to my talk! This talk is about using Neo4j in an Elixir project to make a social networking clone. Who here has heard of Neo4j? Who has used Neo4j? Who has used it in production??
I live in Austin, Texas and I am a freelance mobile developer. I’m knitter and a spinner in addition to coding and I’m so happy to be bringing together two things that I enjoy doing. I can be found on twitter and on github as StabbyMcDuck and on Ravelry as BlueRosebud. If you’re not familiar with Ravelry, you’ll learn a lot more about it during this talk! And to be super clear, I’m not affiliated with Ravelry other than being a user of the site - I’m don’t work for them and this isn’t an official replacement by any means. It was just a fun project I made using a site I love as a template. The project repo can be viewed at github.com/StabbyMcDuck/elixir_ravelry.
non-relational • Uses Cypher for queries • ACID compliant • Just like many relational databases! I said that this talk is about using Neo4j in an Elixir project, but Neo4j is unfamiliar to many of people here. Neo4j is a NoSQL graph database. As it is not a SQL database, it doesn’t use SQL queries but rather it uses Cypher, a declarative query language for graph databases. Neo4j is different than many other NoSQL, like MongoDB, because it is ACID compliant (like SQL databases) and fully transactional.
networks • Graph-based search • Real-Time Recommendations • More! Neo4j has the standard Create, Read, Update, and Delete commands, just like SQL databases. Neo4j really shines at connected data. When I thought of connected data, I immediately thought of social networks, but there are tons of other uses of graph databases - including when you would want to do a graph search or doing real time recommendations for products. For example, Walmart uses Neo4j for real time recommendations to model online shopper’s behavior and the relationships between shoppers and products.
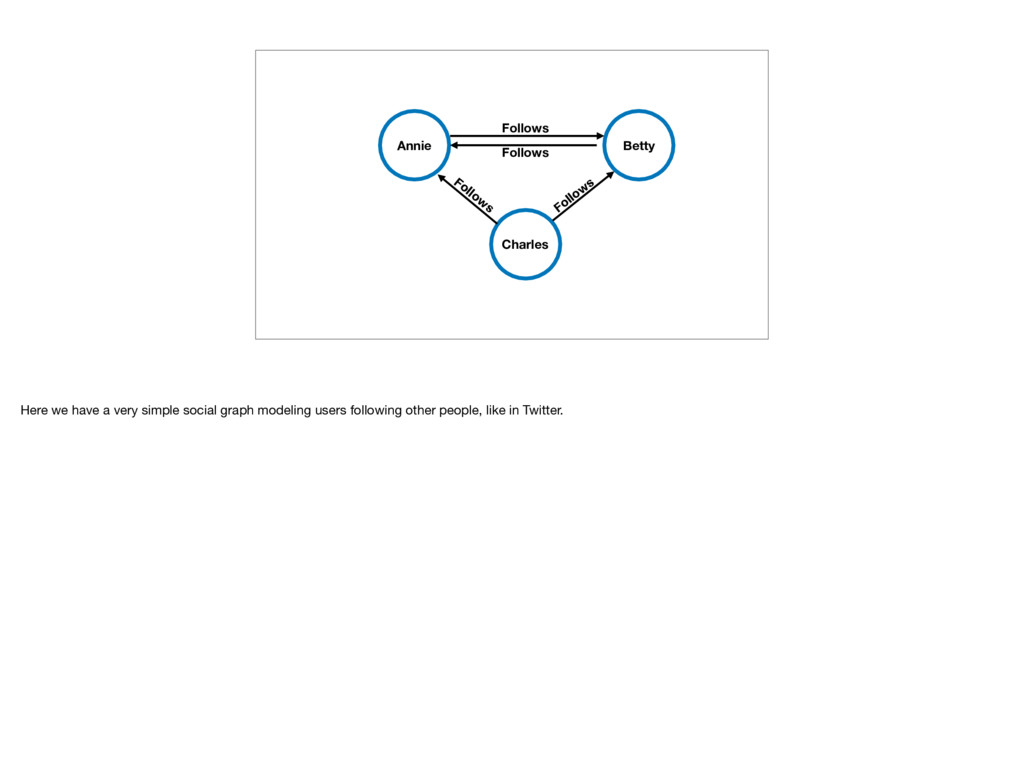
we are not talking about bar graphs or pie charts or anything like that. Instead, we’re talking about graph theory, which you may remember if you took an algorithms or discrete mathematics class. Broadly speaking, graphs are structures that are used to model relations between objects. I’ll be talking a bit about graph theory, since it is the backbone for how graph databases work.
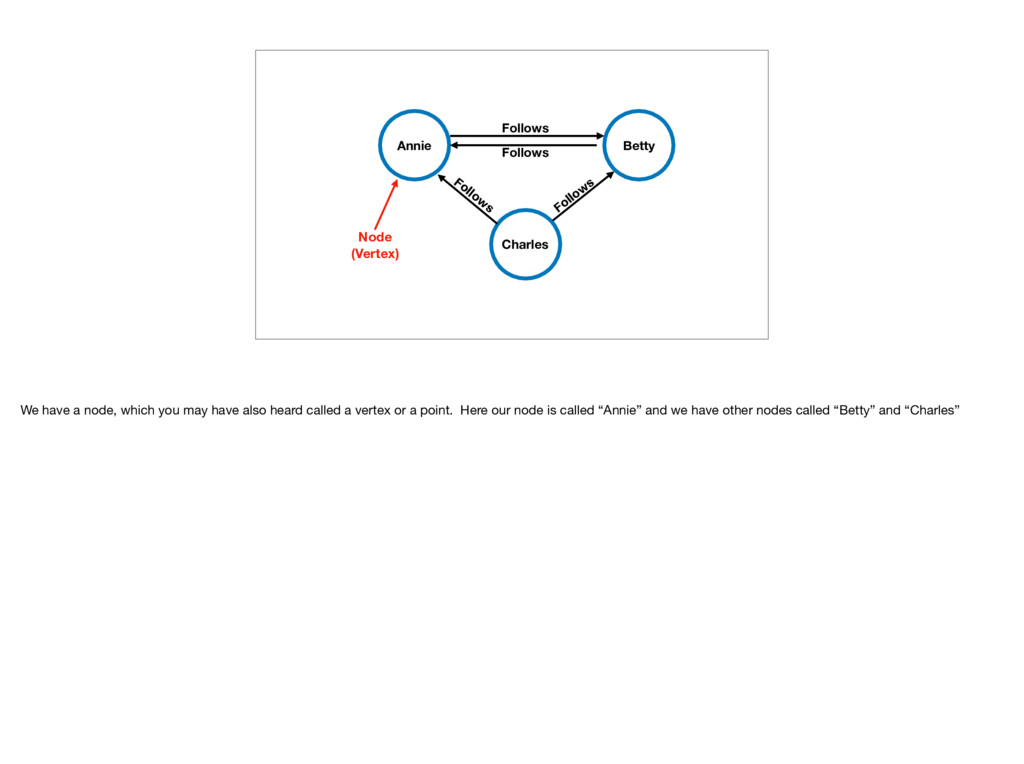
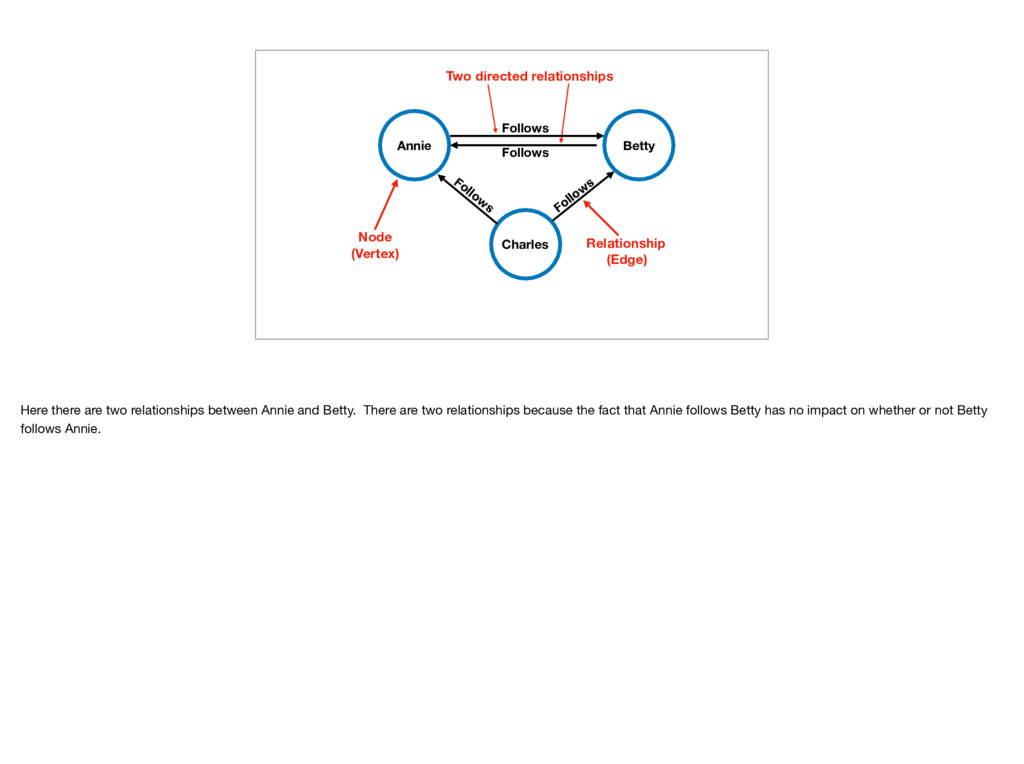
Follows We have a node, which you may have also heard called a vertex or a point. Here our node is called “Annie” and we have other nodes called “Betty” and “Charles”
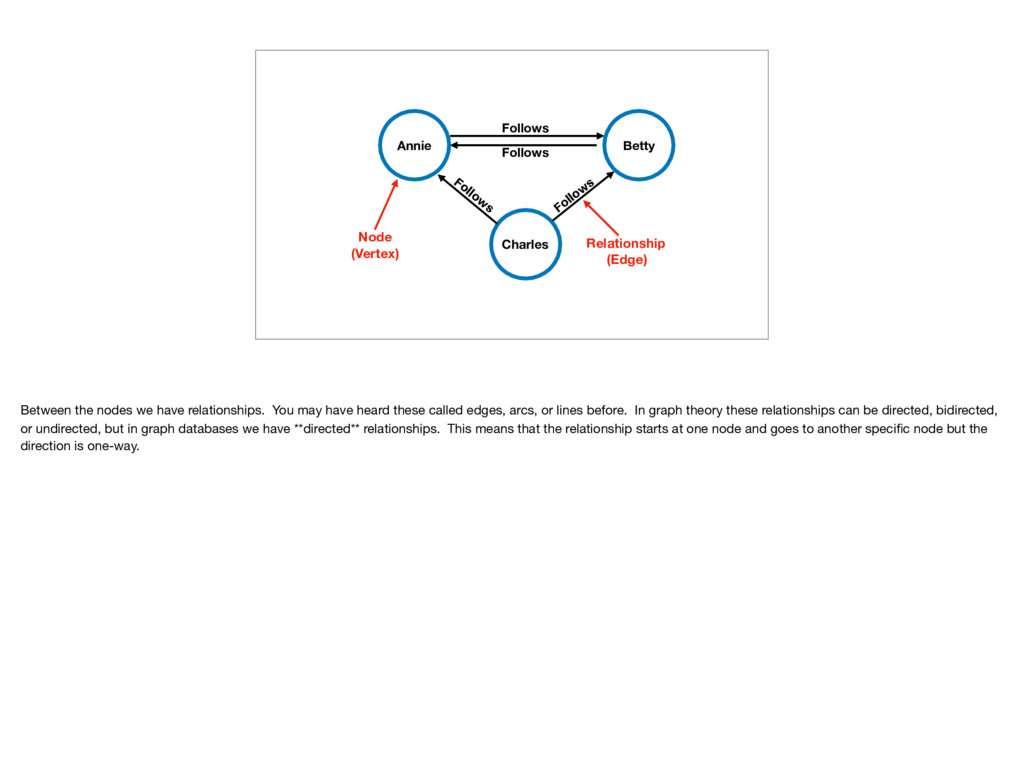
Follow s Follows Between the nodes we have relationships. You may have heard these called edges, arcs, or lines before. In graph theory these relationships can be directed, bidirected, or undirected, but in graph databases we have **directed** relationships. This means that the relationship starts at one node and goes to another specific node but the direction is one-way.
