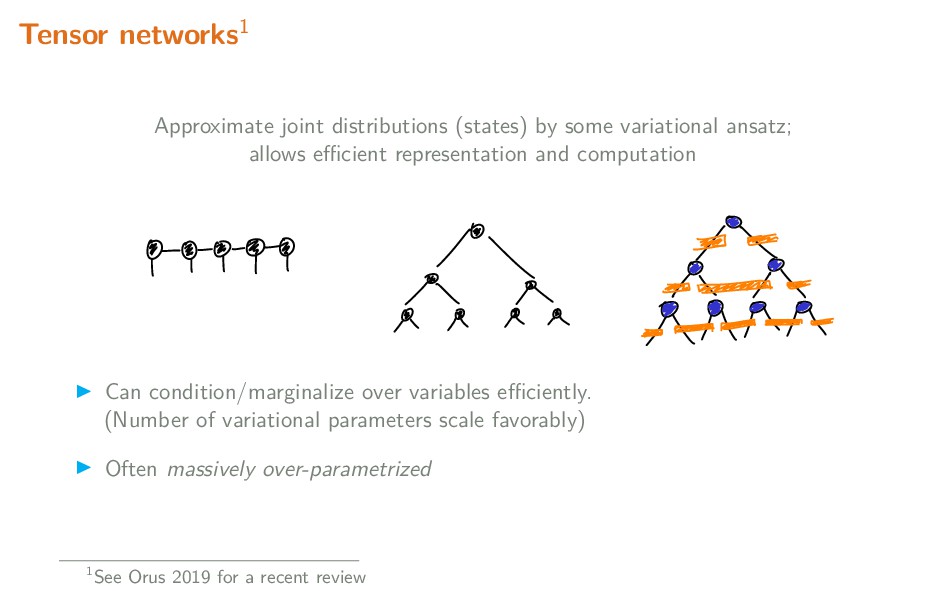
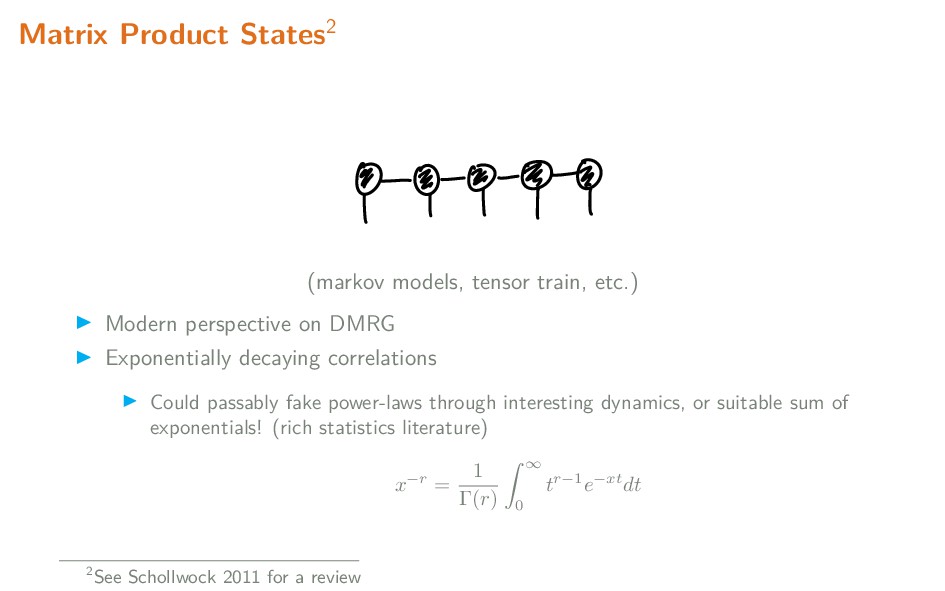
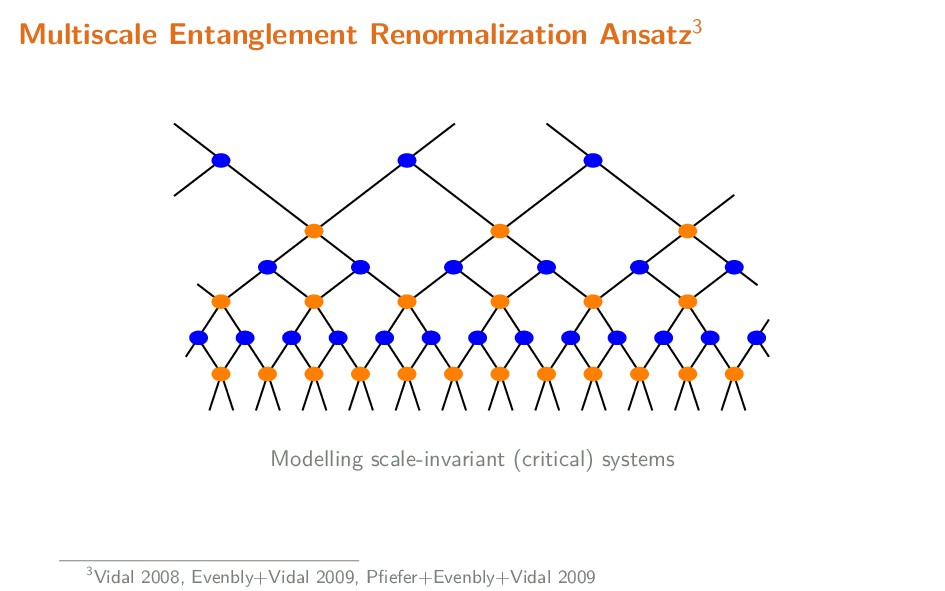
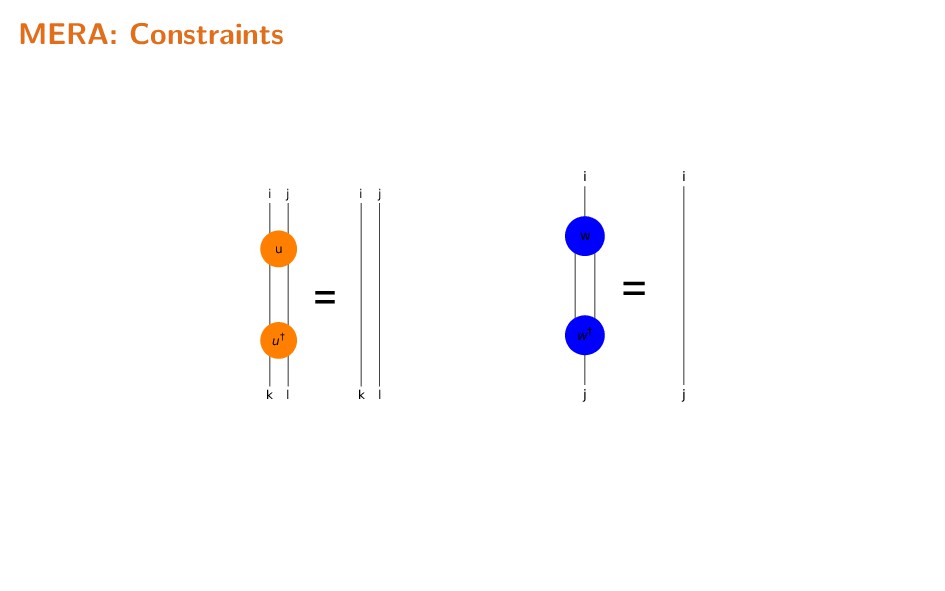
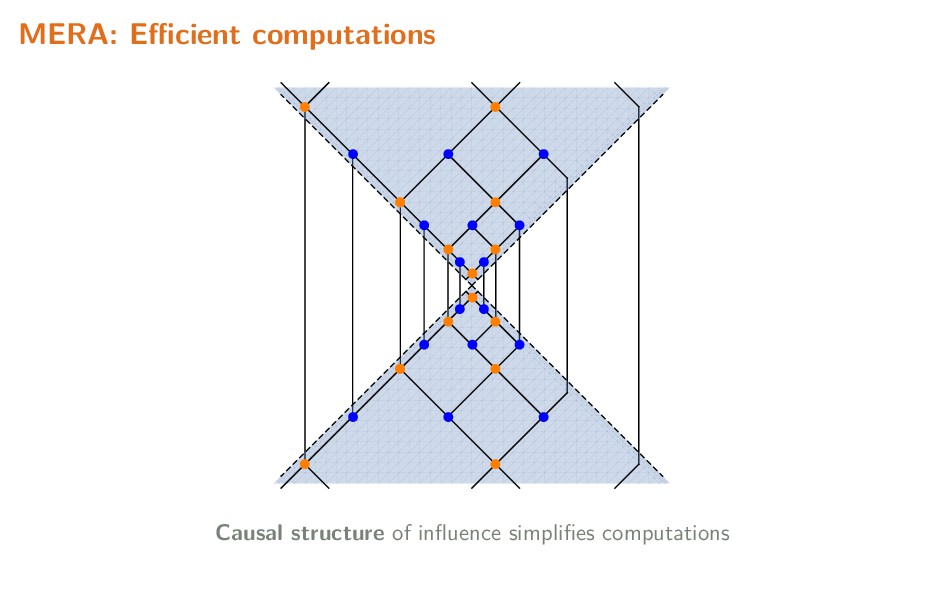
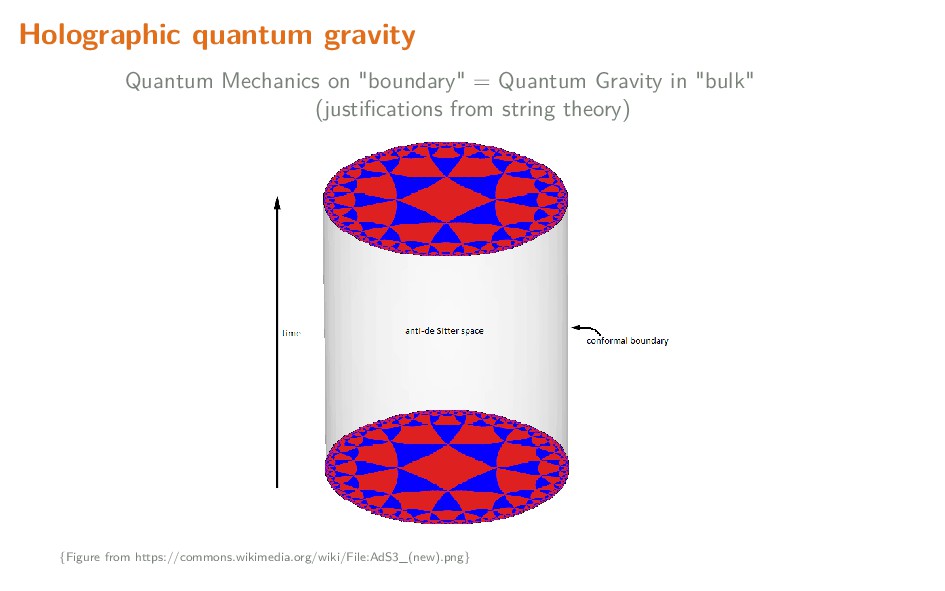
Tensor networks originated as a very useful tool to model states