by tiger | a1 ~ aT) となる.(タイガーに食べられてしまうこと確率を最 小化したい) 一般的に書くと となる.ここで,Cはコスト関数 ★ コスト関数の導入と記法 1 1 1 min ( , ) . . ( , ) T t t t t t t c s a s t s f s a − − = =
) ( ) ( ) ( ) , 1 1 ... T t t t E c s a T T + − − + ★ 1-εの確率で失敗しないで次のステップにい ける.すると,その先でも同じことが起きるの で,また同様にεの確率で失敗して,(T-1)分 のコストをもらう. この値のオーダーは O(εT^2)になる. これは非常に大きいバウ ンドであまり良くない... さてどうしよう?? ※コストなので注意
) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) ( ) | | | 1 1 1 | | 1 1 1 1 | 1 1 | | t train t t t train t mistake t train t t t train t mistake t t mistake t train t p s p s p s p s p s p s p s p s p s − = − + − − − = − − − + − − = − − − この絶対値の確率分布の差をTotal Variation Divergenceという. 最も大きくなるのは,2!(ptrainと全く違う値をとるとすると引き算して絶対値とると 2になる.)よってこの値でバウンドできる.
) ( ) ( ) t t train t train t p s p s p s p s = + − (絶対値を取ることは問題ない => バウンドできる) 定義から1 期待値なのでε 何があろうと さっき計算したこの値 2 2 T T + 結局quadraticな値 になってしまう! これが一般的な 模倣学習の解析 https://rikeilabo.com/sum-formula-of-numerical-sequence
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
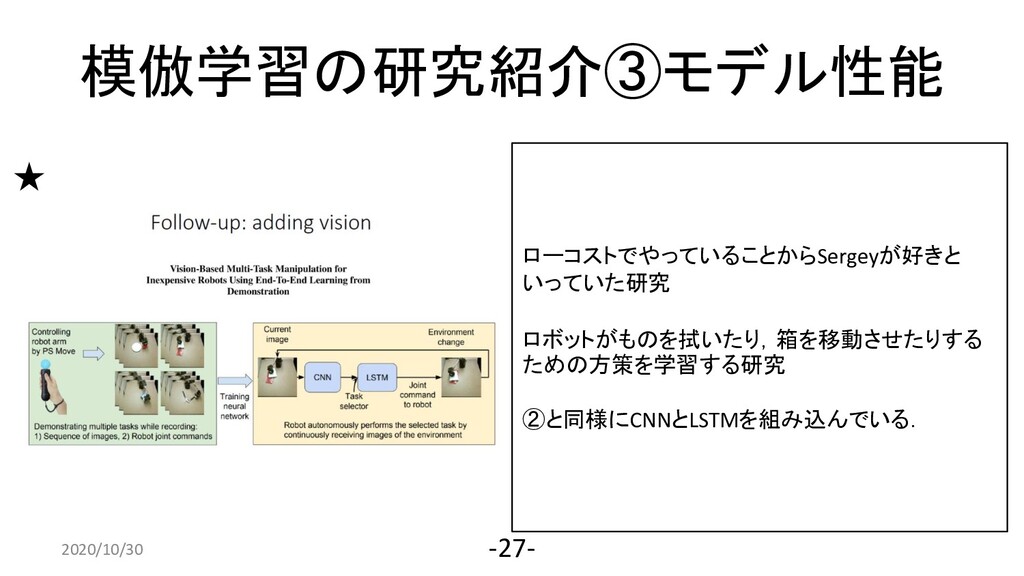{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}