SECR 2018
Полина Казакова
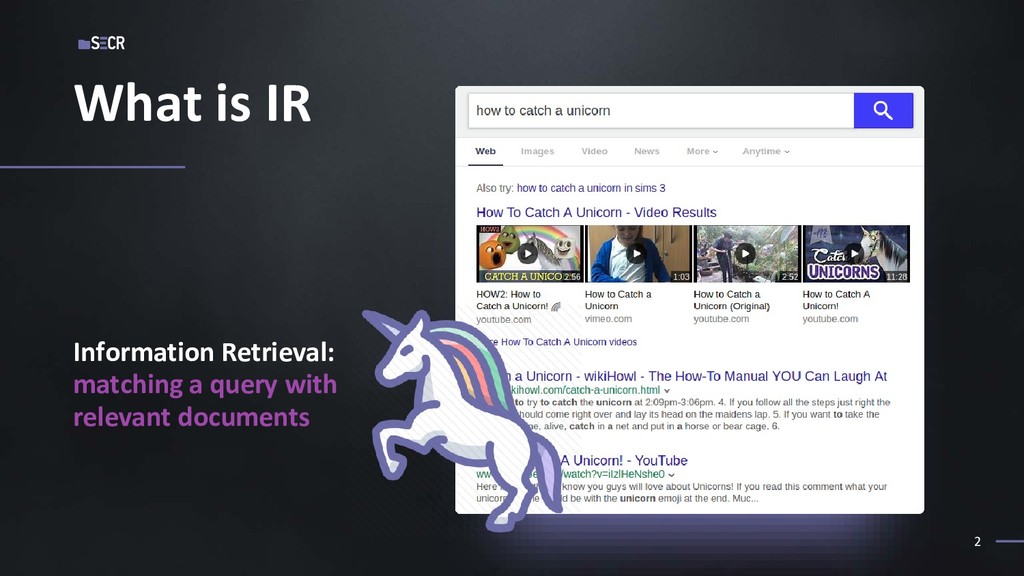
Интегрированные Системы
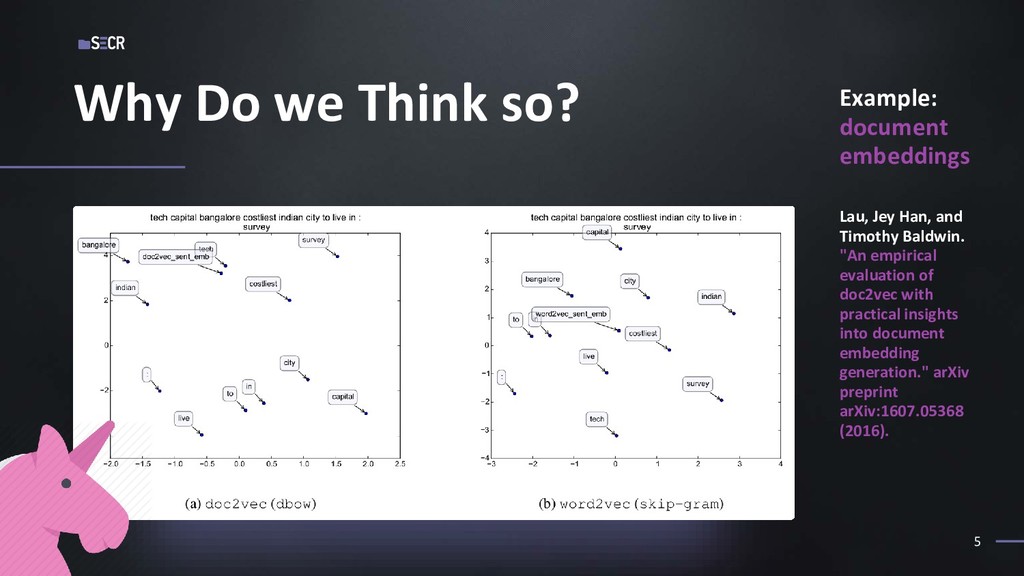
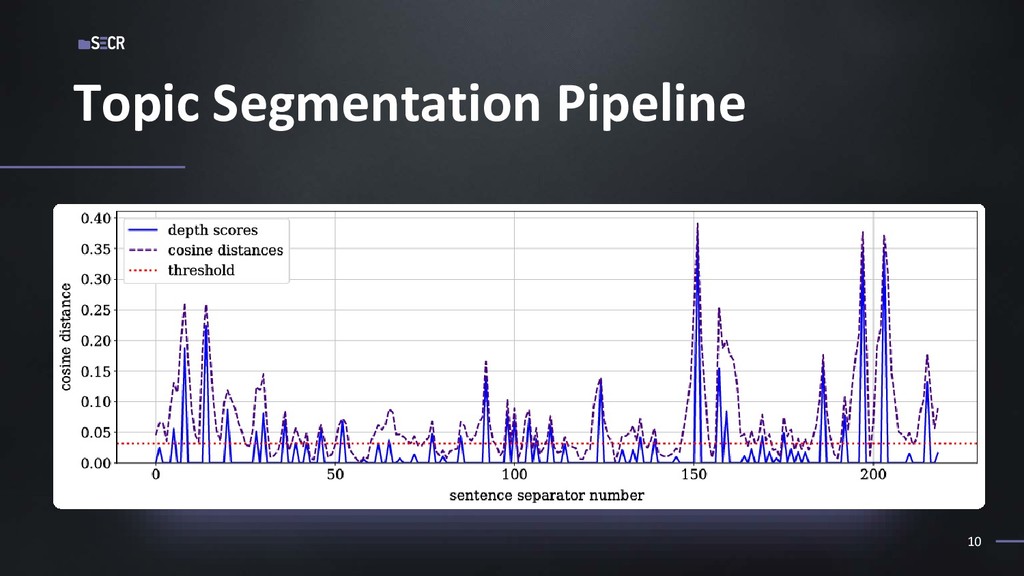
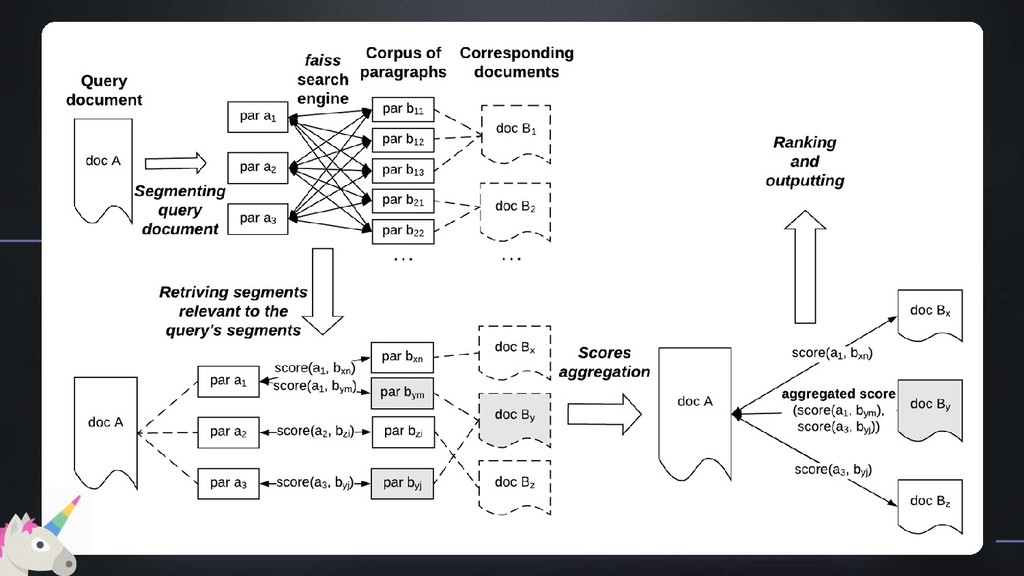
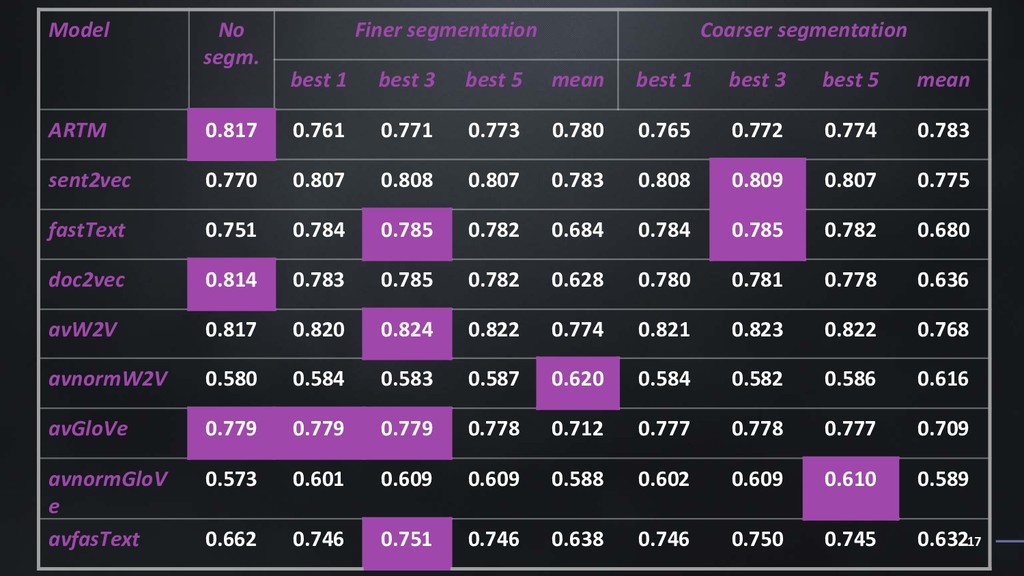
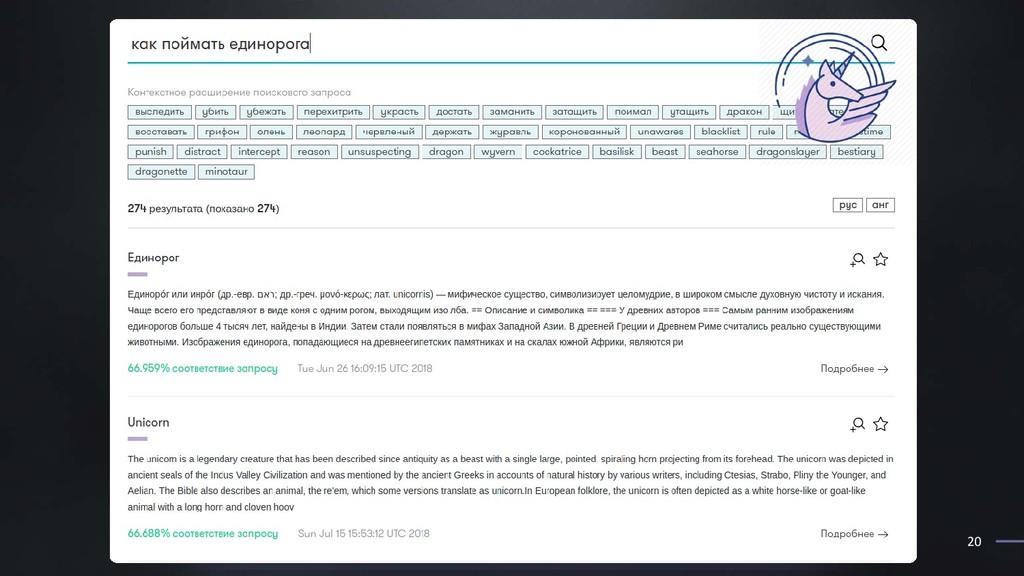
Наша работа посвящена применению текстовой сегментации в сфере информационного поиска. Мы исходим из предположения, что тематическая сегментация позволяет лучше моделировать структуру текста и, как следствие, язык сам по себе, что влияет на качество представления текста в векторном виде. Мы протестировали нашу гипотезу на датасете статей из arXiv и показали, что сегментация действительно в большинстве случаев улучшает качество поиска.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Based on ARTM Additive Regularization of Topic Models [2] (BigARTM](https://files.speakerdeck.com/presentations/2696d855e626401990600c300d011a09/slide_6.jpg){kind=link}
{kind=link}
![Part #2 / Topic Tiling [4] algorithm: ★ For each](https://files.speakerdeck.com/presentations/2696d855e626401990600c300d011a09/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}