Follows Follow s Follow s Follows Here there are two relationships between Annie and Betty. There are two relationships because the fact that Annie follows Betty has no impact on whether or not Betty follows Annie.
pairs) • Have one or more labels • Relationships • Have names • Are directed • Can also contain properties So that’s the very basic structure of of graph database. The model used for this is called the Labeled Property Graph Model and it has a few characteristics to note. We have nodes, which contain properties - which can also be thought of as key-value pairs, and one or more labels attached to that node. We also have relationships, which are named and directed. Relationships must have a start node and an end node and can only have a start node and an end node. Relationships can also contain properties, but they aren’t required.
gets worse with large data sets • Especially compared to join-intensive queries in SQL • Graph databases remain mostly constant • Queries are localized to a section the graph Now that you have some idea of what a graph database is and what it does, you may be wondering why you might want to use this kind of database. Performance is the most obvious answer to that, particularly when we are talking about connected data. Connected data has a habit of needing lots of joins, and the performance of those join-intensive SQL queries gets worse and worse as the dataset gets bigger. Meanwhile, graph database performance doing the same searches remains mostly constant because we are able to localize searches to a section of the graph. Even while the dataset gets bigger, we can still keep searches localized to maintain performance.
are additive • Can add new kinds of relationships, nodes, labels, subgraphs, etc. to existing structure • Won't disturb existing queries! • Less developer time spent on modeling domains Another advantage is flexibility. Graph databases are additive, meaning you can add new nodes, relationships, labels, whatever to your database without affecting existing queries. It's so flexible that you don’t have to model domains as rigorously before you start your project, which saves developer time.
Change the data model as you develop Lastly, graph databases are agile by nature and schema-free. Because they’re flexible, you can change the data model as you develop and as new business requirements come up.
The manufacturing and sales of yarn • Applicable to most social and manufacturing processes So onto the actual project! I am making a small clone of the Ravelry website. Ravelry is a social networking site for the fiber arts community - so knitting, crocheting, spinning, and dying fiber and yarn. You can also buy and sell yarn, fiber, and patterns as well as join special interest groups and talk with other members about pretty much anything. So I’ll be briefly talking about the manufacturing and sales of yarn here, but remember that the key aspects of this are relevant to most manufacturing of products and social networks.
