Sony Our Projects Dragon Age: Inquisition FIFA 14 SIMS 4 Mass Effect 2 League of Legends Grand Theft Auto V About us Our Office Locations USA Poland Russia The Facts Founded in 2004 300+ employees Sperasoft on-line sperasoft.com linkedin.com/company/sperasoft twitter.com/sperasoft facebook.com/sperasoft
generation • Fixed on consoles • Improved algorithm • Very important • Hardware-aware optimization • Optimizing for (limited) range of hardware • Microoptimizations for specific architecture!
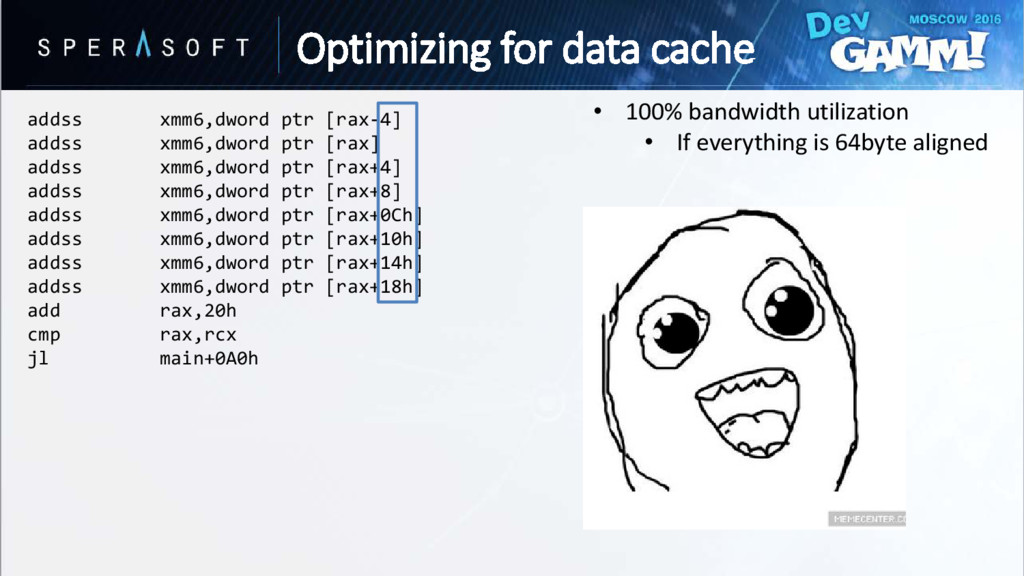
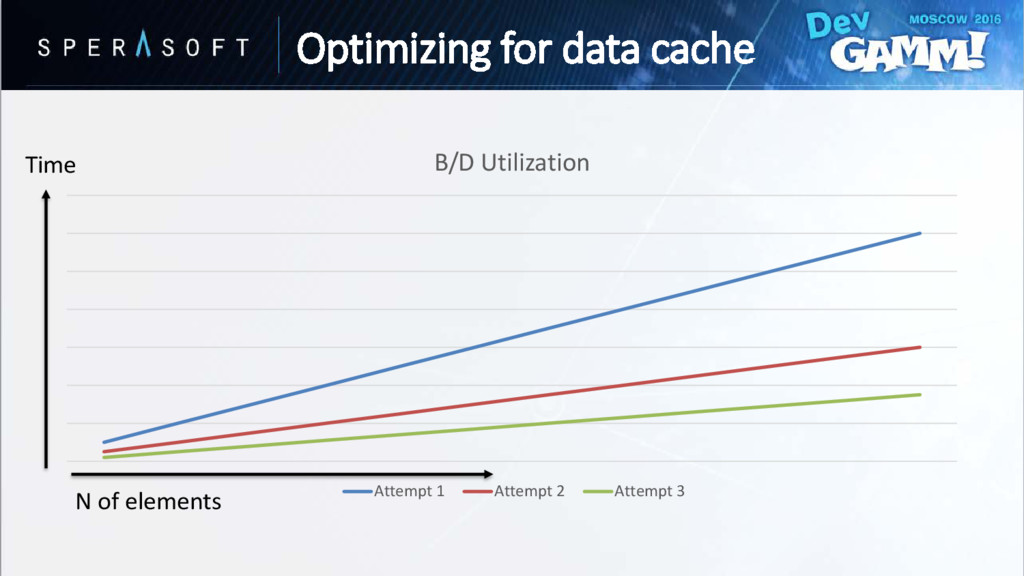
to help hardware prefetching • Processor recognizes pattern and preload data for next iterations beforehand Vec4D in[SIZE]; // Offset from origin float ChebyshevDist[SIZE]; // Chebyshev distance from origin for (auto i = 0; i < SIZE; ++i) { ChebyshevDist[i] = Max(in[i].x, in[i].y, in[i].z, in[i].w); } Optimizing for data cache
