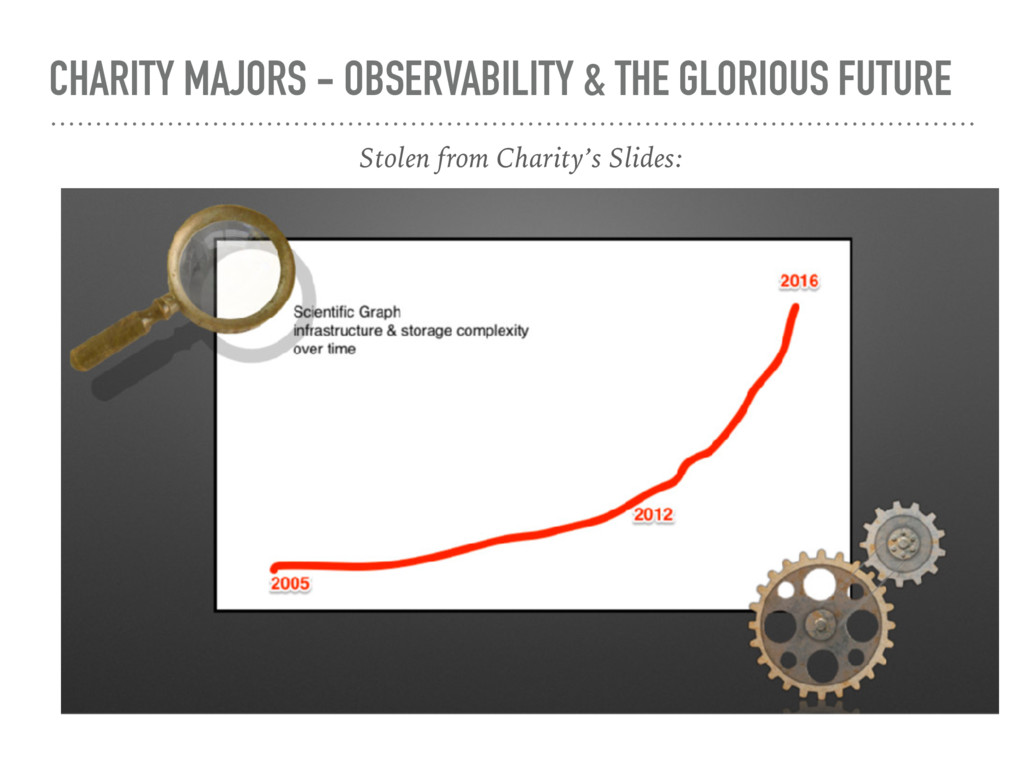
your systems is largely useless ➤ it sucks ➤ Observability is what you need ➤ build a system that you can understand ➤ Our systems have become so complex that the old system of 1000 dashboards can no longer cut it
we have are unreliable symptoms and reports ➤ We need a way to ask questions ➤ As soon as we know the question we usually know the answer too ➤ Modern web apps exist between the nodes ➤ Apps and microservices are so complex that we no longer know the QUESTION ➤ “Complexity is exploding everywhere, but our tools are designed for a predictable world”
photos are loading slowly ➤ LAMP stack edition ➤ App tier capacity exceeded ➤ Connections to DB are slower than normal ➤ ==> Connection timeout and latency to rise ➤ Microservices edition ➤ On one of our 50 micro services, one node is running on degraded hardware ➤ Photos loading fine, but Canadian users running an French language pack on one iPhone version are hitting a firmware condition making them unable to save local cache ➤ Our newest SDK makes additional DB queries if the developer has enabled an optional feature
are no more easy problems in the future, there are only hard problems (Duh…you fixed the easy ones)” ➤ Observability means being open-ended and exploratory ➤ Debug by asking questions, not by using muscle memory ➤ Stop debugging with your eyeballs ➤ Debug with data! ➤ Debugging is a social act ➤ Solving problems is mentally taxing ➤ Sharing information and solutions is not taxing
is a container? ➤ Stand-alone executable package of software with everything you need to run it: code, runtime, tools, libraries, settings, etc. ➤ Sounds like a Virtual Machine… ➤ VM has a complete guest operating system, containers don’t have log in or other unnecessary parts of OS ➤ Containers can pack a lot more apps into a single server than a VM can ➤ VM better for running unknown code - it can only mess up the VM OS, not your OS
of Containers: ➤ Packaging ➤ Eliminate problems with different devs having different version #s ➤ Container images are immutable ➤ Performance ➤ Containers are faster because you aren’t running an entire different OS ➤ Efficiency ➤ Containers are small ➤ You can run lots of them if you want to!
