index.js,/tmp 36
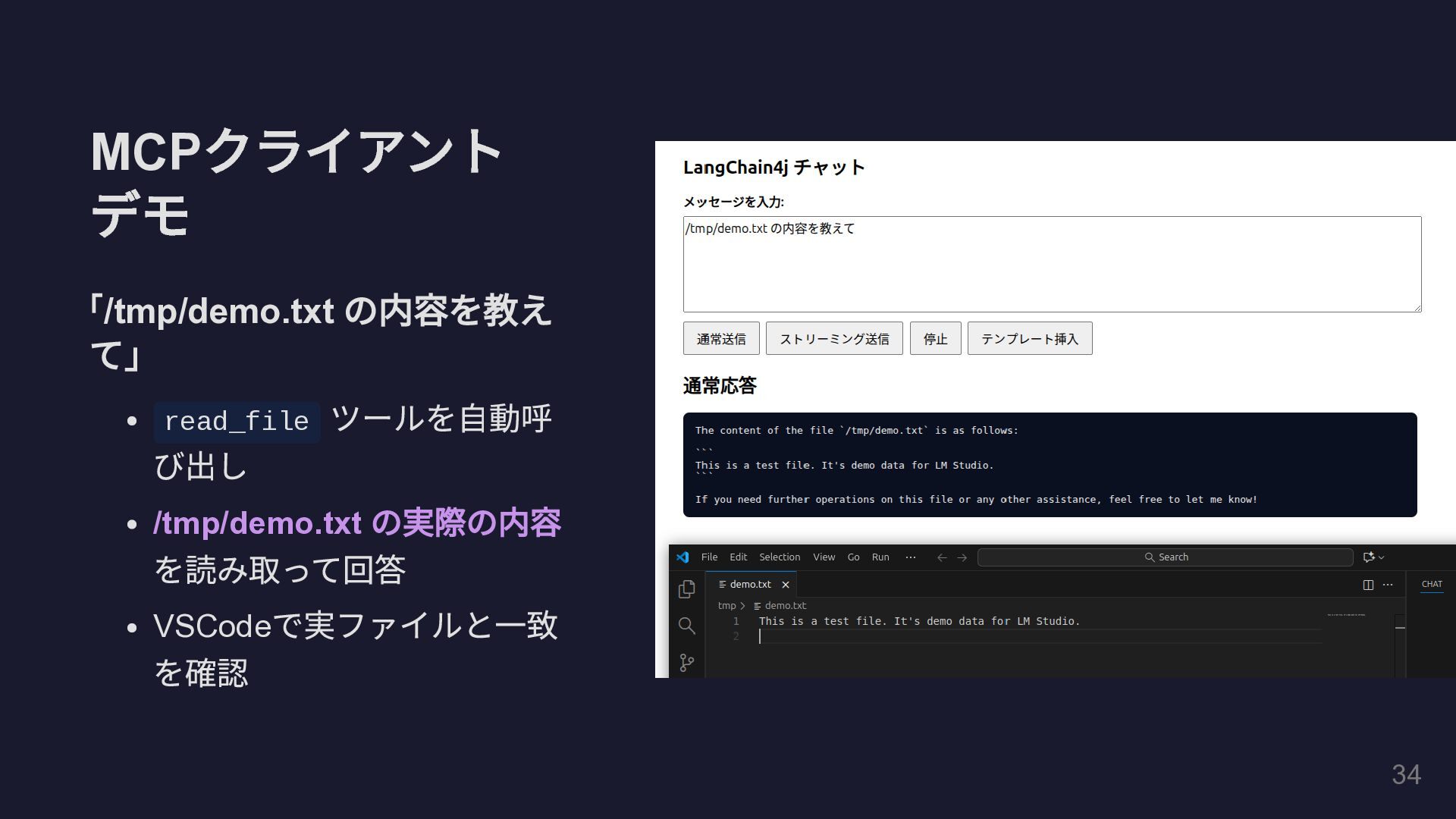
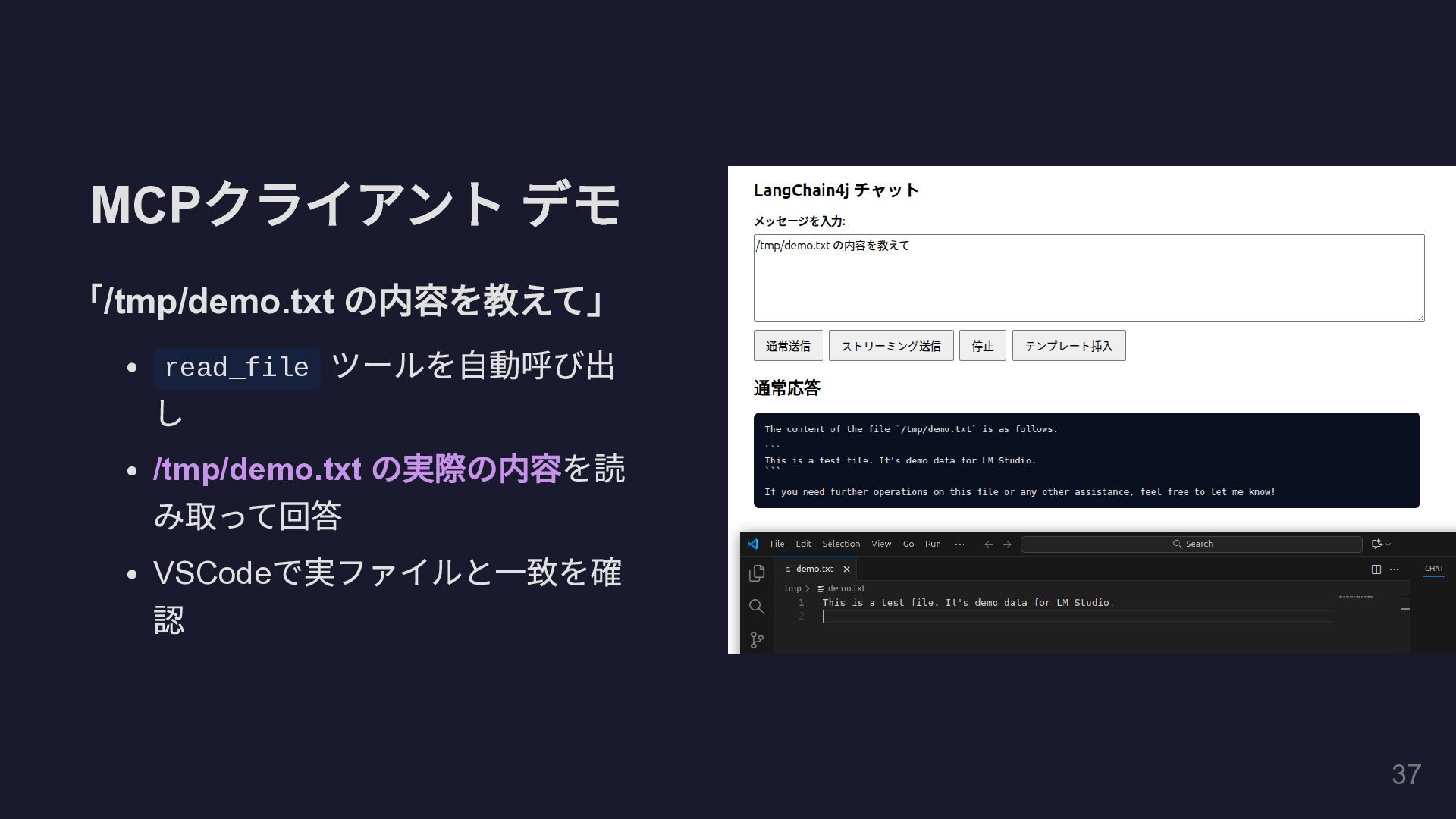
MCP クライアント デモ 「/tmp/demo.txt の内容を教えて」 read_file ツールを自動呼び出 し /tmp/demo.txt の実際の内容を読
み取って回答 VSCode で実ファイルと一致を確 認 37
ローカル LLM を試してわかったこと ローカル LLM を手元で試すことで、アプリケーションの動き方がわかった気がする (浅い) Function Calling や