every cache miss will pollute a cache • Prefetching cannot happen across page boundaries • Might trigger invalid page table walk (on TLB miss) Optimizing for data cache
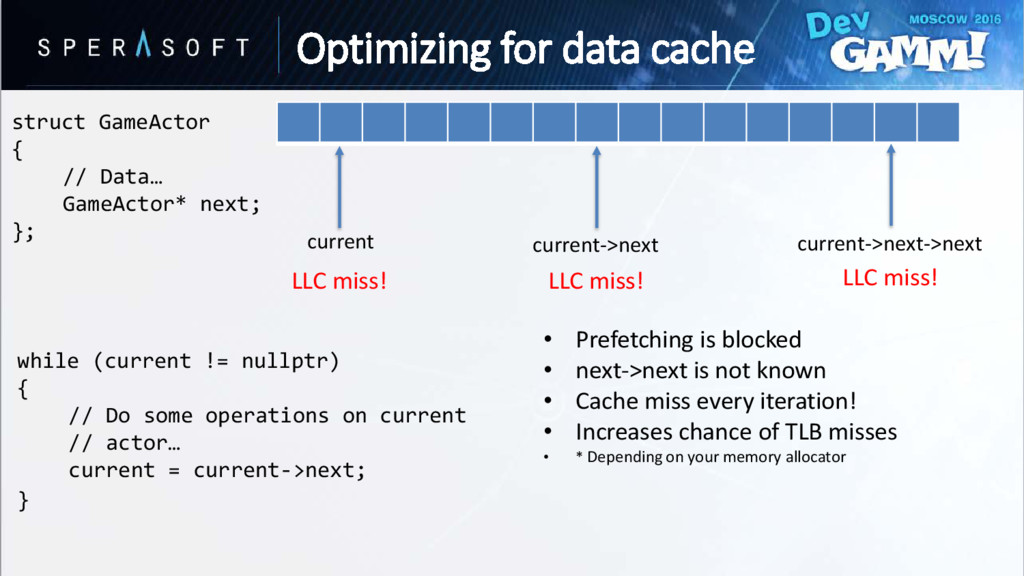
Cache miss every iteration! • Increases chance of TLB misses • * Depending on your memory allocator current current->next->next current->next struct GameActor { // Data… GameActor* next; }; while (current != nullptr) { // Do some operations on current // actor… current = current->next; } LLC miss! LLC miss! LLC miss! Optimizing for data cache
completed • In case of exception such as page fault software prefetch retired without prefetching any data e.g. Intel guide on prefetch instructions: • Load from memory != prefetch instructions • Prefetch instructions may differ depending on H/W vendor Optimizing for data cache
