SECR 2018
Иван Короткий
СПбГУ
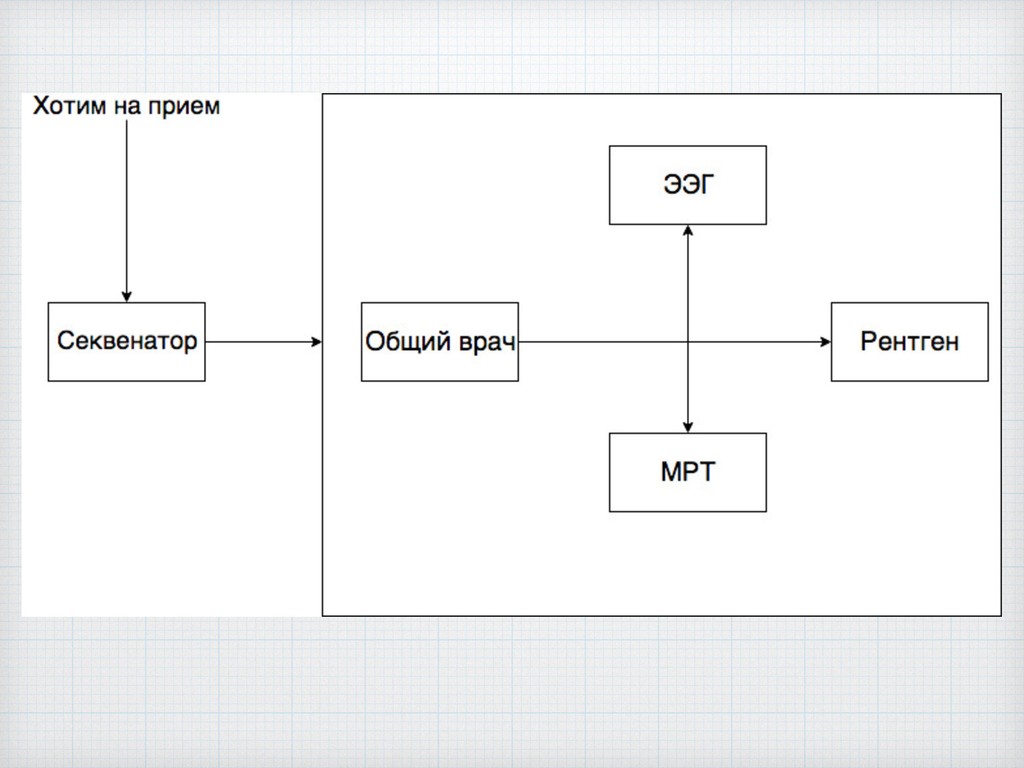
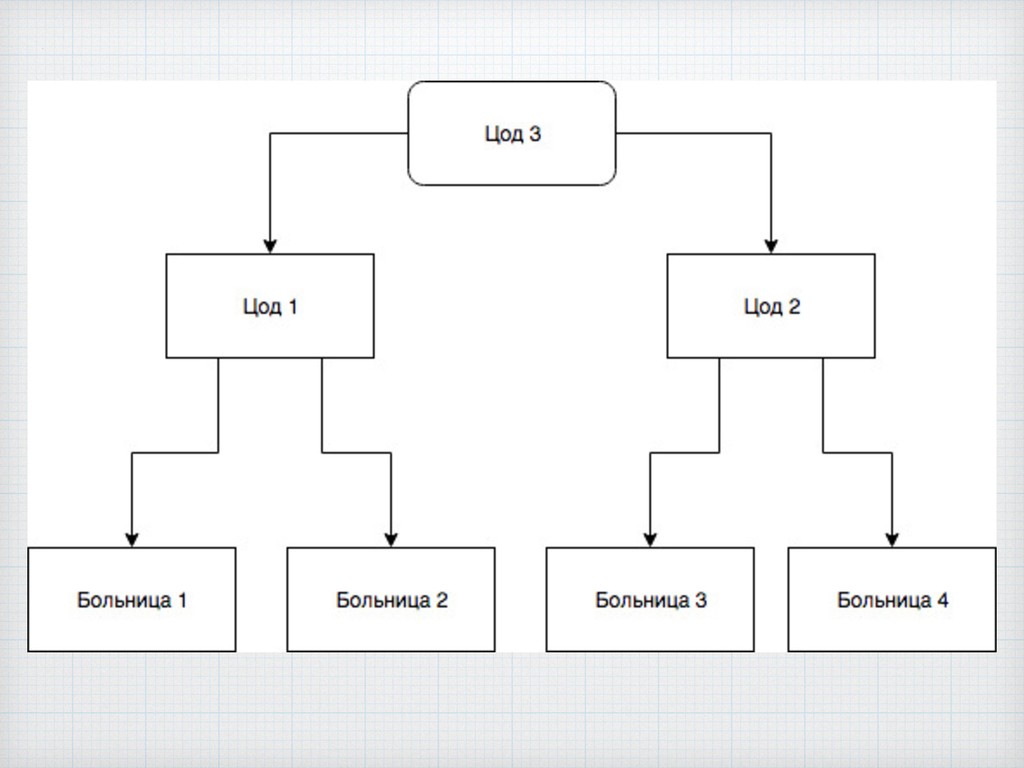
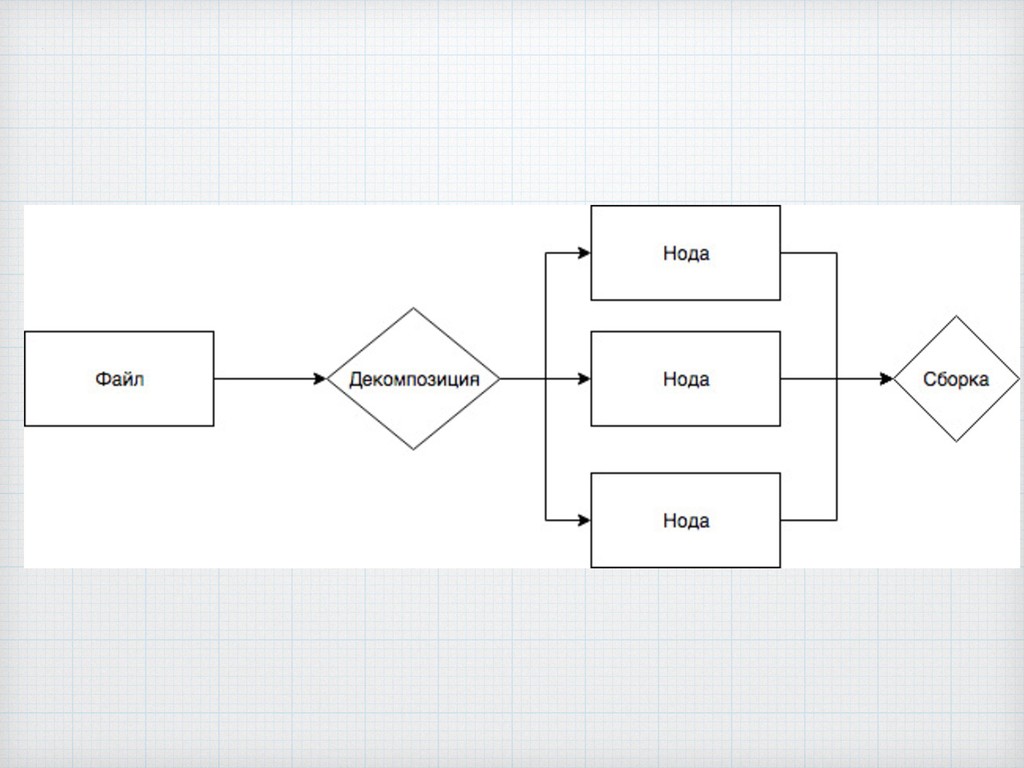
Биоинформатика находится в лидерах по масштабу используемых данных, среди её методов можно выделить секвенирование, которое широко используется в науке и медицине, а значит там существуют проблемы которые связаны с обработкой данных, которые в данный момент по классификации переходят в объём big data. Мы предлагаем использовать базы данных, в обработке биоинформатических данных из-за того, что никто не пытался их тут применить, а отрасль как раз переходит в то состояние где требуются подходы нового поколения.
В выступлении будет раскрыта ситуация в долгосрочной перспективе. Доклад не требует начальных знаний для посещения.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}