RAG、MCP を組み合わせると LLM 単体の限界を超えられる 一方で、 1 つの AI に全部任せると品質・速度に限界があるのも実感した この気づきを踏まえて、さらに一歩先に進んでみましょう 38
7. 応用 AI エージェントのオーケストレーション 39
なぜオーケストレーション? ローカル LLM を試して、 1 つの AI との対話でできることと限界が見えてきました。 しかし実際の開発では、タスクは多岐にわたります。 設計、実装、テスト、レビュー
… 一人の AI に全部任せるのは非効率 得意分野が異なる AI を役割分担させたらどうなる? 人間のチーム開発と同じように、 AI にもチームを組ませる発想 サブエージェントやエージェントチームとの違い サブエージェント( Claude Code 等)は同一プロダクト内の親子関係 エージェントチーム( CrewAI, AutoGen 等)は同一 LLM プロバイダ内での役割分担 これらでは Claude Code・Copilot・Gemini を直接つなぎ込むことができない 今回のアプローチでは、ステップベースで並列実行・条件分岐・障害復旧まで制御する Function Calling や MCP で「ツールとの連携」ができるなら、 次は 「AI 製品を横断した連携」 に挑戦してみよう 40
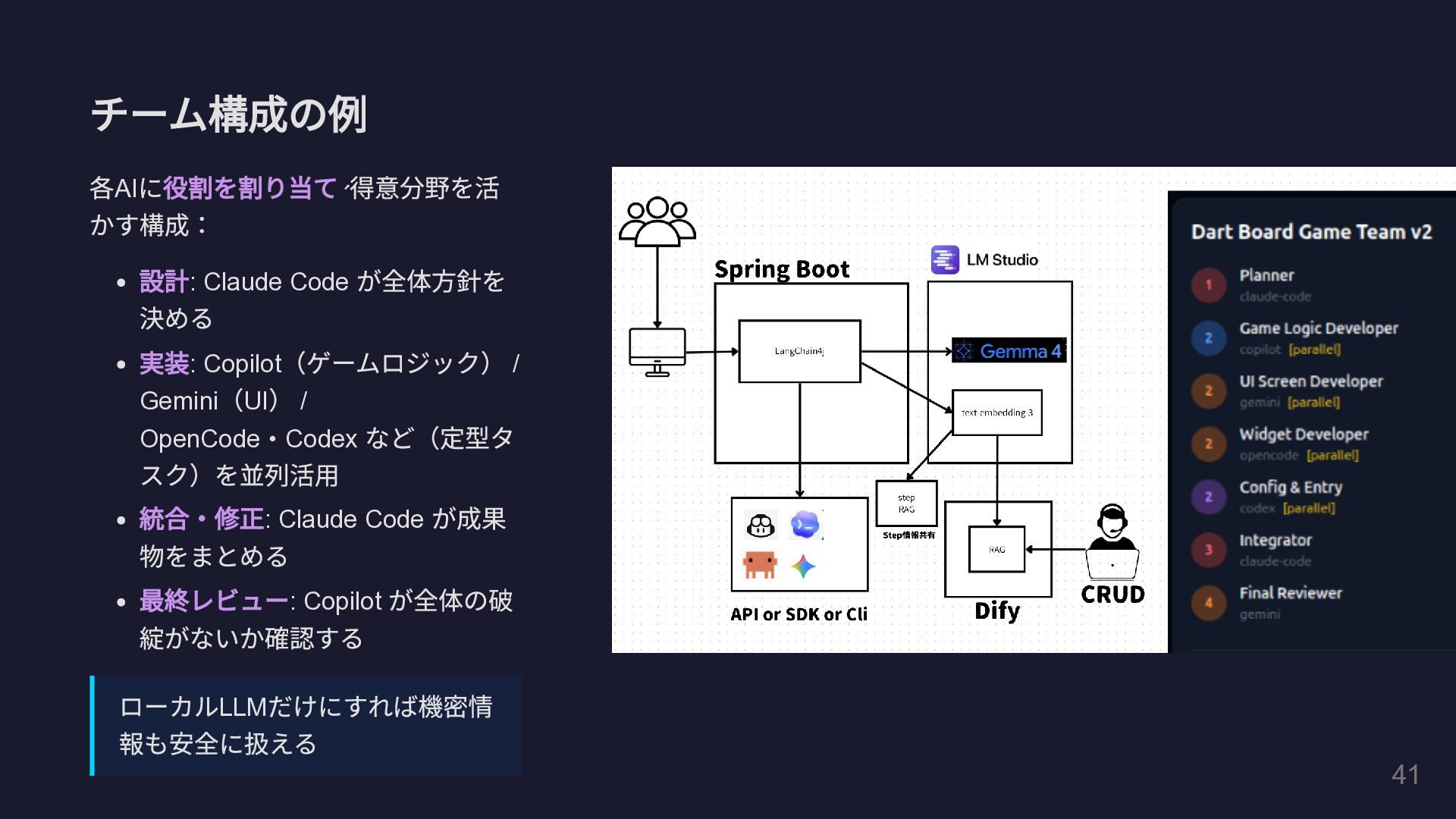
チーム構成の例 各 AI に役割を割り当て、 得意分野を活 かす構成: 設計 : Claude Code