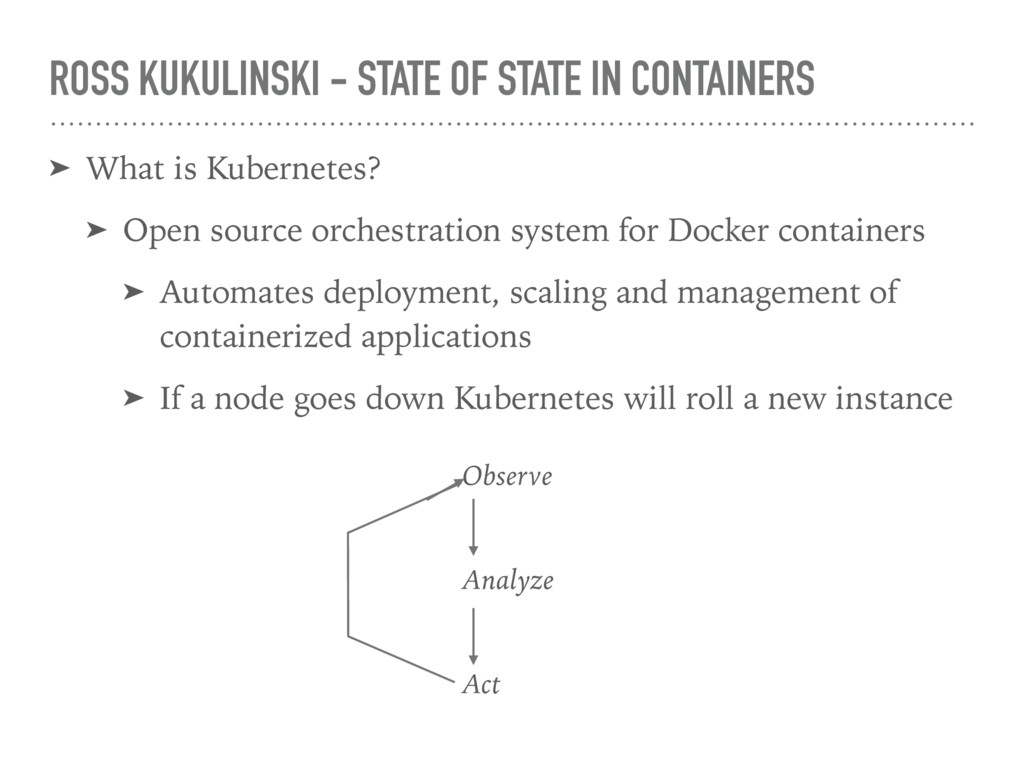
is Kubernetes? ➤ Open source orchestration system for Docker containers ➤ Automates deployment, scaling and management of containerized applications ➤ If a node goes down Kubernetes will roll a new instance Observe Analyze Act
conversion funnel and activating product advocates ➤ Kickstarter campaigns & gamification of getting more users ➤ The clients wanted to use MongoDB (heard it was good!) ➤ Ruby on Rails with MongoDB, Redis, and Heroku ➤ In MongoDB, the document size is limited to 16MB ➤ Translated to ~100 users per campaign ➤ Campaigns could have +100k users, so this wasn’t going to work!
lots of different ways to make MongoDB work ➤ Went from 1 master list to 3 lists ➤ Tried MapReduce ➤ ~30s for 3000 documents ➤ Introduced Sidekiq to help with background processes ➤ 1 HOUR for 329,000 documents ➤ Decided that MongoDB was good for simple operations, but not their app ➤ They couldn’t think of more to do and so his gut told him MySQL was the best option
NodeJS tool to migrate the MongoDB to MySQL ➤ Average response time: ➤ Heroku + MongoDB = 150ms ➤ Amazon Aurora + MySQL = 50ms ➤ Query time: ➤ MongoDB = 1 hour ➤ MySQL = 40 seconds ➤ Without any other query improvements ➤ All of this cost them a year of developer time ➤ 2015 was just putting out fires
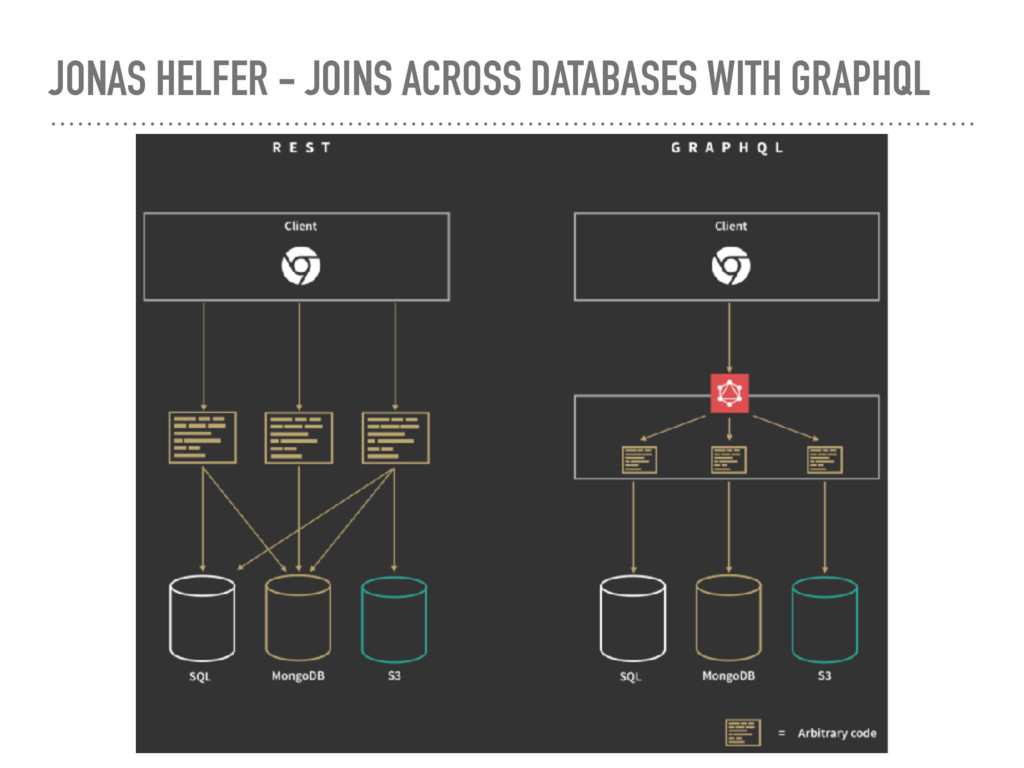
an application layer query language that interprets a string by a server then returns the data in a specified format ➤ A replacement for REST ➤ Easier to consume ➤ Get exactly the data you ask for ➤ Not more or less data than you asked for! ➤ Easier to produce ➤ Write resolvers to write a query to return user #1’s SQL record ➤ Resolver: functions that resolve a field to its value ➤ Version free ➤ The client decides what data it wants, so you can support many different client versions (instead of versioning endpoints)
