presentation of the algorithm • From mllib to courbospark 3. PERFORMANCES • Configuration (cluster description, spark config…) 4. FEEDBACK ON SPARK/MLLIB
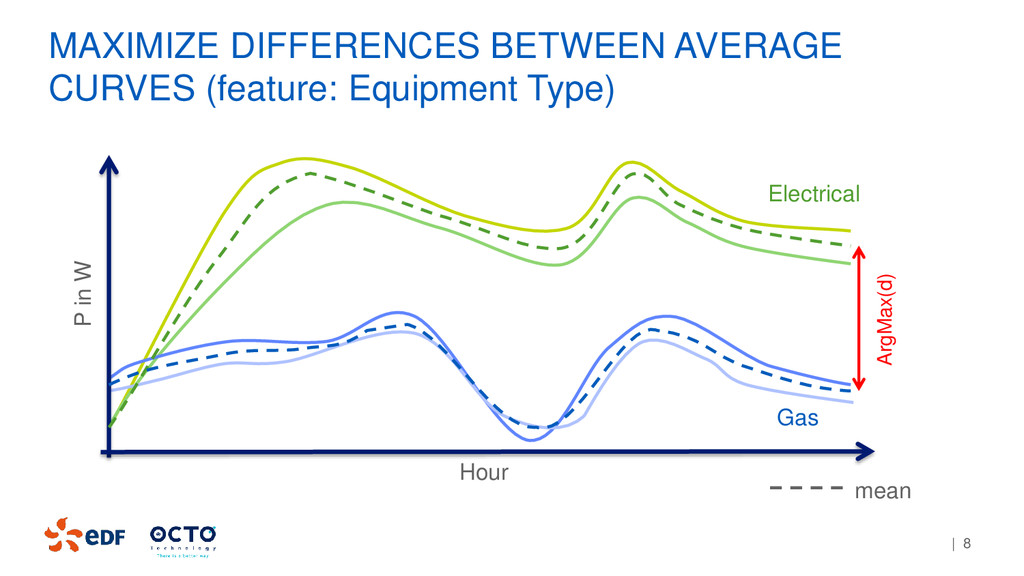
an explanatory feature How to split? we can either: • Minimize curves dispersion (intra inertia) or • Maximize differences between average curves (inter inertia) SPLIT CRITERIA: INERTIA
in Spark MLLib Manish Amde (Origami Logic), Hirakendu Das (Yahoo! Inc.), Evan Sparks (UC Berkeley), Ameet Talwalkar (UC Berkeley). Spark Summit 2014. http://spark-summit.org/wp- content/uploads/2014/07/Scalable-Distributed-Decision-Trees-in-Spark-Made-Das-Sparks-Talwalkar.pdf A MapReduce Implementation of C4.5 Decision Tree Algorithm