страницы (!), • Поиск по компаниям US и UK для продаж, • Цель - найти компании, выдача - список компаний, • [heat pump], [cable production], [baking soda].
• Компании торгующие хлебопекарными изделиями в UK • Печи бюджетные, поэтому средние компании: с доходом не выше X GBP и не более 100 человек • Много, фильтр: получили инвестиции или был куплены (событийные триггеры)
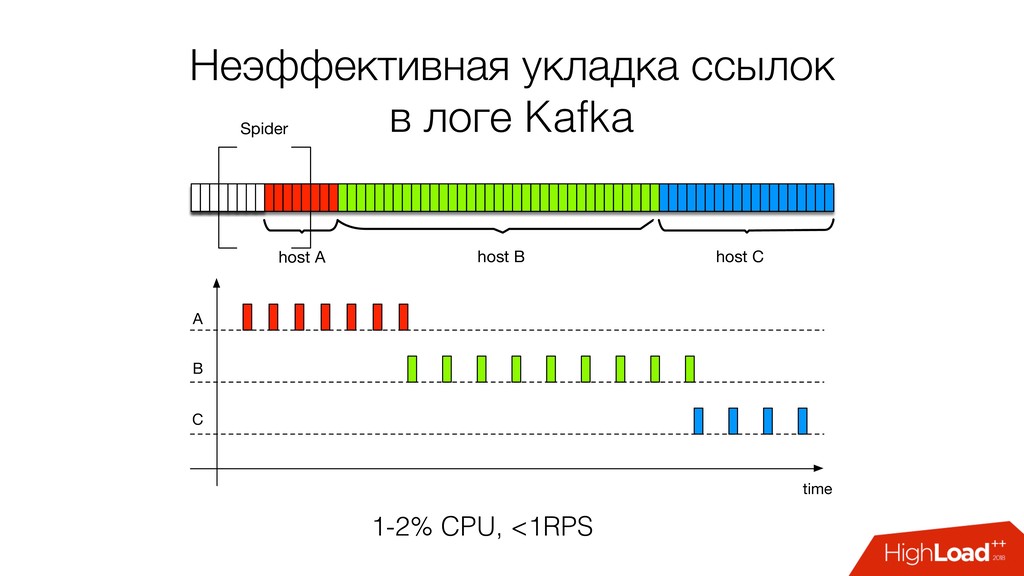
