Peng. Better Automatic Evaluation of Open-Domain Dialogue Systems with Contextualized Embeddings. In Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation, pages 82–89, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. 2
• データや言語の違いに起因する可能性 Table 2: Correlation and similarity values between automatic evaluation metrics (combination of Referenced and Unreferenced metrics) and human annotations for 300 query-response pairs annotated by AMT workers. [1] 14
{kind=link}
![文献情報 [1] Sarik Ghazarian, Johnny Wei, Aram Galstyan, and Nanyun](https://files.speakerdeck.com/presentations/b1220366ac404fcb8ebce8de0276cb52/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
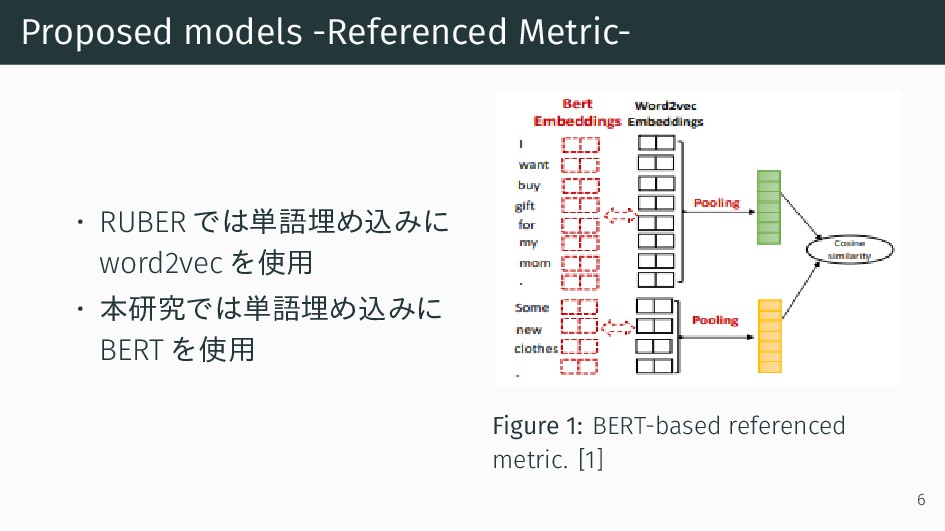{kind=link}
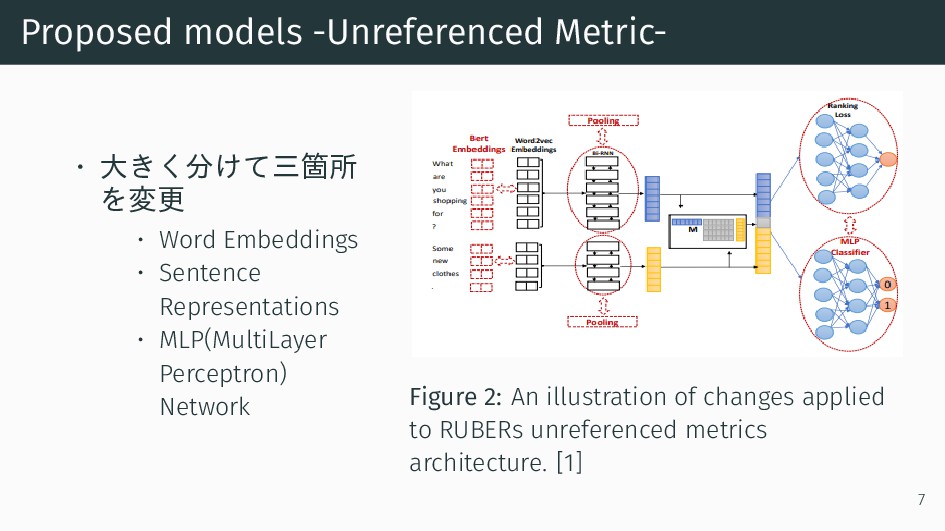{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
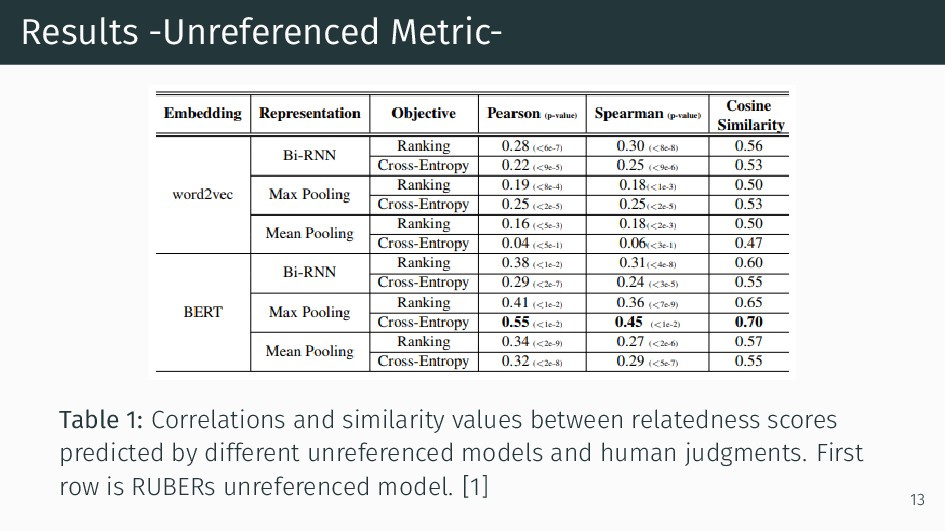{kind=link}
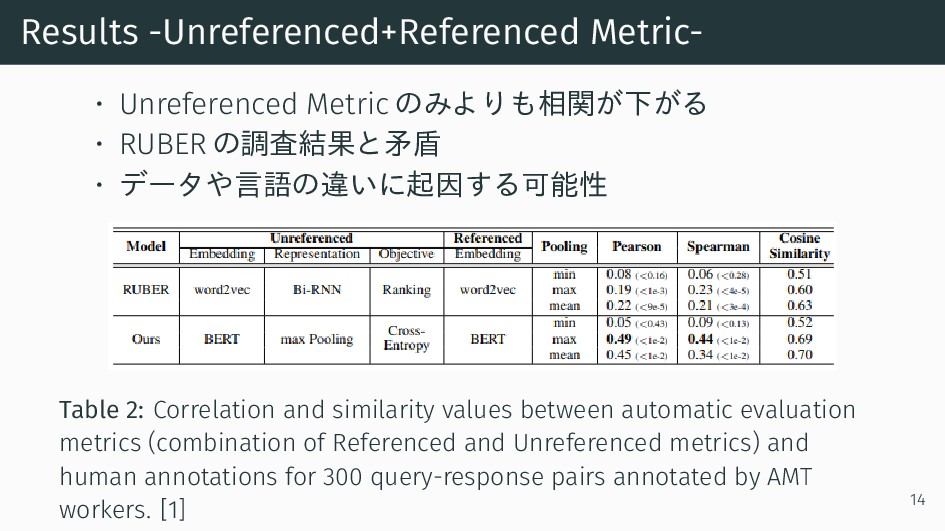{kind=link}
{kind=link}