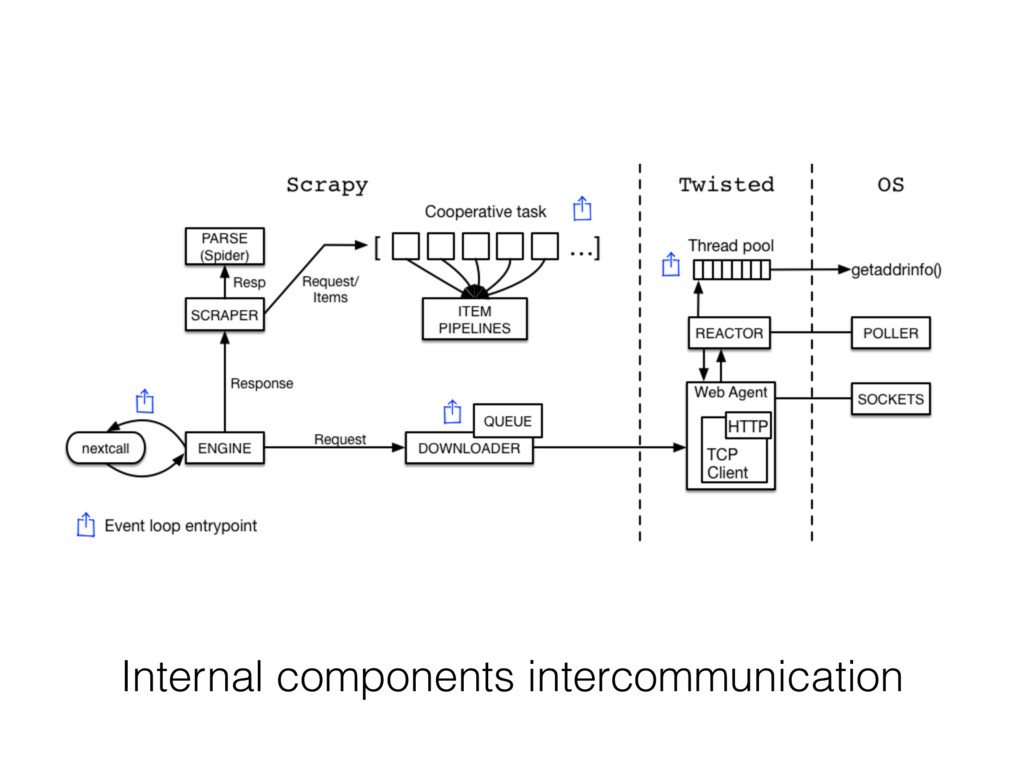
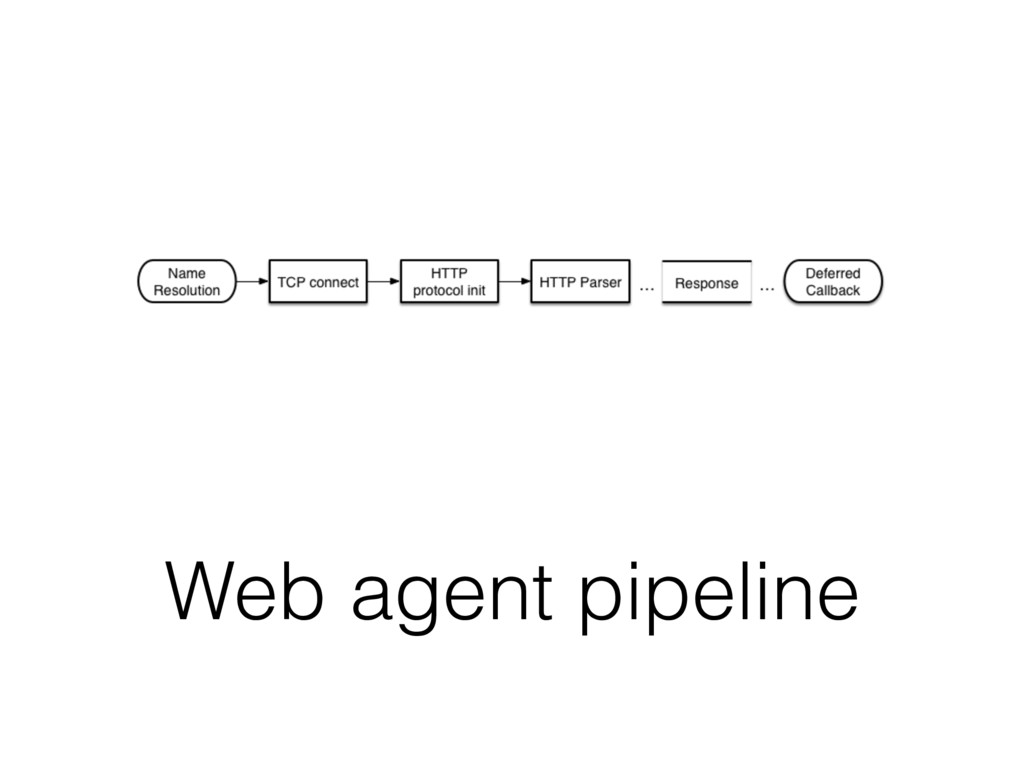
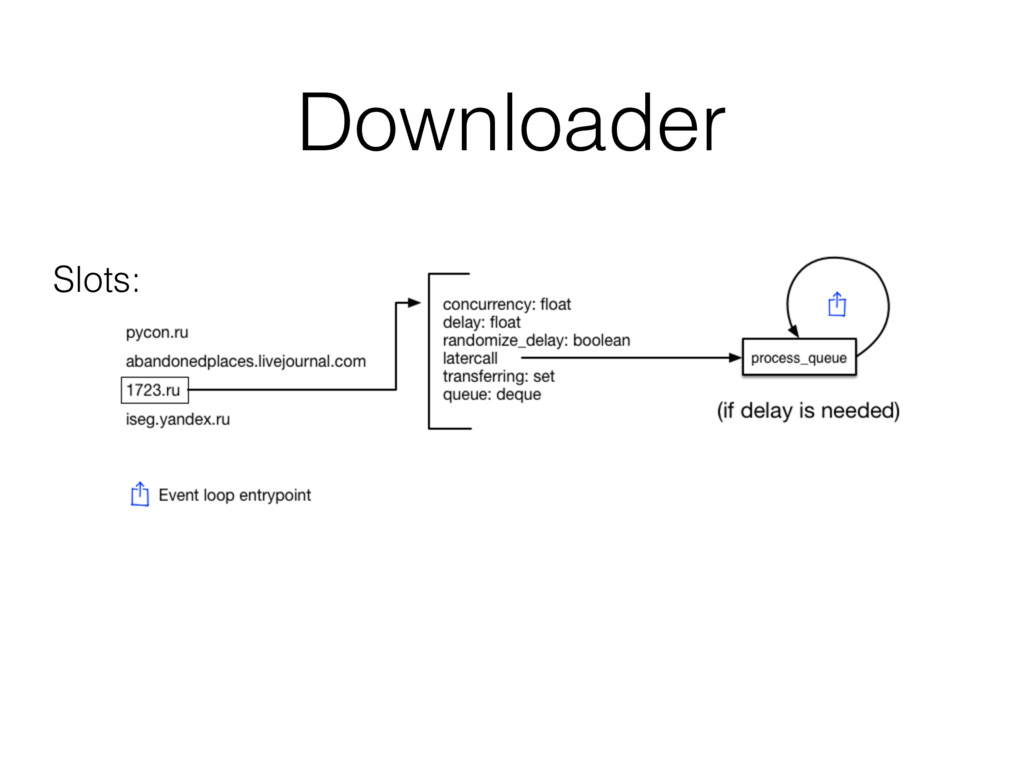
Scrapy itself is a good example of modern asynchronous application. Moreover it's a swiss army knife with all kinds of extensions: Item pipelines, HTML/CSS selectors, Middlewares. In this talk, I’m going to explain how the Scrapy’s internal processing pipeline works, the design of it’s downloader queue and all the things needed to debug it: Scrapy shell, telnet console, memory consumption debugging.
Scrapy is a 100% asynchronous web scraping framework built with Twisted event loop with 21K GitHub stars!