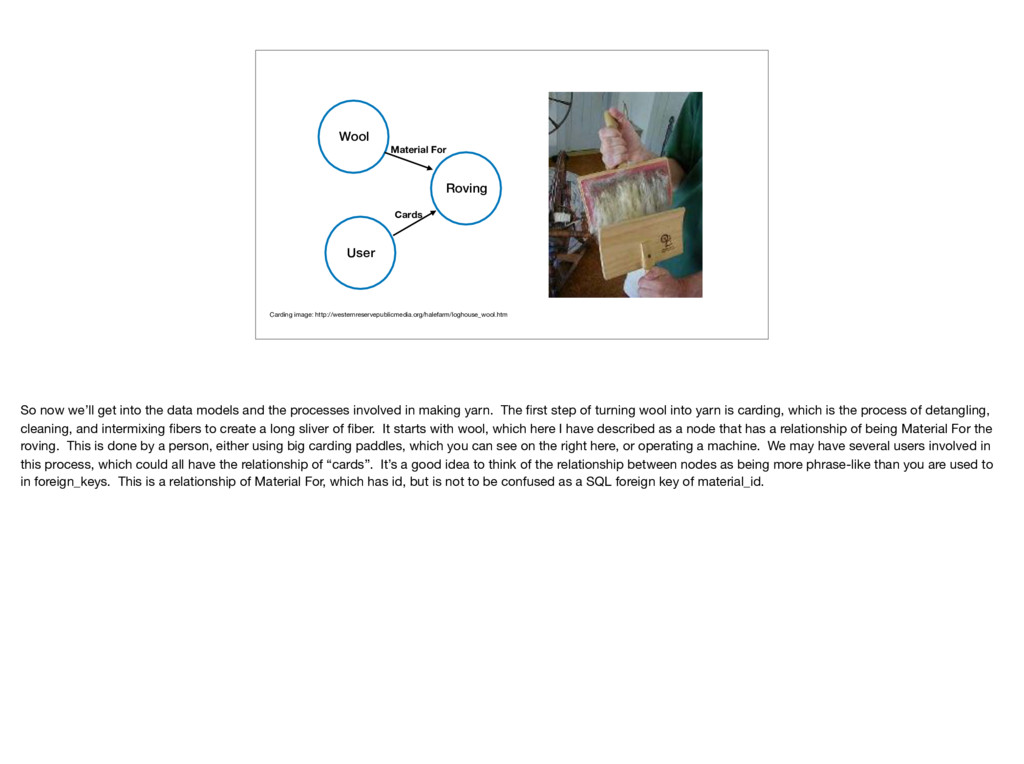
now we’ll get into the data models and the processes involved in making yarn. The first step of turning wool into yarn is carding, which is the process of detangling, cleaning, and intermixing fibers to create a long sliver of fiber. It starts with wool, which here I have described as a node that has a relationship of being Material For the roving. This is done by a person, either using big carding paddles, which you can see on the right here, or operating a machine. We may have several users involved in this process, which could all have the relationship of “cards”. It’s a good idea to think of the relationship between nodes as being more phrase-like than you are used to in foreign_keys. This is a relationship of Material For, which has id, but is not to be confused as a SQL foreign key of material_id.
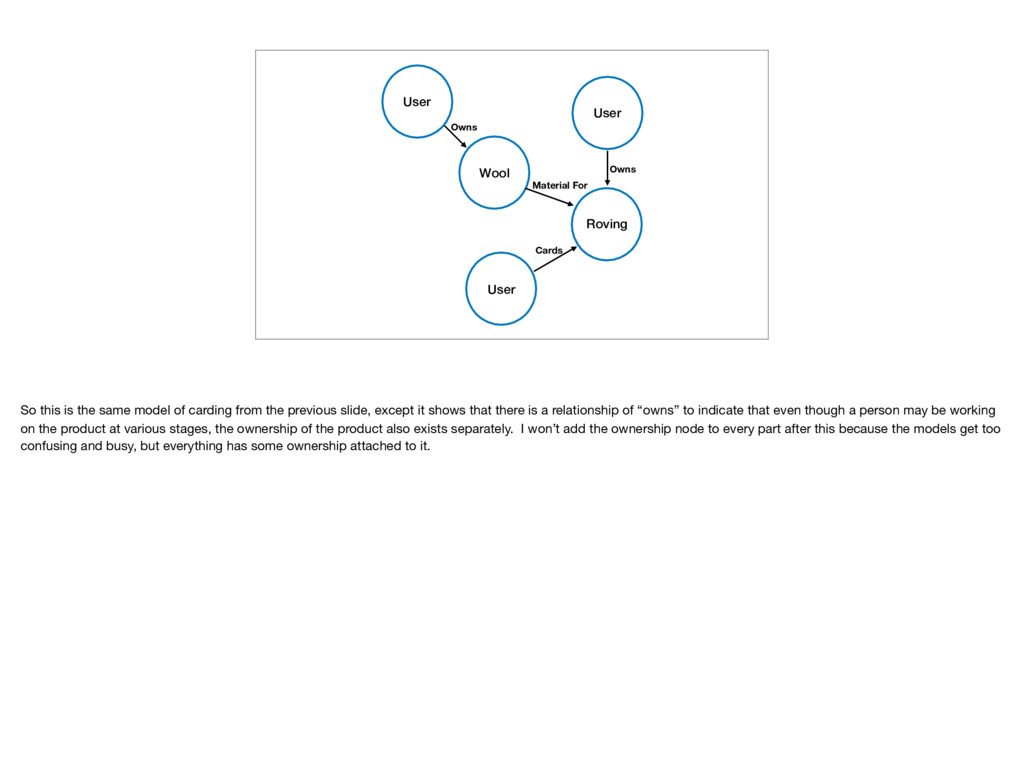
So this is the same model of carding from the previous slide, except it shows that there is a relationship of “owns” to indicate that even though a person may be working on the product at various stages, the ownership of the product also exists separately. I won’t add the ownership node to every part after this because the models get too confusing and busy, but everything has some ownership attached to it.
After the carding, the wool is referred to as roving and it can be dyed. There are lots of ways to dye the roving and again, one or more people may be involved in the process of dyeing the yarn. So we have our carding node from the previous slide which now is material for the dyed roving and we have a user who dyes the roving to make the dyed roving.
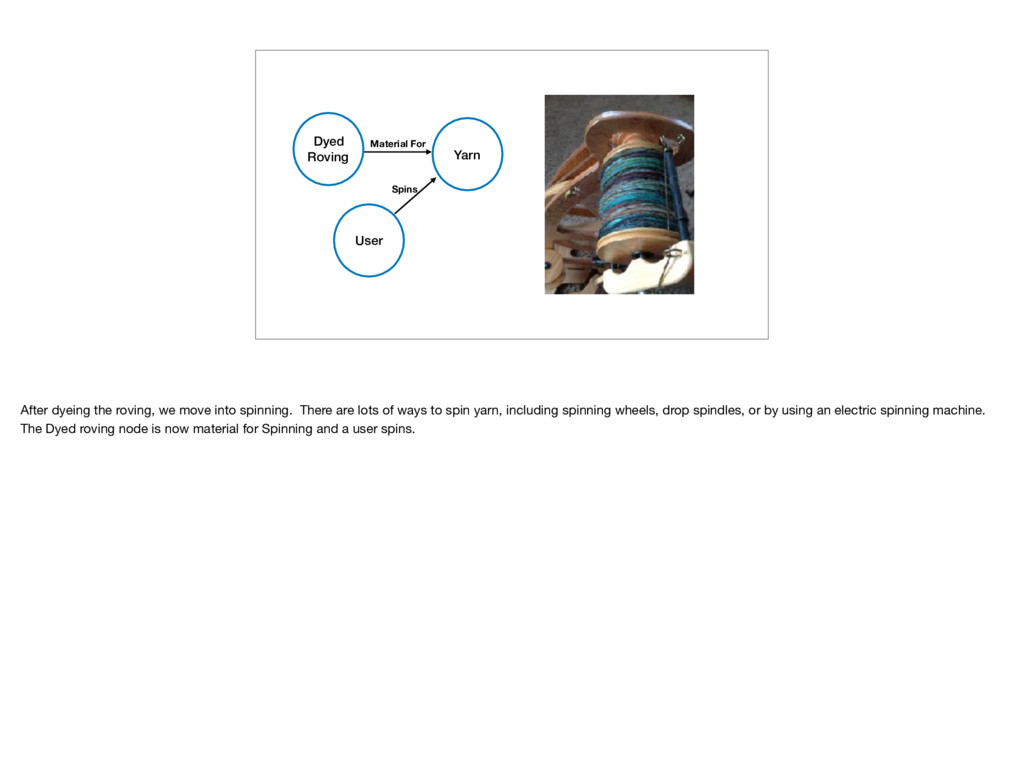
roving, we move into spinning. There are lots of ways to spin yarn, including spinning wheels, drop spindles, or by using an electric spinning machine. The Dyed roving node is now material for Spinning and a user spins.