➤ 40+ years old (Note: Wikipedia says 20 years) ➤ Postgres NoSQL = unstructured + relational database ➤ still ACID (Atomic, Consistent, Isolation, and Durable) ➤ Relational database ➤ Can set up Master Slave replication ➤ Copying database information to a second system to create high availability and redundancy ➤ Cool new features ➤ Date and time auto-magically change based on timezone when the data was entered vs. timezone when queried! ➤ Connect to more stuff with 1 (Postgres) API
is an open source message queue ➤ Queues help your application by ➤ Introducing coupling points ➤ Asynchronously process tasks ➤ Enable parts of the system to scale appropriately ➤ An event in one system causes 100+ other actions
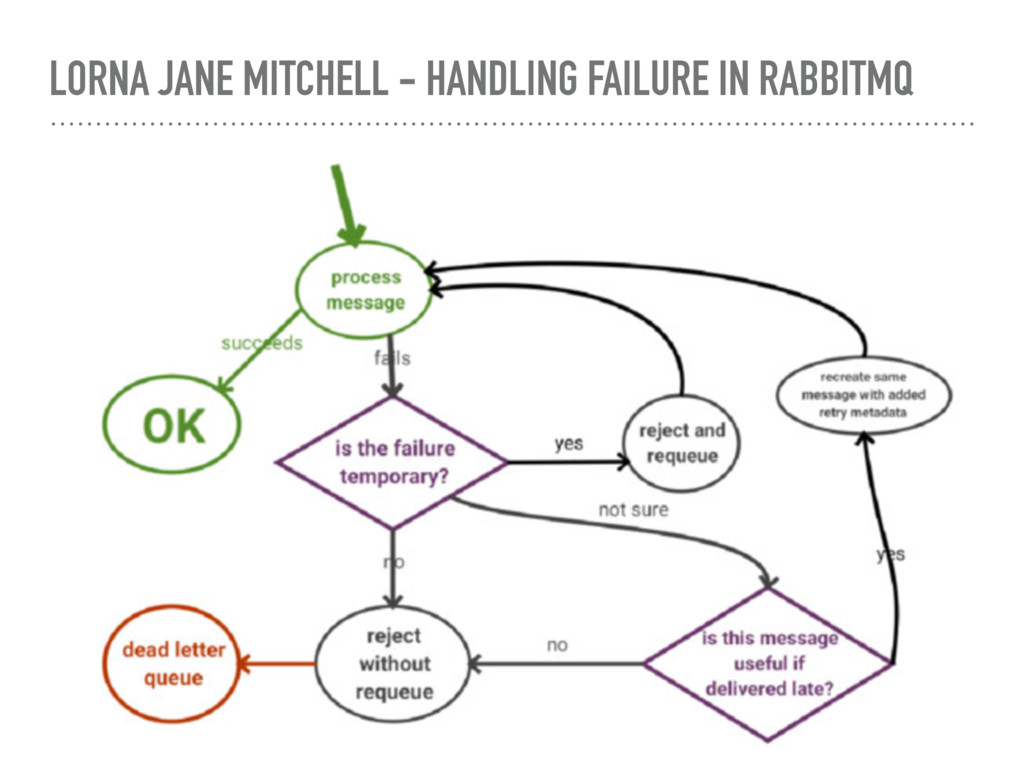
retries ➤ Identify if a message should be retried ➤ Create a new message with the same data ➤ Add retry count ➤ Ack the original message ➤ Reject after #x attempts ➤ Use a dead letter exchange if you can’t process the message! ➤ Republish the message to another exchange when: ➤ A message is rejected ➤ The time-to-live (TTL) for the message expires ➤ The queue length limit is exceeded
Spanner: Google’s globally distributed NewSQL database ➤ NewSQL? Modern relational database that combines the scalable performance of NoSQL while keeping the ACID guarantees ➤ Scales horizontally ➤ Distributed database ➤ Fully managed ➤ Traditional SQL transactions ➤ Currently works with Python, Java, NodeJS, and Go ➤ More languages to come!