of quantum systems with many degrees of freedom (effectively equivalent to high-dimensional probability distributions). By exploiting the naturally sparse entanglement structure, well-designed networks provide variational ansatzes conducive to efficiently modelling such states. Of particular importance are 'MERA' networks, in which information is organized hierarchically, in a manner comparable to feed-forward neural networks. In this talk, I briefly explain the motivation behind and usage of tensor networks, and summarize some applications of tensor networks, both in the physics context, and recent usage in the context of machine learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
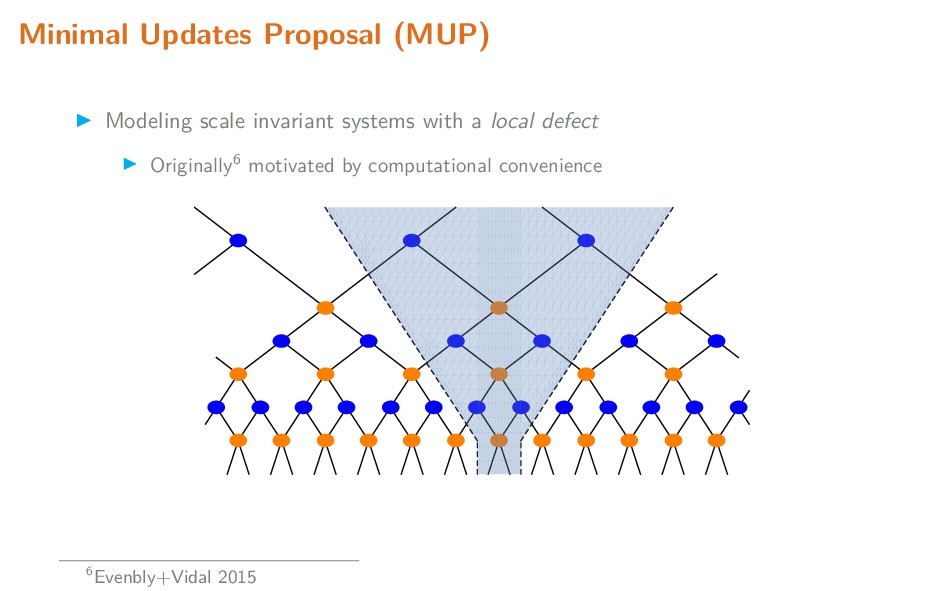{kind=link}
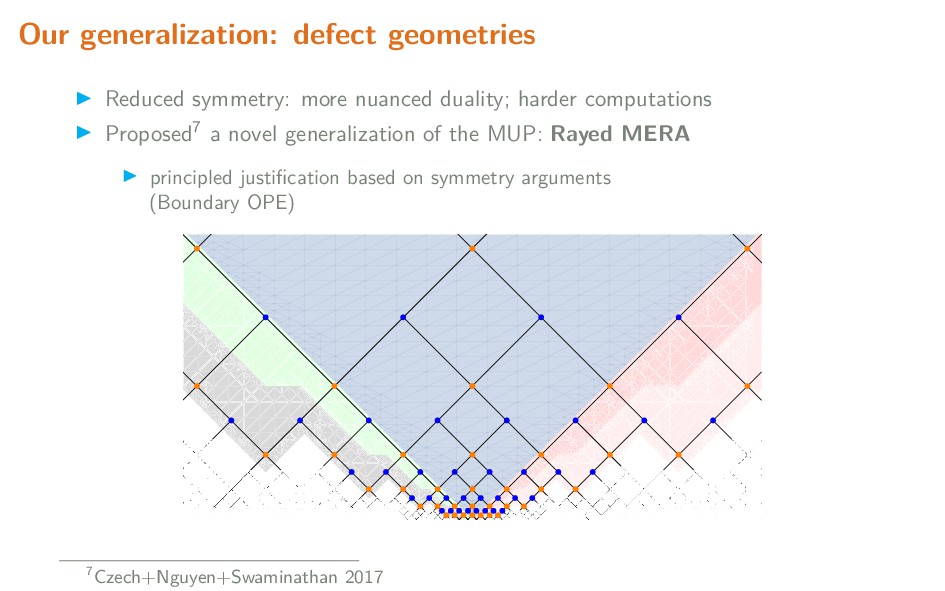{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
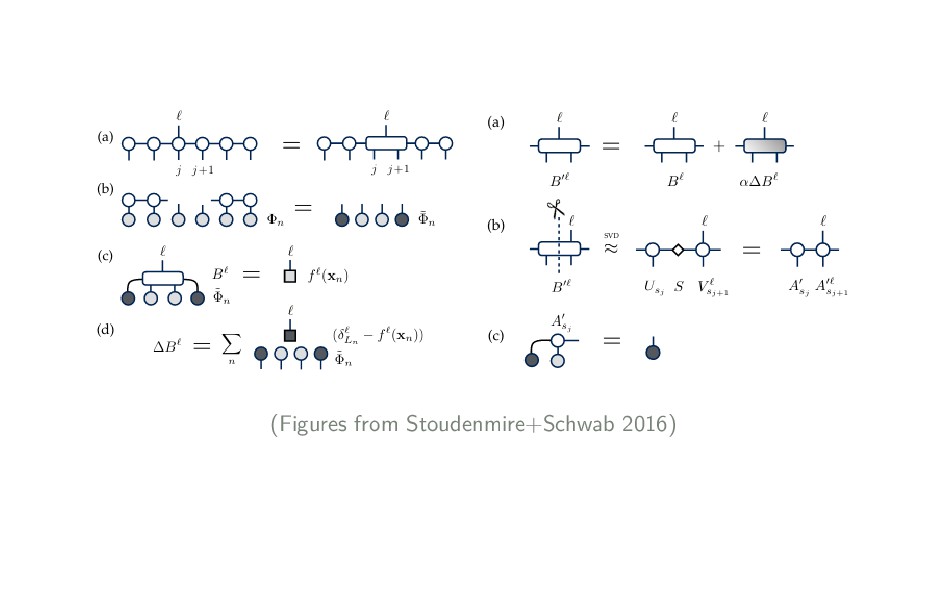{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}