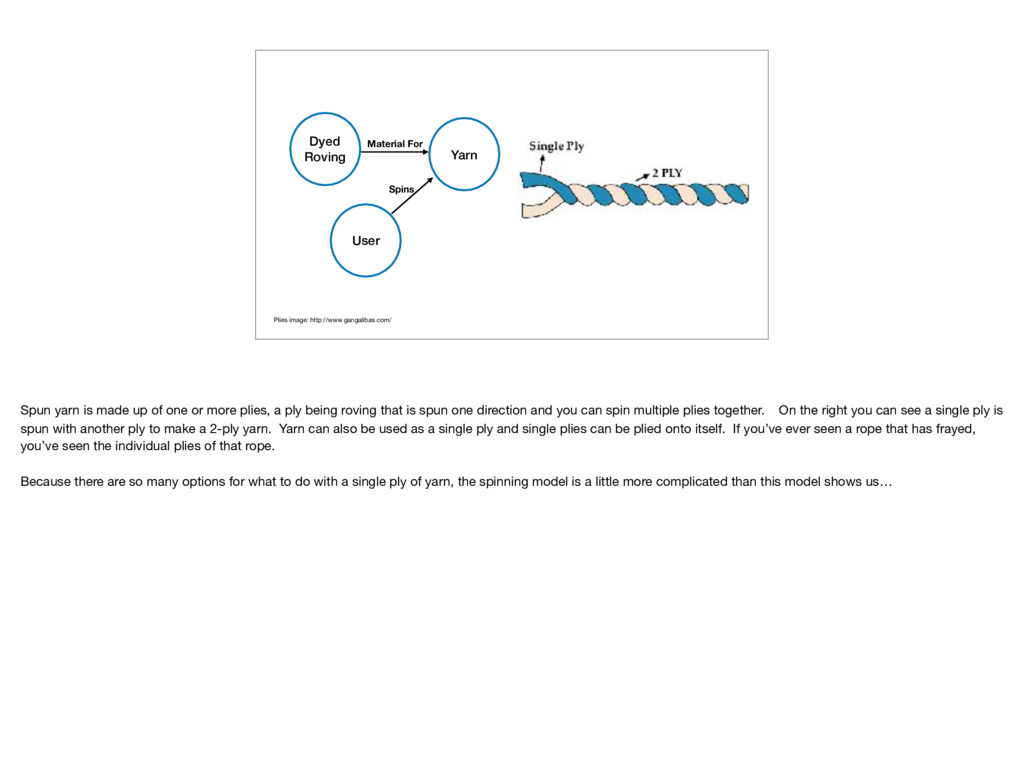
Spun yarn is made up of one or more plies, a ply being roving that is spun one direction and you can spin multiple plies together. On the right you can see a single ply is spun with another ply to make a 2-ply yarn. Yarn can also be used as a single ply and single plies can be plied onto itself. If you’ve ever seen a rope that has frayed, you’ve seen the individual plies of that rope. Because there are so many options for what to do with a single ply of yarn, the spinning model is a little more complicated than this model shows us…
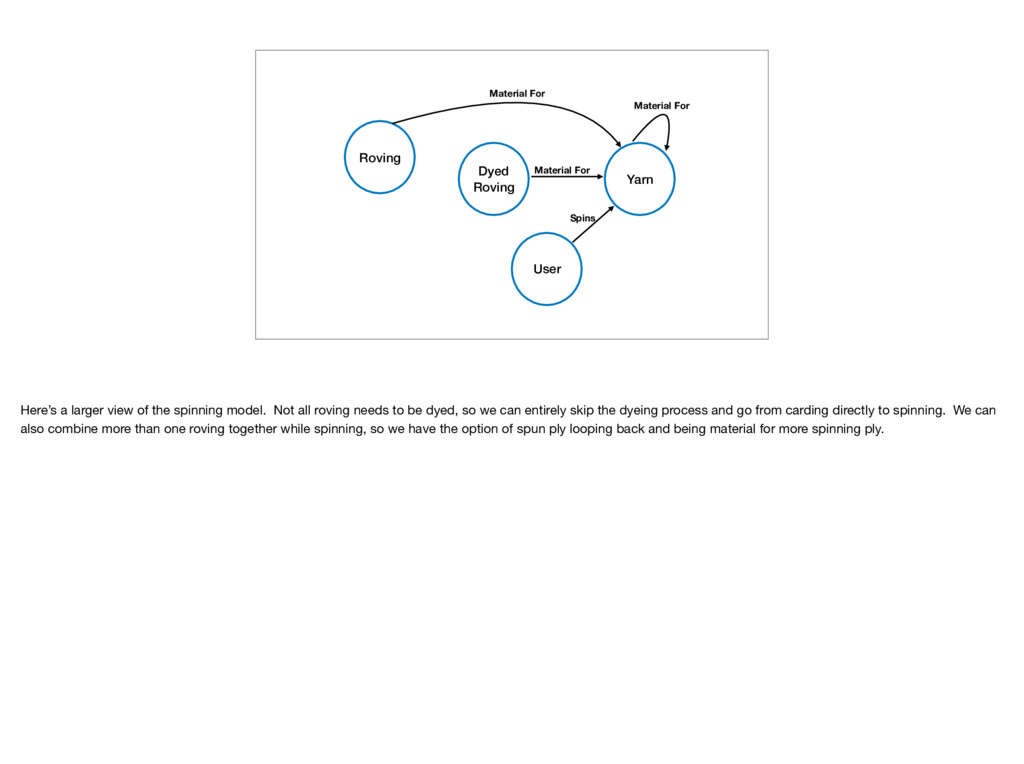
Material For Here’s a larger view of the spinning model. Not all roving needs to be dyed, so we can entirely skip the dyeing process and go from carding directly to spinning. We can also combine more than one roving together while spinning, so we have the option of spun ply looping back and being material for more spinning ply.
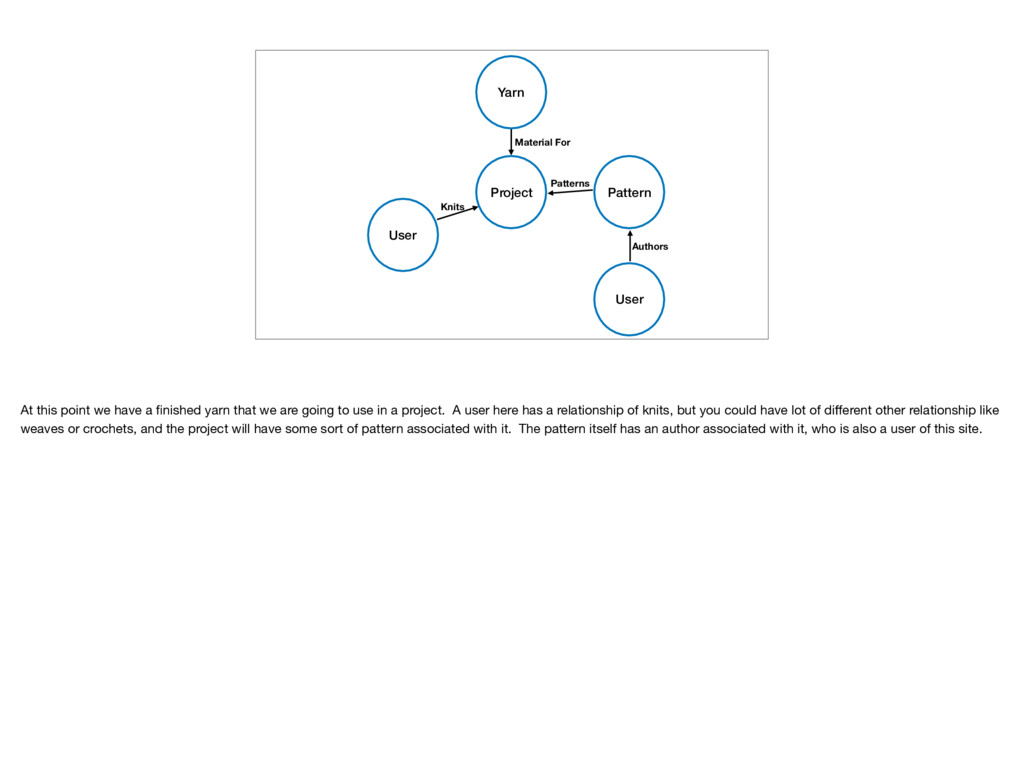
At this point we have a finished yarn that we are going to use in a project. A user here has a relationship of knits, but you could have lot of different other relationship like weaves or crochets, and the project will have some sort of pattern associated with it. The pattern itself has an author associated with it, who is also a user of this site.
