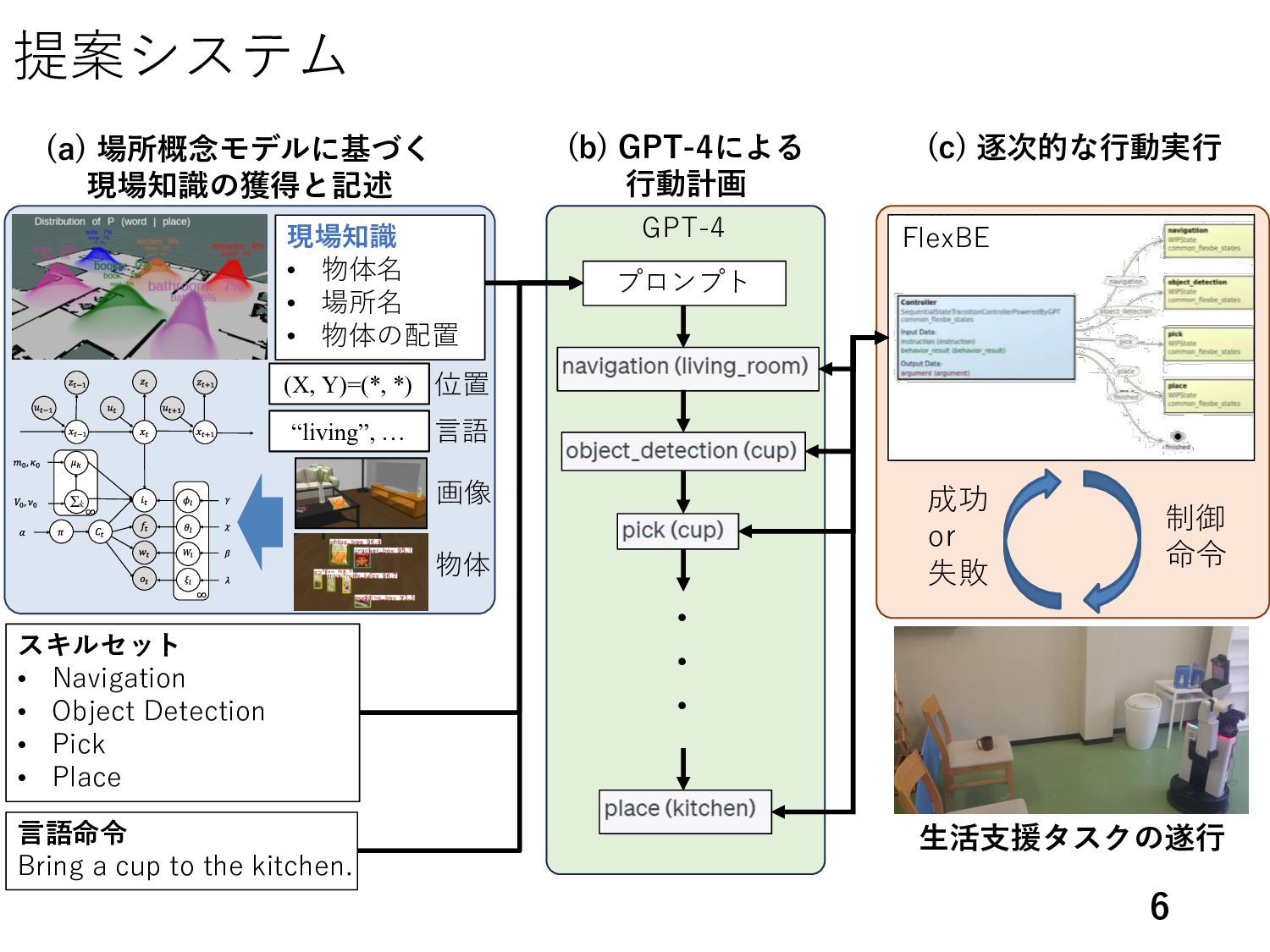
Inner Monologue [3] 大規模言語モデル 現場の知識 • 物体リスト • 場所のリスト • 物体の配置 ・・・ ロボットのスキル • Navigation • Object Detection • Picking ・・・ 言語指示:Bring a cup to the kitchen. 行動列 navigation (living_room) ・・・ Bedroomにあるのは, book, pen, chair, …に, 場所はdining, kitchen,…に, … 記載することがいっぱいだよ! [1] S. Vemprala, et al. “ChatGPT for Robotics: Design Principles and Model Abilities“, Microsoft Technical Report-2023-8, 2023. [2] M. Ahn, et al. "Do As I Can, Not As I Say: Grounding Language in Robotic Affordances." arXiv preprint