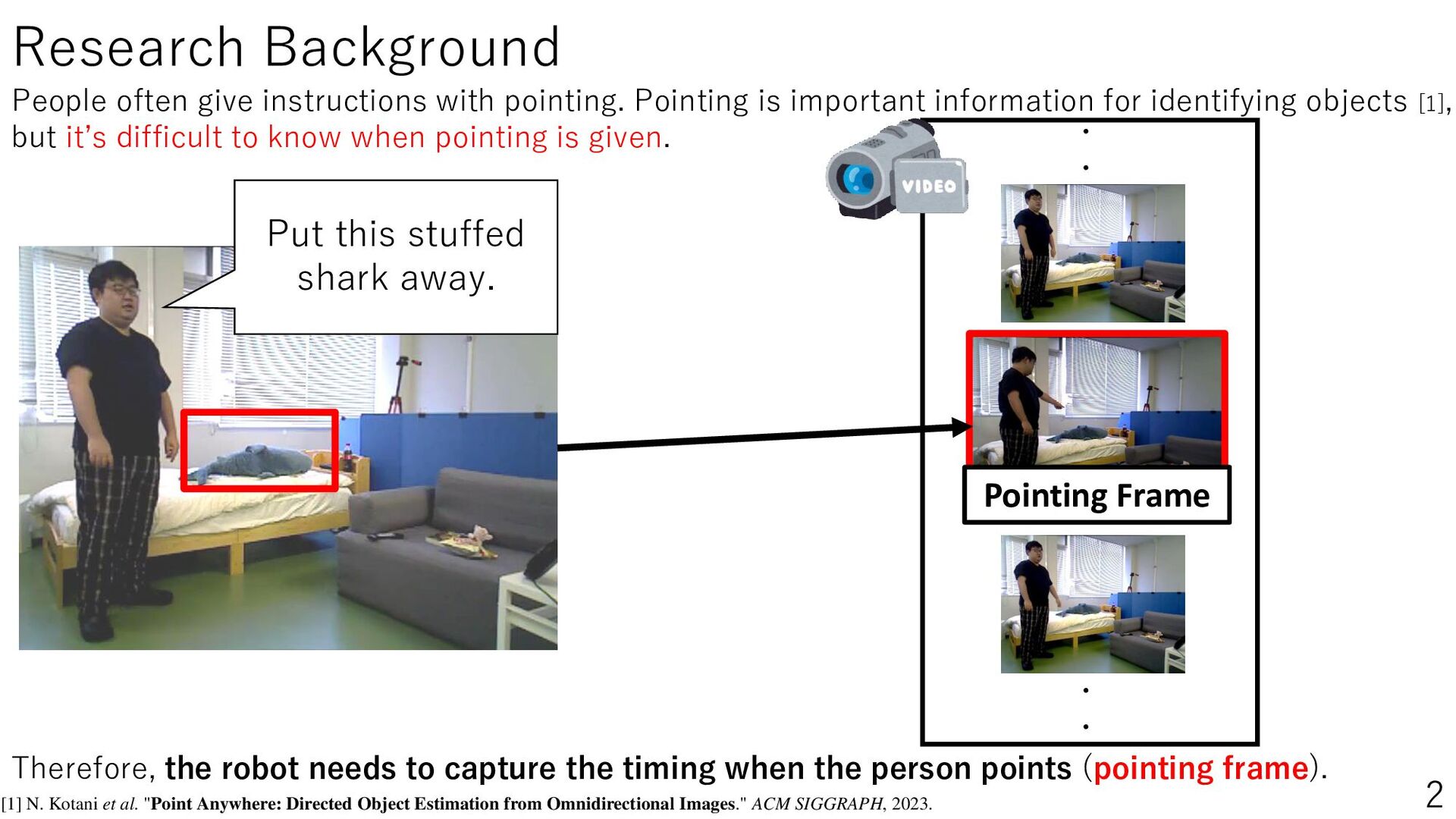
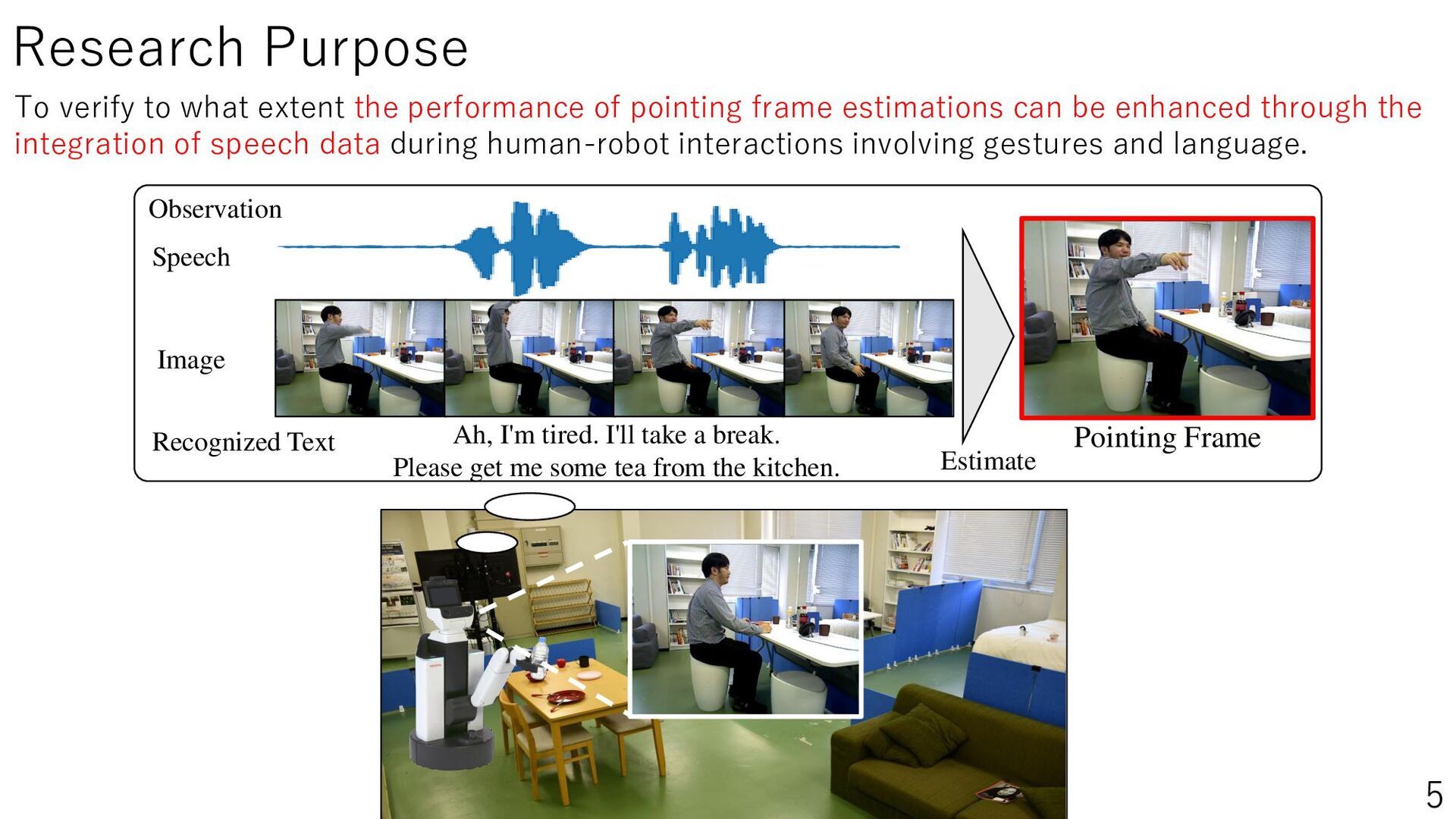
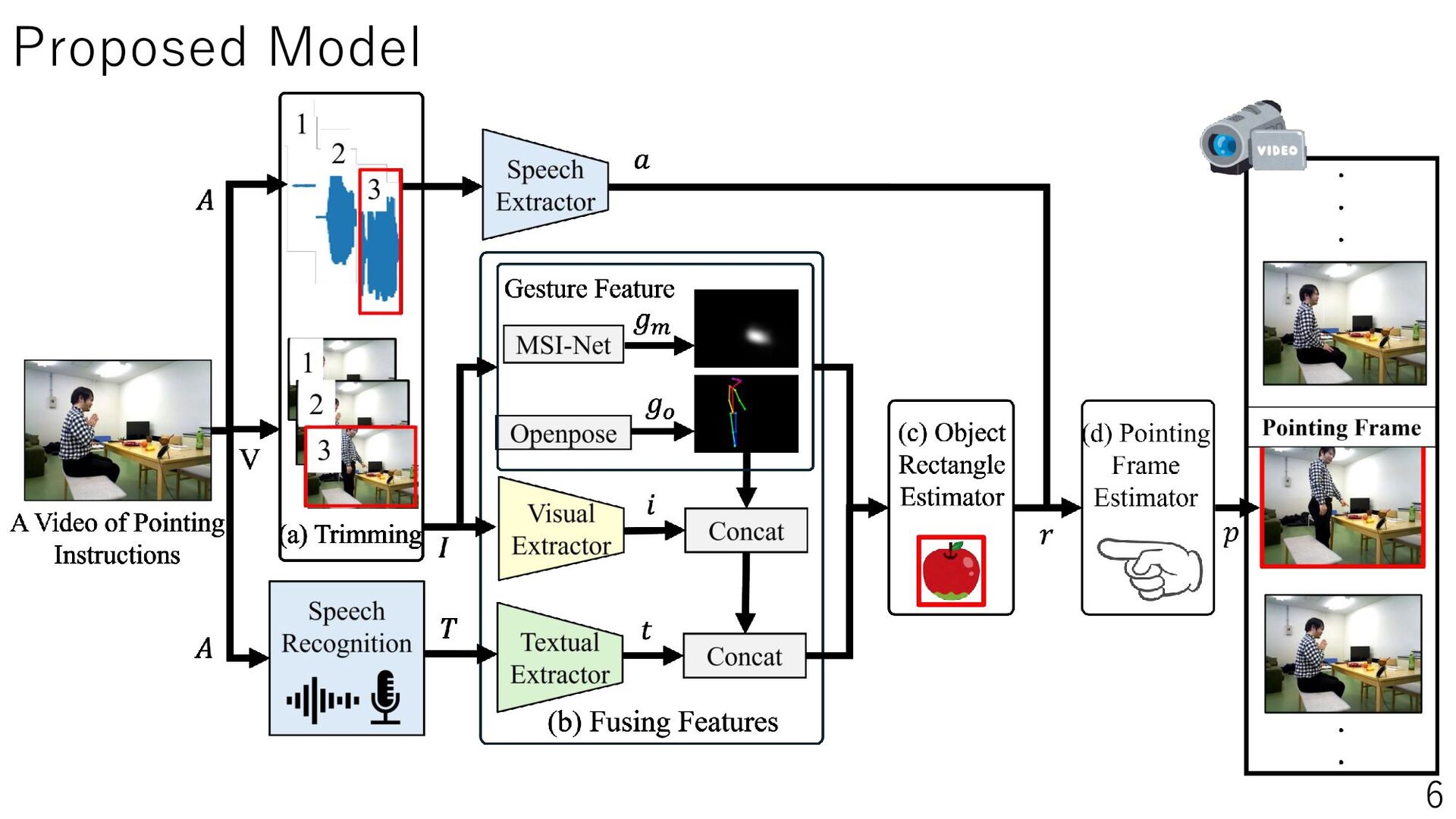
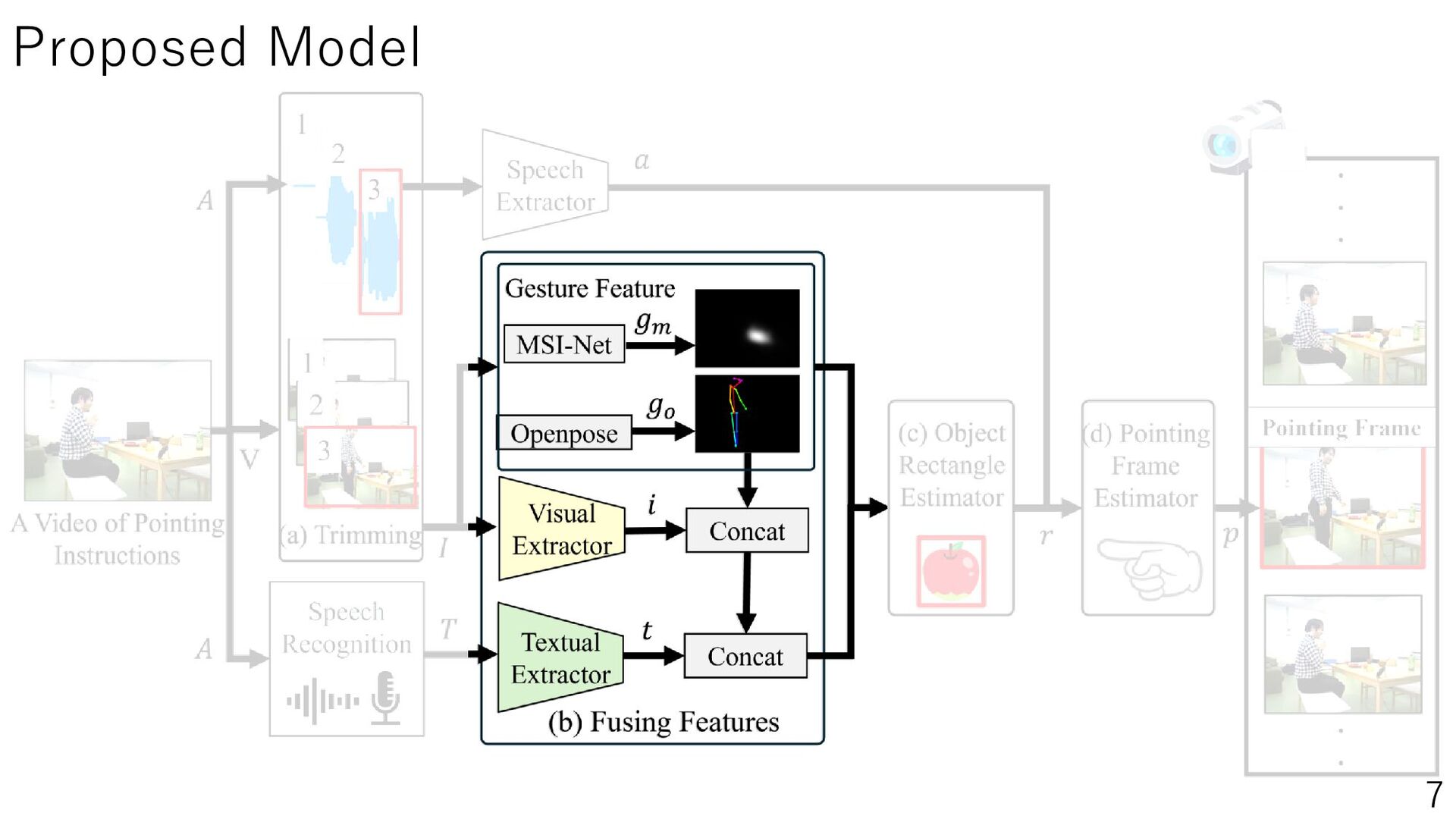
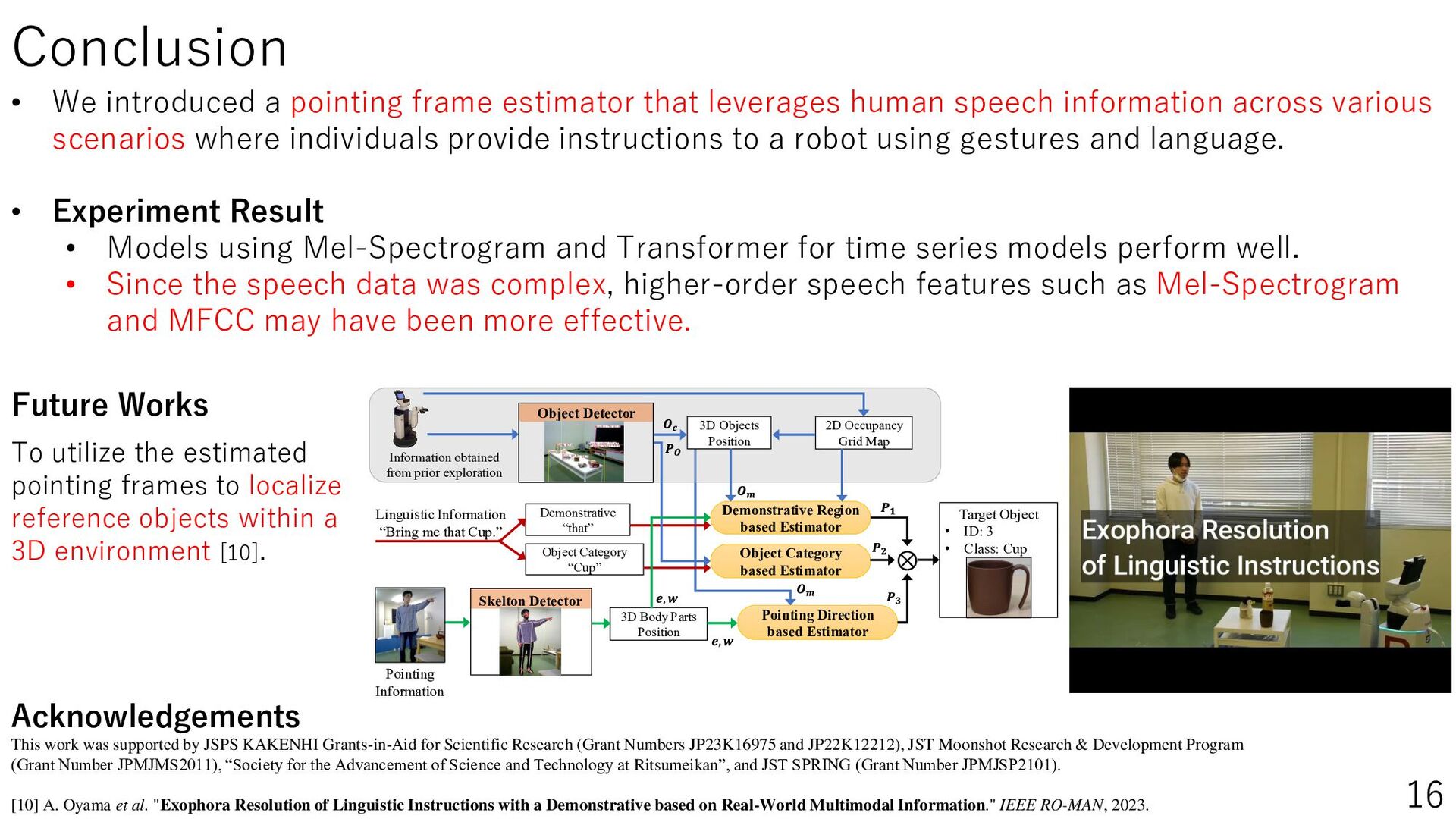
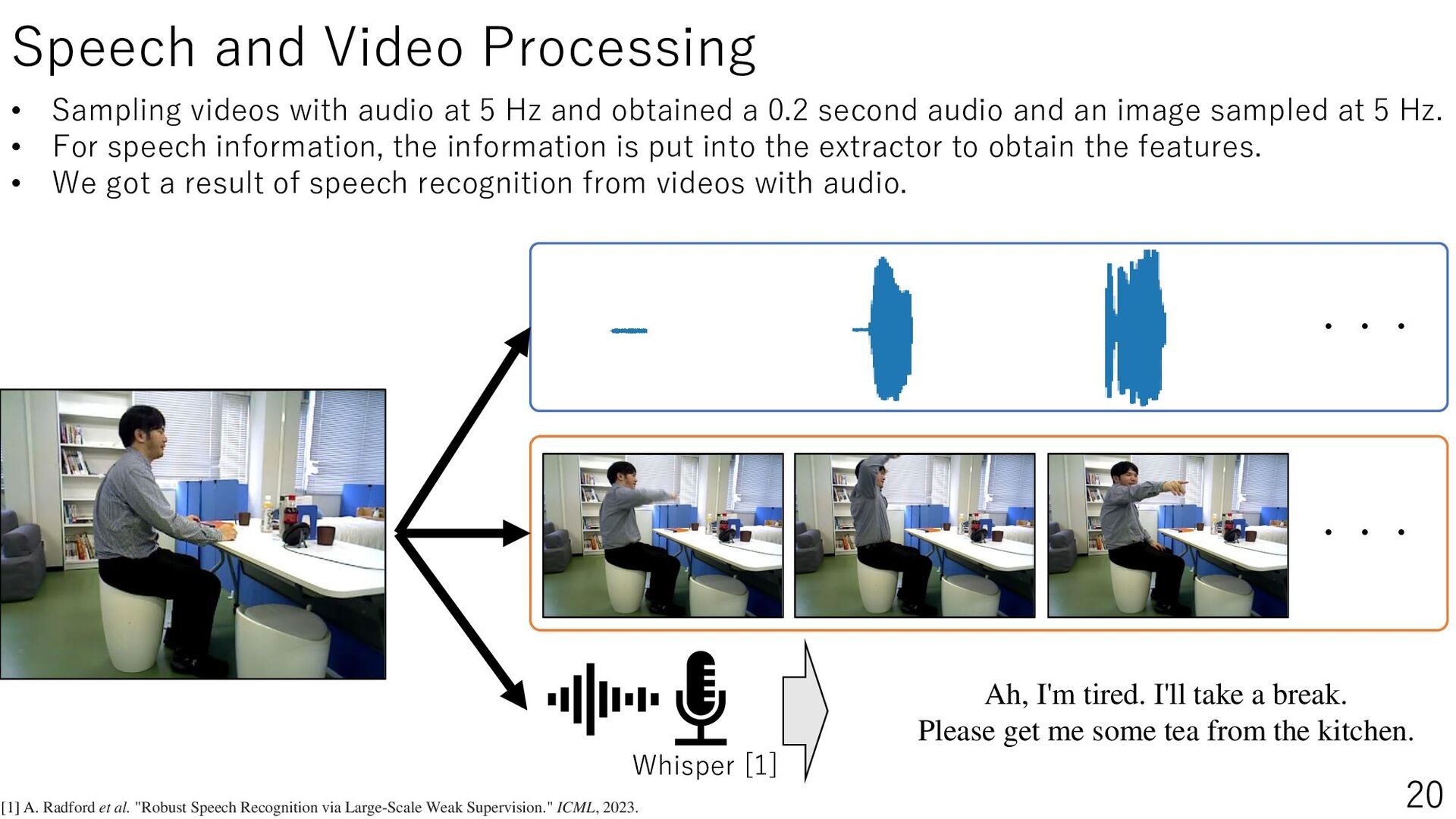
Daily life support robots in the home environment interpret the user’s pointing and understand the instructions, thereby