Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介:対話破綻検出の対話システムへの適用
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
shu_suzuki
May 07, 2019
0
210
文献紹介:対話破綻検出の対話システムへの適用
長岡技術科学大学
自然言語処理研究室
鈴木脩右
shu_suzuki
May 07, 2019
Tweet
Share
More Decks by shu_suzuki
See All by shu_suzuki
文献紹介:Investigating Evaluation of Open-Domain Dialogue Systems With Human Generated Multiple References
shu_suzuki
0
200
文献紹介:Do Neural Dialog Systems Use the Conversation History Effectively? An Empirical Study
shu_suzuki
0
86
文献紹介: How to Make Context More Useful? An Empirical Study on Context-Aware Neural Conversational Models
shu_suzuki
0
360
文献紹介:Conversational Response Re-ranking Based on Event Causality and Role Factored Tensor Event Embedding
shu_suzuki
0
180
文献紹介:Modeling Semantic Relationship in Multi-turn Conversations with Hierarchical Latent Variables
shu_suzuki
0
80
文献紹介:ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation
shu_suzuki
0
220
文献紹介:Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings
shu_suzuki
0
130
文献紹介:Why are Sequence-to-Sequence Models So Dull?
shu_suzuki
0
75
文献紹介:Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network
shu_suzuki
0
220
Featured
See All Featured
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.3k
Exploring anti-patterns in Rails
aemeredith
2
300
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
1
330
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
390
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
1.8k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