arXiv:2204.01691, 2022. [3] W. Huang, et al. “Inner Monologue: Embodied Reasoning through Planning with Language Models " arXiv preprint arXiv: 2207.05608, 2022. 現場環境
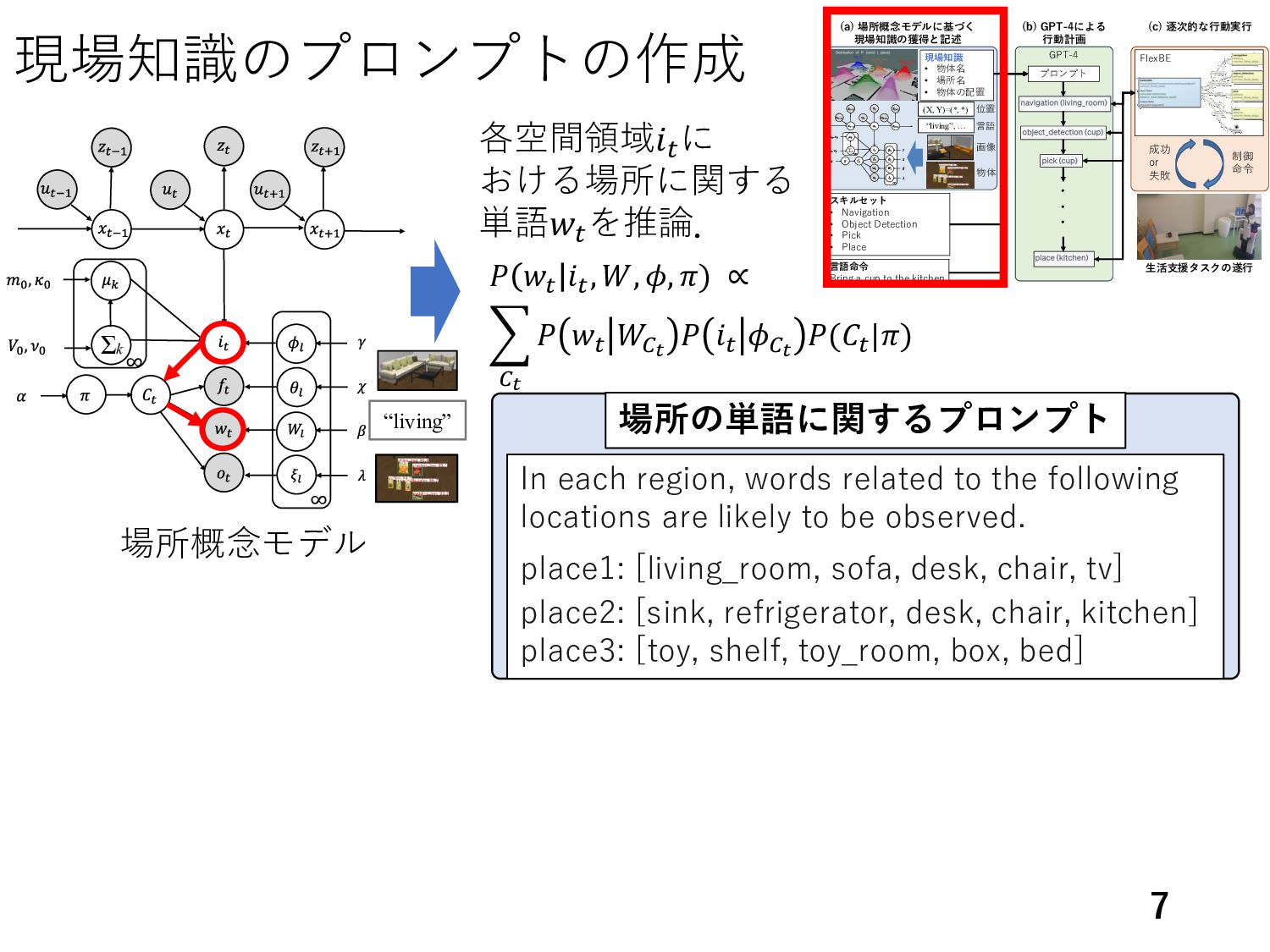
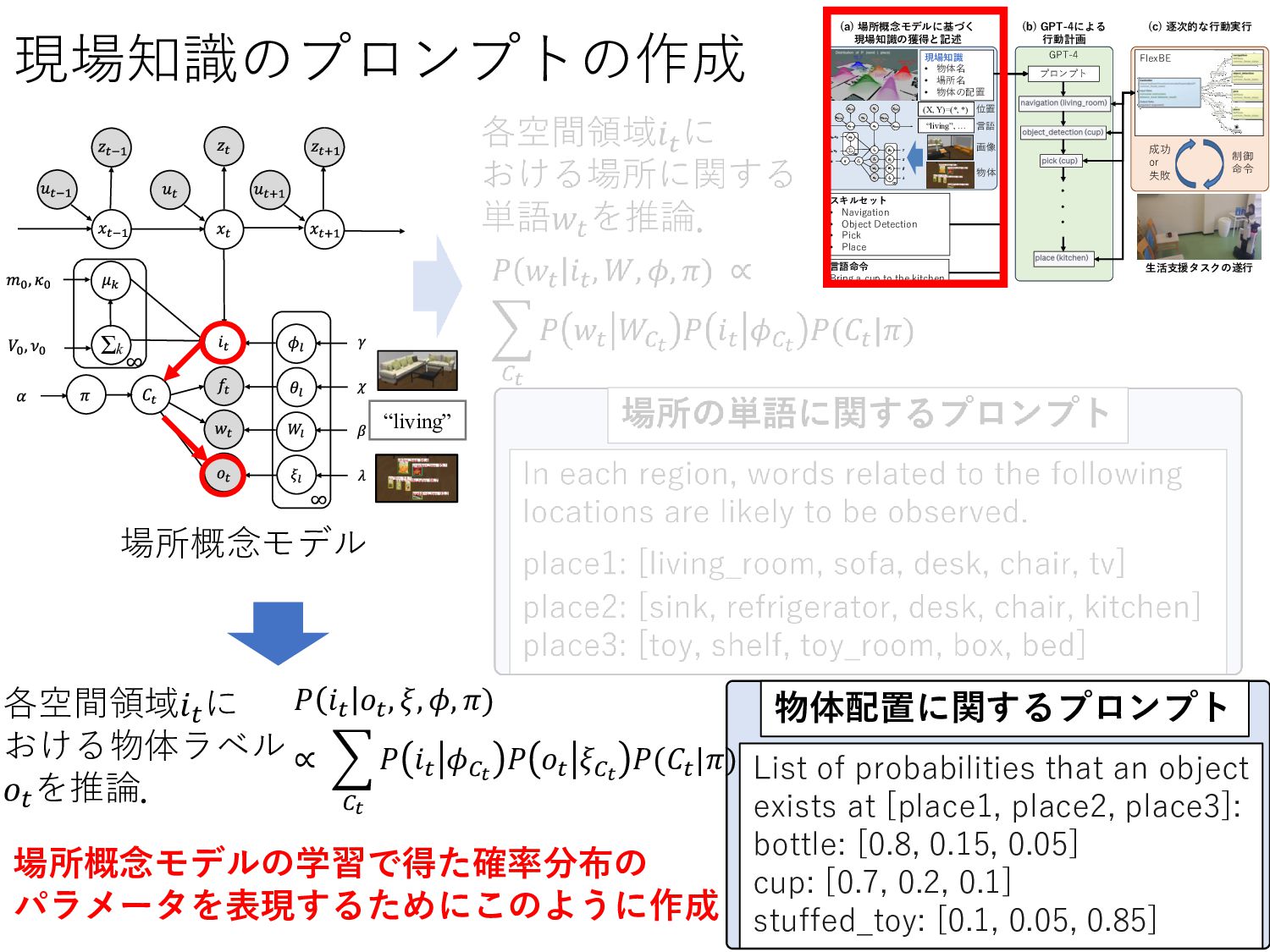
ion ick ace 生活支援タスクの 行 命 or e による 行動計画 言語 rin a c p o he ki chen 物体 画 living , 言語 置 , , 現場知識 物体 場所 物体の配置 的な行動 行 場所概念モデルに 現場知識の と記述 プロンプト 現場知識のプロンプトの作 7 𝑃 𝑤𝑡 𝑖𝑡 , 𝑊, 𝜙, 𝜋) ∝ 𝐶𝑡 𝑃 𝑤𝑡 𝑊𝐶𝑡 𝑃 𝑖𝑡 𝜙𝐶𝑡 𝑃(𝐶𝑡 |𝜋) 場所概念モデル 各空間領域𝑖𝑡 に おける場所に関する 単語𝑤𝑡 を推論. In each region, words related to the