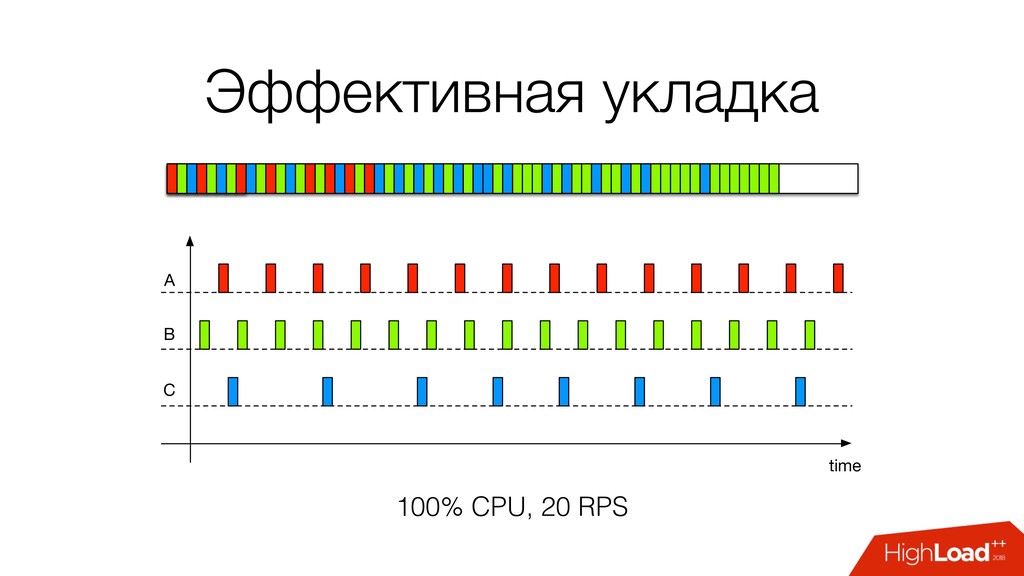
затыков в разных частях системы • Следование robots.txt, запросы с задержками (бан) • Минимум железа • 100% загрузка сетевого канала • Хранить контент минимум времени (дешевле и легальнее, GDPR)
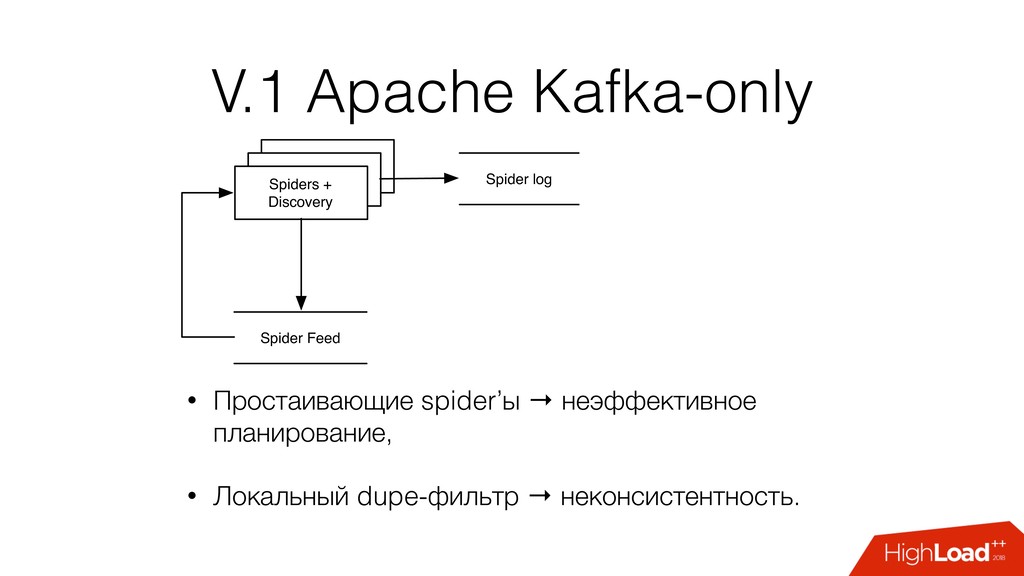
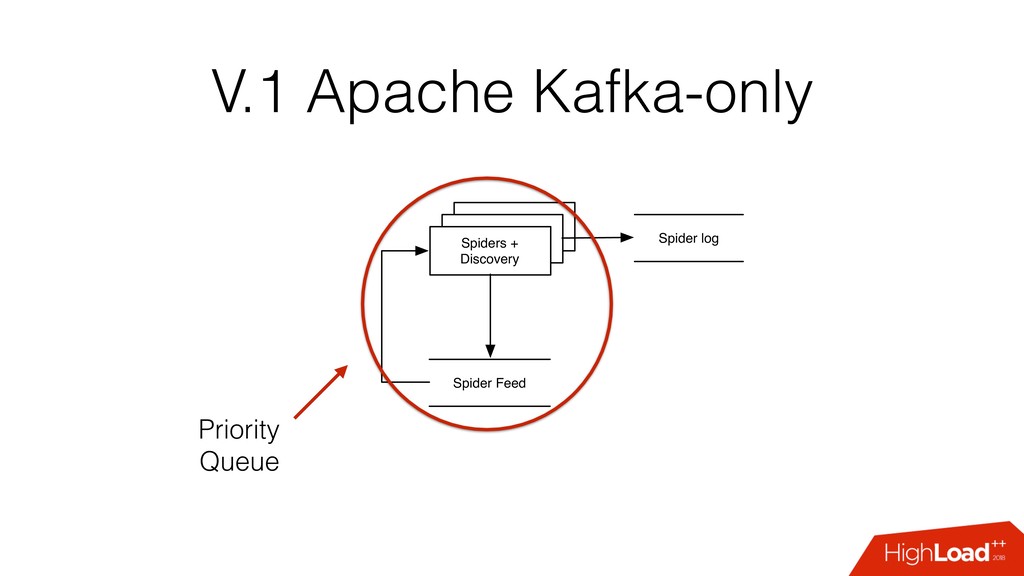
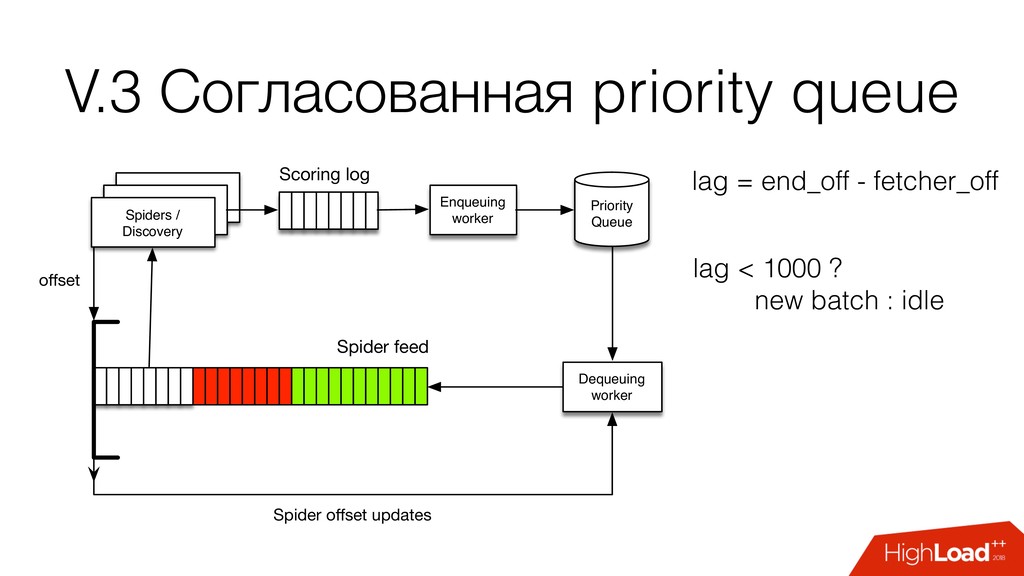
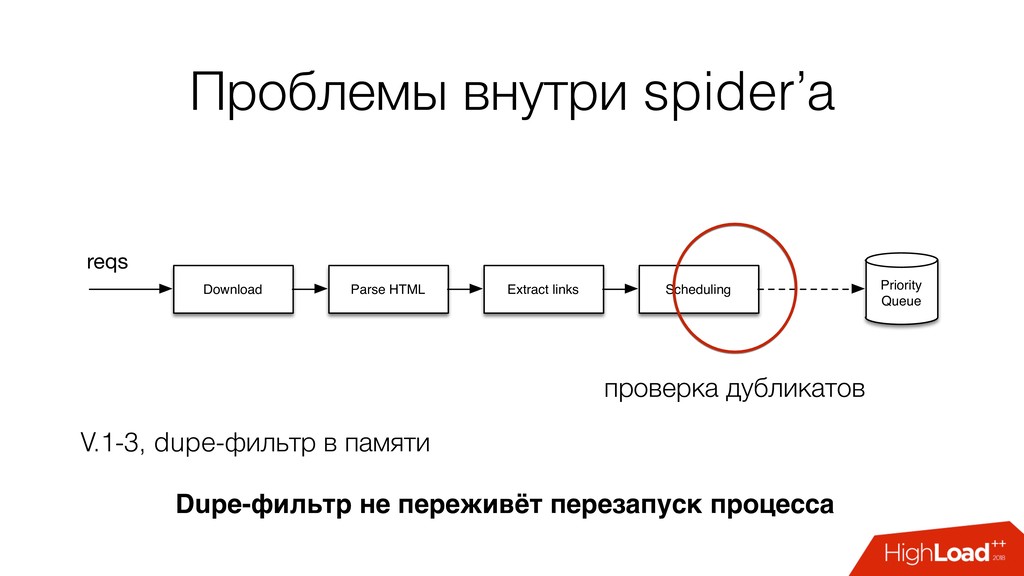
