Improving instance-specific image goal navigation (InstanceImageNav), which involves locating an object in the real world that is identical to a query image, is essential for enabling robots to help users find desired objects. The challenge lies in the domain gap between the low-quality images observed by the moving robot, characterized by motion blur and low resolution, and the high-quality query images provided by the user. These domain gaps can significantly reduce the task success rate, yet previous work has not adequately addressed them. To tackle this issue, we propose a novel method: few-shot cross-quality instance-aware adaptation (CrossIA). This approach employs contrastive learning with an instance classifier to align features between a large set of low-quality images and a small set of high-quality images. We fine-tuned the SimSiam model, pre-trained on ImageNet, using CrossIA with instance labels based on a 3D semantic map. Additionally, our system integrates object image collection with a pre-trained deblurring model to enhance the quality of the observed images. Evaluated on an InstanceImageNav task with 20 different instance types, our method improved the task success rate by up to three-fold compared to a baseline based on SuperGlue. These findings highlight the potential of contrastive learning and image enhancement techniques in improving object localization in robotic applications. The project website is
CrossIA.
{kind=link}
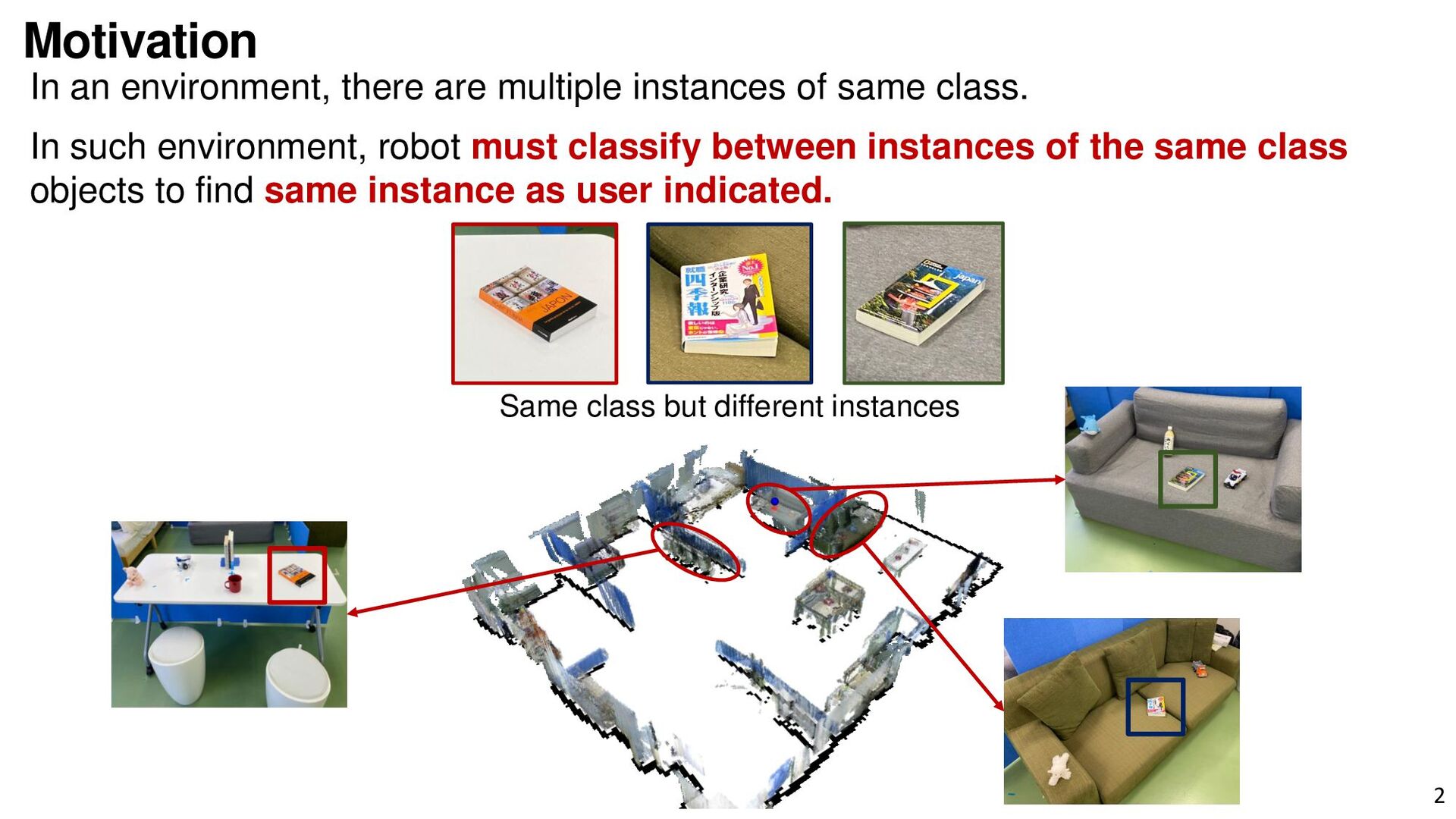{kind=link}
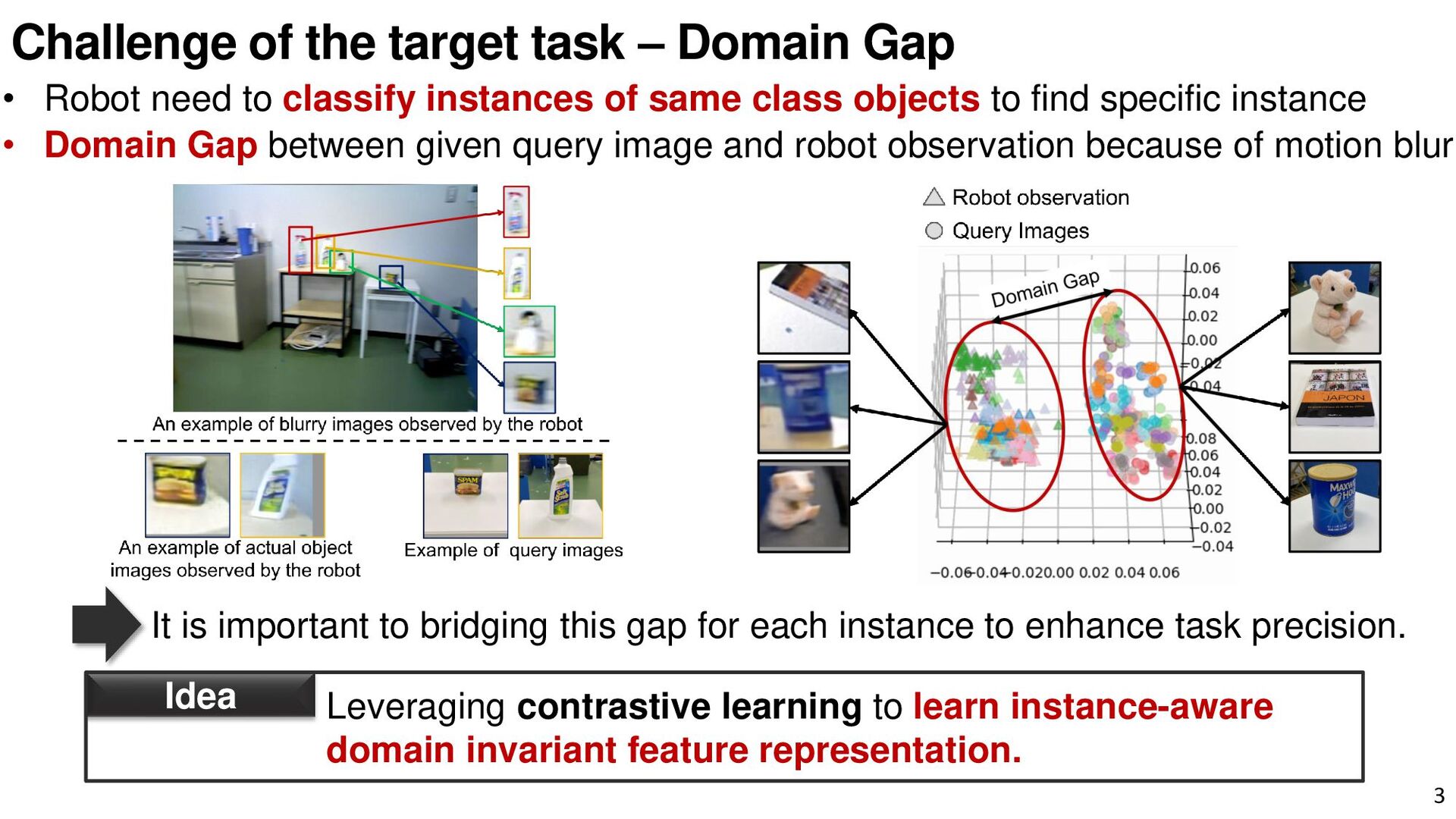{kind=link}
![(Typical) Similar Navigation Tasks Instance Specific Image Goal Navigation [1]](https://files.speakerdeck.com/presentations/8e300e48b47446b9864417e8af7c34d5/slide_3.jpg){kind=link}
![Related work – Instance Specific Image Goal Navigation [4] J.](https://files.speakerdeck.com/presentations/8e300e48b47446b9864417e8af7c34d5/slide_4.jpg){kind=link}
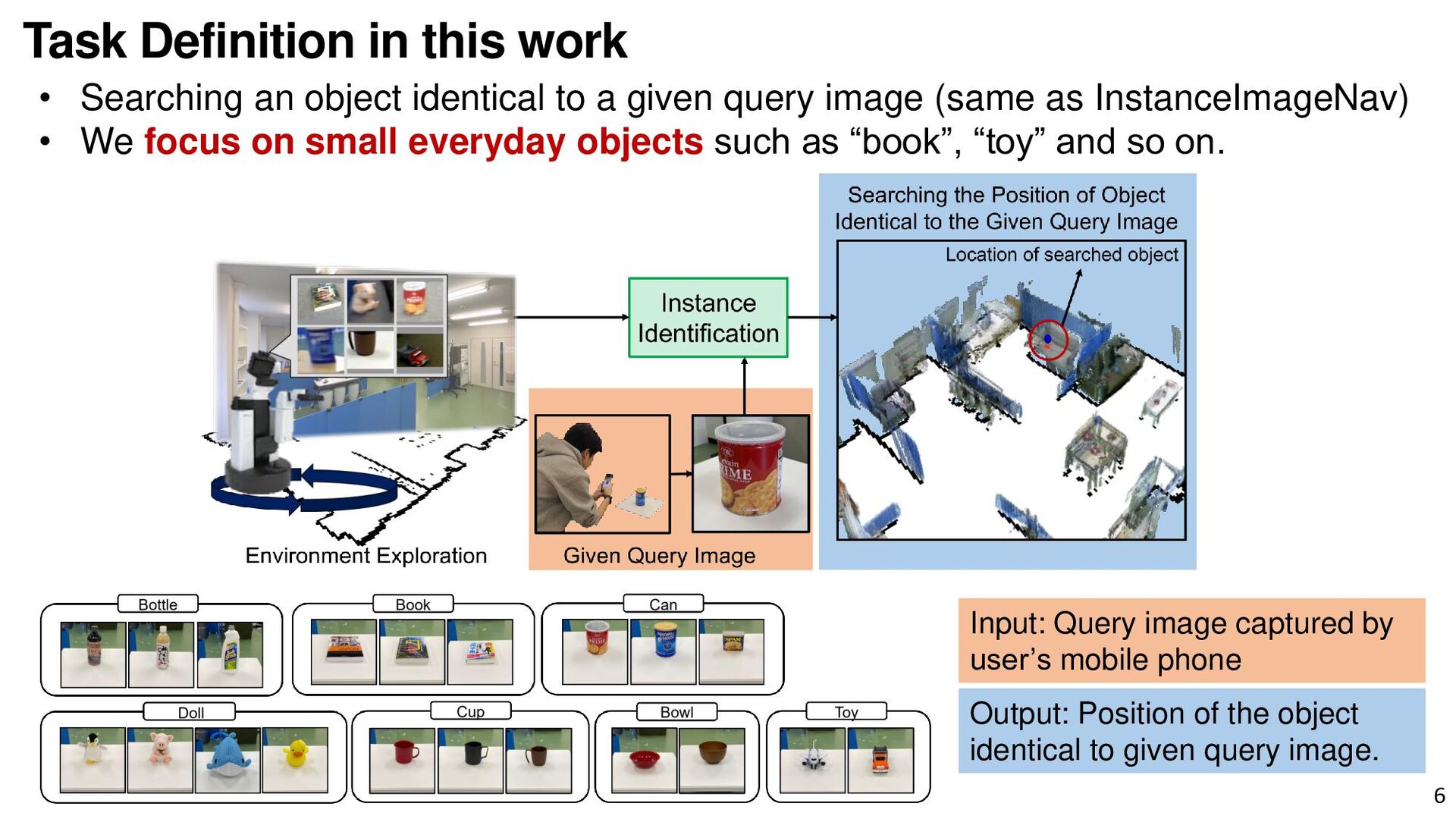{kind=link}