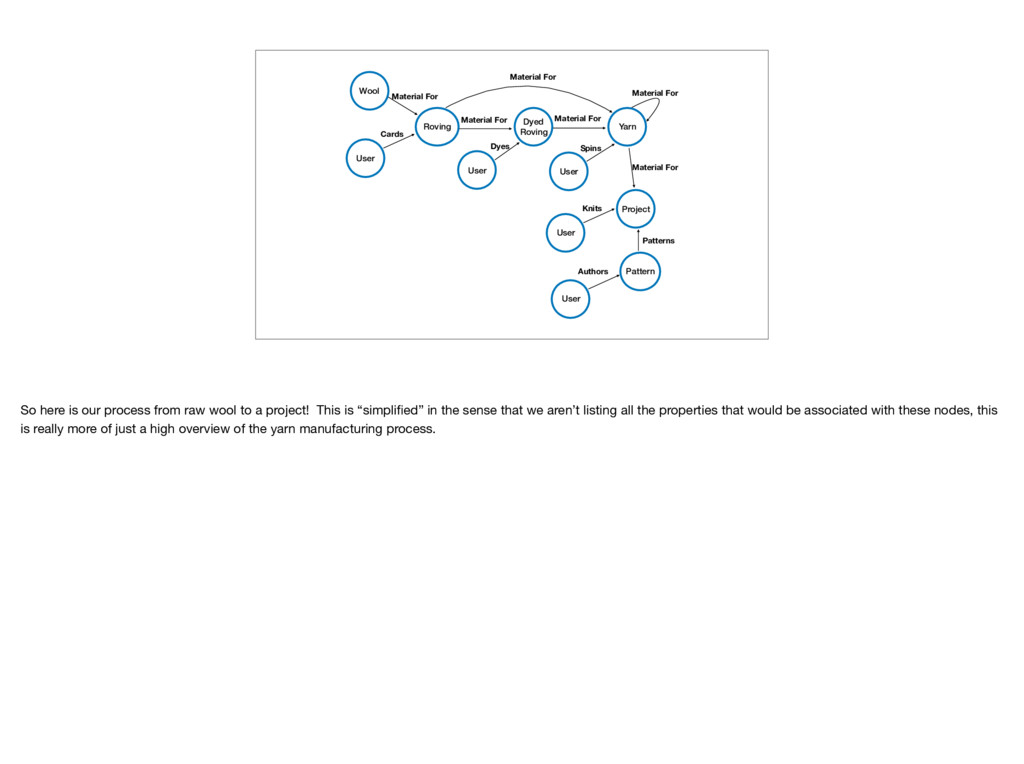
User Dyes Yarn Material For User Spins Material For Project Material For User Knits Pattern Patterns User Authors Material For So here is our process from raw wool to a project! This is “simplified” in the sense that we aren’t listing all the properties that would be associated with these nodes, this is really more of just a high overview of the yarn manufacturing process.
of yarn has tested positive for anthrax! • We need to find all the people who were involved in the production of this dye lot to test them too So now we have a possible, but for any knitters in the room, a seriously far-fetched scenario: somebody who knitted a skein of yarn has tested positive for anthrax! Anthrax is an infection caused by a bacterium, and forms a small blister on the skin or, much much more rarely, it can be inhaled and result in a severe respiratory infection. It’s spread by contact with the spores of the Bacillus anthracis and it is very rare and primarily occurs with people who work with livestock and livestock products…. like our sheep! So we’re going to need to find all of the people who were involved in the production of this yarn to test all of them too.
spinnings ON spinnings.spinner_id = users.id INNER JOIN yarn ON yarn.material_id = spinnings.id INNER JOIN users as knitters ON knitters.id = yarn.knitter_id WHERE knitters.name = "Bob" UNION We’ll need to work backwards from our yarn to all the way back to our carding. From our yarn, we can work back to who the spinner was - so in a SQL query we’ll who spun the yarn that is now knitted by somebody, here we named them Bob after the Ravelry mascot. So we select the all the users from users, inner join spinning on the ids that match, inner join yarn where the yarn material id matched the spinning id, inner join the users as knitters where the knitter id matches the yarn knitter id where the knitter’s name is “bob” and union that with the next slide…
JOIN dyed_roving ON dyed_roving.dyer_id = users.id INNER JOIN spinnings ON spinnings.material_id = dyed_roving.id INNER JOIN yarn ON yarn.material_id = spinnings.id INNER JOIN users as knitters ON knitters.id = yarn.knitter_id WHERE knitters.name = "Bob" UNION Then we need to add the dyed roving section. So we select all the users from users and inner join dyed_roving where the dyer id matches the user id and inner join spinning where the material id equals the dyed roving id, inner join the yarn table and match the yarn material id to the spinning id and then inner join the users as knitters where the knitter id equals the yarn knitter id where the knitters name is Bob and union that with…..
roving ON roving.carder_id = users.id INNER JOIN dyed_roving ON dyed_roving.material_id = roving.id INNER JOIN spinnings ON spinnings.material_id = dyed_roving.id INNER JOIN yarn ON yarn.material_id = spinnings.id INNER JOIN users as knitters ON knitters.id = yarn.knitter_id WHERE knitters.name = "Bob" It just keeps going! This is all that deep of a query and it’s already annoying. That’s a lot of nasty table joins! That’s a lot of stuff that could go wrong! That’s also a lot of data that if we add a new table or changed things a lot of this wouldn’t work and would have to be rewritten.
= ‘sherlock' RETURN q But there’s an easier way with a Cypher Query! Cypher is a declarative graph query language made by the folks at Neo4j. So here is the entire cypher query that replaces the 35 lines of SQL query and accomplishes the same goal of finding all the people who were involved in the manufacturing process of the yarn in question. Let’s go over this query:
= ‘sherlock' RETURN q Variable The Match is exactly what you’d think it means, it’s matching whatever comes after it. The single letters you see before the colon are just variables that we can attach to make the queries easier to use later. They are optional.
= ‘sherlock' RETURN q Variable Relationship Node The square brackets indicate a relationship. We have a relationship OWNS between User and Yarn, so the User who owns a yarn, and a relationship of star between Yarn and User….
= ‘sherlock' RETURN q Variable Relationship Variable length path Node The star in the relationship bracket indicates that it’s a variable length path. This means that one or more relationships between y:Yarn and q:User will be queried. You can also specify how many length path you want here too, but in our case we really don’t care how many relationships exist between the Yarn and other users, we want them all.
= ‘sherlock' RETURN q Variable Relationship Variable length path Type Node Where you see a colon is a Type. Types the overarching name we can give to relationships and nodes. Here we have node with types User and Yarn and relationship with a type of Owns.
= ‘sherlock' RETURN q Variable Relationship Directed Relationship Variable length path Type Node The arrow here in the middle of our match indicates it’s a directed relationship. So the query is Match the node user, p that has a relationship of owns to the yarn and find all the users associated with that yarn with a name of ‘sherlock’ and we return all the users with some relationship to this yarn. Unlike in SQL where the returning statement is optional, Return is required in Cypher. Cypher allows us to completely gloss over all of the joins that we have to write in SQL.