increasing the number of instructions accomplished. This study aims to improve the estimation performance of pointing frames by using speech information when a person gives pointing or verbal instructions to the robot. The estimation of the pointing frame, which represents the moment when the user points, can help the user understand the instructions. Therefore, we perform pointing frame estimation using a time series model, utilizing the user’s speech, images, and speech recognized text observed by the robot. In our experiments, we set up realistic communication conditions, such as speech containing everyday conversation, non-upright posture, actions other than pointing, and reference objects outside the robot’s field of view. The results showed that adding speech information improved the estimation performance, especially the Transformer model with Mel-Spectrogram as a feature. This study will lead to be applied to object localization and action planning in 3D environments by robots in the future. The project website is PointingImgEst
{kind=link}
{kind=link}
![Previous Research: Estimating Pointing Frames 3 [2] Y. Chen et](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
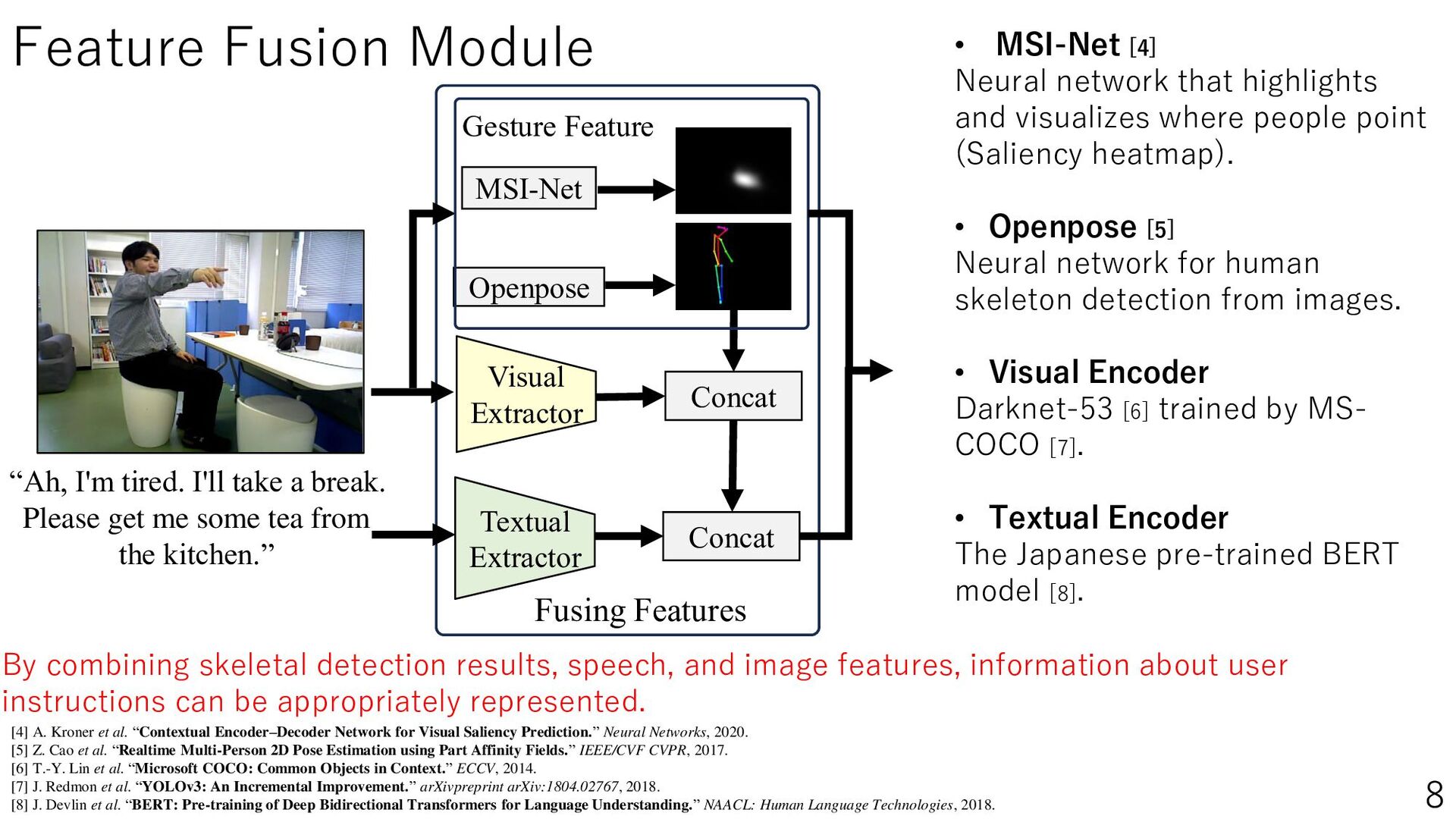{kind=link}
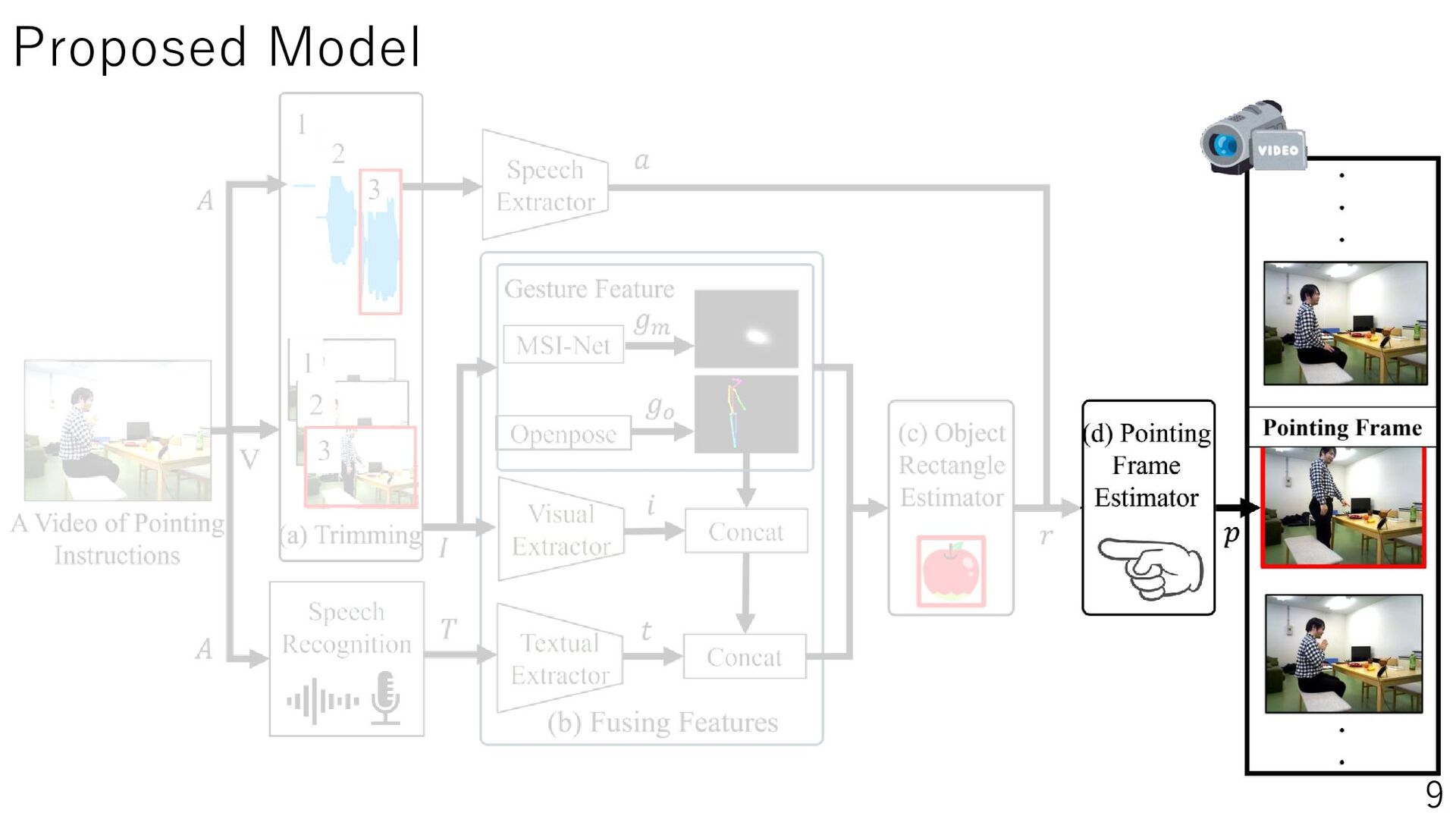{kind=link}
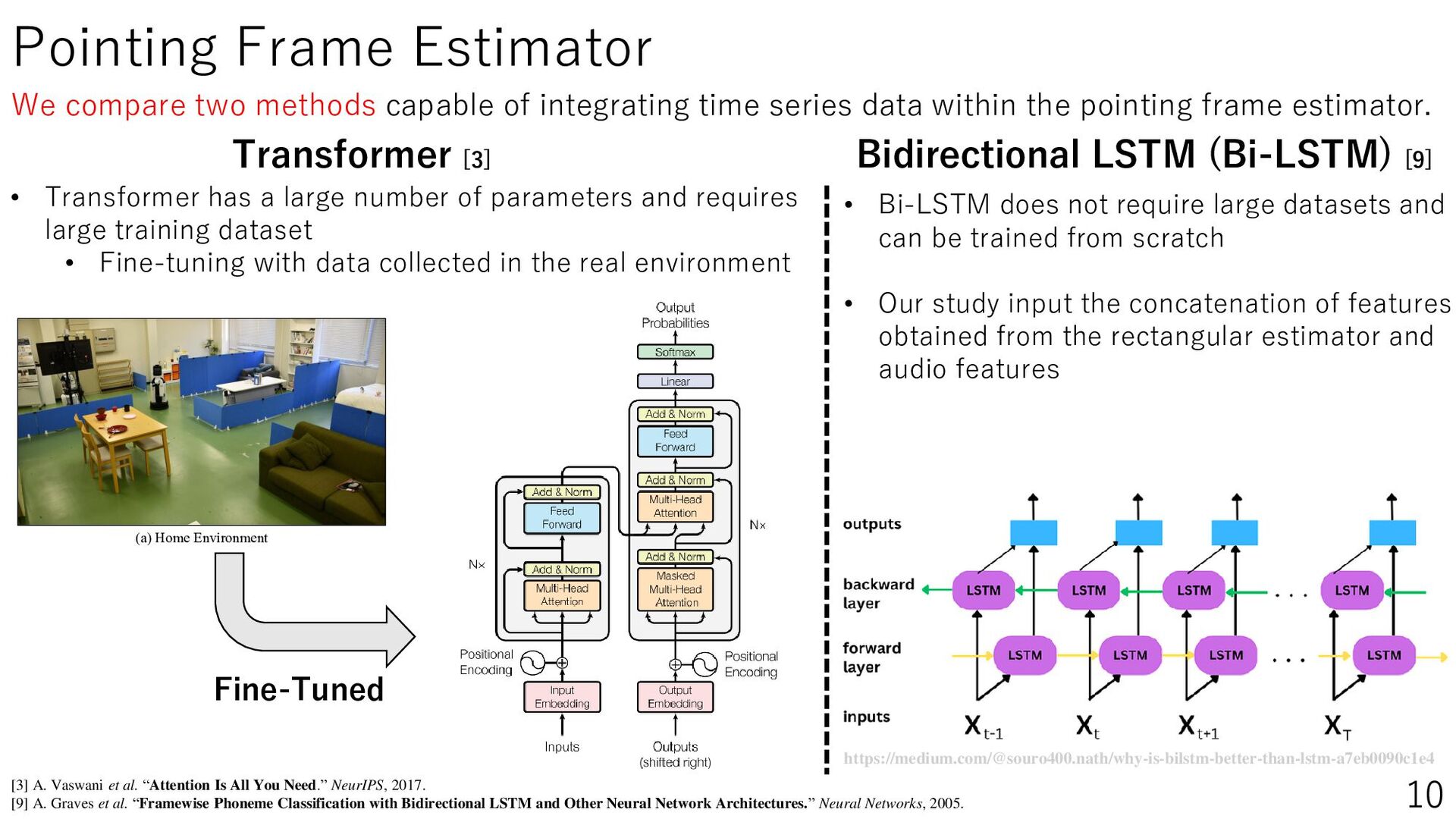{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Comparison Methods Baseline (Chen et al. [2] ) • Dataset](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_13.jpg){kind=link}