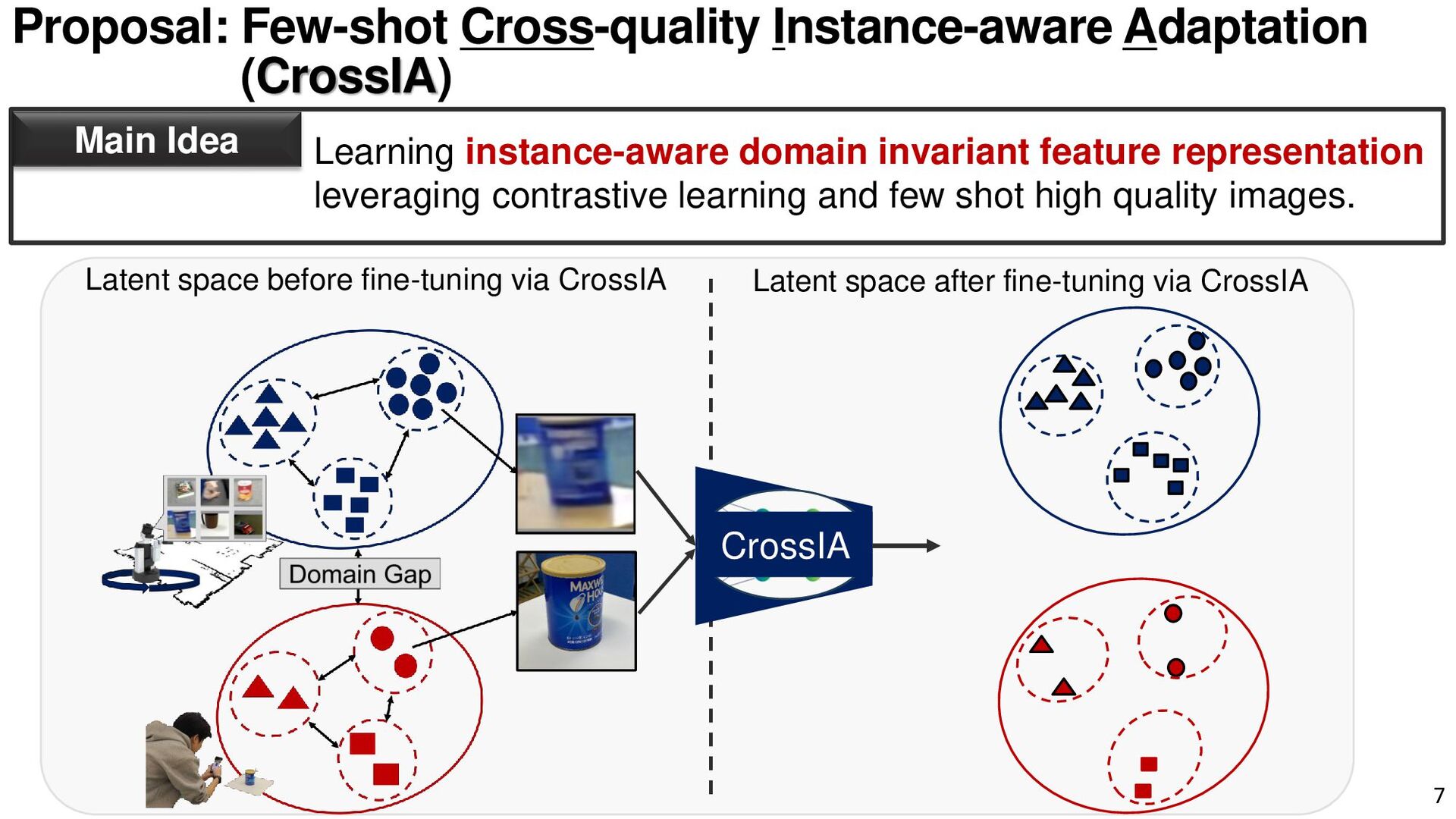{kind=link}
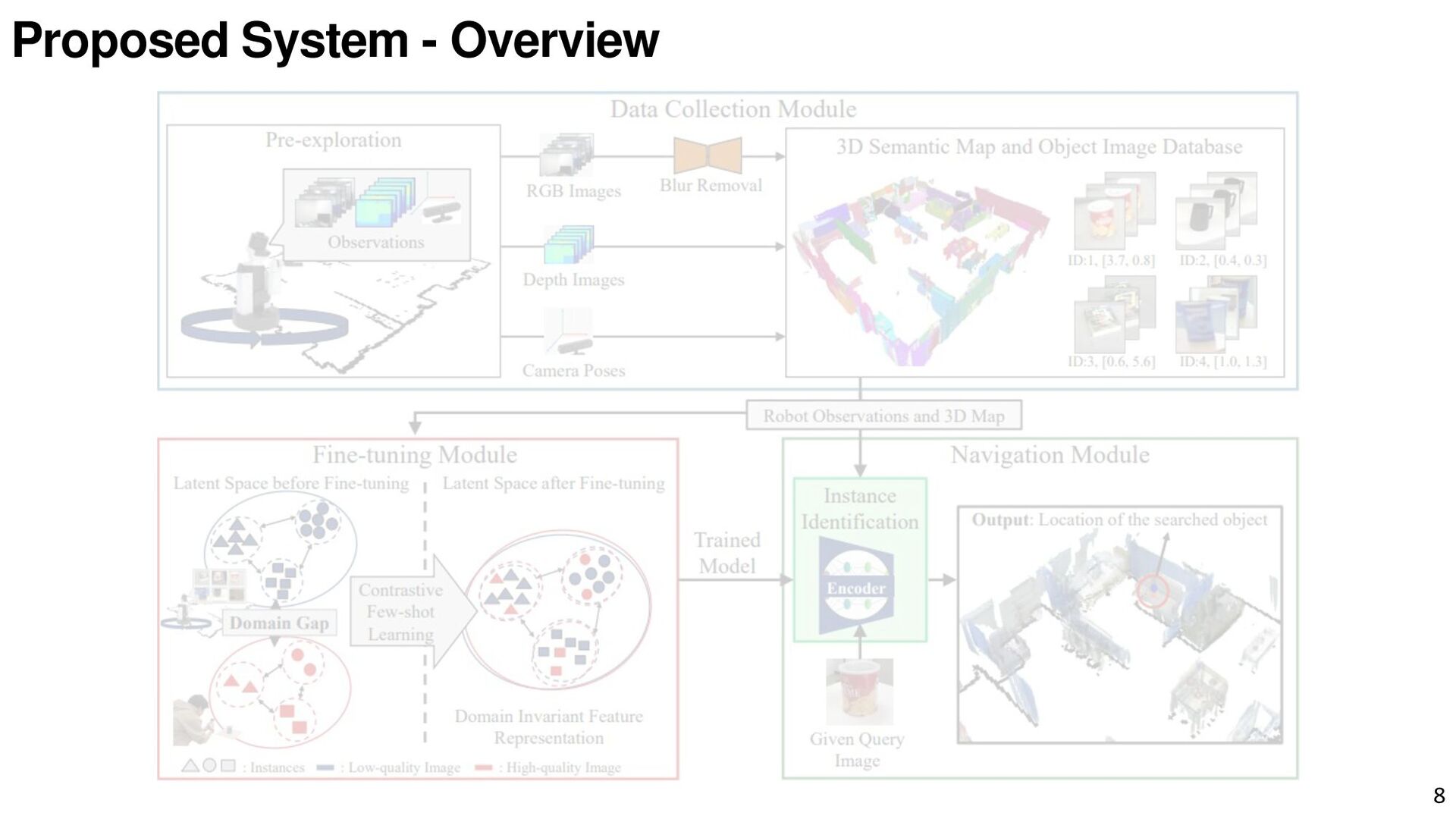{kind=link}
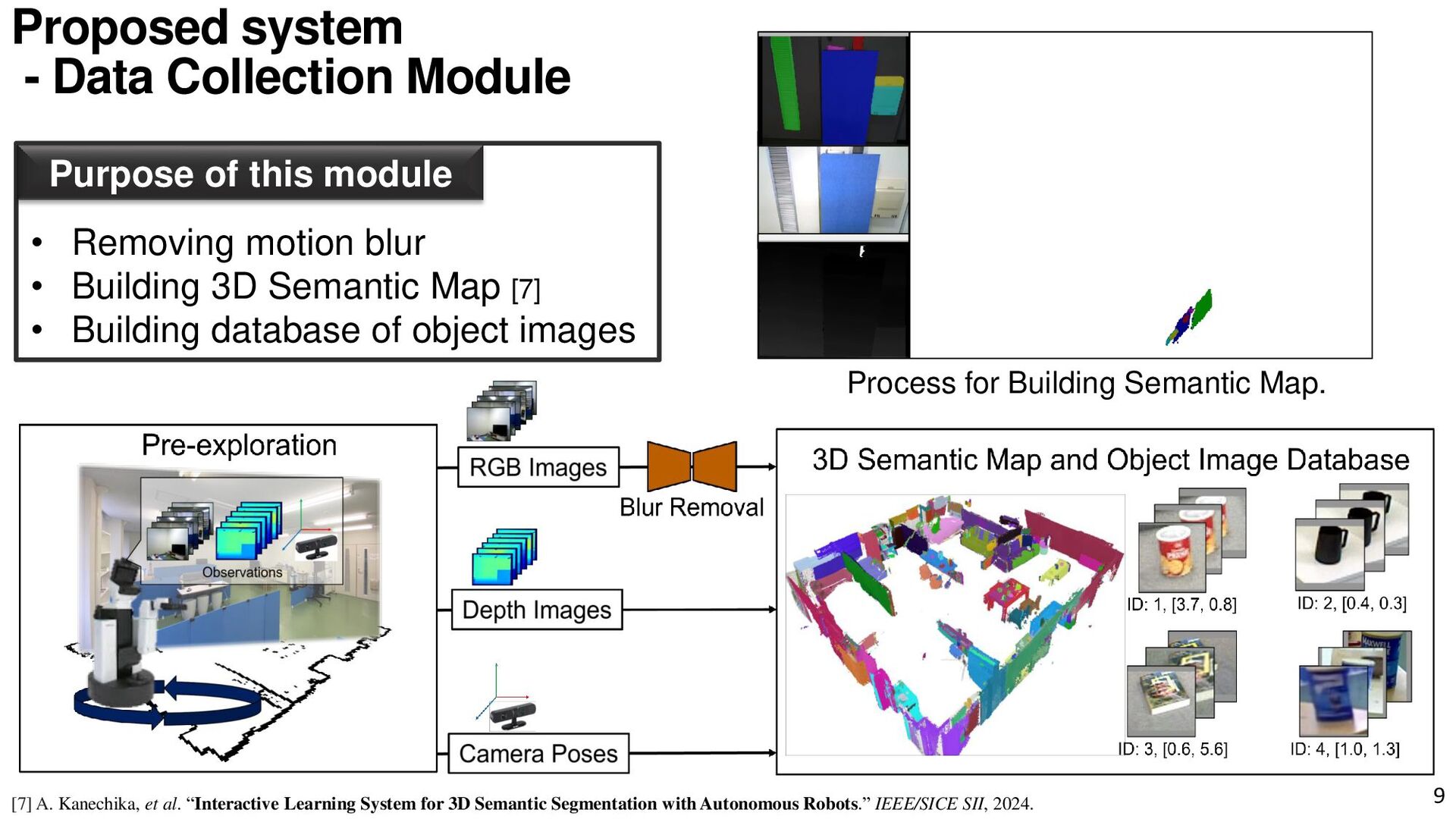{kind=link}
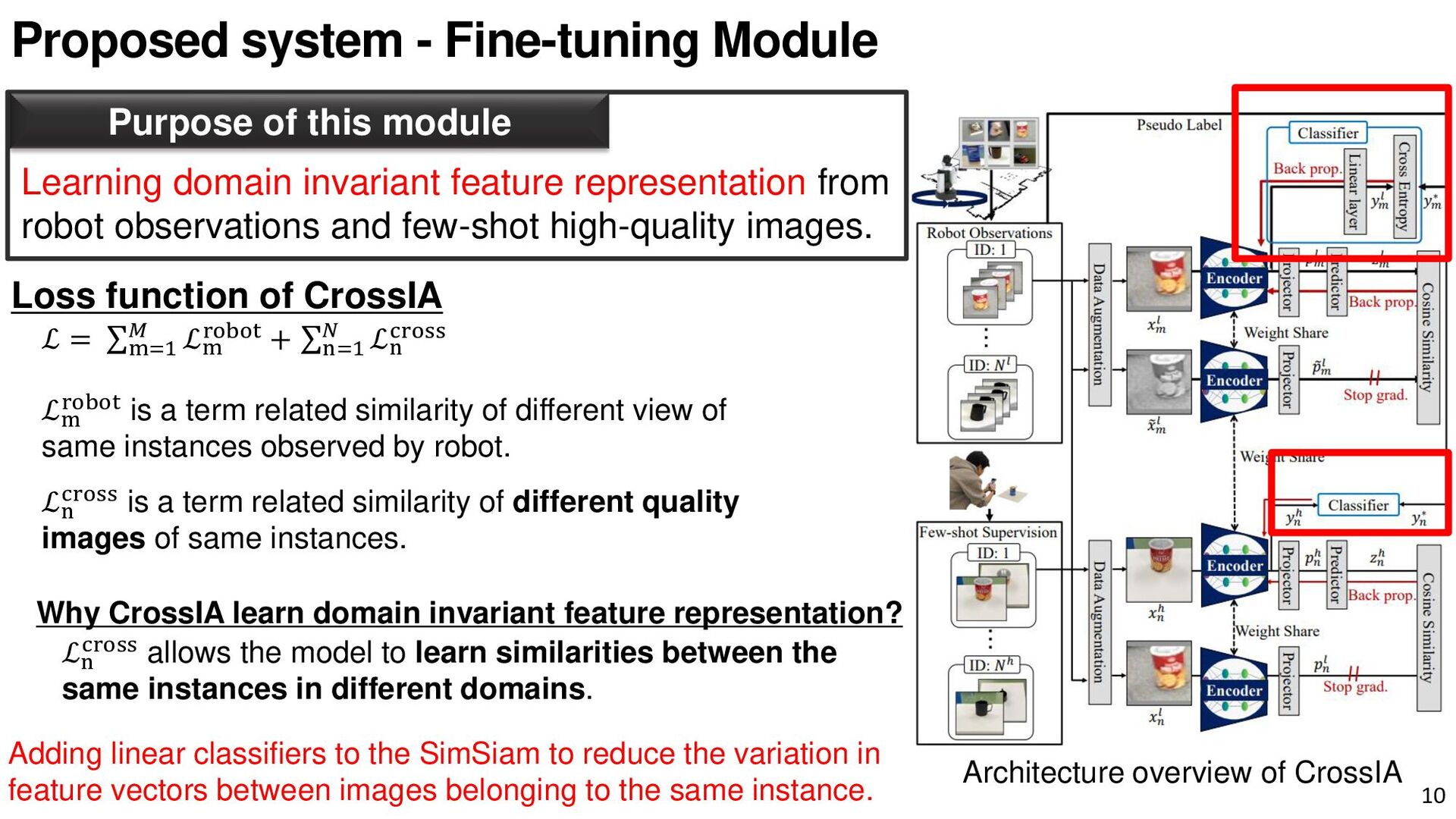{kind=link}
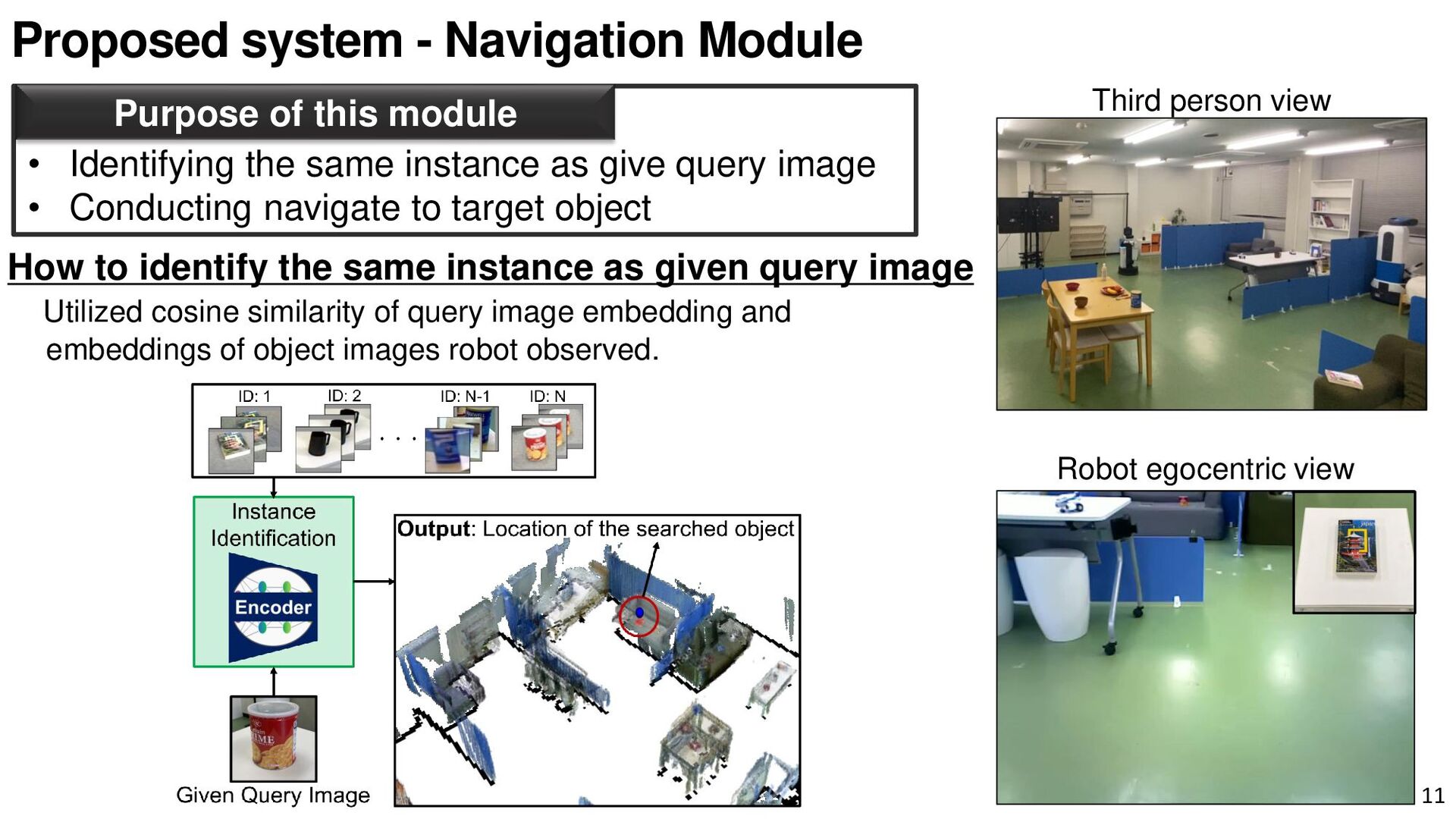{kind=link}
{kind=link}
![Experiment – Conditions Conditions : Instance identifier • SuperGlue [5]](https://files.speakerdeck.com/presentations/8e300e48b47446b9864417e8af7c34d5/slide_12.jpg){kind=link}
{kind=link}
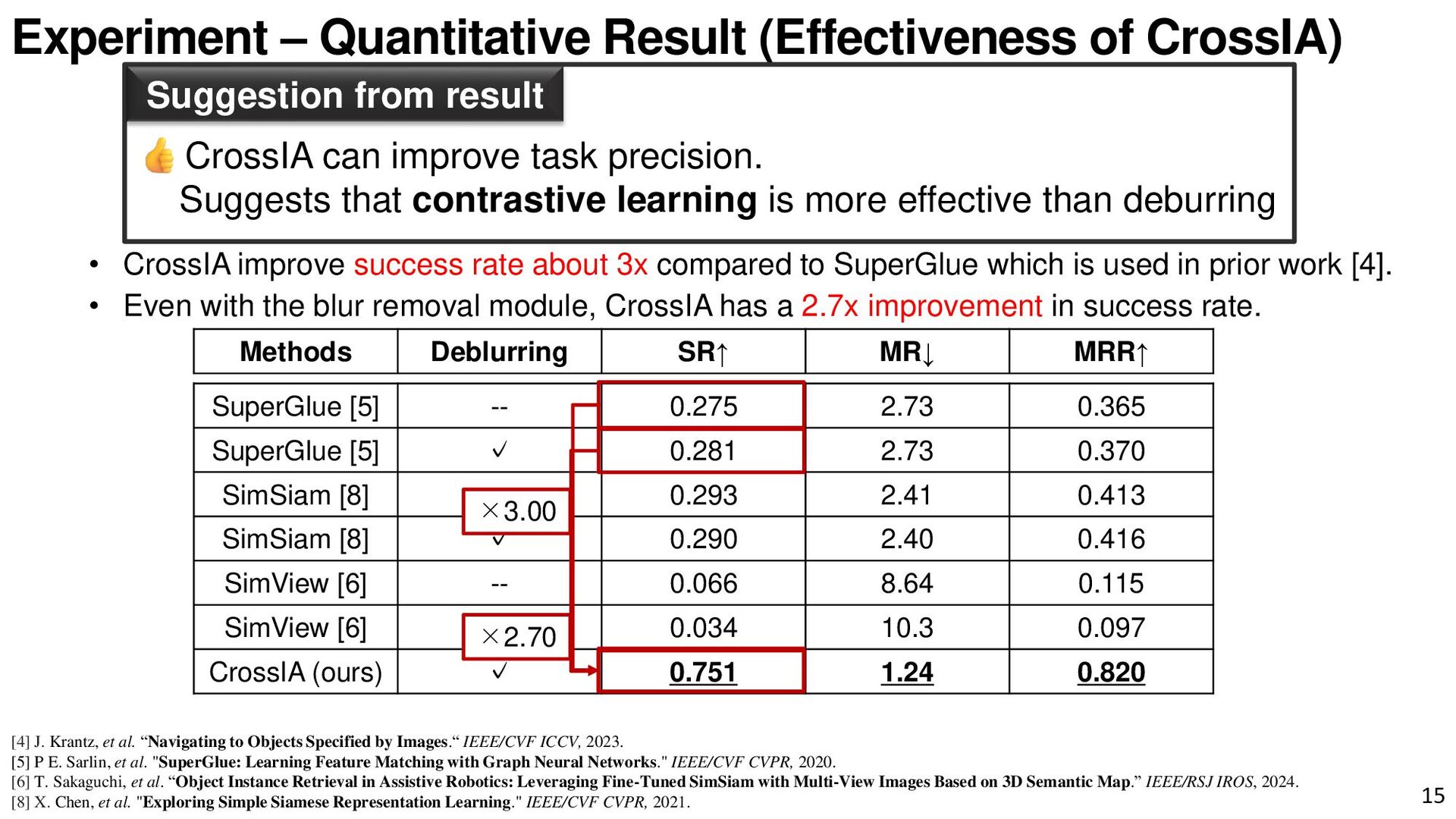{kind=link}
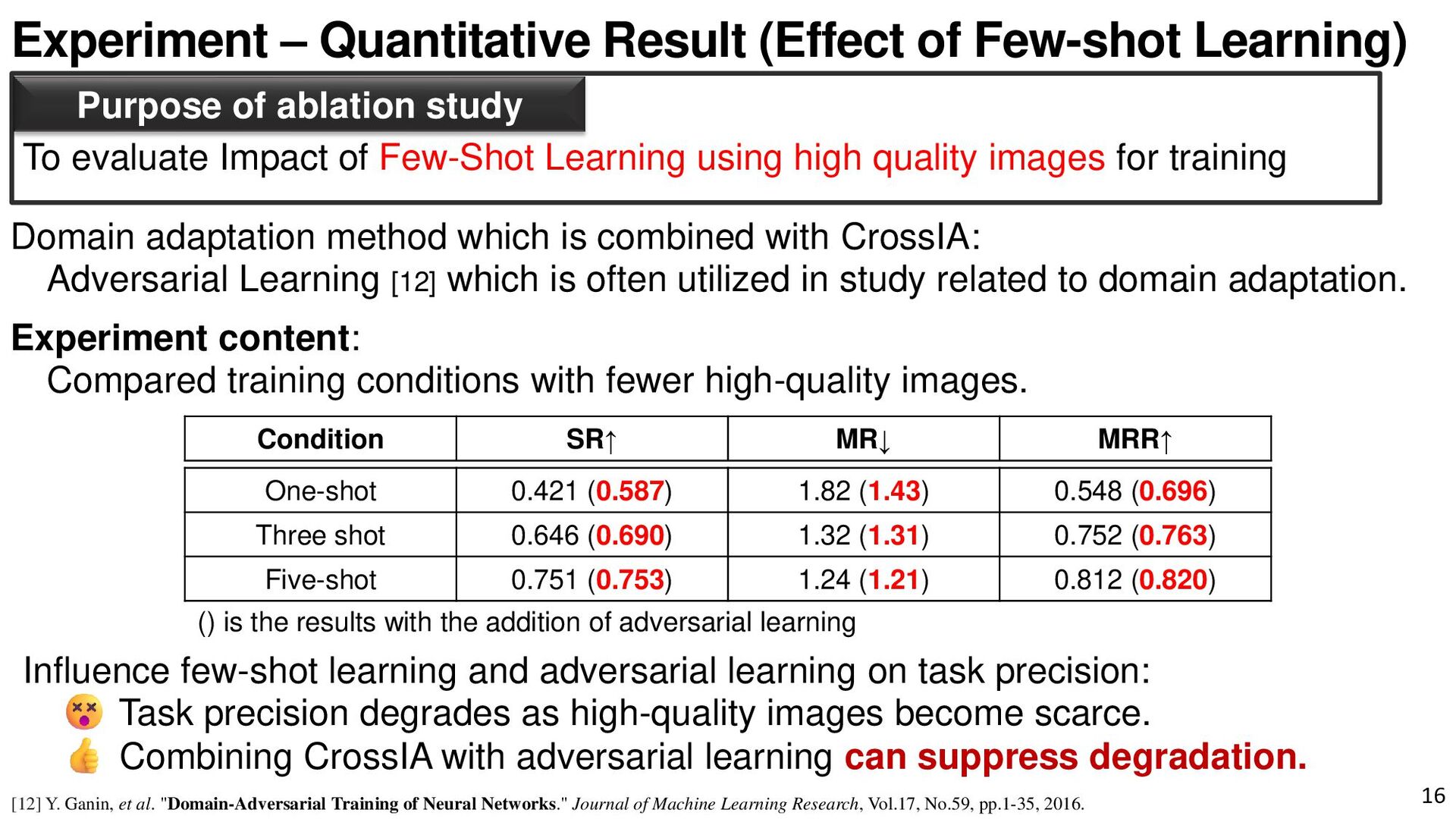{kind=link}
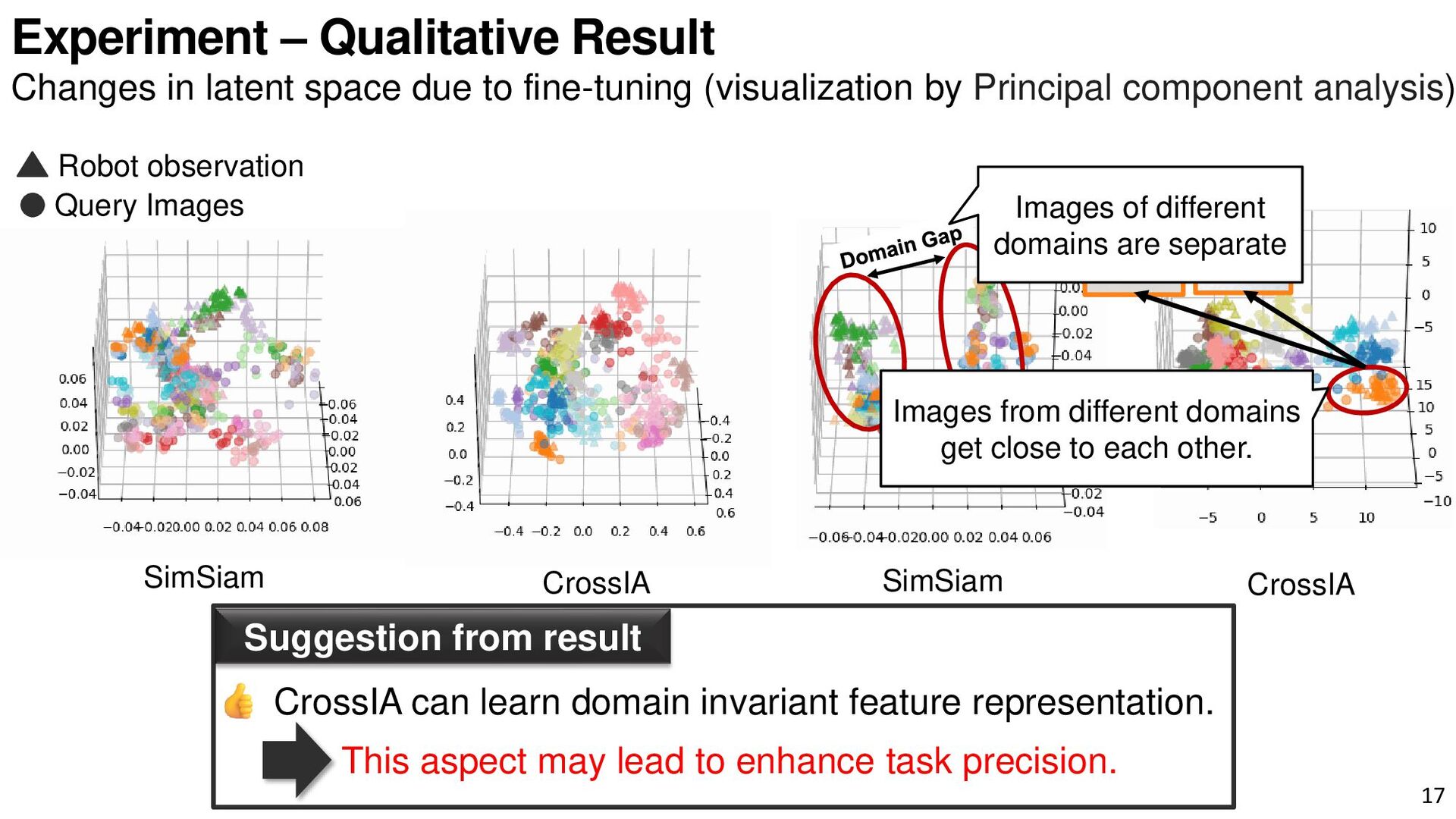{kind=link}
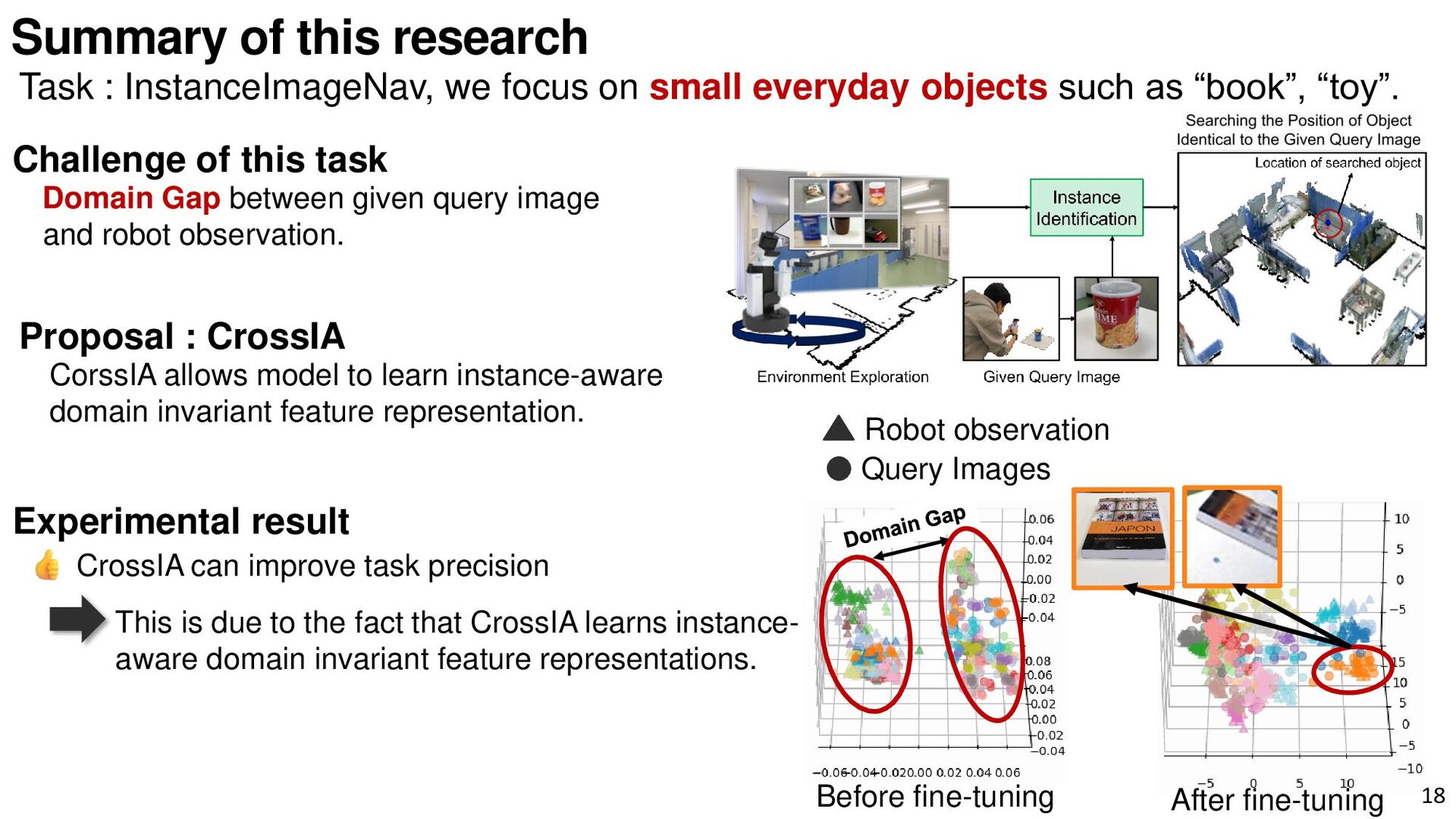{kind=link}
{kind=link}