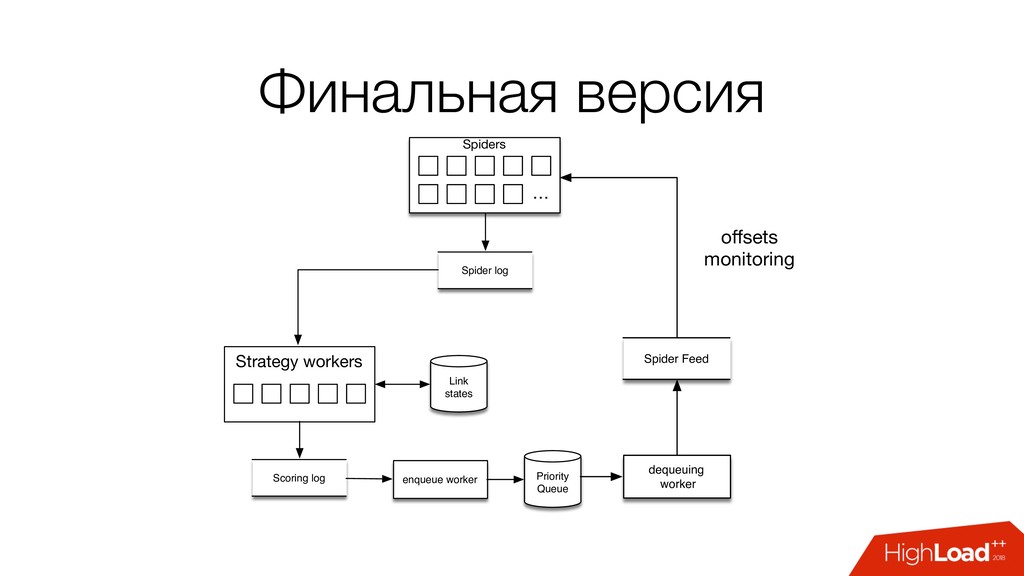
и парсирующий процесс spider feed - поток запросов на прокачку spider log - результаты прокачки: документы, ссылки seed - URL с которого начинается обход
dupe-фильтр: Redis sets (SADD, SLEN) • очередь: Redis sorted set по ключу (ZADD, ZREM*) SPOF Redis ops Как дальше масштабировать? См. https://github.com/rmax/scrapy-redis
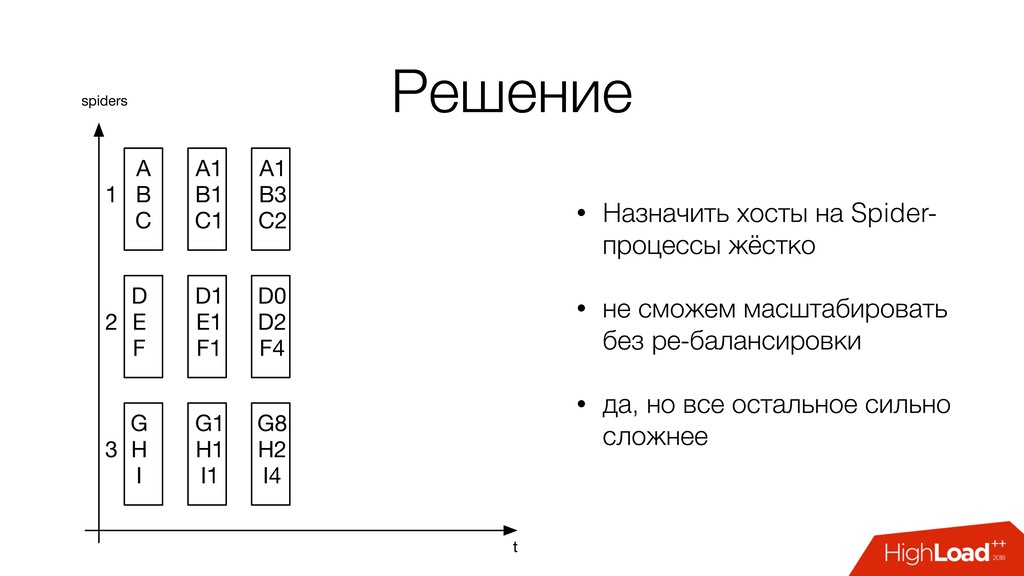
