In this talk I’m going to introduce Scrapinghub’s new open source framework Frontera. Frontera allows to build real-time distributed web crawlers and website focused ones.
Offering:
customizable URL metadata storage (RDBMS or Key-Value based),
crawling strategies management,
transport layer abstraction.
fetcher abstraction.
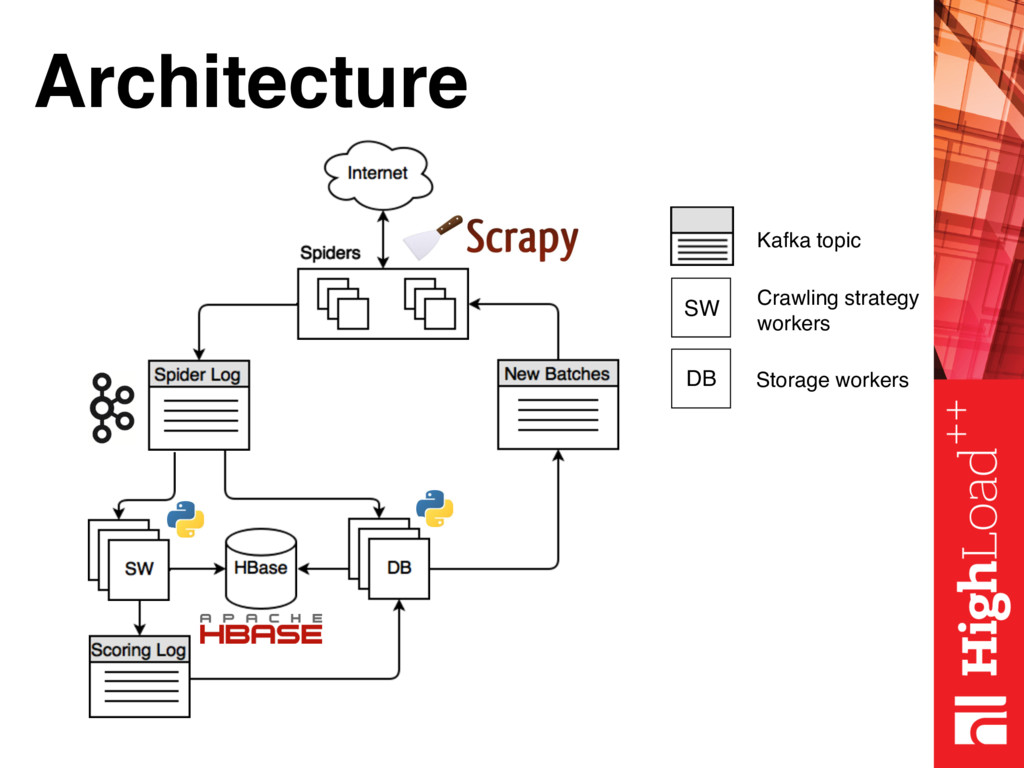
Along with framework description I’ll demonstrate how to build a distributed crawler using Scrapy, Kafka and HBase, and hopefully present some statistics of Spanish internet collected with newly built crawler.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо! Alexander Sibiryakov, [email protected]](https://files.speakerdeck.com/presentations/2121d9612c6747fcbf98d190d7f0b69f/slide_33.jpg){kind=link}