Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Streaming Ingestion & Processing at Flipkart
Search
Siddhartha Reddy
May 15, 2015
Technology
430
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Streaming Ingestion & Processing at Flipkart
Presented at the Bangalore Hadoop Meetup held on 15th May 2015.
Siddhartha Reddy
May 15, 2015
More Decks by Siddhartha Reddy
See All by Siddhartha Reddy
Future Patterns in Data Ecosystem
sids
1
220
CAP Theorem: You don’t need CP, you don’t want AP, and you can’t have CA
sids
6
12k
Other Decks in Technology
See All in Technology
CTOキーノート:AI時代の「つなぐ」を再定義 ― 真のIoTとリアルワールドAI【SORACOM Discovery 2026】
soracom
PRO
0
330
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
260
plamo-3-translateの開発
pfn
PRO
0
220
論語・武士道・産業革命から見る かわるもの、かわらないもの
ichimichi
8
2k
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
170
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
180
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
370
Retriever と Reranker、結局どうする?
kazuaki
1
530
エンタープライズデータへ安全につなぐ Production-ready なエージェント設計 ― AI × MCP リファレンスアーキテクチャ ― #AIDevDay
cdataj
1
370
MCPをつなげて作る組織横断のAIエージェント基盤
tsubakimoto_s
0
440
NYC Summit 2026 における Amazon Bedrock AgentCore のアップデート
ren8k
3
280
『モンスターストライク』 の運営に伴走する! データ民主化への 解析グループの3つのアプローチ
mixi_engineers
PRO
0
190
Featured
See All Featured
Code Reviewing Like a Champion
maltzj
528
40k
Ethics towards AI in product and experience design
skipperchong
2
330
Bash Introduction
62gerente
615
220k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
400
Rails Girls Zürich Keynote
gr2m
96
14k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
190
AI: The stuff that nobody shows you
jnunemaker
PRO
9
850
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
160
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
440
It's Worth the Effort
3n
188
29k
How to Talk to Developers About Accessibility
jct
2
460
Transcript
Streaming Ingestion & Processing at Flipkart Siddhartha Reddy @sids
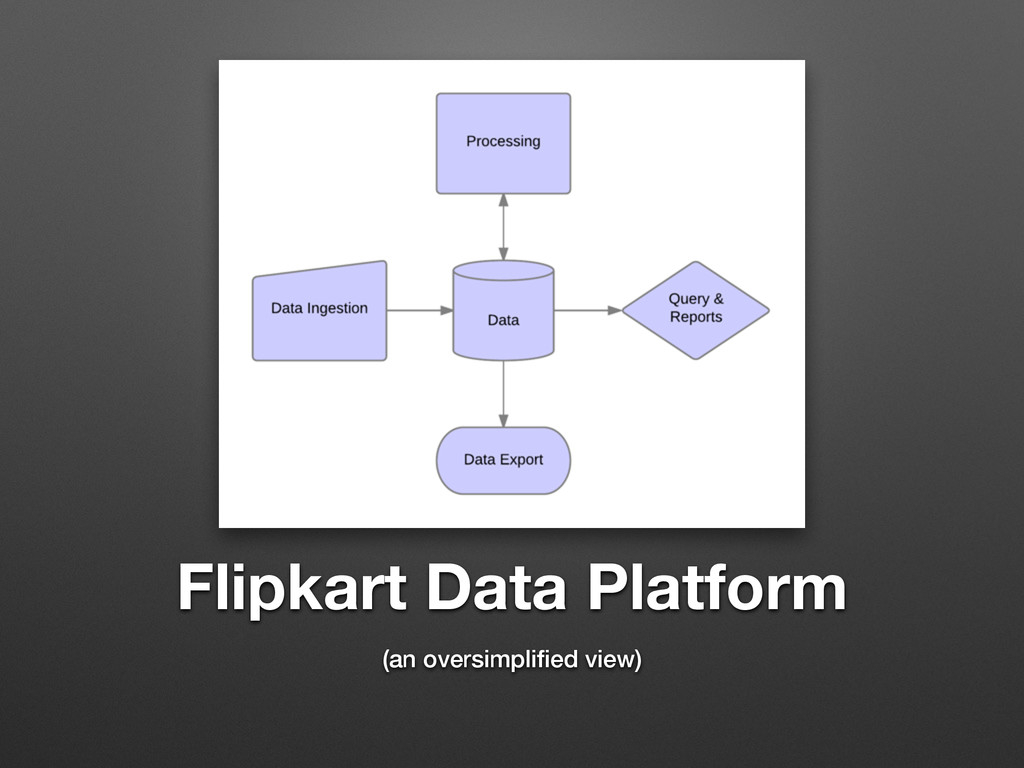
Flipkart Data Platform (an oversimplified view)
Streaming Ingestion
Choices • push, not pull • schemas & validations
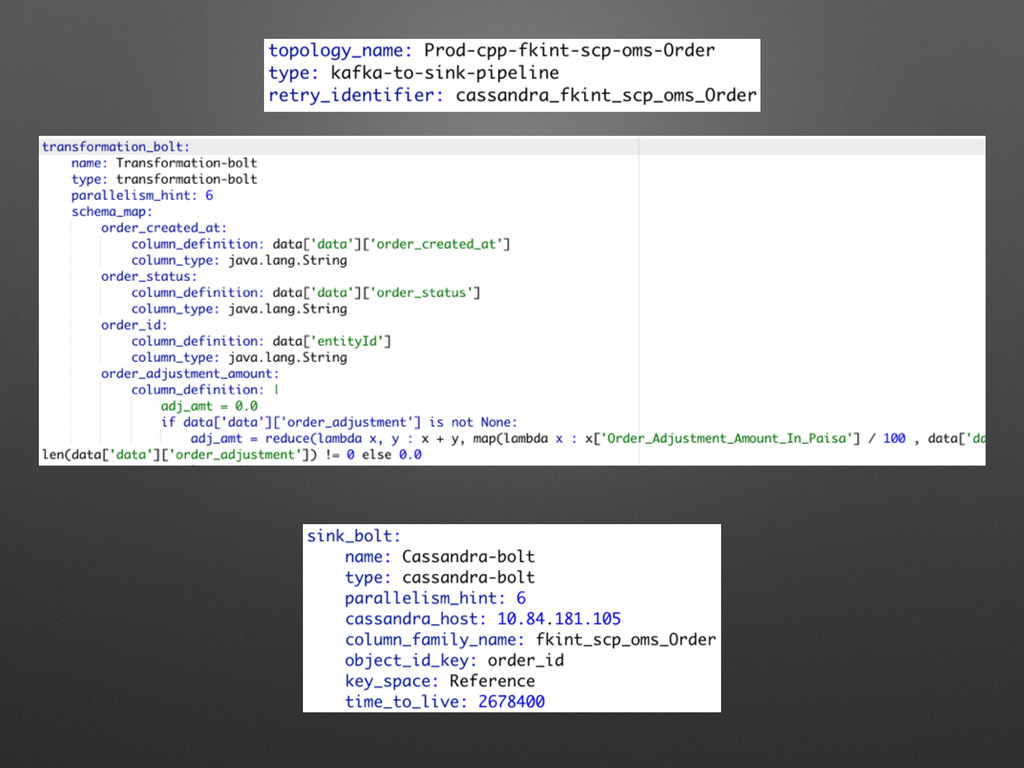
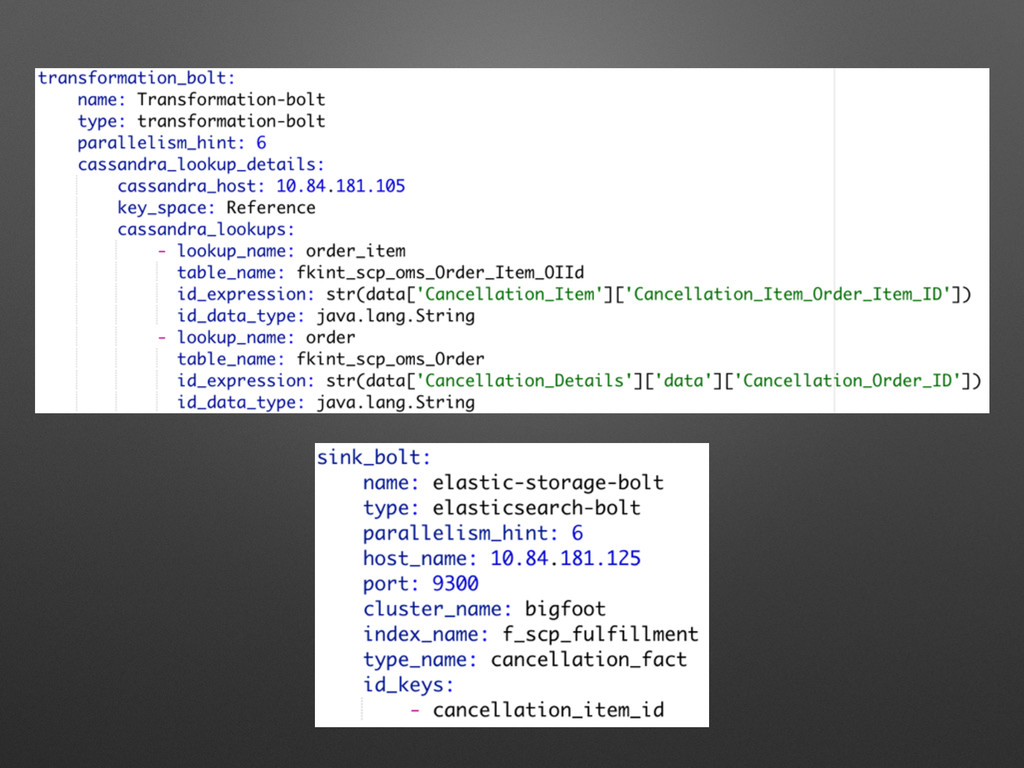
Streaming Ingestion v1.0
None
• Push 㱺 accountability (with source teams) • good call!