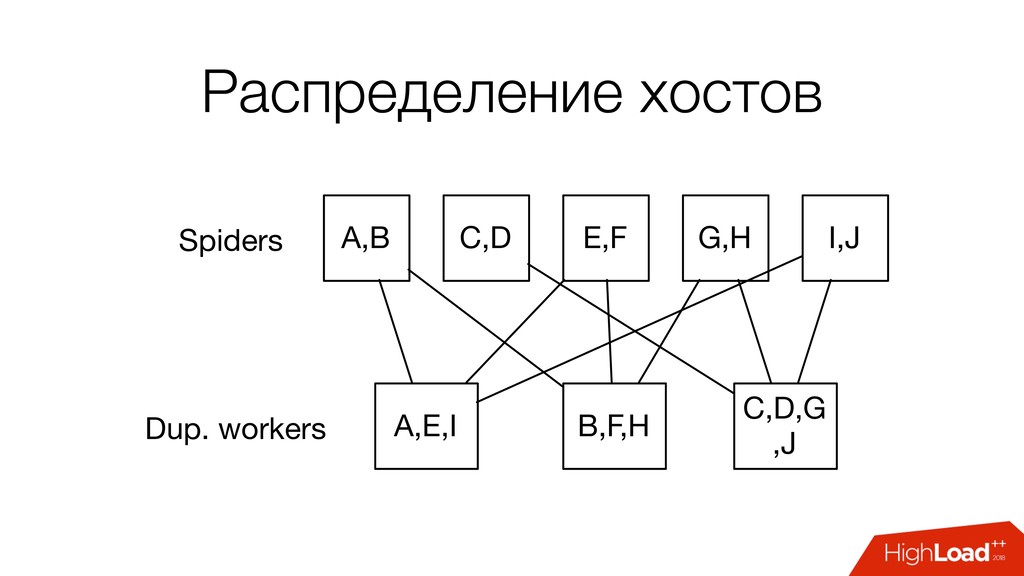
хостам • Один хост с нескольких процессов? • Как сделать доступным, для всех процессов? • Не надо • Нужно качать каждый хост, не более чем с одного процесса
B3 C2 D0 D2 F4 G8 H2 I4 1 2 3 D E F G H I D1 E1 F1 G1 H1 I1 • Назначить хосты на Spider- процессы жёстко • не сможем масштабировать без ре-балансировки • да, но все остальное сильно сложнее
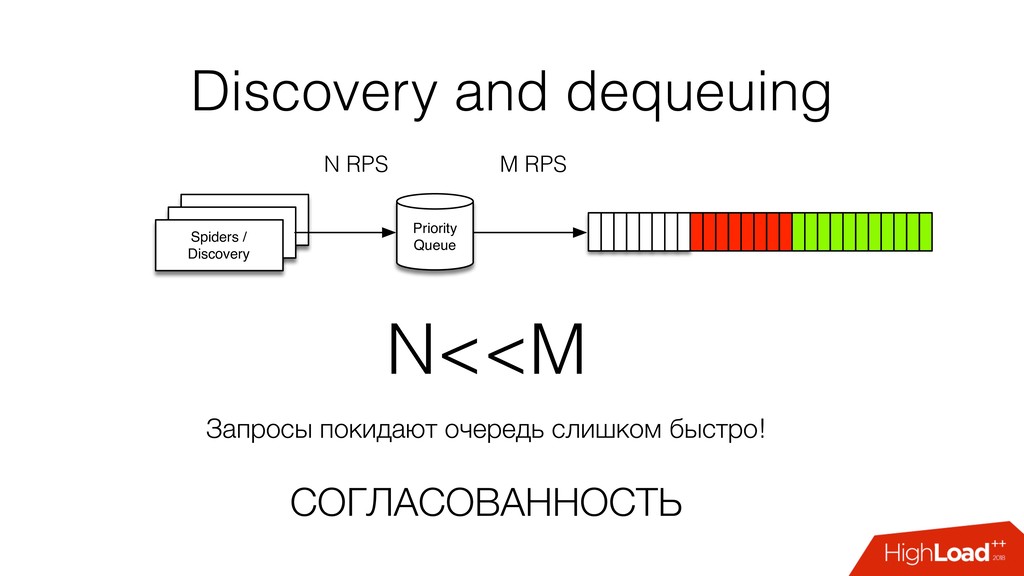
