I describe the different problems that we can find in variables in a dataset, how they affect the different machine learning models, and which techniques we can use to overcome them.
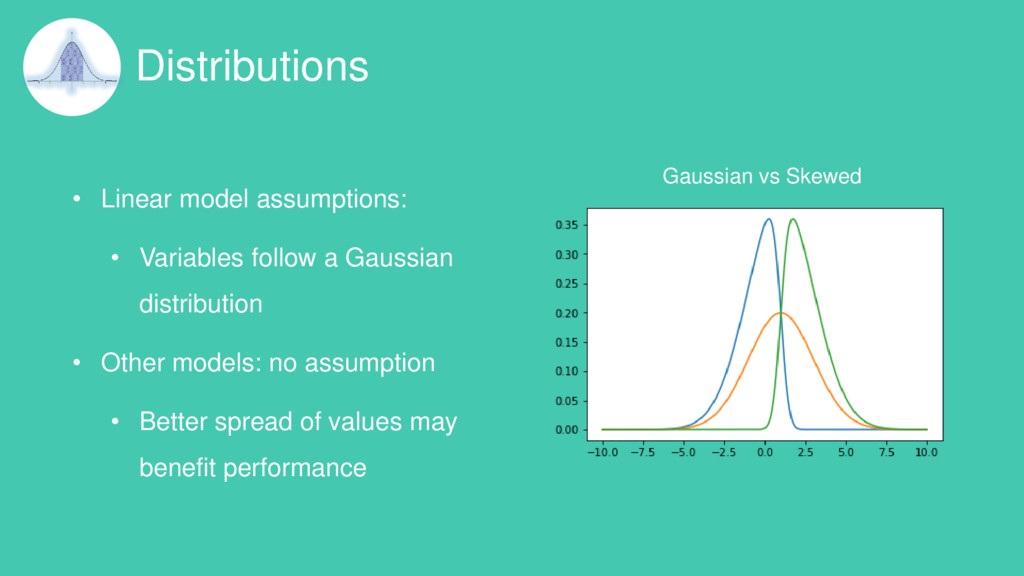
the magnitude of the feature: • Linear and Logistic Regression • Neural Networks • Support Vector Machines • KNN • K-means clustering • Linear Discriminant Analysis (LDA) • Principal Component Analysis (PCA) Machine learning models insensitive to feature magnitude are the ones based on Trees: • Classification and Regression Trees • Random Forests • Gradient Boosted Trees
sample Arbitrary number End of distribution NA indicator • May remove a big chunk of dataset • Alters distribution • Element of randomness • Still need to fill in the NA • Alters distribution
Ordinal encoding Weight of evidence • Expands the feature space • Account for zero values as it uses logarithm • No monotonic relationship • Prone to overfitting
worldwide for feature transformation, learnt from Kaggle and the KDD competition websites, white papers, different blogs and forums, and from my experience as a Data Scientist. To provide a source of reference for data scientists, where they can learn and re-visit the techniques and code needed to modify variables prior to use in Machine Learning algorithms. DSCOACH2018 (discount voucher)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}