• Schemas 㱺 contracts for consumers • can make assumptions that are assured to be true • Insufficient tooling 㱺 too many “ingestion frameworks” • adopt some frameworks & offer as tools! • Synchronous error handling 㱺 complexity • accept all data
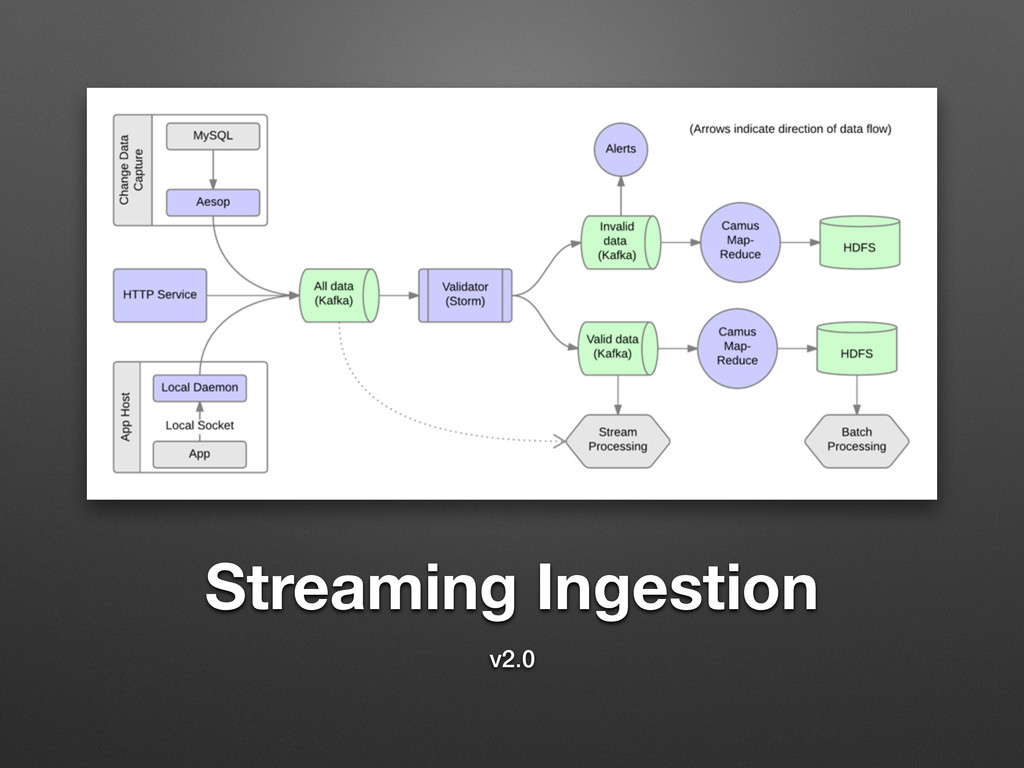
Streaming Ingestion v2.0
Stream Processing
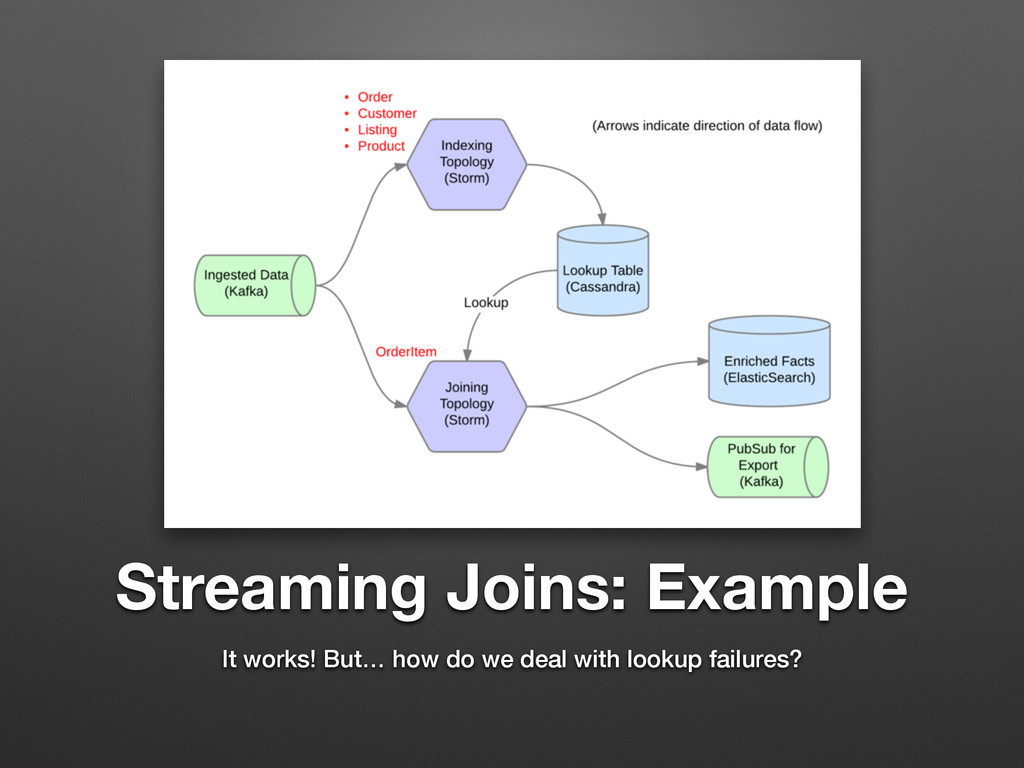