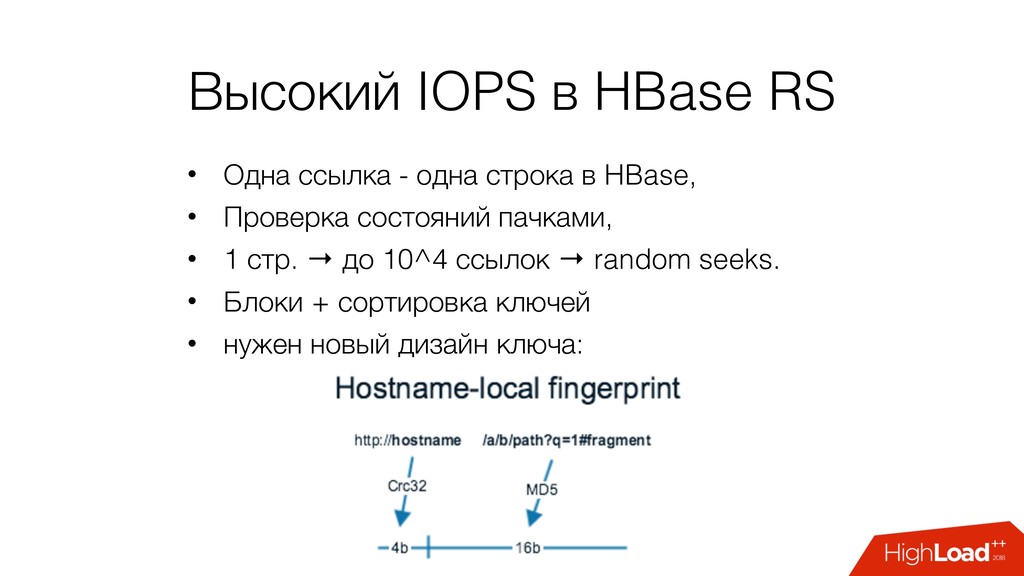
→ требования к ACID низкие, • Данных много, миллиарды ссылок, миллионы URL в очереди, Тб → шардирование, • Access patterns: • GET по ключу, • GET/PUT пачку.
Состояния ссылок: RPS высокий, но большое пересечение → возможность брать из кэша, • В один момент времени мы работаем с небольшой частью данных, • Хорошая масштабируемость, • Стоимость потери данных велика → репликация.
разных хостов. • Не допускать обработку одного хоста с нескольких машин: дубликаты, бесконтрольный RPS. • Продумывать назначение хостов на начальном этапе. • При проверке ссылок кэш, страницы с одного сайта имеют похожие ссылки.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо! Вопросы. [email protected]](https://files.speakerdeck.com/presentations/30ef08d802cc4d5bb1340b9f5fb5a213/slide_53.jpg){kind=link}