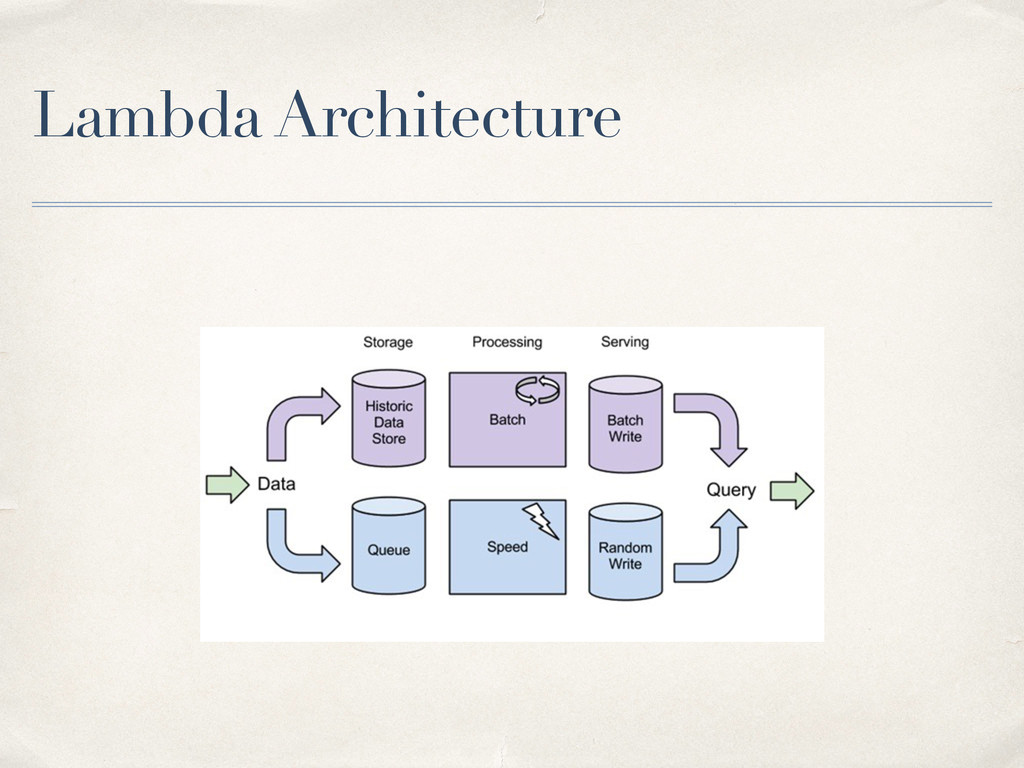
It is important for anyone building a software platform to have a good pulse on the patterns of use that the system would see — this is one of the most important aspects that determines the value it would generate. The world of Big Data, Analytics & Data Science is fast-moving, with the "in vogue" tools changing almost every year. While most of us have grown accustomed to adopting to the changes in tooling, what often catch us unawares are the paradigm shifts within the ecosystem. This talk will walk through some such emerging patterns in the world of Big Data and go over how they're manifested at Flipkart — which has been an early adopter of many of these patterns.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}