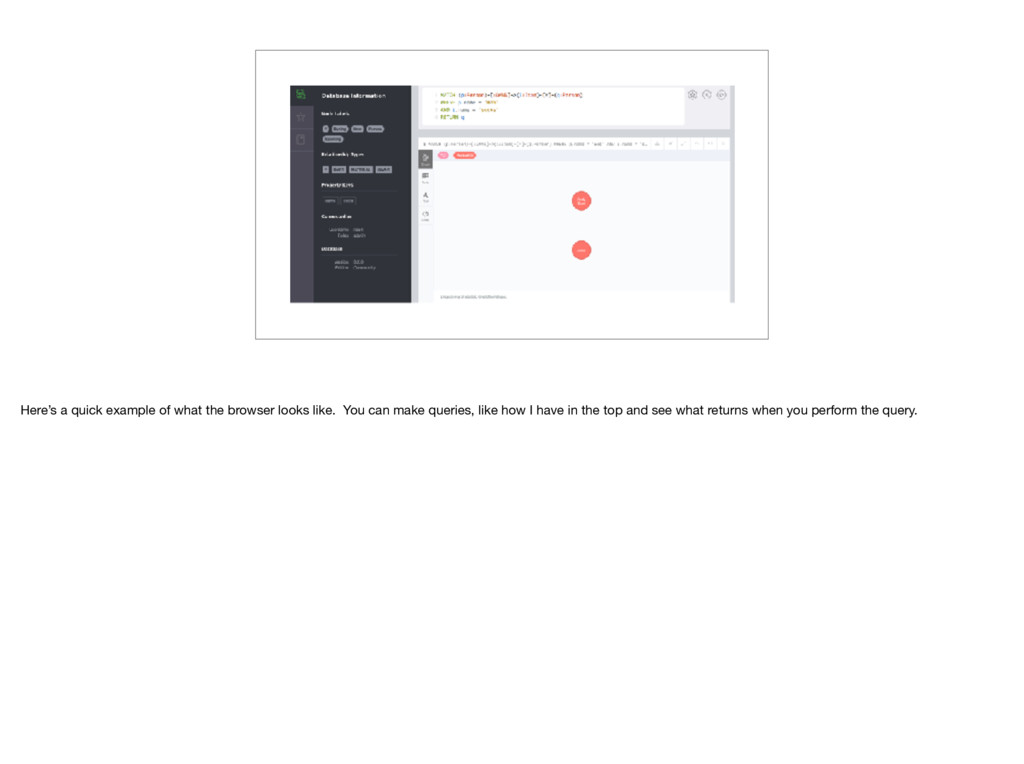
data • Interact with data A few more points about Cypher and Neo4j: - Neo4j installs with a browser where you can make queries, visualize your data, and interact with your data. One word of caution is that if you make new nodes and relationships in the browser it will populate your actual database and in my case, make tests fail, so make sure you clean out any nodes or relationships made.
Uses Bolt protocol • Supports Cypher queries • Connection pool So how are we able to use neo4j in an elixir project? Luckily we have a few brave souls who made Bolt.Sips, a neo4j driver for Elixir. It’s similar to Postgrex, in that it’s a driver to the database, but it operates at a lower level than Ecto. It uses the Bolt protocol, the newest network protocol from Neo4j. If you go Googling, you’ll likely see neo4j.sips as well, which uses an older network protocol and doesn’t offer the high-performance that Bolt.Sips offers. I used Bolt.Sips for my project. Bolt sips supports transactions and Cypher queries as well as taking care of connection pool implementation with PoolBoy
graph databases ☹ • Ecto Repo • No adapter for Neo4j • Ecto Schema • No nodes, no relationships The biggest challenge with using Neo4j in Elixir is Ecto. Ecto is composed of ecto query, ecto repo, and ecto schema. Ecto query was designed for SQL databases and has been adapted to work with MongoDB. Ecto query doesn’t share the same keywords that Cypher uses and there’s no one-to-one translation of Ecto query to Cypher, so Ecto query won’t work for our purposes. Ecto repo doesn’t have an adaptor for neo4j and ecto schema doesn’t support nodes and, more importantly, relationships. So you might be thinking why even bother?
Bolt.Sips.begin() on_exit fn !-> Bolt.Sips.rollback(bolt_sips_conn) end conn = Plug.Conn.put_private(conn, :bolt_sips_conn, bolt_sips_conn) %{bolt_sips_conn: bolt_sips_conn, conn: conn} end We can’t use Ecto.Adapters.SQL.Sandbox because there is no Ecto adapter for us AND this isn’t SQL! So instead we have to manage the transactions ourselves. Florin, the maintainer of Bolt_Sips, was kind enough to open a PR to make these transactions into a case template instead of having it copied into every test.
Bolt.Sips.begin() on_exit fn !-> Bolt.Sips.rollback(bolt_sips_conn) end conn = Plug.Conn.put_private(conn, :bolt_sips_conn, bolt_sips_conn) %{bolt_sips_conn: bolt_sips_conn, conn: conn} end So begin and rollback work on beginning and rolling back the transaction, just like in SQL.
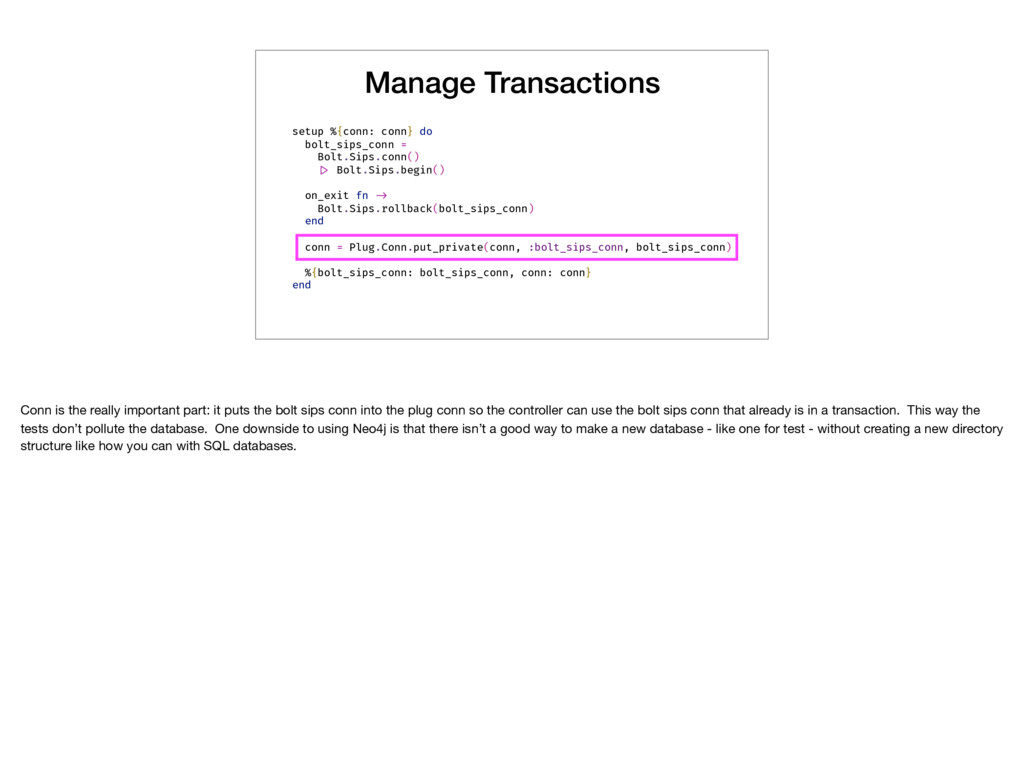
Bolt.Sips.begin() on_exit fn !-> Bolt.Sips.rollback(bolt_sips_conn) end conn = Plug.Conn.put_private(conn, :bolt_sips_conn, bolt_sips_conn) %{bolt_sips_conn: bolt_sips_conn, conn: conn} end Conn is the really important part: it puts the bolt sips conn into the plug conn so the controller can use the bolt sips conn that already is in a transaction. This way the tests don’t pollute the database. One downside to using Neo4j is that there isn’t a good way to make a new database - like one for test - without creating a new directory structure like how you can with SQL databases.
_params) do dyed_roving = conn !|> bolt_sips_conn() !|> Repo.DyedRoving.list() json conn, dyed_roving end Bolt sips conn is a function in the controller.ex file. Bolt sips conn takes in the plug connection, and we look for a private connection in the map. Get lazy is to ensure that we only make one connection instead of making multiple connections that could lead to confusion and eat up memory. The index function I show here is for the dyed roving controller and is just an example of how to use bolt sips conn to ensure we use the test connection in a transaction when it's available. The index function takes in the plug connection, we take that plug connection and pipe it to bolt sips conn to get the test connection if it’s available or set up a new connection if there is no test connection, then pipe the connection to the repo list.
do Repo.get_node(conn, type(), id) end def graph(conn, id, direction) do Repo.graph(conn, type(), id, direction) end def list(conn) do Repo.list_node(conn, type()) end end end As I was writing the different repos for the different nodes and relationships I noticed a pattern of writing the same code over and over again, so I pulled out this macro to make more generic for all nodes. There’s a similar macro for relationships. This macro defines default implementations for get, graph, and list for nodes as they don’t depend on the types of the individual fields.
struct the behavior of get, list, and graph also require row to struct and create because they contain the types. Because there’s no Ecto adapter, we can’t use the types in the Ecto schema and instead have to do the type conversions manually. I did end up using the Ecto types and ecto changeset to cast the params for the create controller actions.