following locations are likely to be observed. place1: [living_room, sofa, desk, chair, tv] place2: [sink, refrigerator, desk, chair, kitchen] place3: [toy, shelf, toy_room, box, bed] “living” 場所の単語に関するプロ プト
place1: [living_room, sofa, desk, chair, tv] … 物体の配 情報 bottle: [0.8, 0.15, 0.05] … 1. navigation (location_name) 2. object_detection (object_name) 3. pick (object_name) 4. place (location_name) These behaviors return "succeeded" or "failed". If "failed" is returned, try the same or another behavior again. 言語指示 Could you please find a snack box I'm looking for? プロンプト [6] OpenAI, “GPT-4 Technical Report”, arXiv preprint arXiv: 2303.08774, 2023. Prompt is here: https://github.com/Shoichi-Hasegawa0628/rsj2023_prompt GPT-4 ・ ・ スキル ット a i a ion b ec e ec ion ick ace 生活支援タスクの 行 命 or e による 行動計画 言語 rin a c p o he ki chen 物体 画 living , 言語 置 , , 現場知識 物体 場所 物体の配置 的な行動 行 場所概念モデルに 現場知識の と記述 プロンプト 現場知識に き行動計画を行うため,探索する部屋数の削減が期待できる.
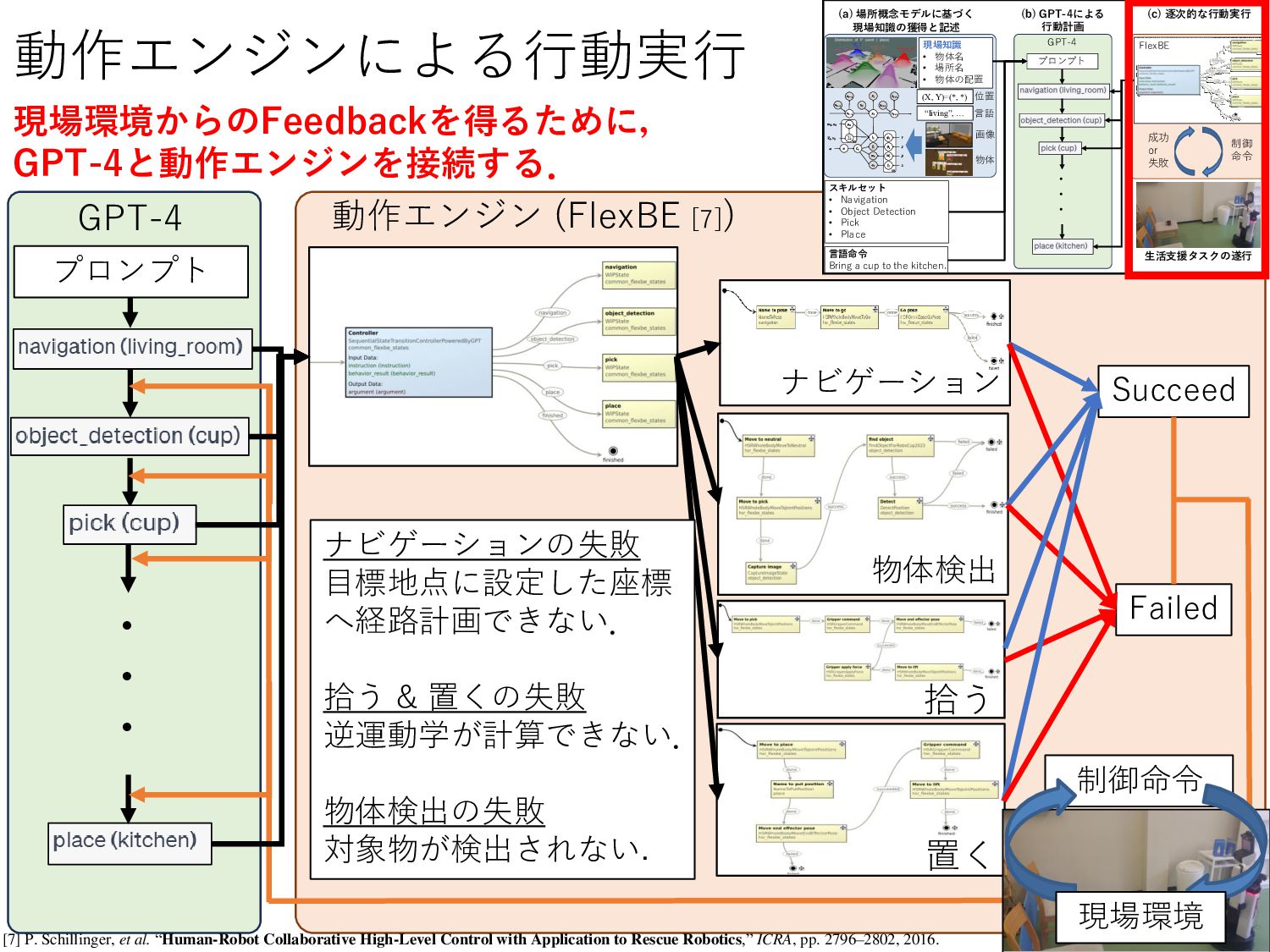
(FlexBE [7]) [7] P. Schillinger, et al. “Human-Robot Collaborative High-Level Control