and Yoshua Bengio. Do neural dialog systems use the conversation history effectively? an empirical study. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 32–37, Florence, Italy, July 2019. Association for Computational Linguistics. 2
{kind=link}
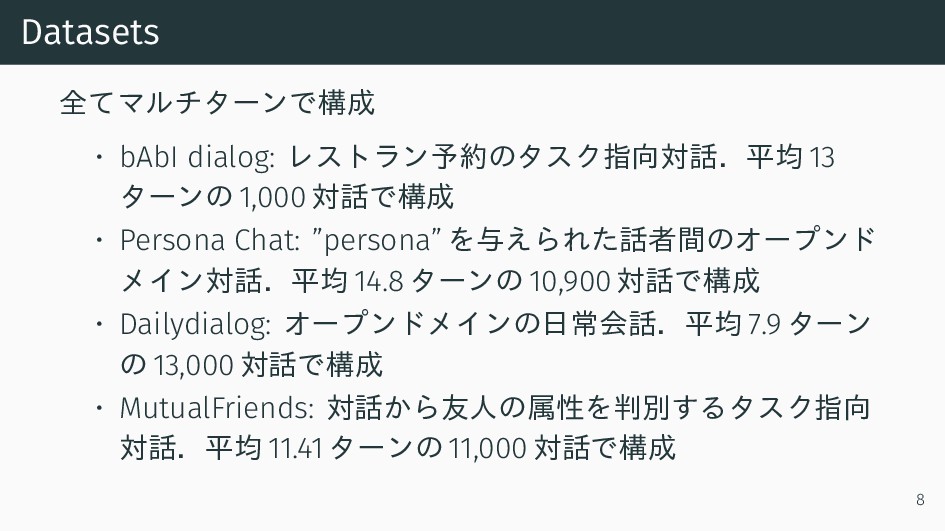
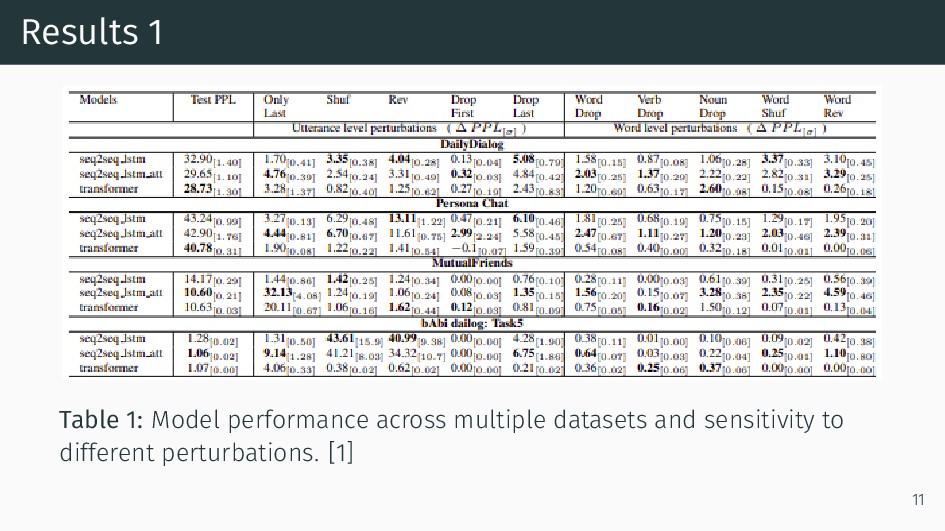
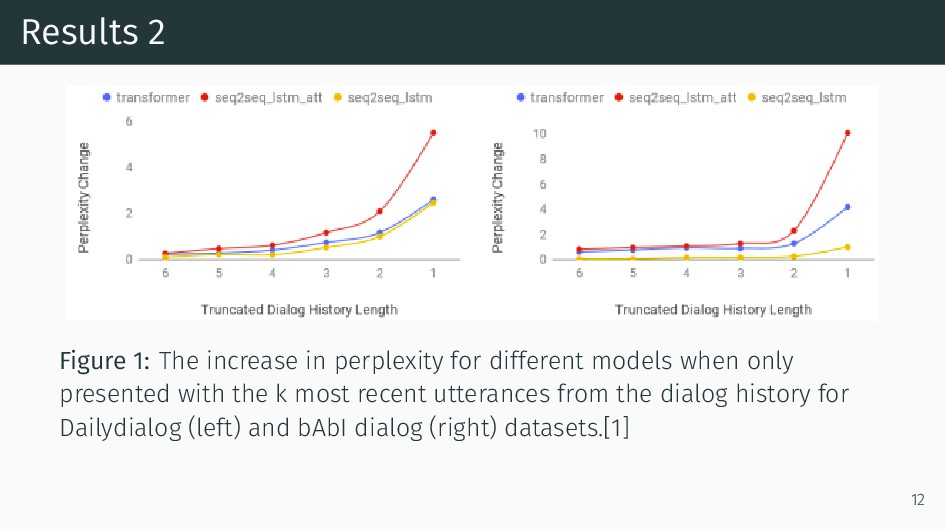
![文献情報 [1] Chinnadhurai Sankar, Sandeep Subramanian, Chris Pal, Sarath Chandar,](https://files.speakerdeck.com/presentations/570b8f49b74e44d8bcdef2cd488715a9/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}