360
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Statistics for Hackers
jakevdp
799
230k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
180
Building AI with AI
inesmontani
PRO
1
830
We Have a Design System, Now What?
morganepeng
55
8k
Transcript
文献紹介 対話破綻検出の対話システムへの適用 鈴木脩右 2019/5/7 長岡技術科学大学 自然言語処理研究室 1
文献情報 • 稲葉通将,高橋健一 • 人工知能学会論文誌 • Vol.34,No.3,p.B-I 1-8,2019 2
概要 • 対話破綻検出を適用した対話システムを提案 • 適用手法として,分類ベース手法,非破綻確率ベース手法, 線形回帰ベース手法を提案 • 3 種類のシステムに適用した結果,非破綻確率ベース手法, 線形回帰ベース手法において性能が向上
3
背景 • 対話システムのタスクに,対話破綻検出チャレンジがある • 検出をすることで,システムが対話破綻を回避できるよう になるとされているが,実際に検証した例は少ない • また,具体的な適用手法についても明らかにされていない 4
対話破綻検出チャレンジ • 本研究における対話破綻検出は,対話破綻検出チャレンジ (DBDC) に準拠 • 破綻ラベルをアノテーションされた対話データを用いて学 習し,破綻検出器を作成 • アノテーションには
3 つの破綻ラベルが付与 • O:破綻ではない • T:破綻と言い切れないが,違和感がある • X:破綻している 5
対話破綻検出手法 • DBDC2 において性能が最も良かった手法を用いる (杉山 2016) • 急激な話題転換や対話行為などを素性に,Extra Trees Regressor
でラベルの確率分布を推定 • 素性の 1 つに対話行為アノテーション済みコーパスを用いる → 当該コーパスは非公開 • 新たに,対話行為コーパスを作成し対話行為推定器を構築 • 39 個の対話行為を多クラス SVM で学習 • 予備実験で杉山の結果と,同等の結果が得られることを確認 6
対話モデル(1) • 用例ベース対話システム (IRS) • ユーザ発話と類似した用例を検索し応答とする • 408 回分の対話から抽出した合計 26972
個の用例を使用 • 検索に Apache Lucene,形態素解析器に Kuromoji を使用 • 応答候補は類似度の上位 10 件,応答スコアは Apache Lucene が 出力した類似度 7
対話モデル(2) • Neural Conversational Model(NCM) • ニューラルベースの Encoder-Decoder Model •
各 1000 次元の LSTM を 4 層のネットワークに使用 • 語彙数は入力, 出力ともに 80000 とし, Dropout 率は 20% , パラ メータの最適化手法には Adam • 学習データには約 1000 万件の Twitter のツイート・リプライペア を使用 8
対話モデル(3) • Neural Utterance Ranking モデル (NUR) • ニューラルネットワークベースの対話モデル •