with Application to Rescue Robotics,” ICRA, pp. 2796–2802, 2016. ナビゲーション 物体検出 置く 拾う Failed Succeed ナビゲーションの 目標地点に設定した座標 へ経路計画できない. 拾う & 置くの 逆運動学が計算できない. 物体検出の 対象物が検出されない. 命 現場環境 スキル ット a i a ion b ec e ec ion ick ace 生活支援タスクの 行 命 or e による 行動計画 言語 rin a c p o he ki chen 物体 画 living , 言語 置 , , 現場知識 物体 場所 物体の配置 的な行動 行 場所概念モデルに 現場知識の と記述 プロンプト
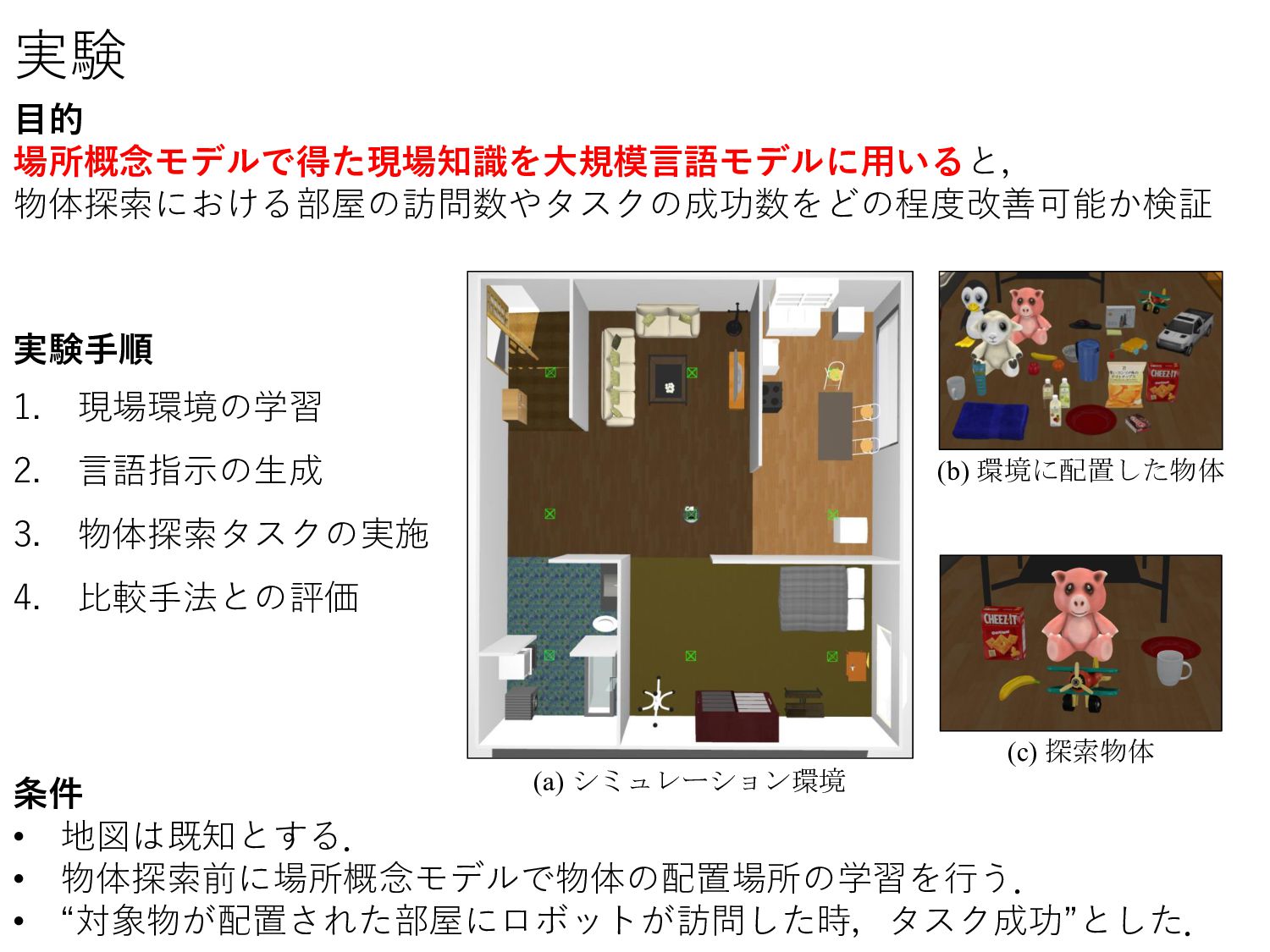
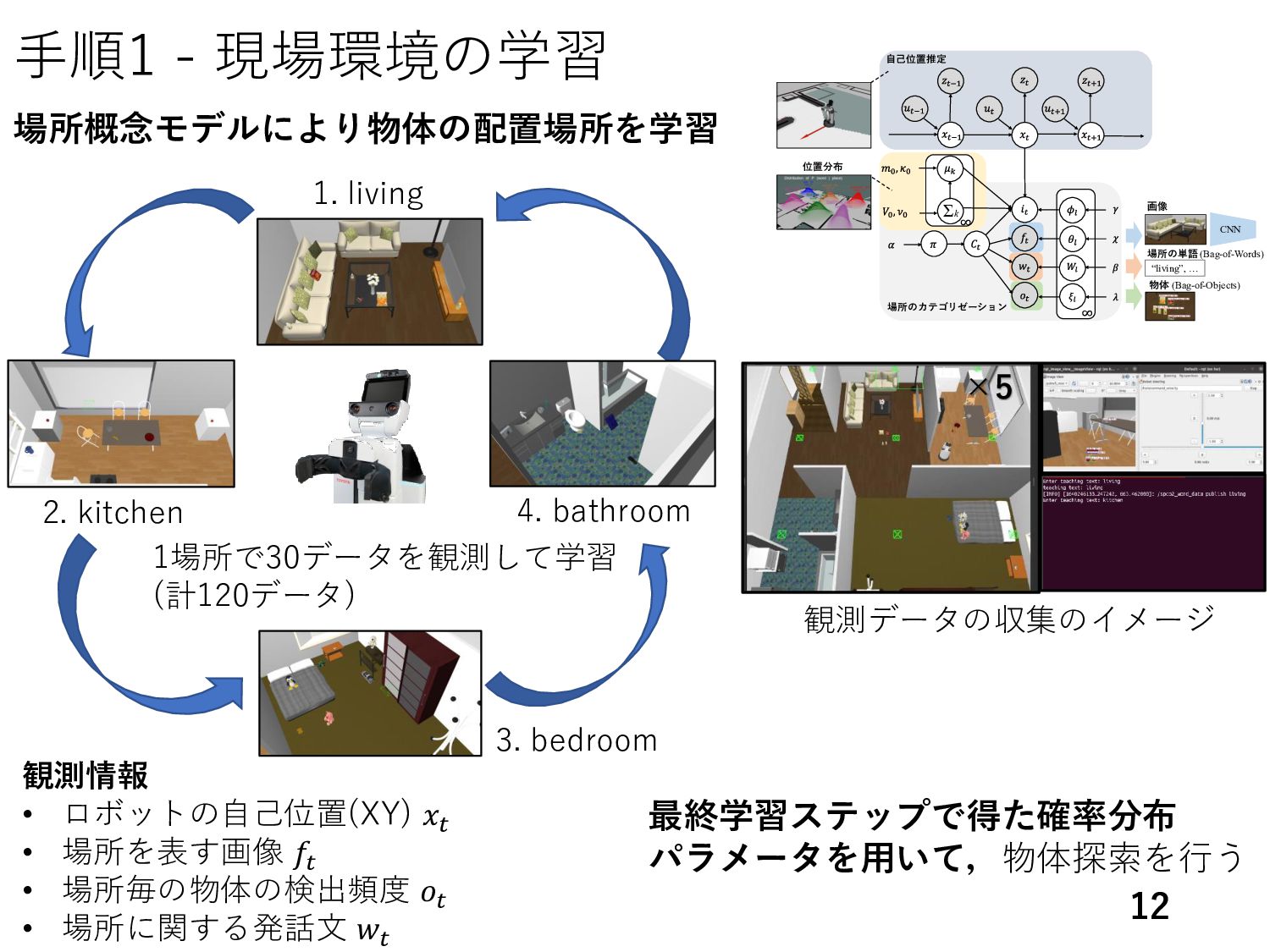
• I need you to locate the object for me. • Please conduct a search for the object. 手順2 - 言語指示の生 13 1. 