time enough • Remember LLC miss ~ 200c vs trivial ALUs ~ 3-4c while (current != nullptr) { Prefetch(current->next) // Trivial ALU computations on current actor current = current->next; } Optimizing for data cache
Prefetch near enough so it’s not evicted from data cache • Do NOT overprefetch • Prefetching is not free • Polluting cache • Always profile when using software prefetching Optimizing for data cache
every character… // Assume we have array<FooBonus> structs; float Sum{0.0f}; for (auto i = 0; i < SIZE; ++i) { Actor->Total += FooArray[i].fooBonus; } Example of poor data layout: Optimizing for data cache
cold fields? • Make use of Structure of Arrays • Store and index different arrays struct FooBonus { float fooBonus; }; struct MiscData { float otherData[15]; }; Optimizing for data cache
and how it’s used • Include logging to getters/setters • Collect any other useful data (time/counters) float GameCharacter::GetStamina() const { // Active only in debug build CollectData(“GameCharacter::Stamina”); return Stamina; } Optimizing for data cache
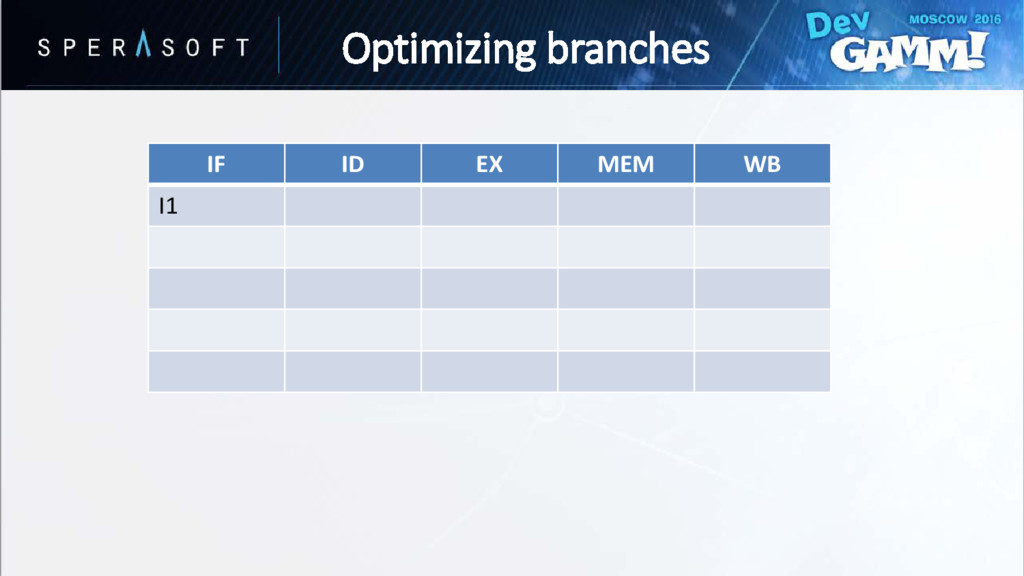
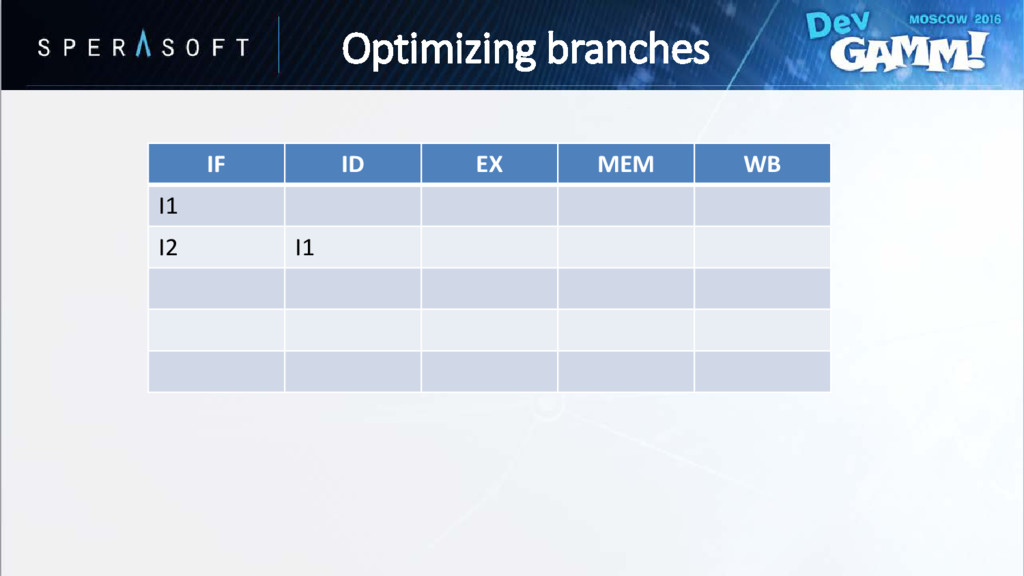
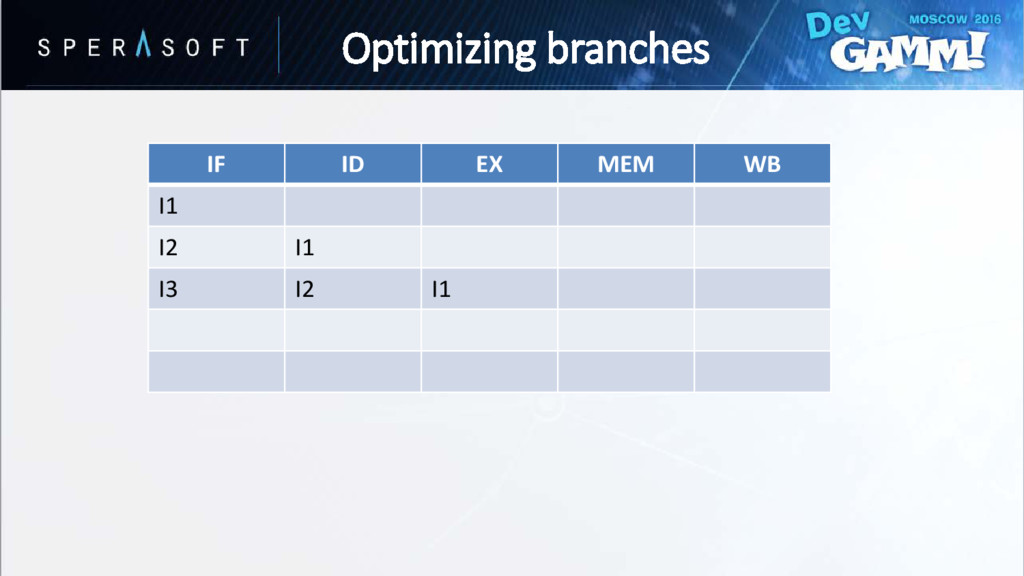
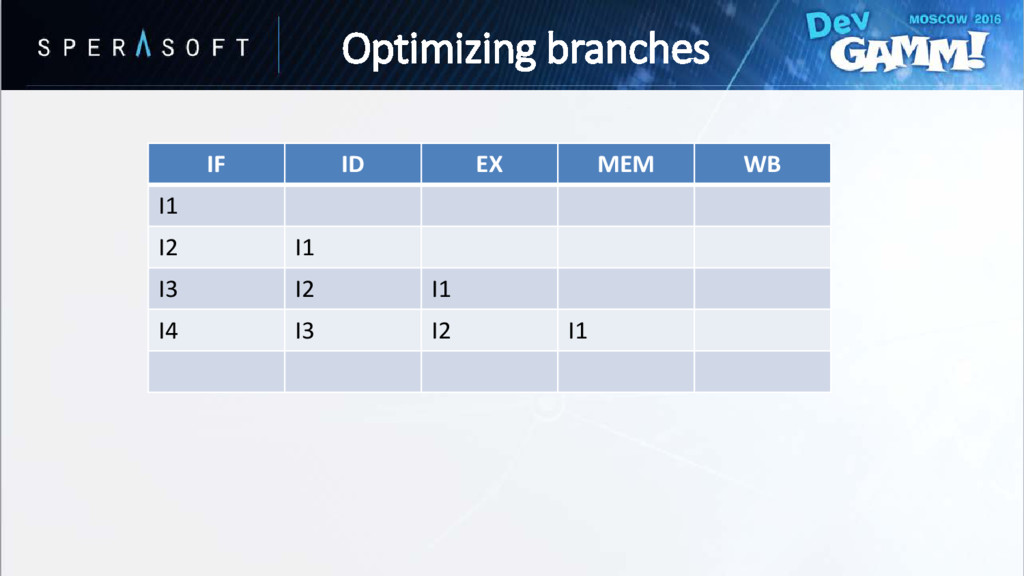
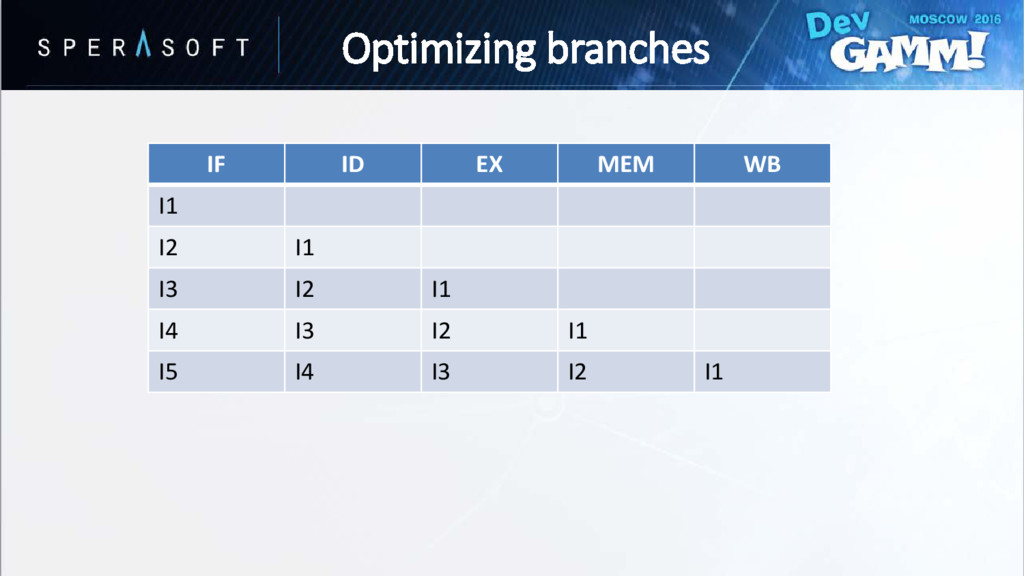
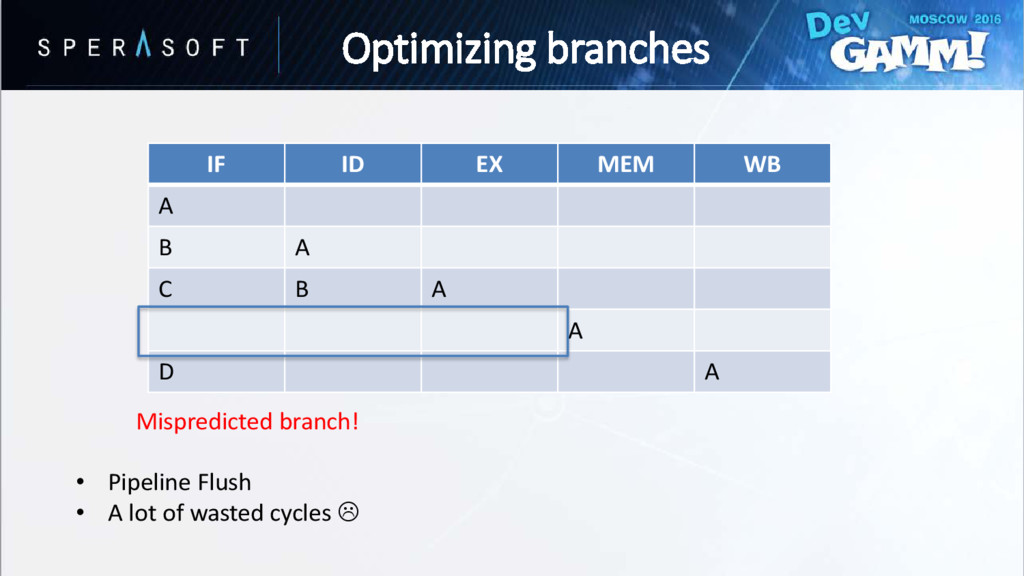
hasn’t been evaluated yet • Processor speculatively chooses one of the paths • Wrong guess is called branch misprediction // Instruction A if (Condition == true) { // Instruction B // Instruction C } else { // Instruction D // Instruction E } Optimizing branches
int In; int Out; bool bDontNegate; r = (bDontNegate ^ (bDontNegate– 1)) * v; int In; int Out; bool bDontNegate; Out = In; if (bDontNegate == false) { out *= -1; } Branchy version: Branchless version: https://graphics.stanford.edu/~seander/bithacks.html Optimizing branches