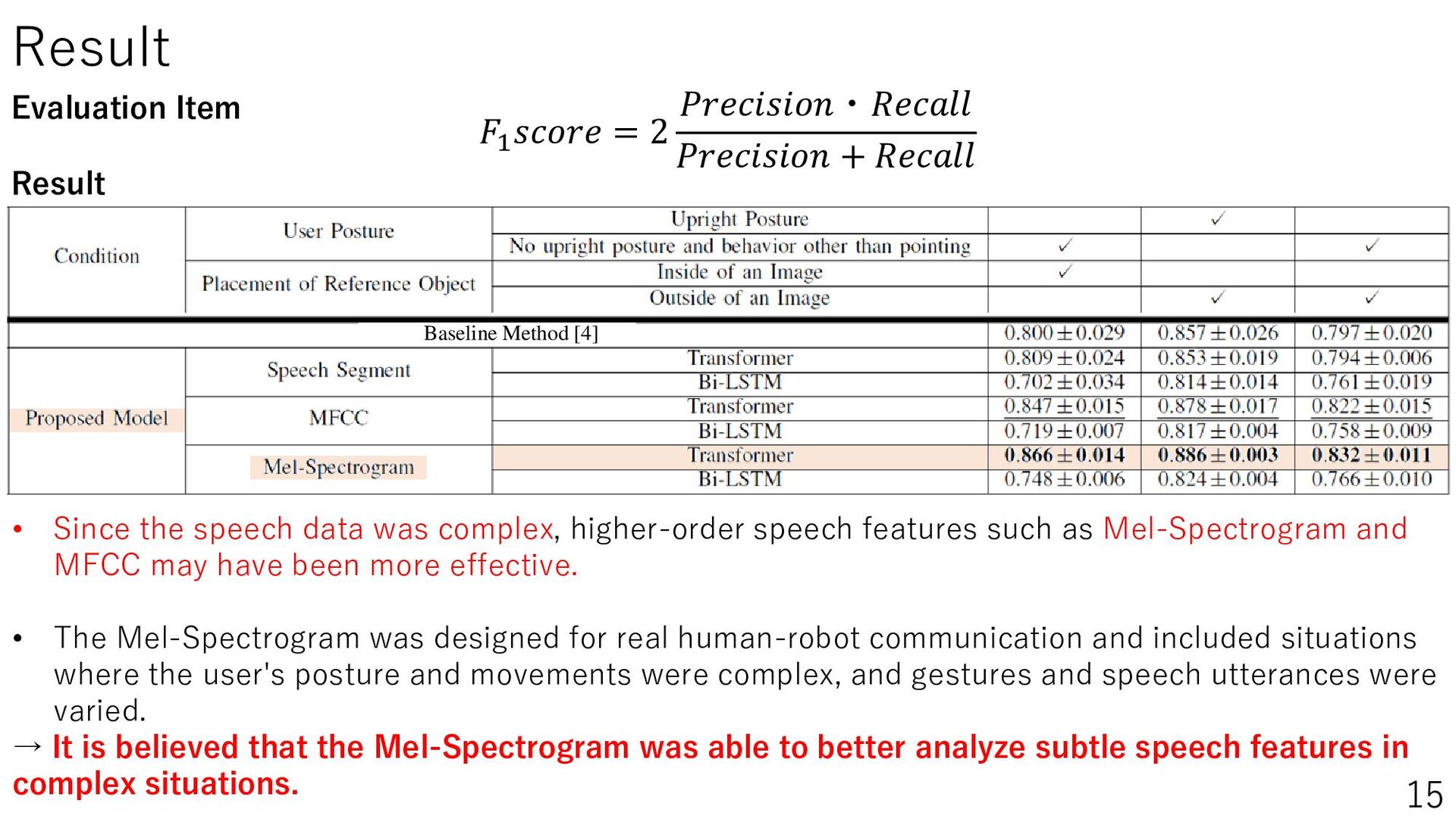{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Object Rectangle Estimator [1] 21 [1] Z. Yang, et al.](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_20.jpg){kind=link}
![Pointing Frame Estimator: Transformer 22 Transformer [1] • Transformer has](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
