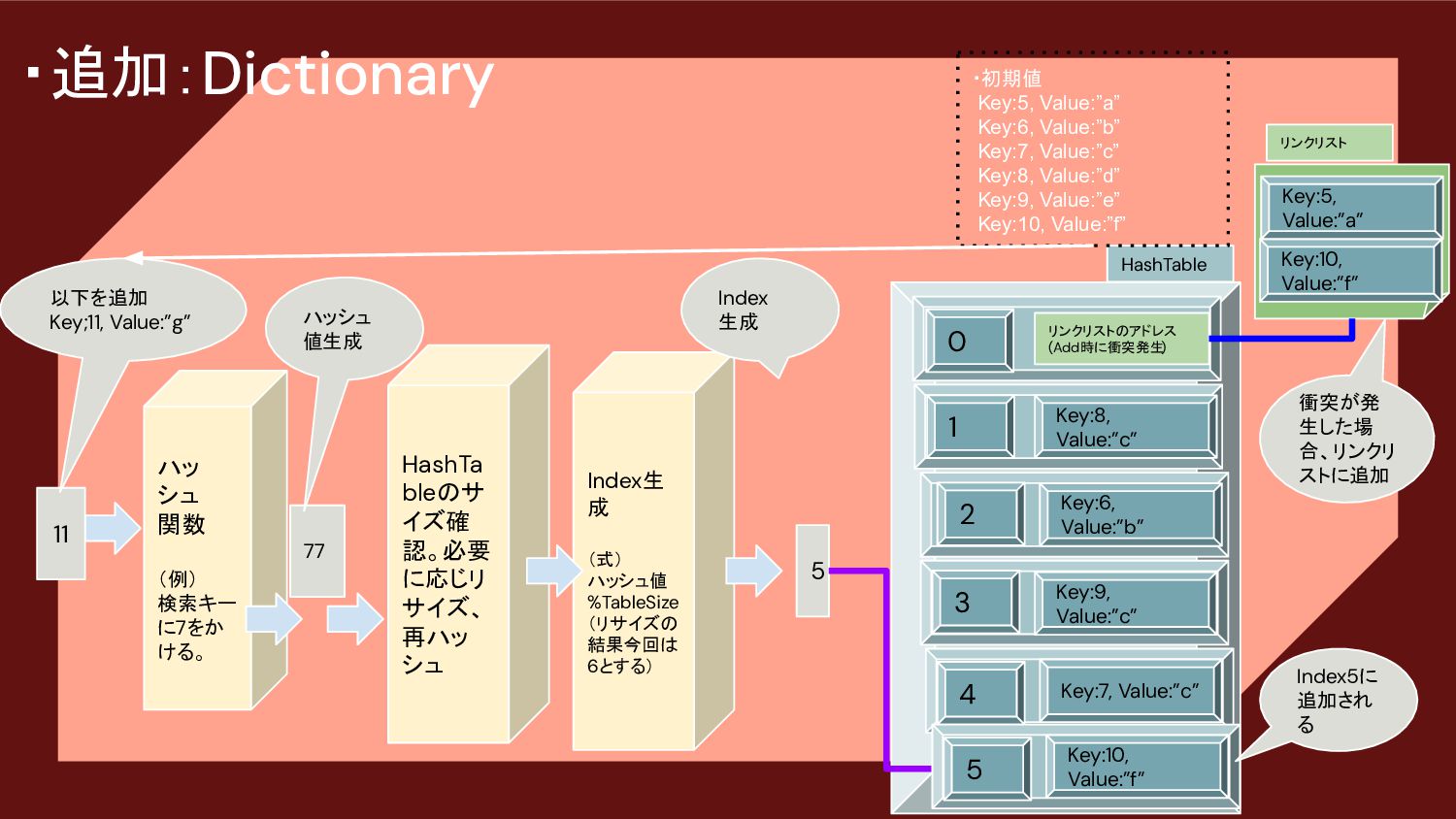
77 以下を追加 Key;11, Value:”g” Index生 成 (式) ハッシュ値 %TableSize (リサイズの 結果今回は 6とする) 5 Index 生成 HashTable ・初期値 Key:5, Value:”a” Key:6, Value:”b” Key:7, Value:”c” Key:8, Value:”d” Key:9, Value:”e” Key:10, Value:”f” 1 3 2 3 リンクリスト Key:6, Value:”b” Key:7, Value:”c” Key:8, Value:”c” Key:9, Value:”c” Key:10, Value:”f” リンクリストのアドレス (Add時に衝突発生 ) 0 Key:5, Value:”a” 4 HashTa bleのサ イズ確 認。必要 に応じリ サイズ、 再ハッ シュ ハッシュ 値生成 Key:10, Value:”f” 5 Index5に 追加され る 衝突が発 生した場 合、リンクリ ストに追加