![Scrapy internals Alexander Sibiryakov, 16-17 July 2017, PyConRU 2017 [email protected]](https://files.speakerdeck.com/presentations/49c70710d2504f32985e915841507a27/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
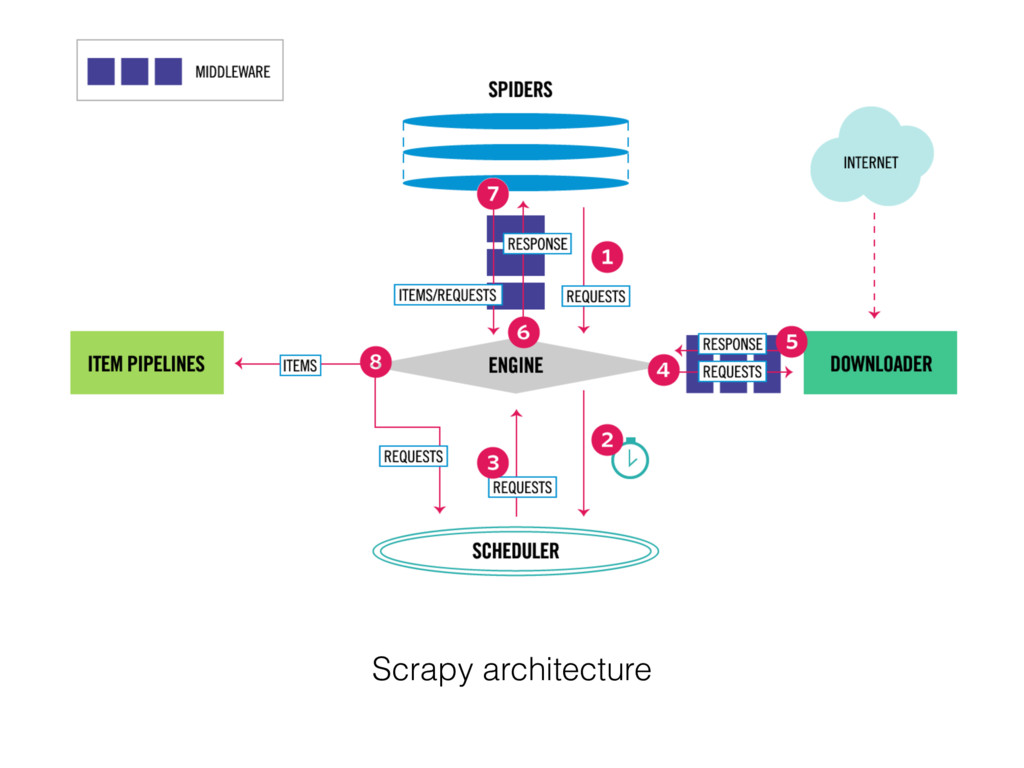{kind=link}