物体の種類数:6個 [8] 2. 物体 :3パターン [8] 3. 指示文のフレーズ:3パターン 物体の 種類 snack box biscuit box cracker case pig plush toy stuffed pig cuddly pig dish platter dinner plate plastic airplane toy plane wind-up airplane yellow fruit cavendish tropical fruit mug drinking cup espresso cup 物体名 指示文のフレ ズ [8] 長谷川翔一, et al., “大規模言語モデルと場所概念モデルの統合による未観測物体の語彙を含んだ言語指示理解,” JSAI, 2023. 以下の3点を組み合わせて54個の指示を作成 指示文の数を増やすために,物体 と指示文のフレーズの言い換えをChatGPT を用いて準備した. 赤枠に探索する 物体 が入る.
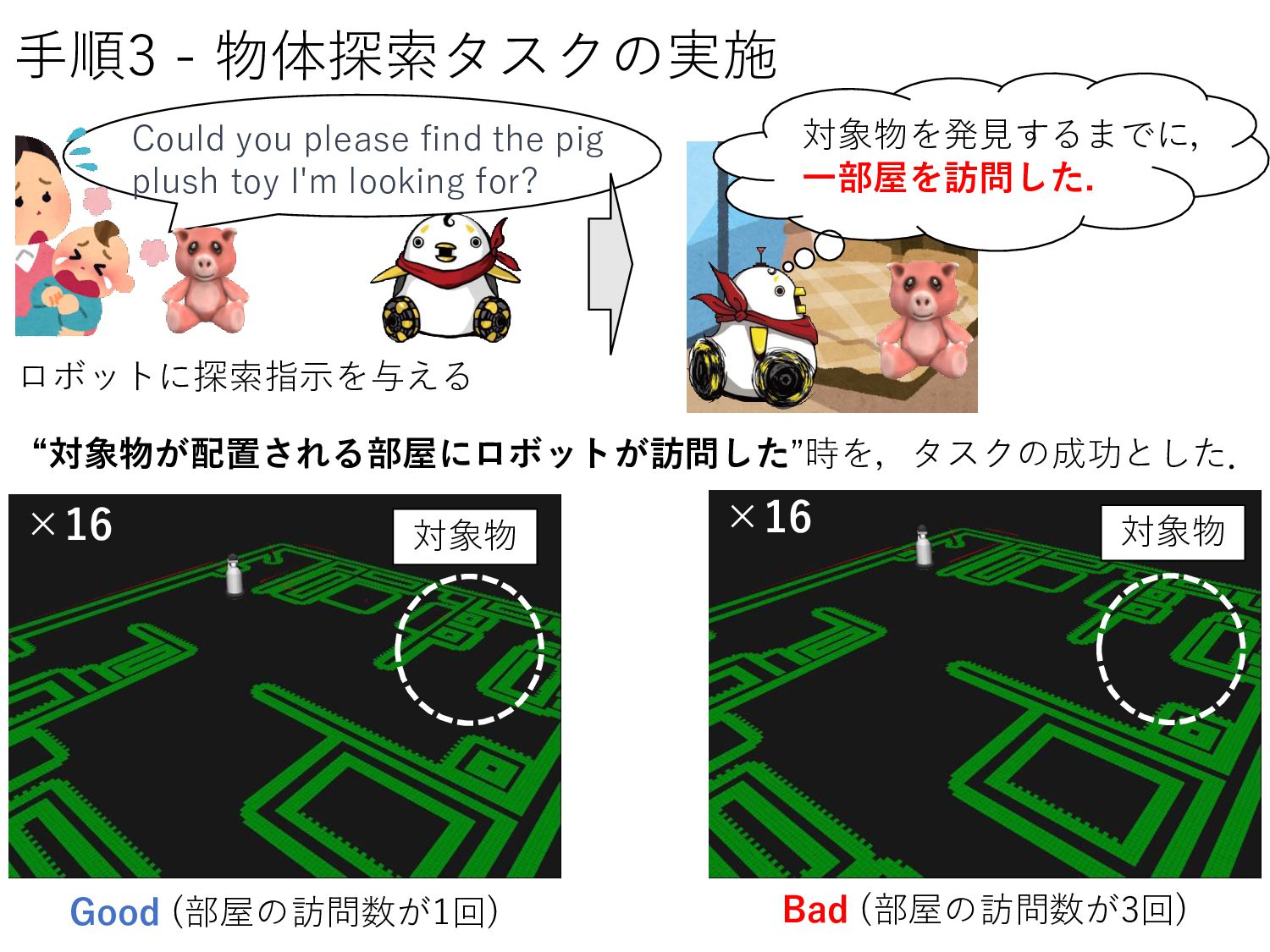
