and Xueqi Cheng. ReCoSa: Detecting the Relevant Contexts with Self-Attention for Multi-turn Dialogue Generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3721–3730, Florence, Italy, July 2019. Association for Computational Linguistics. 2
HRAN では Attention を用いこれを解決 • RNN では遠い位置にある関連文脈を捉え るのは難しい • 本研究では,Self-Attention でこの問題を 改善 Table 1: The two examples from the customer services dataset, and the red sentence indicaters the relevant context to the response.[1] 4
{kind=link}
![文献情報 [1] Hainan Zhang, Yanyan Lan, Liang Pang, Jiafeng Guo,](https://files.speakerdeck.com/presentations/75aa517841a74a288a86e17a30525f04/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
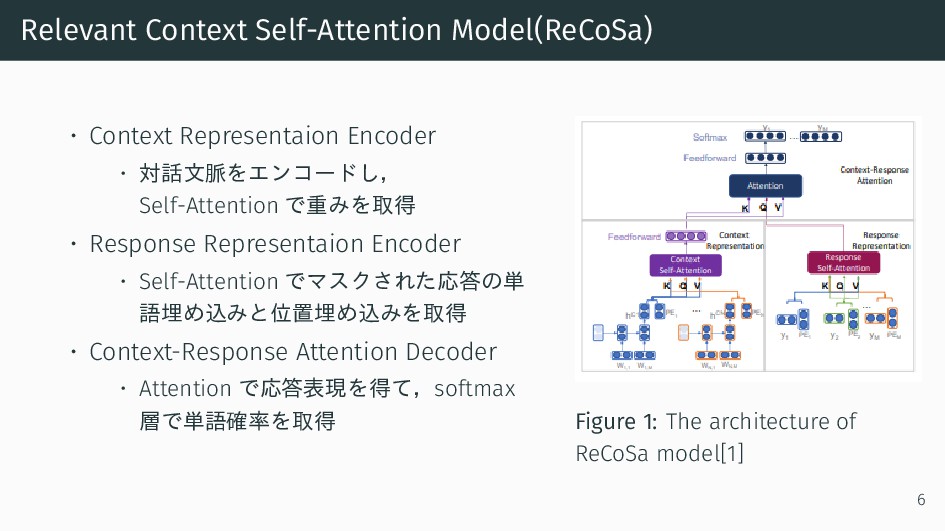{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Results 1 Table 2: The metric-based evaluation results (%).[1] Table](https://files.speakerdeck.com/presentations/75aa517841a74a288a86e17a30525f04/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
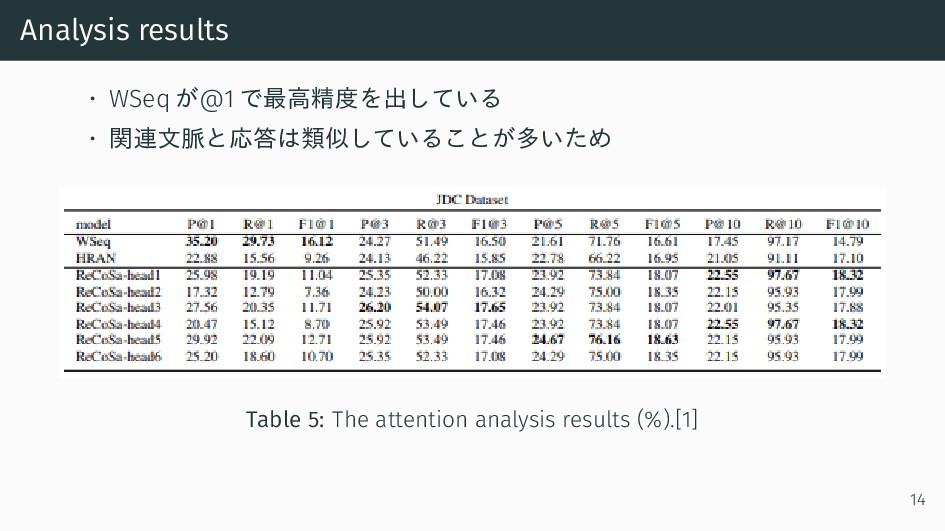{kind=link}
{kind=link}