%{type: type(), end_node_id: wool_id, start_node_id: user_id, started_at: Repo.to_timestamp(started_at)}) end Here’s the owns create, which creates a relationship of type owns - and you’ll see that there is a call to Repo.to_timestamp. Because there’s no Ecto adapter, we have to manually translate from ecto date time to unix timestamp, which is the time type that neo4j understands. Broadly speaking, Neo4j is less type-rich than Postgres, which is why I had to do more type conversions than you'd think.
!=> started_at_timestamp }, start: user_id, type: type() } ) do %Owns{ !__meta!__: %Ecto.Schema.Metadata{ source: {nil, type()}, state: :loaded }, id: id, wool_id: wool_id, user_id: user_id, started_at: Repo.from_timestamp(started_at_timestamp) } end Likewise, in row-to-struct, we have to translate from Neo4j understandable unix timestamp back to Ecto’s date time.
!=> started_at_timestamp }, start: user_id, type: type() } ) do %Owns{ !__meta!__: %Ecto.Schema.Metadata{ source: {nil, type()}, state: :loaded }, id: id, wool_id: wool_id, user_id: user_id, started_at: Repo.from_timestamp(started_at_timestamp) } end Here’s the row to struct function for a relationship and you’ll see there’s start and end fields. To make the relationships work better in Ecto, we map start and end to specific foreign key names. This way we can have ecto do more work for us.
!=> started_at_timestamp }, start: user_id, type: type() } ) do %Owns{ !__meta!__: %Ecto.Schema.Metadata{ source: {nil, type()}, state: :loaded }, id: id, wool_id: wool_id, user_id: user_id, started_at: Repo.from_timestamp(started_at_timestamp) } end The weird meta field shown here is stuff that is normally filled in and taken care of by the Ecto adaptors, but again, as there is no Neo4j ecto adaptor, I had to fill this in manually. If the meta data state isn’t filled in, then the default value is colon built. Built and loaded change the way the changeset functions work, so it’s important to fill this in.
= if type do ":!#{type}" else "" end conn !|> Bolt.Sips.query!( """ MATCH (n!#{n_type}) WHERE id(n) = toInteger({id}) !#{graph_optional_match(direction, options)} WITH !#{graph_with(direction)} RETURN !#{graph_return(direction)} """, cypher_parameters(id, options) ) !|> graph_return_to_map() end To construct the graph, we have to match on the starting node, which is looked up by id. You’ll notice we look up the node id by using the id function. This is because ids in Neo4j cannot be looked up with dot id, like in SQL. We have to explicitly cast to ToInteger because parameterized values aren’t cast automagically like in Postgres. Next we’ll figure out the direction of the graph by taking in the direction of either forward, backward, or both. Users may not care about the backwards graph, because they only care about how the thing they made is used, but if you’re making a sweater out of handspun yarn and run out of yarn when you haven’t finished the sweater, you’ll want to be able to look up where to source that material. With, in cypher queries, can be tricky. With is a hard line in the sand - only names declared as outputs can be used after the with. Any pre-existing named variables are completely hidden after the with line. With doesn’t have to be the last line before return, it can be used as filtering to break up multiple sub-queries. The trickiness of with is why there is only one with line in this query - I tried having a with for each direction but the values couldn’t all be used in the return, which lead to problems.
defp graph_optional_match("both", options) do "!#{graph_optional_match("forward", options)}\n!#{graph_optional_match("backwards", options)}" end defp graph_optional_match("backwards", options) do "OPTIONAL MATCH backwards = (source!#{backwards_type(options)})-[backwards_relationship*0!..]!->(n)" end Unlike with, match and optional match doesn’t hide previously matched variables. The graph for both directions can have both the line for forward followed by the line for backwards.
You’ll notice in the relationship here is star zero dot dot. 0.. overrides the default minimum of 1 that the star has, which allows us to have 0 or more relationships. When there are 0 relationships, there is no source or sink node, and the source and sink nodes collapse into n, the node we’re starting from. This ensures that if the graph only has the node itself, the graph is still returned. If there are one or more nodes, you’ll get the middle node back from both the forward and backwards paths. I wasn’t able to figure out how to eliminate the duplicate node in Cypher, but I did a Enum.unique on the combined list of source and sink nodes to work around this.
"User"} Here we are filtering for those users who worked on this project that may have tested positive for anthrax. We filter backwards from the project, since the knitter is the one who started this scare, we want to go backwards. We filter by type of User because we want to find all of the people involved, regardless of their role in manufacturing the finished project.
(source#{backwards_type(options)})- [backwards_relationship*0..]->(n) WITH COLLECT(DISTINCT source) as source_nodes, COLLECT(DISTINCT head(backwards_relationship)) as backwards_rels RETURN source_nodes, backwards_rels You’ll notice on this slide that there are several areas where we have interpolation with hash and curly braces but also just curly braces, such as in the toInteger id call. This is because either bolt sips or the bolt protocol, I haven’t figured which, won’t allow types to parameterized like values. We have to parameterized the types with Elixir interpolation and pass the values as parameters instead of simply interpolating everything, because interpolation means we have to manually protect against exploitation.
(source#{backwards_type(options)})- [backwards_relationship*0..]->(n) WITH COLLECT(DISTINCT source) as source_nodes, COLLECT(DISTINCT head(backwards_relationship)) as backwards_rels RETURN source_nodes, backwards_rels You’ll notice on this slide that there are several areas where we have interpolation with hash and curly braces but also just curly braces, such as in the toInteger id call. This is because either bolt sips or the bolt protocol, I haven’t figured which, won’t allow types to parameterized like values. We have to parameterized the types with Elixir interpolation and pass the values as parameters instead of simply interpolating everything, because interpolation means we have to manually protect against exploitation.
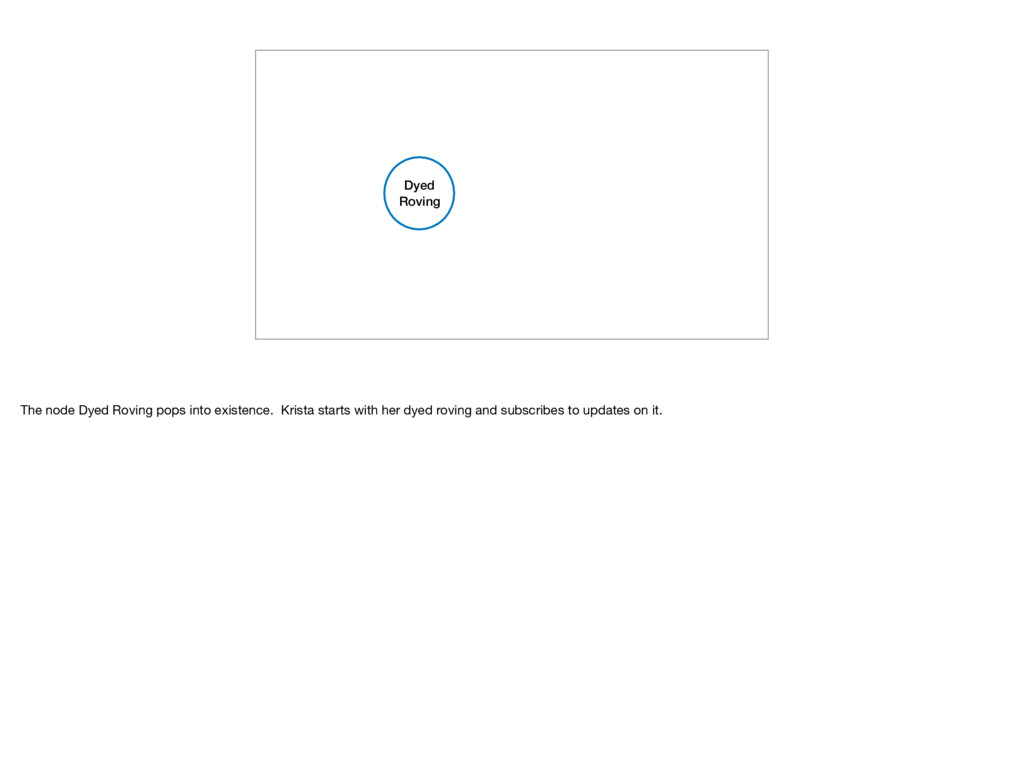
the graph as it is updated • The Problem: • Don’t want to send the whole graph every single time it’s updated • The Solution: • Store the previously sent graph on the socket So far I’ve shown a basic CRUD API, it doesn’t do anything real time. By using Phoenix sockets we can let people subscribe to only receiving updates to the graph instead having to hit the API to get the entire graph each and every time. For instance, Krista is a dyer and wants to see what project people make from her dyed roving that they purchased from her Etsy store. By subscribing to graph updates on her dyed roving’s id, she can see the projects created when knitters link their projects in to the graph. She can use it connect with knitters on her Instagram account or contact those users about new available color ways and dye lots. So we want to see changes to the graph as it is updated but we don’t want to have to send the whole graph each and every time the graph is updated. The solution is to store the previously sent graph on the socket and compare the differences.