An Example
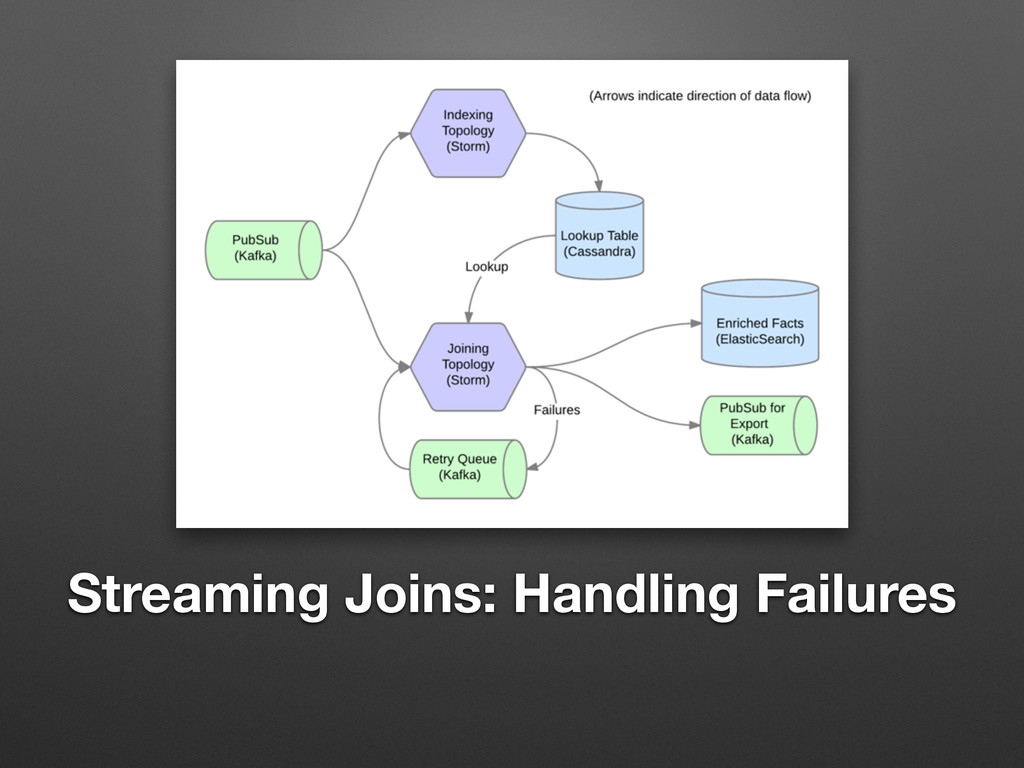
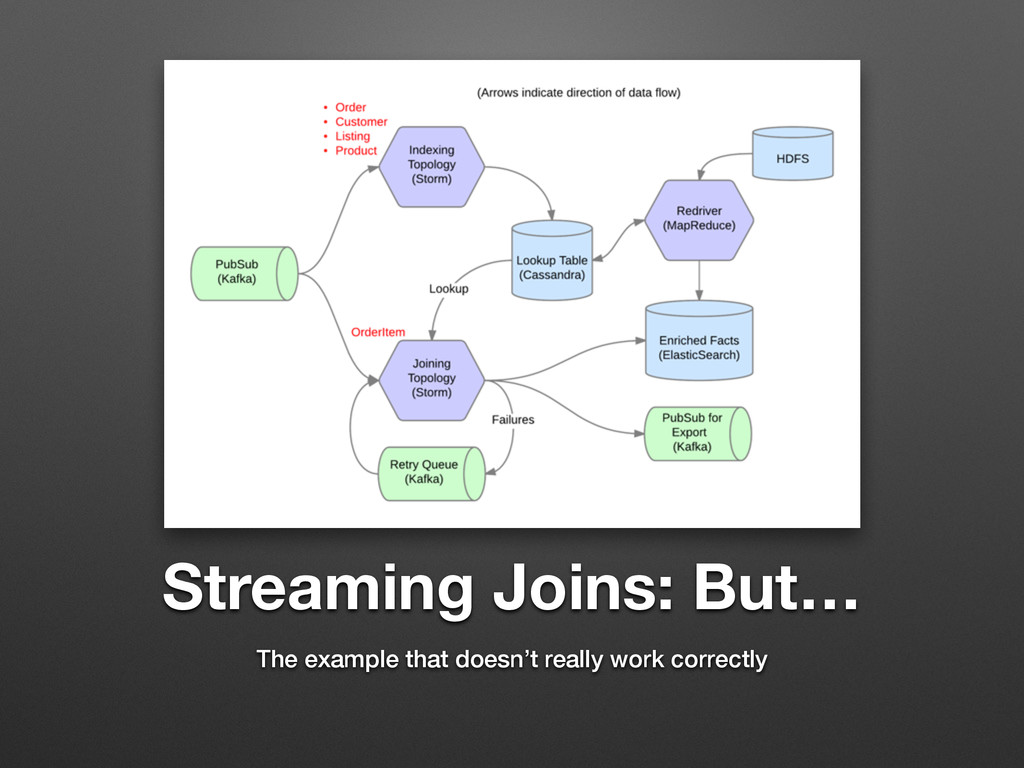
Streaming Joins: Example It works! But… how do we deal
with lookup failures?