生成した発話候補をランキングし,高順位の発話を使用 • 応答のスコアは NUR モデルが発話候補の順位付けのために出力す るスコアを用いる 9
提案手法 • 分類ベース • 破綻検出の分類結果を重視し,破綻と分類された応答候補を下位 にする手法 • 各ラベルの確率分布から最大確率のラベルを分類結果とする • 非破綻確率ベース
• 応答候補のスコアと非破綻確率の積をスコアとしリランキング • 線形回帰ベース • 各破綻ラベルの確率と応答スコアを入力とした線形回帰モデルの 算出スコアでリランキング • 損失関数は,教師スコア 1.0,負例 0.0 とした時の平均二乗誤差 10
学習データ • NCM と NUR は,独自に収 集したものを使用 • IRS は
DBDC2 のデータセッ トを使用 Table 1: 対話破綻検出学習データ 11
評価実験 • 応答候補リストをリランキ ングした結果を評価 • テストデータは,複数候補 に対し破綻ラベルを付与し たものを使用 • 評価指標には
MAP を使用 Table 2: テストデータ 12
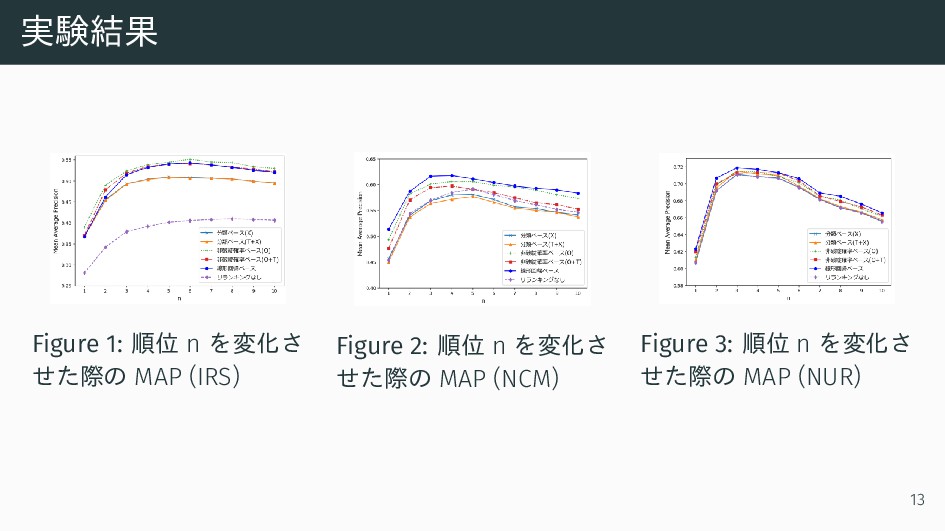
実験結果 Figure 1: 順位 n を変化さ せた際の MAP (IRS) Figure
2: 順位 n を変化さ せた際の MAP (NCM) Figure 3: 順位 n を変化さ せた際の MAP (NUR) 13
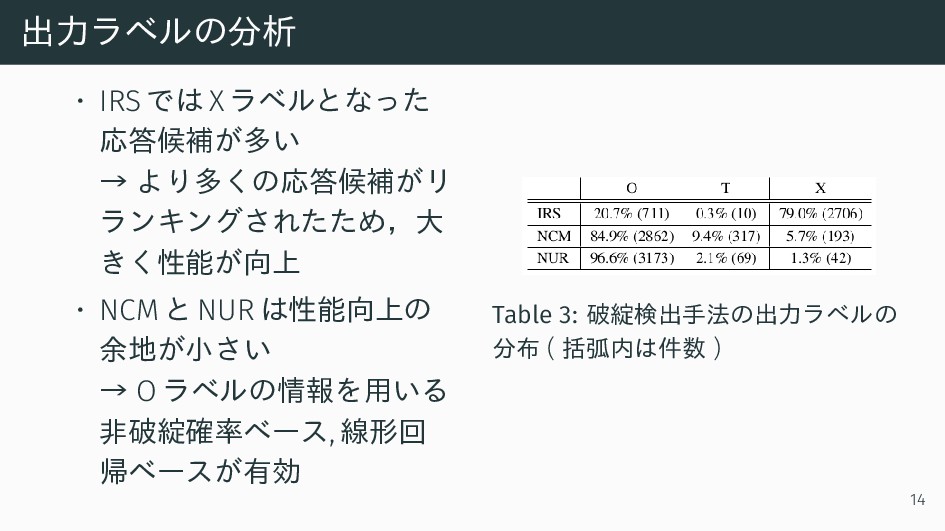
出力ラベルの分析 • IRS では X ラベルとなった 応答候補が多い → より多くの応答候補がリ ランキングされたため,大
きく性能が向上 • NCM と NUR は性能向上の 余地が小さい → O ラベルの情報を用いる 非破綻確率ベース, 線形回 帰ベースが有効 Table 3: 破綻検出手法の出力ラベルの 分布 ( 括弧内は件数 ) 14
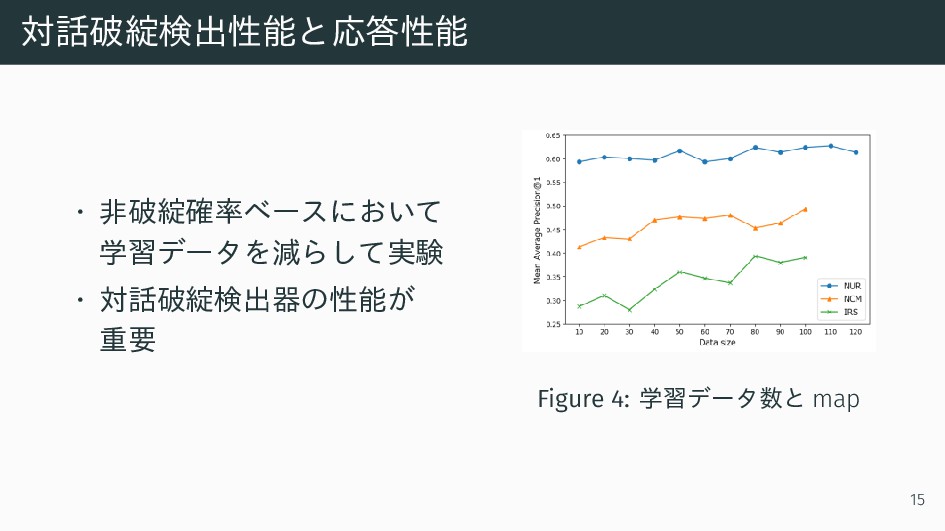
対話破綻検出性能と応答性能 • 非破綻確率ベースにおいて 学習データを減らして実験 • 対話破綻検出器の性能が 重要 Figure 4: 学習データ数と
map 15
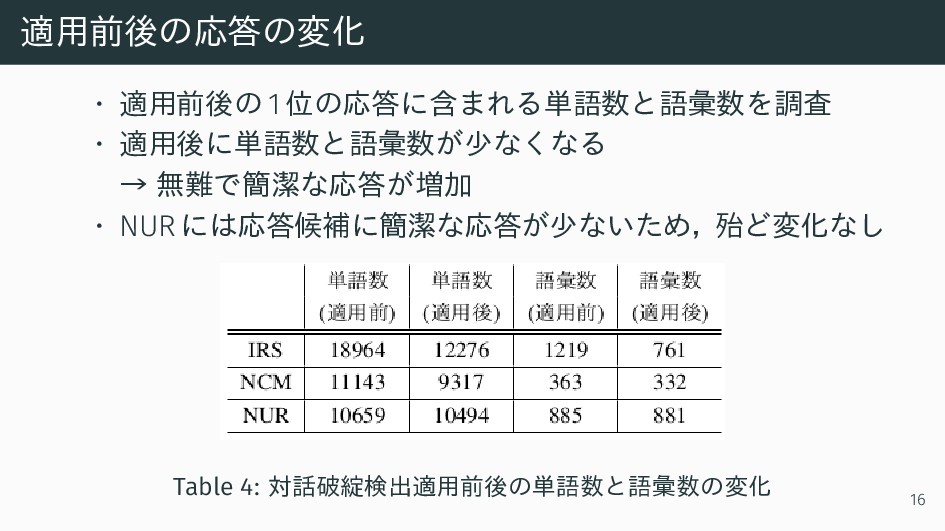
適用前後の応答の変化 • 適用前後の 1 位の応答に含まれる単語数と語彙数を調査 • 適用後に単語数と語彙数が少なくなる → 無難で簡潔な応答が増加 •
NURには応答候補に簡潔な応答が少ないため,殆ど変化なし Table 4: 対話破綻検出適用前後の単語数と語彙数の変化 16
対話実験 • 実際にユーザとシステムで 対話を行い評価 • IRS+非破綻確率ベースを 使用 • クラウドワーカー 110
名に より,自然さ,楽しさ,総 合の 3 項目で評価 Table 5: 対話実験結果 ( 括弧内は人数 ) 17
まとめ • 対話破綻検出を適用することで,対話システムの応答性能 を向上出来るかを実験的に評価 • 適用手法として,分類ベース手法,非破綻確率ベース手法, 線形回帰ベース手法を提案 • 非破綻確率ベース手法と線形回帰ベース手法において全て のシステムの応答性能の向上が確認
• 対話破綻検出を適用しないモデルと比較し,自然さが向上 するが,楽しさが低下することを確認 • 今後の課題は,無難な応答が増加することへの対処が挙げ られる 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}