が全体方針を 決める 実装 : Copilot (ゲームロジック) / Gemini ( UI ) / OpenCode・Codex など(定型タ スク)を並列活用 統合・修正 : Claude Code が成果 物をまとめる 最終レビュー : Copilot が全体の破 綻がないか確認する ローカル LLM だけにすれば機密情 報も安全に扱える 41
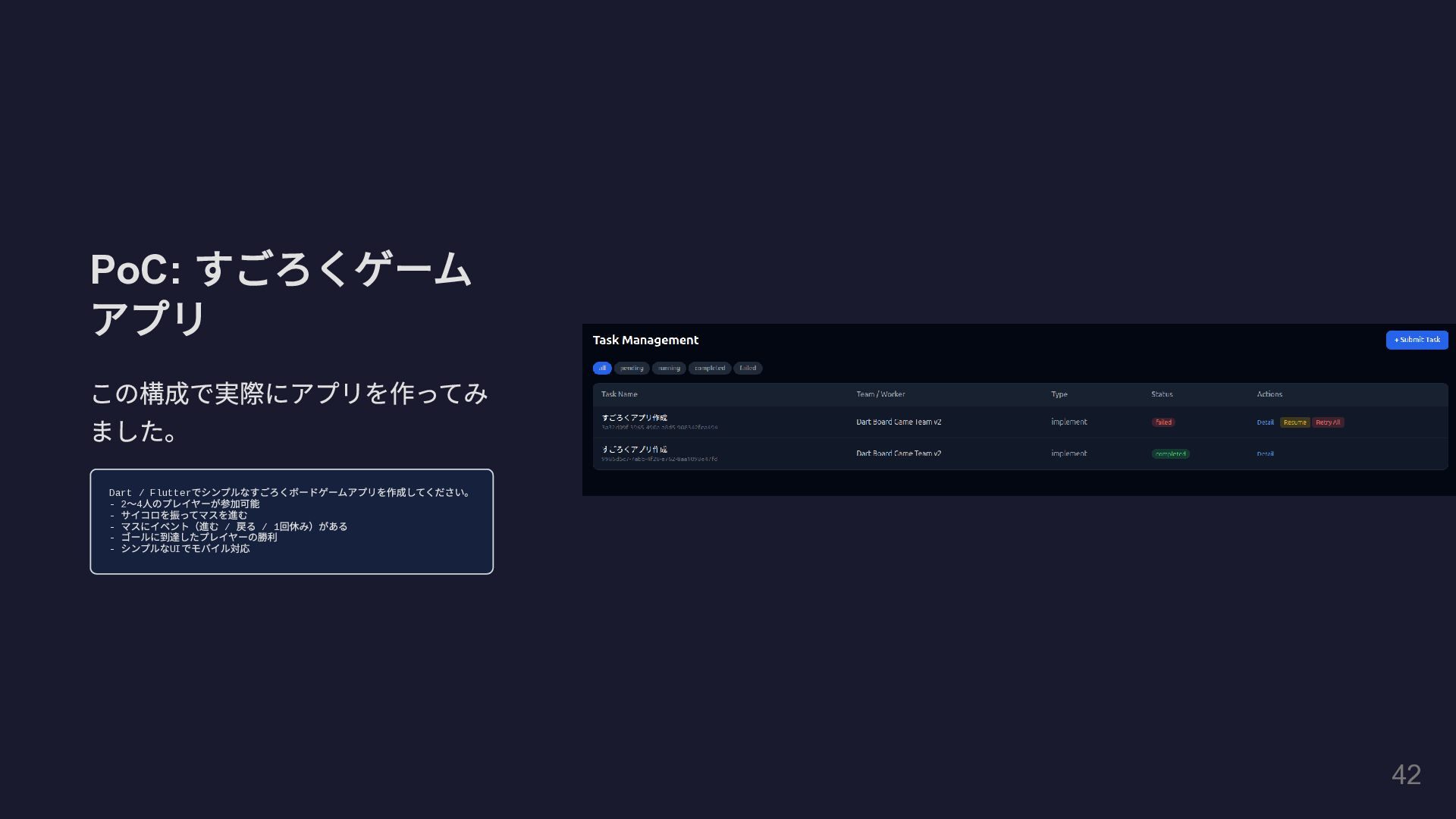
PoC: すごろくゲーム アプリ この構成で実際にアプリを作ってみ ました。 Dart / Flutter でシンプルなすごろくボードゲームアプリを作成してください。 -