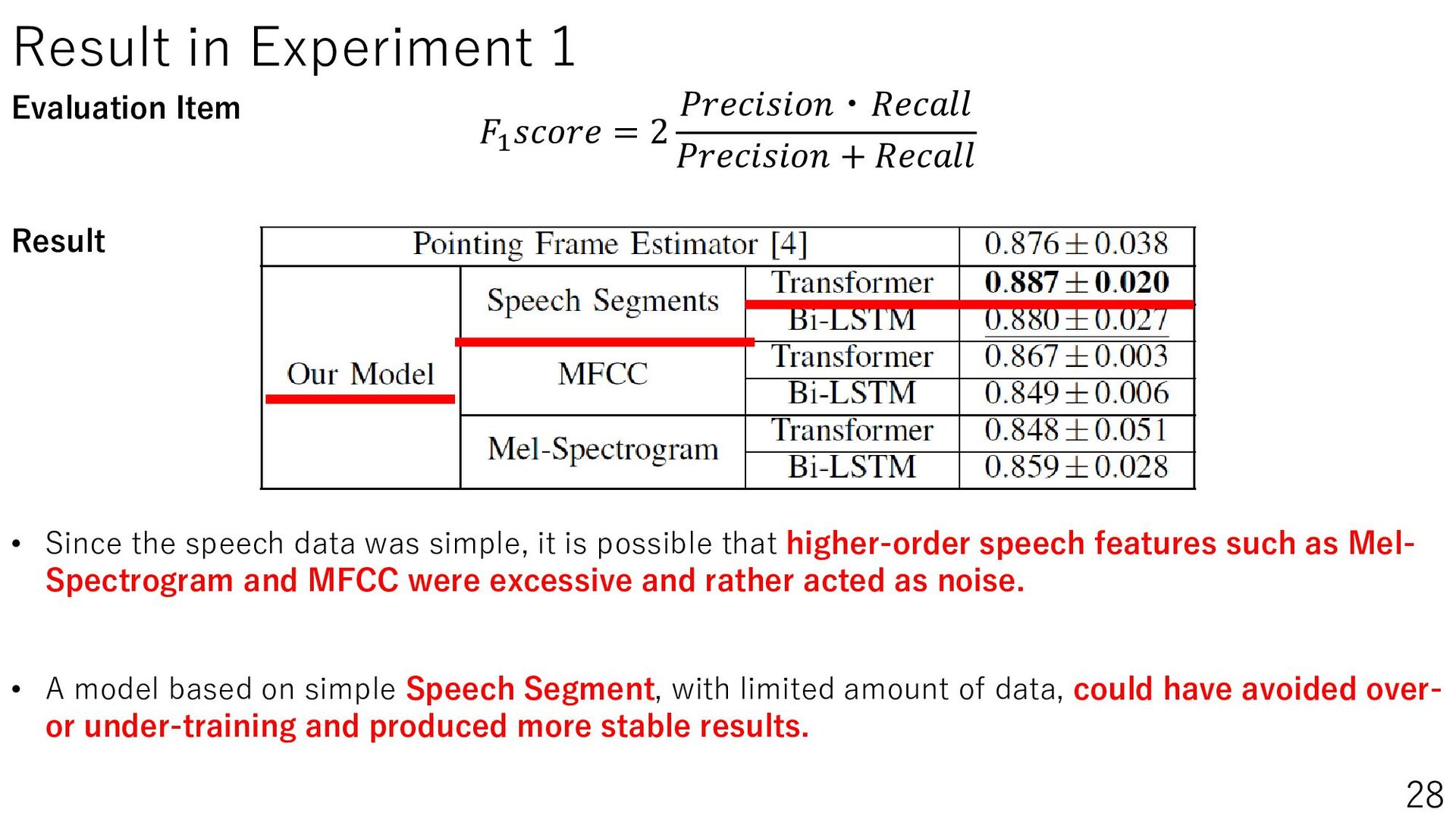{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
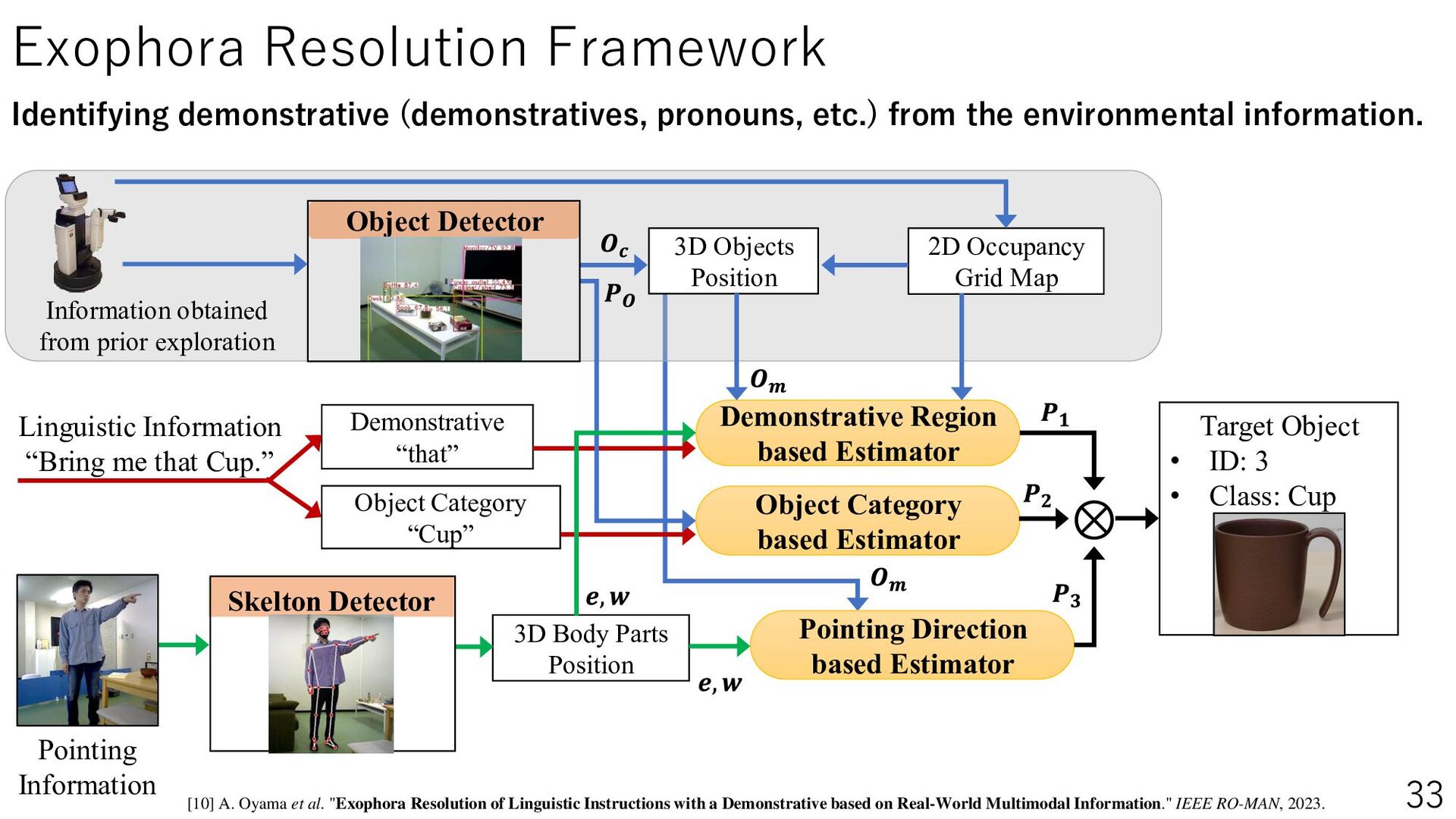{kind=link}
{kind=link}
![Object Category-based Estimator 35 [6] J. Redmon, et al. "You](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
![LLM-based Robot Action Planning: System [1] 38 avigation b ect](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
![Action Planning by GPT-4 41 Action Plan by GPT-4 [1]](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_40.jpg){kind=link}
![Behavior Engine by FlexBE [1] 42 Sequentially generates the actions](https://files.speakerdeck.com/presentations/747d9c9d962042f5b1313dd5f3be23fb/slide_41.jpg){kind=link}