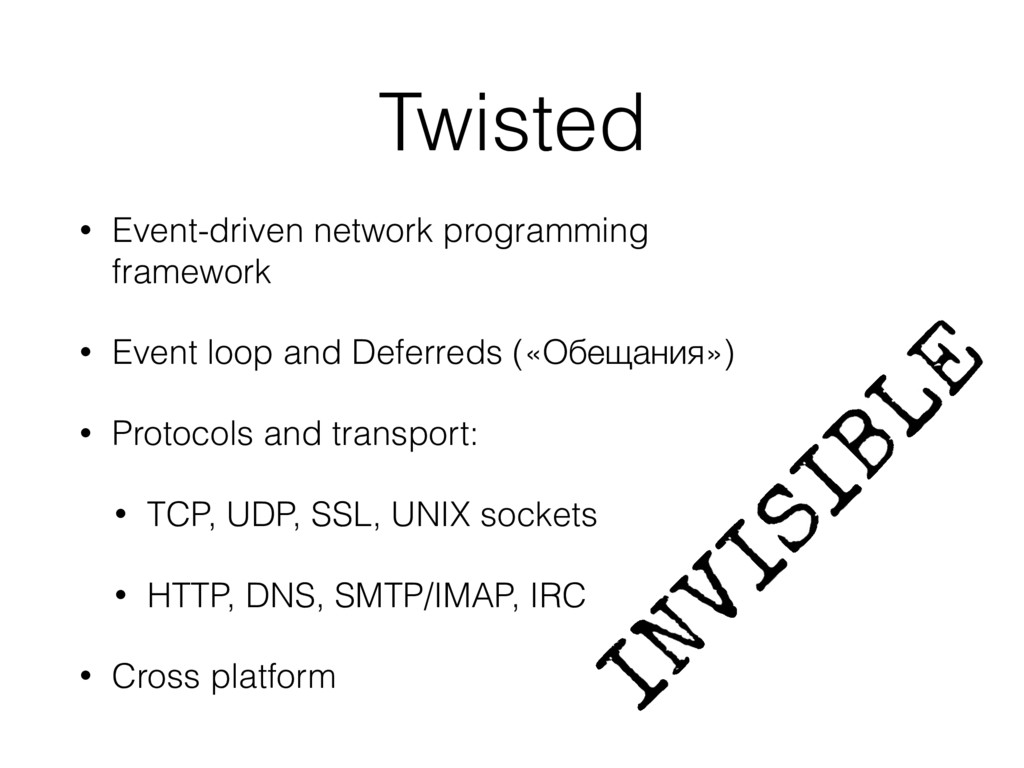{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
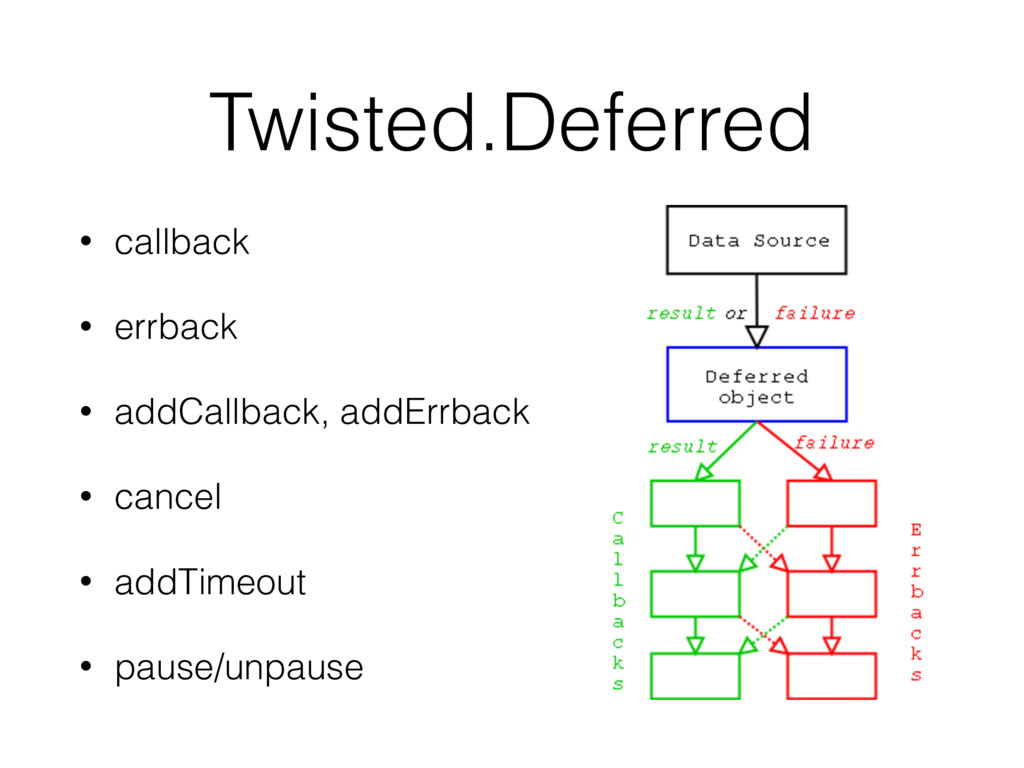{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы Alexander Sibiryakov, Scrapinghub Ltd., [email protected]](https://files.speakerdeck.com/presentations/49c70710d2504f32985e915841507a27/slide_21.jpg){kind=link}