spend more than 3% time 18 8.32% mdct_backward(int, float*) 4.18% mdct_unroll_lap(int, int, int, int, float*, float*, float const*, float const*, short*, int, int, int) 1.87% floor1_inverse2(vorbis_dsp_state*, vorbis_info_floor1*, int*, int*) 1.77% decode_map(codebook*, oggpack_buffer*, int*, int) 2.55% [kernel.kallsyms][+ffffffc000b81c44] 1.08% Bypass_I16_NChan(AkAudioBuffer*, AkAudioBuffer*, unsigned int, AkInternalPitchState*) 0.87% __memcpy_base_aligned 0.76% CAkMixer::MixChannelSIMD(float*, float*, float, float, unsigned int) 0.53% mapping_inverse(vorbis_dsp_state*, vorbis_info_mapping*) 0.52% void _Execute<AkLpfParamEval>(AkAudioBuffer*, AkBQFParams&,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
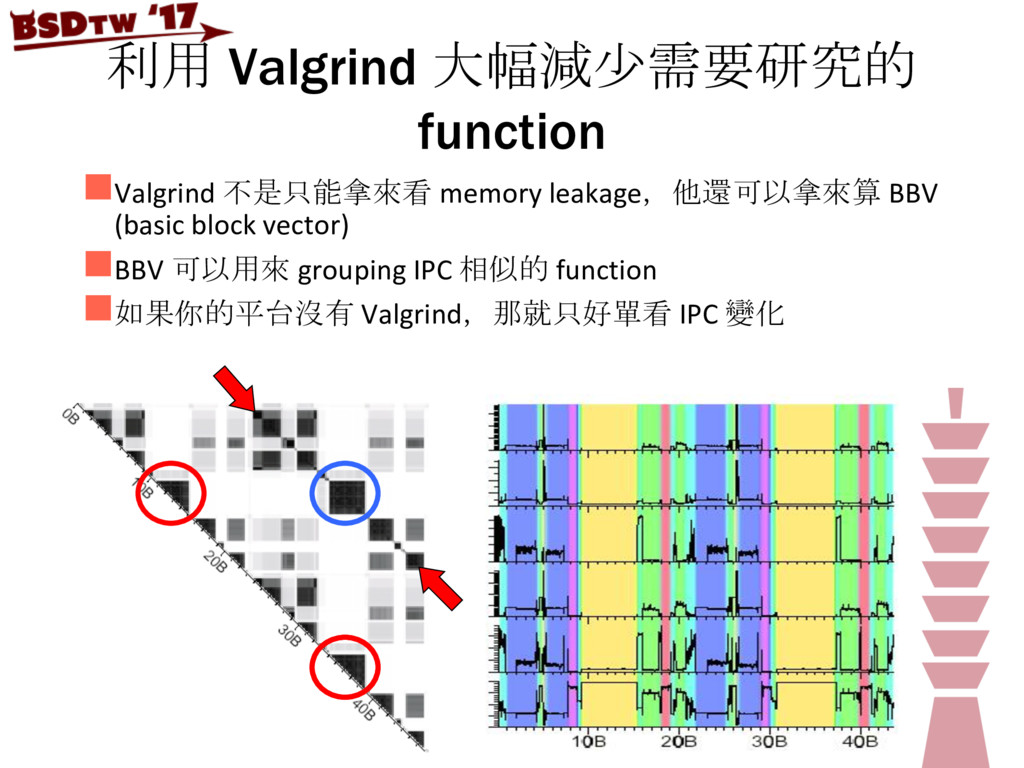{kind=link}
![利用 gcc -fdump-tree-all 來看優化統計 n重新編譯一次,可以利用 evaluate 來增加 -fdump-tree-all 統計項目 n[檔名].[順序].[優化名稱]](https://files.speakerdeck.com/presentations/40816464f748481b8c3daad33c533f1d/slide_22.jpg){kind=link}
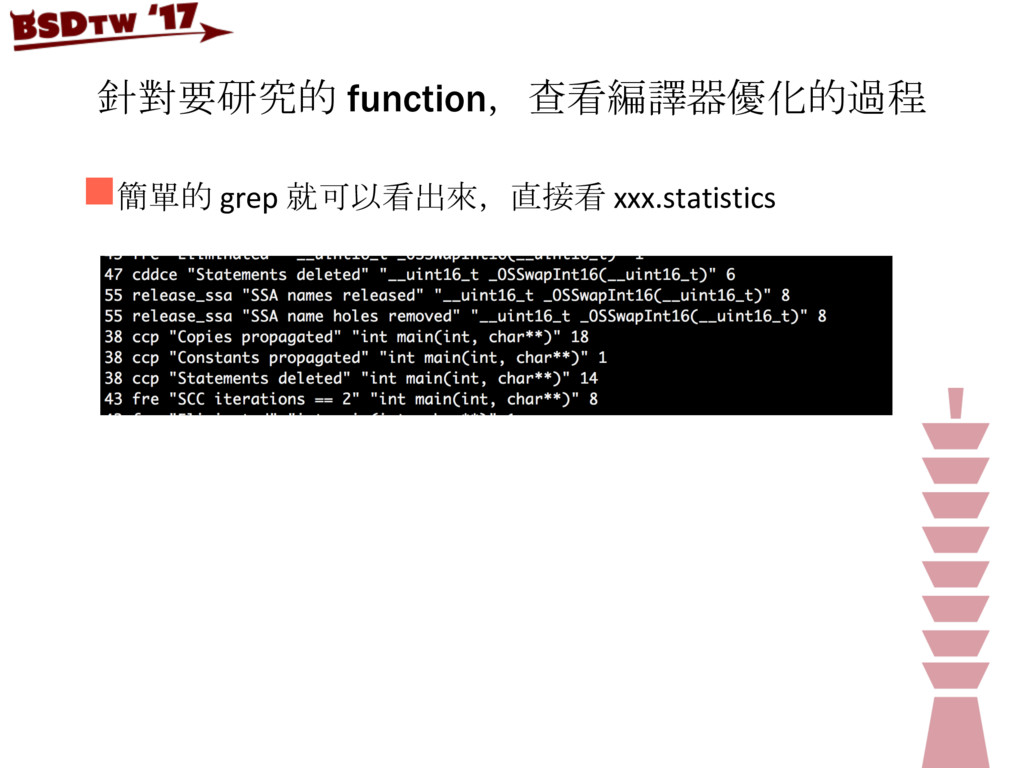{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}