Wei Dai, Wei Ji. International Journal of Database Theory and Application. Vol. 7, No. 1, 2014, pages 49- 60. http://www.chinacloud.cn/upload/2014-03/14031920373451.pdf PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce Biswanath Panda, Joshua S. Herbach, Sugato Basu, Roberto J. Bayardo. VLDB 2009. http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/36296.pdf Distributed Decision Tree Learning for Mining Big Data Streams Arinto Murdopo, Master thesis, Yahoo ! Labs Barcelona, July 2013. http://people.ac.upc.edu/leandro/emdc/arinto-emdc-thesis.pdf
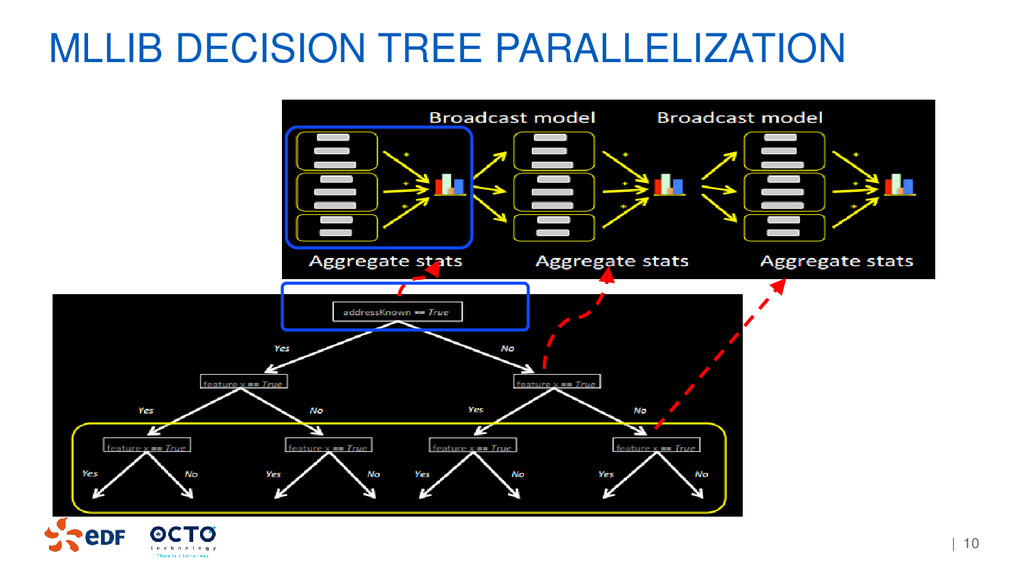
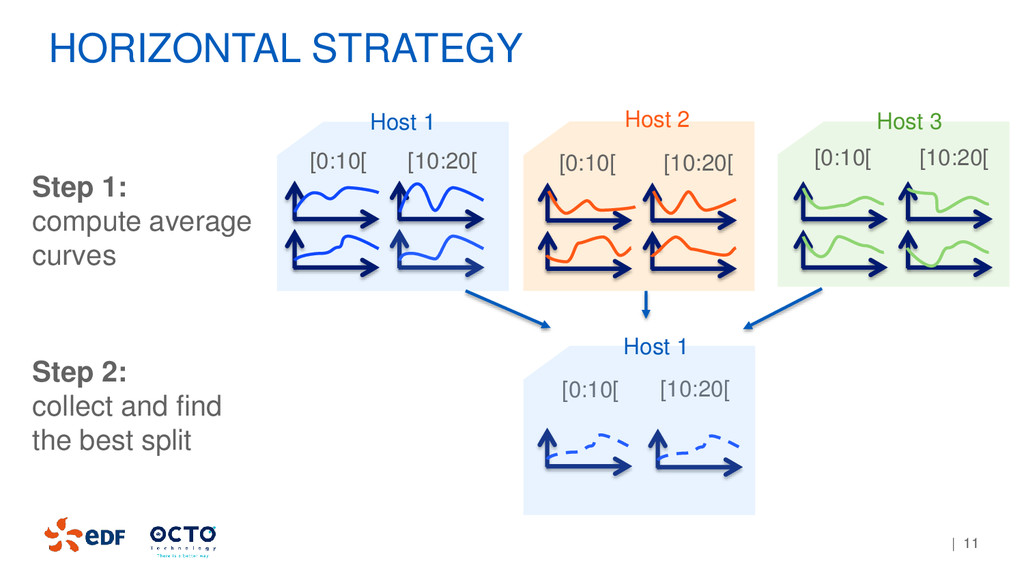