2 〜4 人のプレイヤーが参加可能 - サイコロを振ってマスを進む - マスにイベント(進む / 戻る / 1 回休み)がある - ゴールに到達したプレイヤーの勝利 - シンプルなUI でモバイル対応 42
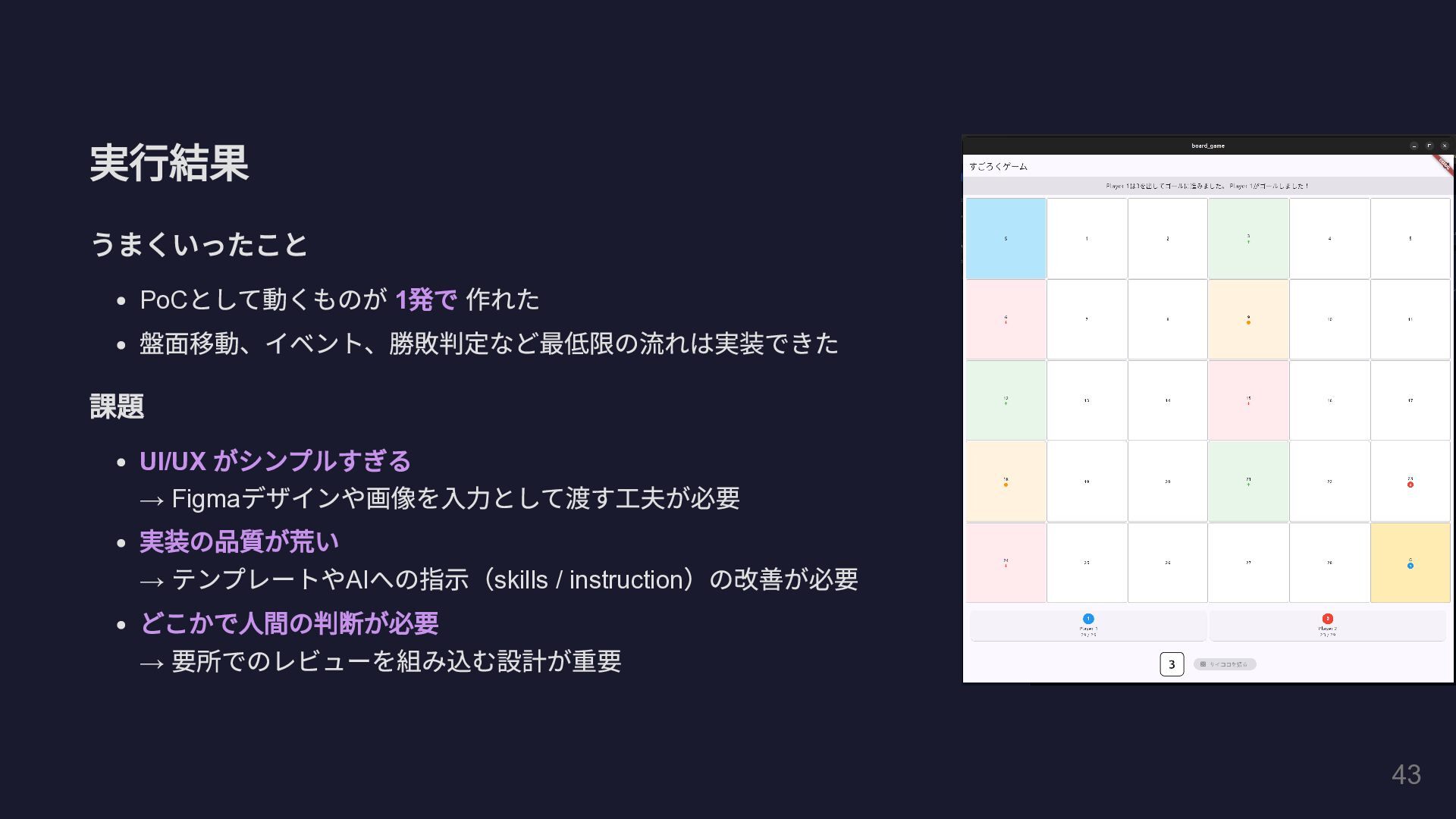
実行結果 うまくいったこと PoC として動くものが 1 発で 作れた 盤面移動、イベント、勝敗判定など最低限の流れは実装できた 課題 UI/UX
がシンプルすぎる → Figma デザインや画像を入力として渡す工夫が必要 実装の品質が荒い → テンプレートや AI への指示( skills / instruction )の改善が必要 どこかで人間の判断が必要 → 要所でのレビューを組み込む設計が重要 43