Streaming Joins: Handling Failures
None
None
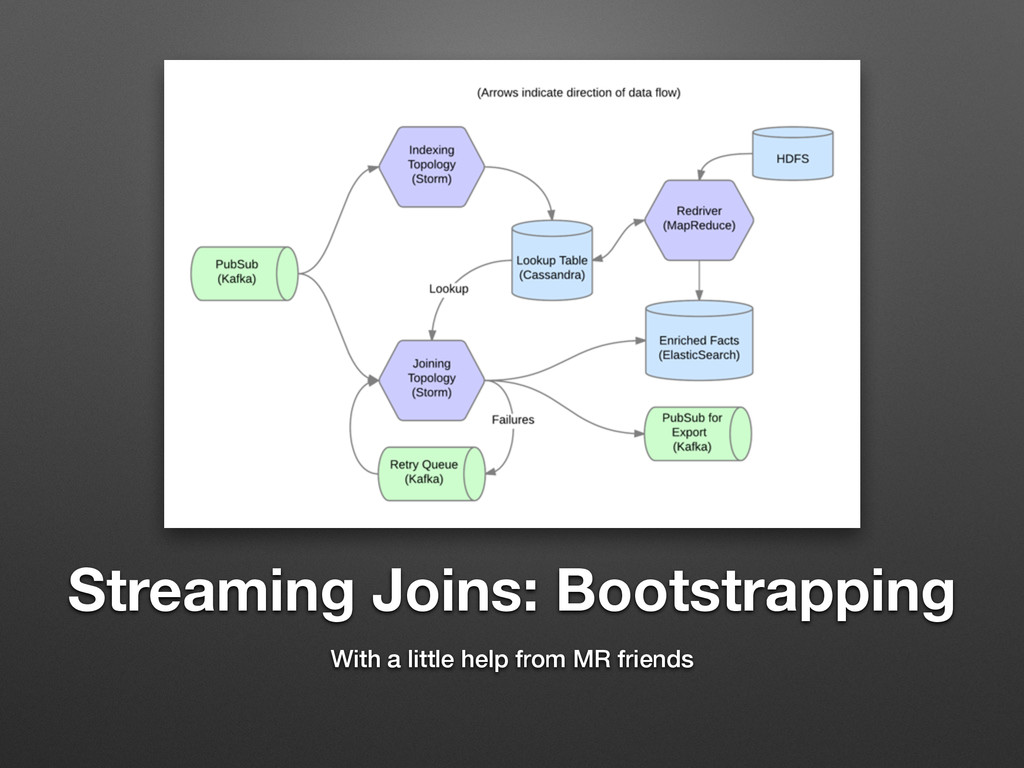
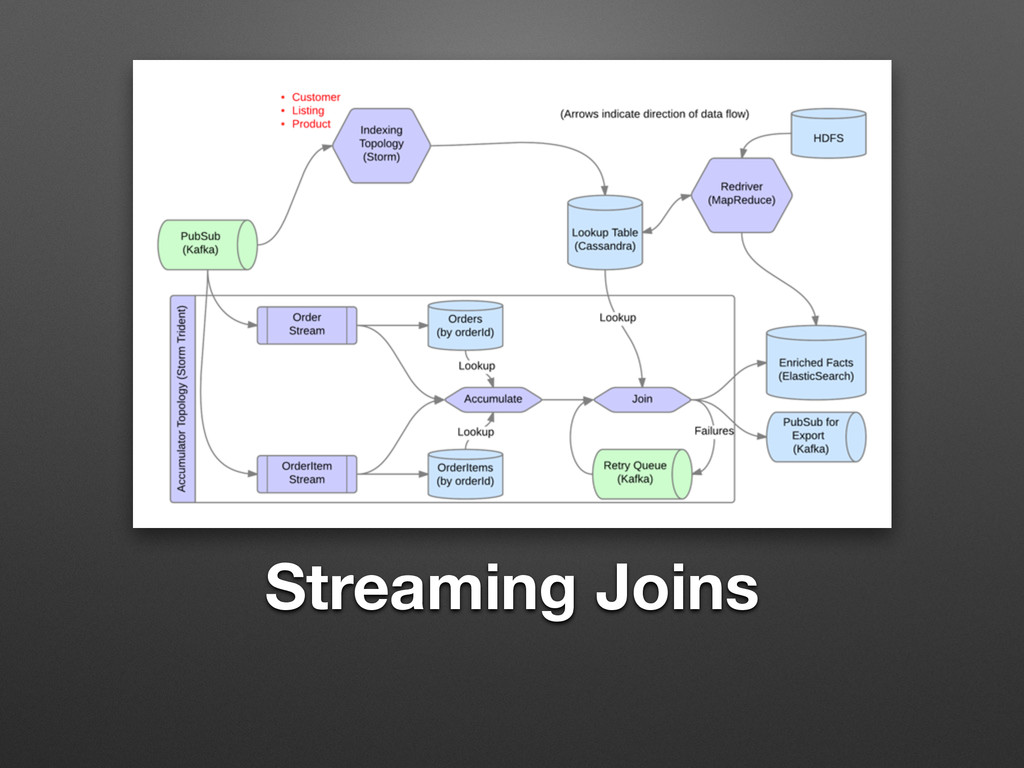
Streaming Joins: Bootstrapping With a little help from MR friends
Streaming Joins: But… The example that doesn’t really work correctly
Streaming Joins
In summary • Streaming Ingestion: push, schemas & validation, HTTP
service, local daemon, change data capture • Streaming Joins: indexing, lookup tables, map-joins, retry queue, batch re-driver sid@flipkart.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}