Obviously have to compute both results • Introduces data-dependency blocking out-of- order execution • Profile! Compute both summary: Optimizing branches
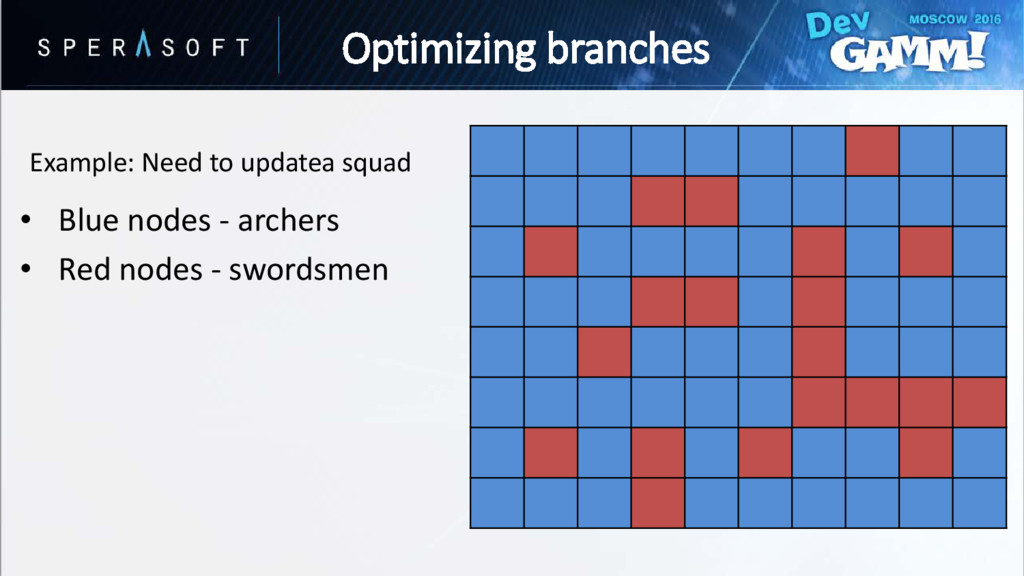
}; struct Squad { CombatActor Archers[A_SIZE]; CombatActor Swordsmen[S_SIZE]; }; void UpdateArchers(const Squad & squad) { // Just iterate and process, no branching here // Update archers } • Split! And process separately • No branching in processing methods • + Better utilization of I-cache! void UpdateSwordsmen(const Squad & squad) { // Just iterate and process, no branching here // Update swordsmen } Optimizing branches
; set of some ALU instructions… ;… END: ; function epilogue ; function prologue cmp dword ptr [data], 0 jne COMP jmp END COMP: ; set of some ALU instructions… ;… END: ; function epilogue • Imagine cmp dword ptr [data], 0 – likely to evaluate to “false” • Prefer predicted not taken Predicted not taken Predicted taken Optimizing branches
you really need a branch • Compute both results • Bit/Math hacks • Study the data and split it • Based on access patterns • Based on performed computation Optimizing branches
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![struct FooBonus { float fooBonus; float otherData[15]; }; // For](https://files.speakerdeck.com/presentations/90e93659d5ad4fc2926b7a997bb43847/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![; function prologue cmp dword ptr [data], 0 je END](https://files.speakerdeck.com/presentations/90e93659d5ad4fc2926b7a997bb43847/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? • E-mail: [email protected] • Twitter: @EvgenyGD • Web: evgenymuralev.com](https://files.speakerdeck.com/presentations/90e93659d5ad4fc2926b7a997bb43847/slide_55.jpg){kind=link}
{kind=link}