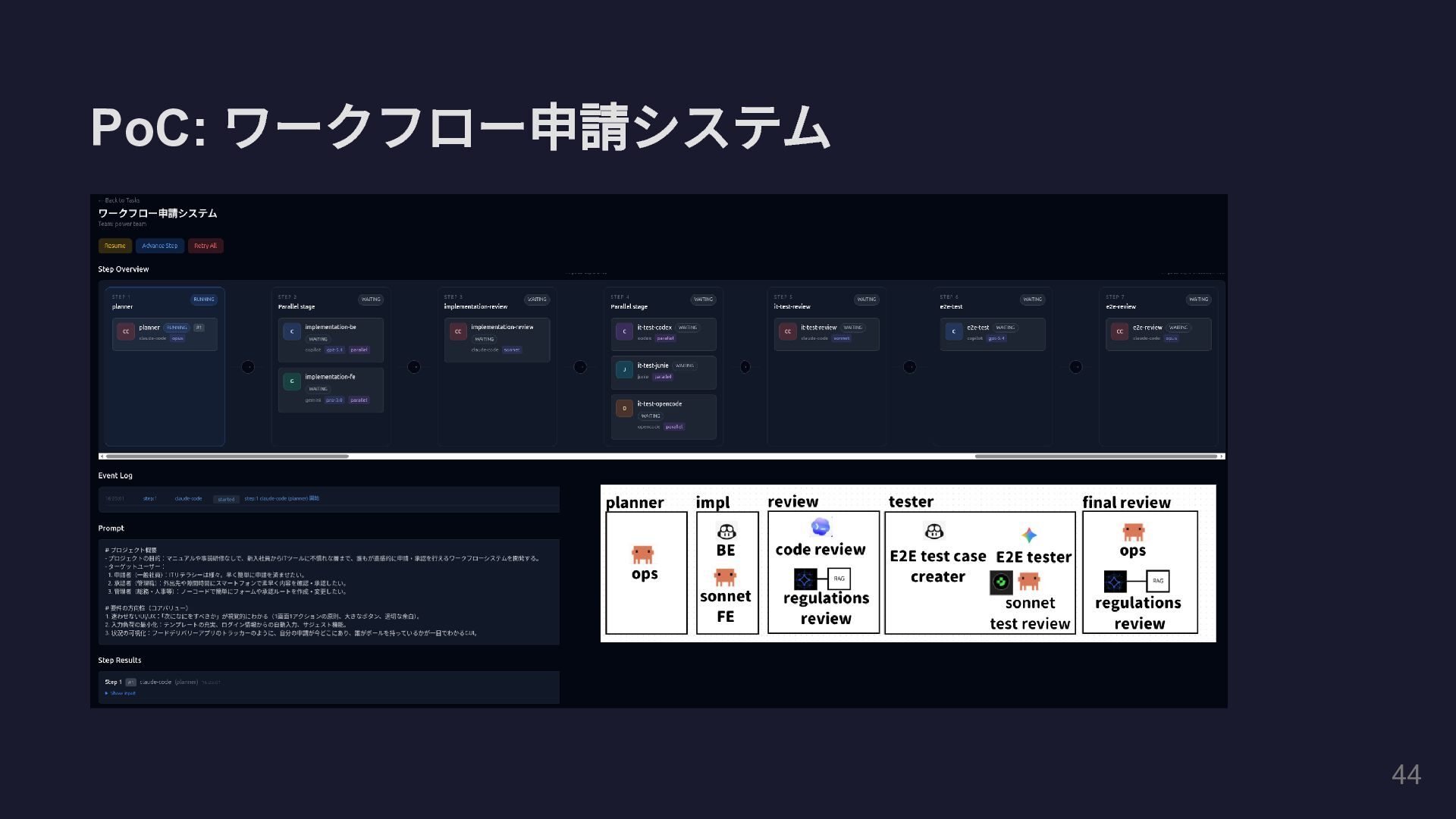
PoC: ワークフロー申請システム 44
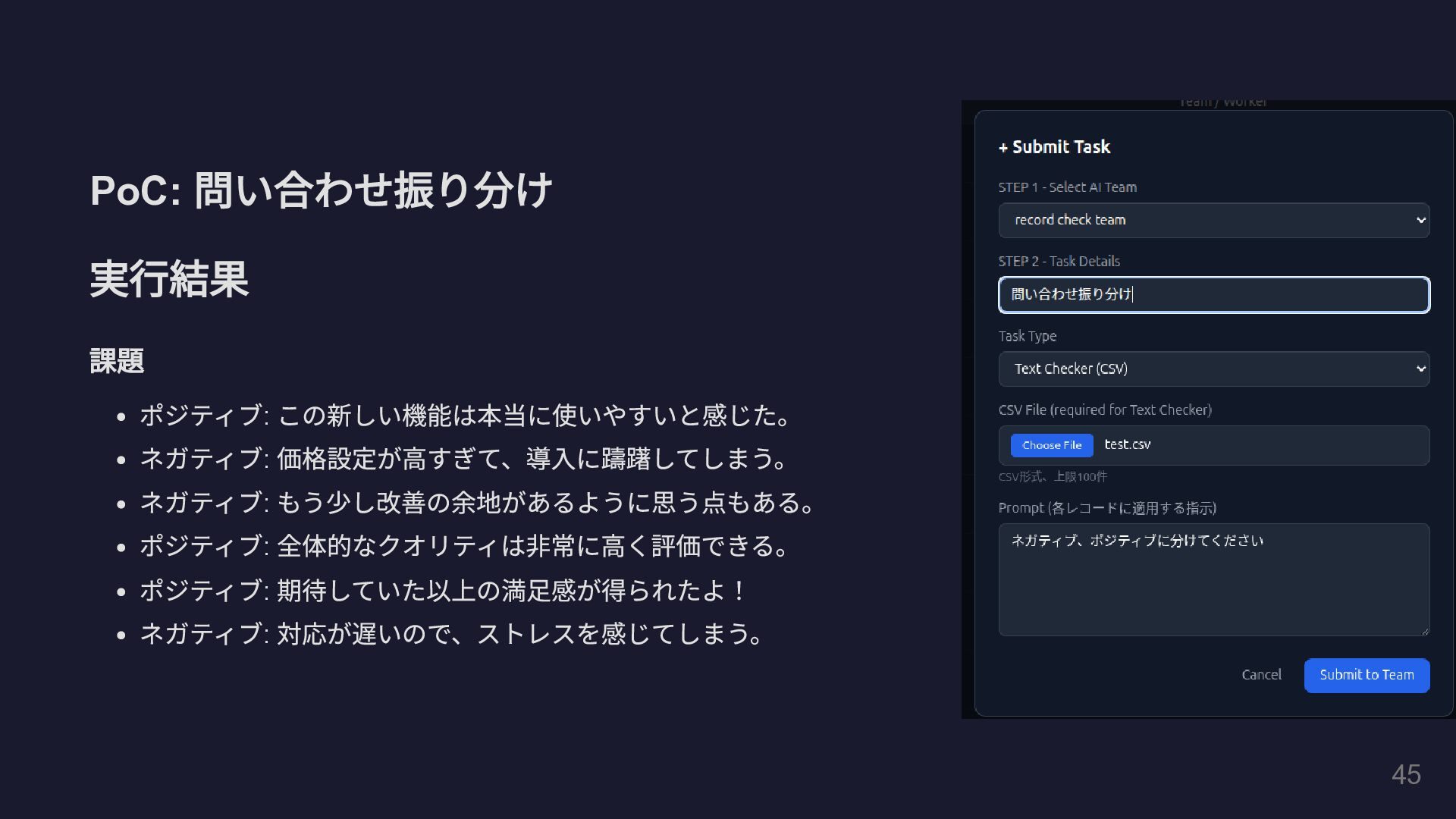
PoC: 問い合わせ振り分け 実行結果 課題 ポジティブ : この新しい機能は本当に使いやすいと感じた。 ネガティブ : 価格設定が高すぎて、導入に躊躇してしまう。
ネガティブ : もう少し改善の余地があるように思う点もある。 ポジティブ : 全体的なクオリティは非常に高く評価できる。 ポジティブ : 期待していた以上の満足感が得られたよ! ネガティブ : 対応が遅いので、ストレスを感じてしまう。 45
オーケストレーションの学び 開発の基本は今までと変わらない: 設計 → 実装 → レビュー → テスト ->
強制させる。 AI に自由度を与えすぎると品質がブレる。 ワークフローに沿った動きを強制する 仕組みが効果的 どこで並列してパフォーマンス出すか、どこで人間が判断するかの設計が重要 46
まとめ LM Studio + LangChain4j から広がる活用 1. 無料でローカル LLM を動かせる
2. Function Calling で LLM が外部ツールと連携 3. RAG でドメイン知識を活用 4. MCP クライアント /MCP サーバーでツール連携 5. 複数 AI の役割分担で開発プロセス自体も設計対象になる 6. PoC が自宅で簡単に作れる → アイデア次第で何でもできる ローカル LLM は開発・検証・学習の強力なパートナー! 47
ありがとうございました! ソースコード このリポジトリのコードを参照してください 参考リンク LM Studio: https://lmstudio.ai LangChain4j: https://docs.langchain4j.dev MCP:
https://modelcontextprotocol.io 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}