de temps de calcul • Des technos agiles “in-memory” comme python ou R • Pas de technos distribuées comme Spark, Beam, Hadoop… • Pas d’infrastructures (à pars un macbook ou datalab)
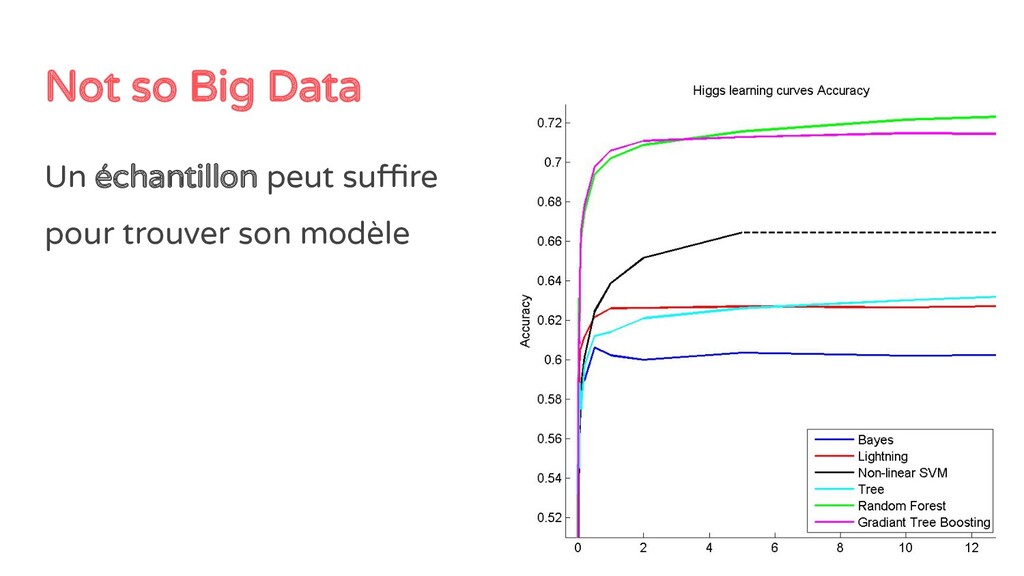
de projet, chercher 80% de la performance • Chaque problème de machine learning a son équilibre : pour 1% de précision en plus, combien de temps projet, et combien d’euros à la clef?
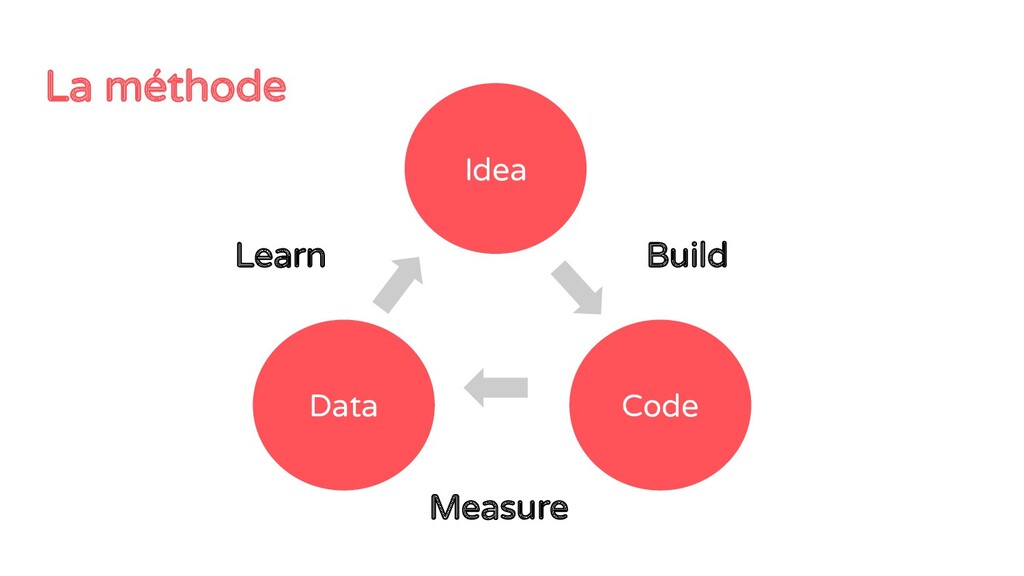
un modèle simple sur un échantillon et avec cross-val solide 2. Mettre en place la stack d'entraînement et de prédiction avec intégration continue et des technos simples (SQL, batch, in-mem, cloud) 3. Mettre en place la méthode d’analyse des résultats (dashboards…) 4. Pusher un modèles simple (python ou la moyenne en SQL) 5. Essayer de le battre avec des itérations courtes 6. S'arrêter quand on a assez gagné (pareto)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Je recherche un (lean) data engineer! [email protected] linkedin.com/in/simonmaby/](https://files.speakerdeck.com/presentations/7da47eae38e14b21ade6dbf05af05311/slide_21.jpg){kind=link}