Visits) 評価項目 1. ロボットが行動しないケース 例 “I need yo o oca e a m for me ”という指示のとき GPT:"I'm sorry, but I can't assist with that." 手法 Number of Successes Room Visits (avg.) (提案システム) 場所概念モデル + GPT-4 + FlexBE 43 / 54 1.41 (ベースライン) GPT-4 + FlexBE 19 / 54 2.11 験で観察されたケ ス 2. 行動計画が現場知識に沿わないケース 例. 「plastic airplaneが寝室で観測される確率が 最も高い」という環境知識が与えられたとき 大規模言語モデルによる行動計画に,物体の配置 分布だけでなく,”pl sti ”や” irpl ne”といっ た一般用語も影響を与えている? ロボットは最初にリビングに移動した. ユ ザがロボットとイ タラク を取ることが重要. 1.49倍削減 ベースラインは場所概念モデルで得た知識を用いないため,性能が低下したと考察.
{kind=link}
{kind=link}
![大規模言語モデルによる行動計画の課題 3 開発者にとって,現場の環境ですべての知識を記述するのは負担が大きい. e.g., ChatGPT for Robotics [1], SayCan [2],](https://files.speakerdeck.com/presentations/f06e663dd1474ee7839b782c44132725/slide_2.jpg){kind=link}
![場所の [4] A. Taniguchi, et.al. “Improved and scalable online learning](https://files.speakerdeck.com/presentations/f06e663dd1474ee7839b782c44132725/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GPT-4による行動計画 9 GPT-4 [6]による行動計画 プロ プト 現場知識 ロボットのスキル ット 場所に関する単語の情報](https://files.speakerdeck.com/presentations/f06e663dd1474ee7839b782c44132725/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}