No Foreign Keys! (but you have primary keys) ➤ Instead you interleave definitions ➤ Table rows will be physically co-located ➤ Increases leverage for Spanner to distribute data ➤ It’s a bad idea to create non-interleaved indexes on column whose values are monotonically increasing or decreasing (even if they aren’t primary key columns) ➤ Note: Spanner will be slow if you interleave EVERYTHING, so only interleave with discretion ➤ No downtime for schema migration ➤ No free tier :(
MongoDB and Elasticsearch ➤ Users can text simple commands to a bot to get balance, move money from checking to savings, etc. ➤ What they needed for this bot: ➤ Zero False Positives ➤ “I don’t know” is better than a wrong answer ➤ Only get 1 chance to respond
map responses in MongoDB ➤ map the message to the intended action 2. Index Message in Elasticsearch ➤ Stemming: accounting -> account ➤ Fuzzy query: acount -> account 3. Weigh frequencies ➤ High frequency: I, a, the ➤ Low frequency: balance, account, checking 4. Test it ➤ Test especially for false positives 5. Ship it
➤ Open Core ➤ Core features are open source ➤ Upgraded features are paid ➤ Pro: financially sustainable ➤ Con: seen as corporate/not really open source ➤ Examples: ➤ GitLab ➤ MySQL ➤ SugarCRM
➤ What went wrong at RethinkDB ➤ Lost funding ➤ Lost IP ➤ Had to purchase IP back ➤ Joined Linux Foundation ➤ Focused on building community and not on building a business model (and sticking with it) ➤ Hired Christina (community manager) when they should have been hiring marketing/sales/sales engineers
Stream-Filter-Drain(SFD) ➤ Alternative to Extract-Transform-Load(ETL) data pipelines ➤ Not just finding needle in haystack, there are only needles in the stack ➤ Make a real time stream processing tool ➤ Work with data at massive scale ➤ Keep it fast!
Data is fast before it is big ➤ Event processor ➤ Filter ➤ Grammar restricted RegEx ➤ Content based filtration ➤ Drain ➤ Pull matches by key tag ➤ Goes to data consumers ➤ Application, microservices, Spark, etc.
now are 12-factor monolithic beasts ➤ Hard to maintain ➤ Bit rot ➤ Microservices ➤ Part of a cluster of services ➤ Does 1 thing ➤ Coordinates with other services
➤ Amazon Lambda ➤ There is no cloud, just somebody else’s computer ➤ It isn’t: ➤ Small services ➤ Fine grained billing ➤ Cost as a constraint ➤ Distributed ➤ “Stateless”
Redis ➤ Fast ➤ Well supported ➤ Well Documented ➤ Fast ➤ Fixes the “stateless” problem ➤ Language agnostic ➤ Can lower costs by billing by milliseconds rather than by hour/minute ➤ You don’t have to do everything yourself!!
has limitations ➤ Middleware logic that connects DB with realtime protocols ➤ Can’t deal with complex realtime scenarios ➤ Doesn’t scale well ➤ Alternative: Streaming Database System ➤ Take the best parts of a DB system and add realtime protocols ➤ Middleware layer is optional!
Distributed text search ➤ Based on Lucene ➤ Scales to many nodes easily ➤ Percolation ➤ Indexes queries and filter documents against the indexed queries to know which queries they match ➤ Allows reverse search ➤ Matches when new documents are added
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}