variance, inertia (to compare time-series) • Data structure: LabelPoint, TimeSeries • Finding split point for nominal features For data visualization of the tree: • Quantile on the nodes and leaves • Lost of inertia • Number of curves per nodes, leaves FROM MLLIB TO COURBOSPARK
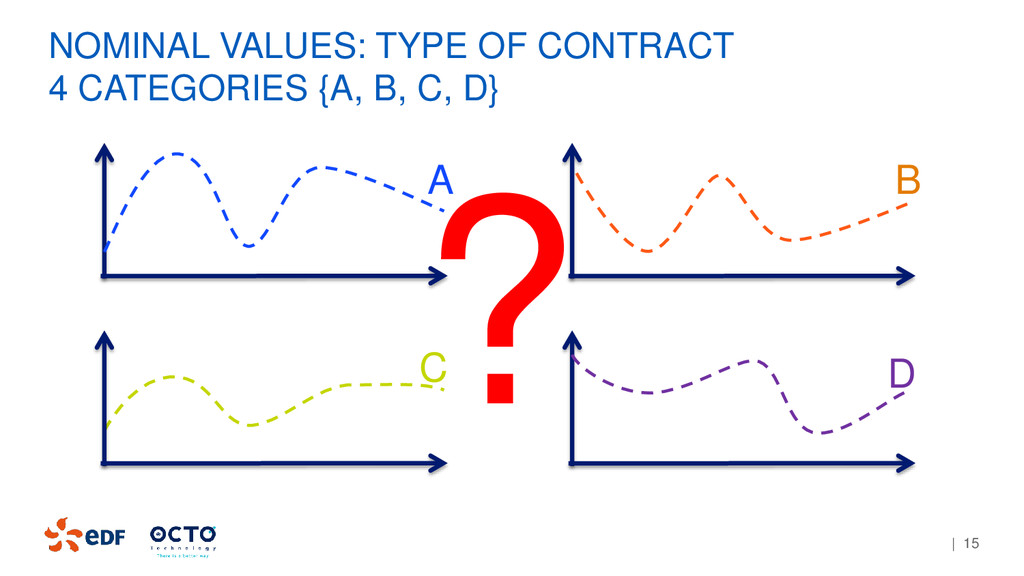
Solution 1: Compare curves 2 by 2 {A}/{BCD}, {AB}/{CD}, {ABC}/{D}, {AC}/{BD}… Problem: Combinatory problem depending on n the number of different categories. Complexity is O(2n)
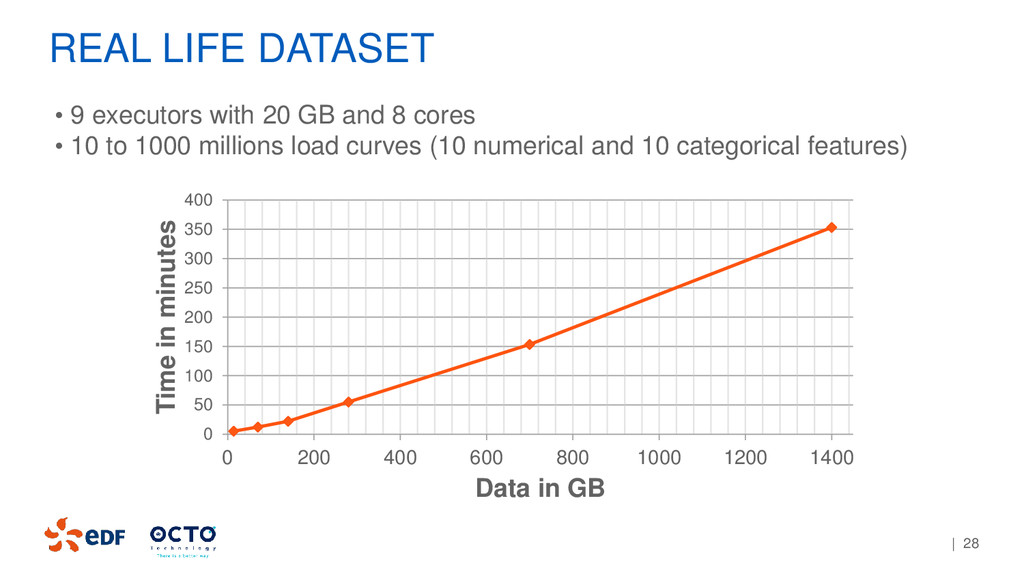
250 300 350 400 0 200 400 600 800 1000 1200 1400 Time in minutes Data in GB • 9 executors with 20 GB and 8 cores • 10 to 1000 millions load curves (10 numerical and 10 categorical features)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}