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
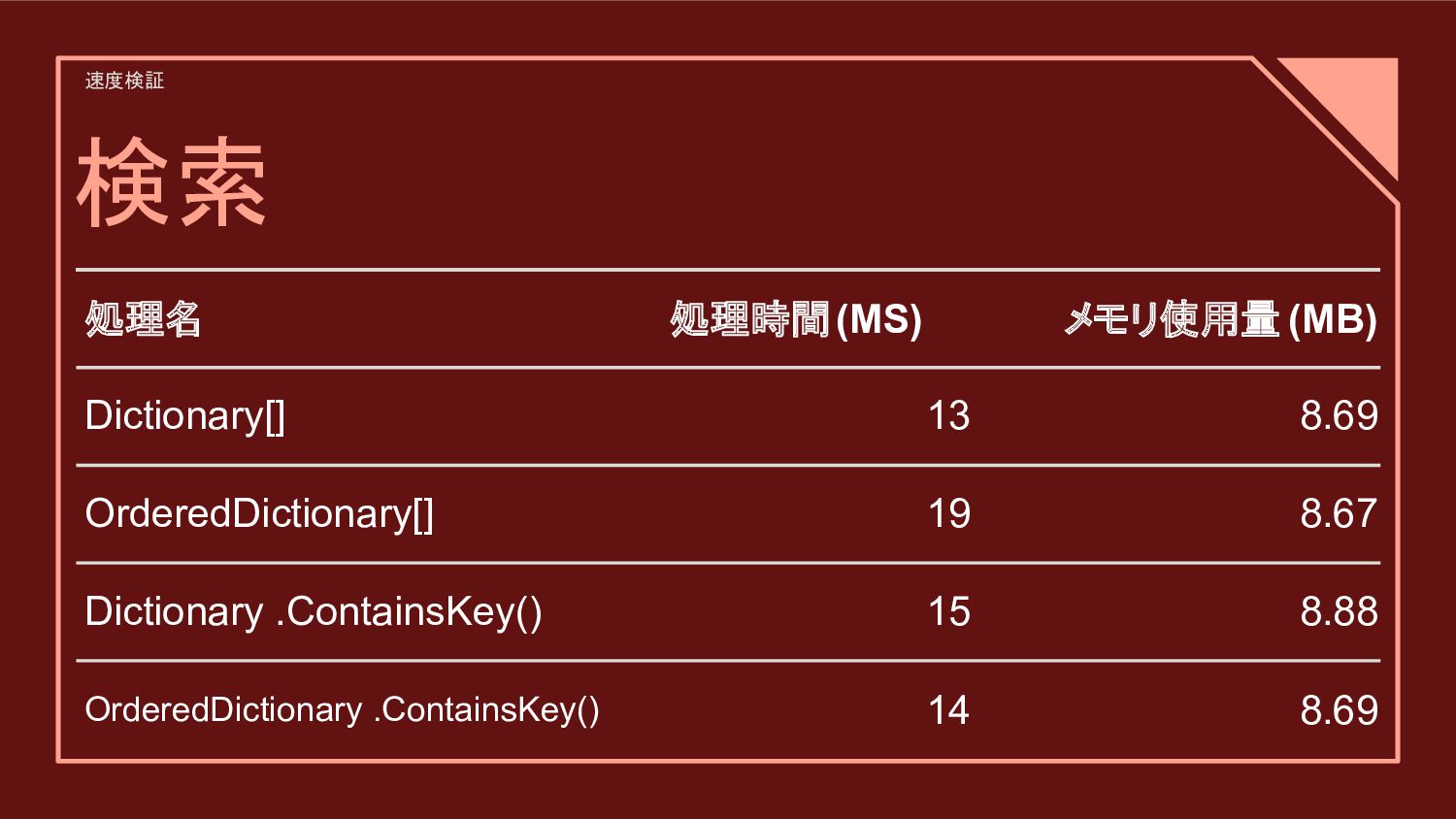
![検証対象(検索) • Dictionary[i] ◦ 説明: 指定したキーiをもとにハッシュ値を計算し、データを取得する辞書型のアクセス方法。 ◦ ポイント : 高速な検索が可能だが、衝突が起きた場合の処理が必要。](https://files.speakerdeck.com/presentations/16d121c499bd48838c8b53665e5aae77/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
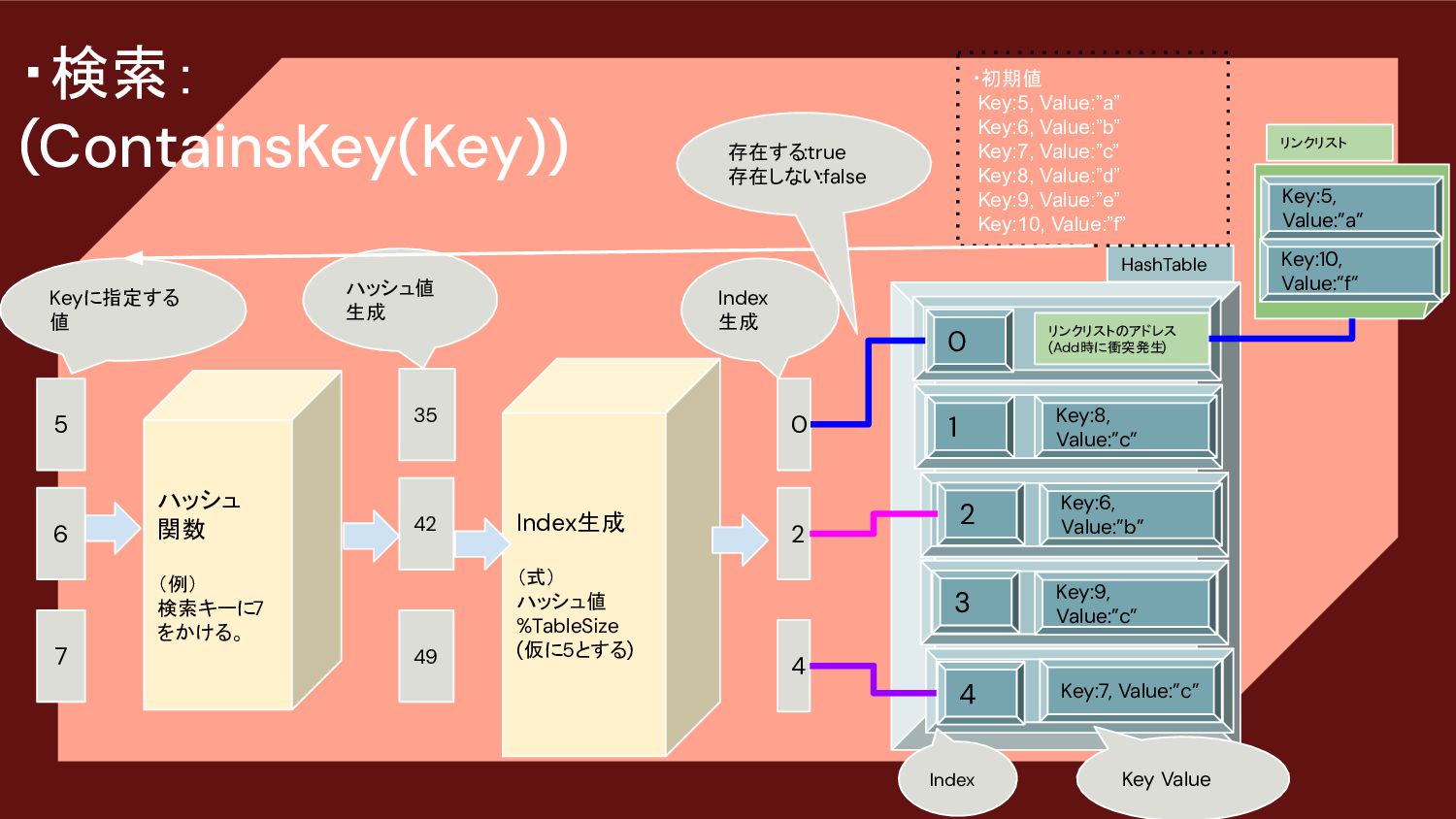
![・検索: (Dictionary[i]) 19 5 ハッシュ 関数 (例) 検索キーに7 をかける。 6](https://files.speakerdeck.com/presentations/16d121c499bd48838c8b53665e5aae77/slide_18.jpg){kind=link}
![・検索:(OrderedDictionary[i]) 20 1 2 3 [i]に指定 する値 ・初期値 [0] Key:5,](https://files.speakerdeck.com/presentations/16d121c499bd48838c8b53665e5aae77/slide_19.jpg){kind=link}
![OrderedDictionary[i] vs Dictionary[i] でOrderedDictionaryが遅い理由の考察 • OrderedDictionaryは、内部で「順序リスト」を保持し、 要素の検索時に順序リスト内を線形探索しています。 線形検索で見つけたインデックスを使用しハッシュテーブルを検索します。 そのため、要素数が増加するほど、 順序リストの特定のインデックスにアクセスする際の処理時間が増加します。](https://files.speakerdeck.com/presentations/16d121c499bd48838c8b53665e5aae77/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}