Relationships need a start node and an end node • Monitor when relationships are created The graph topic monitors a specific node id for when its graph grows. Because individual nodes are created before the relationships, the graph can only grow when a relationship is created, so we only need to monitor when relationships are created and not when nodes are created.
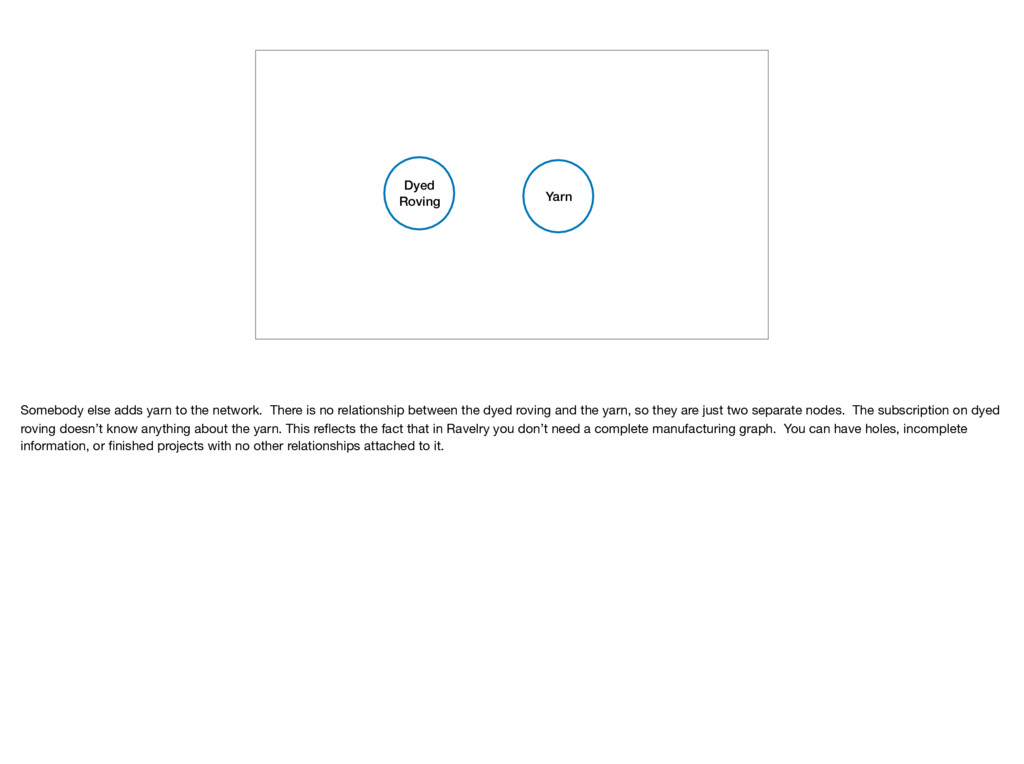
There is no relationship between the dyed roving and the yarn, so they are just two separate nodes. The subscription on dyed roving doesn’t know anything about the yarn. This reflects the fact that in Ravelry you don’t need a complete manufacturing graph. You can have holes, incomplete information, or finished projects with no other relationships attached to it.
yarn marks Krista’s dyed roving as material for her yarn, which creates the relationship between the dyed roving and the finished yarn. It is this relationship that expands the graph for dyed roving. It’s only relationship creation that updates the graph, creation of individual nodes doesn’t signal updates for the graph.
socket = %Phoenix.Socket{ assigns: %{node_id_set: node_id_set, relationship_id_set: relationship_id_set}}) do # !!...Calculate filtered graph!!... push socket, event, filtered_graph new_socket = socket !|> assign(:node_id_set, new_node_id_set) !|> assign(:relationship_id_set, new_relationship_id_set) {:noreply, new_socket} end Because we only want to show updates, we need to keep track on the socket of previously pushed nodes and relationships, using node id set and relationship id set. Every time a graph update event is broadcast, we intercept it and handle_out calculates the difference between the previously seen id set and the new id set for the whole graph. The nodes and relationships get filtered down to those with new ids, which then get pushed out. The full set of node and relationship ids from the current graph then are stored on the socket for any future broadcasts. This way each time we receive a broadcast, we only send the diff. This is done on a per-socket basis, so any user using multiple sockets will receive the whole graph on each new socket.
query on start or end node id of relationship 3. Broadcast for each node in graph to that node’s graph id topic The steps for create get expanded from just create the Repo, to doing the old create followed immediately by a graph query on start or end node id of the relationship, and then broadcasting for each node in the graph to the node’s graph id topic.
yarn.id, end_node_id: project.id} conn = conn !|> recycle() !|> Plug.Conn.put_private(:bolt_sips_conn, bolt_sips_conn) !|> post("/api/v1/cards", %{user_id: cards_user.id, roving_id: roving.id}) To test these real time updates, we hit multiple controllers to simulate creating relationships over time. Each request to the controller needed us to add Bolt_sips_conn to the controller as, for some reason, it got stripped from the conn. It got manually put back in and worked!
%{ nodes: first_nodes, relationships: _first_relationships } } Also, I found that I couldn’t use assert push because I couldn’t specify the topic when using it. Interpolating the topic didn’t work, giving me a compile error of “cannot invoke remote function project.id inside match” but by instead using assert receive, I was able to get around that problem and still specify the topic.
do type conversions • Remove need to pass Bolt.Sips.Conn everywhere • Query Library • Ecto Query won’t support Cypher keywords So for future work on this, I’d like to turn the basics of what I have into an ecto adapter for neo4j. I think it’s really close to that at this point and it would make using Neo4j in an Elixir project a lot easier if we had an adaptor. For the adapter, I’d like to get Ecto Schema to do the type conversions and figure out a way to not need to pass Bolt.Sips.Conn everywhere like I’m doing now. I’d also like to make some sort of query library for this, as Ecto isn’t going to support cypher keywords anytime soon.
• Cypher Refcard • neo4j.com/docs/cypher-refcard/current • GraphConnect • graphconnect.com Here are a few resources I used for this talk: The O’Reilly Graph Databases book is really thorough and is available as a free download on the Neo4j site. The cypher reference card also came in handy, as it has a brief explanation of everything cypher can do and it made writing the cypher easier to do. Also, if you want to learn a lot more about Neo4j, there’s Graph Connect, a conference in New York City next month hosted by Neo4j, and I’m going too!
Imhoff @kronicdeth I’d like to thank a few people for helping me out: - Florin for writing and maintaining bolt sips, writing so much documentation, and for making a few pull requests and fixing stuff in the Elixir Ravelry project. - Car-een, the neo4j community manager, for the stickers and swag I was able to bring here. - And Luke, my husband, for technical help but for also watching our son so I could work on this talk and project.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_27.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_28.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_29.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_30.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_31.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_32.jpg){kind=link}
![Cypher Query MATCH (p:User)-[:OWNS]->(y:Yarn)-[*]-(q:User) WHERE p.name = ‘Bob' AND y.name](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![defmacro !__using!__([]) do quote do alias ElixirRavelry.Repo def get(conn, id)](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_42.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![defp graph_optional_match("forward", options) do "OPTIONAL MATCH forward = (n)-[forward_relationship*0!..]!->(sink!#{forward_type(options)})" end](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_49.jpg){kind=link}
![defp graph_optional_match("forward", options) do "OPTIONAL MATCH forward = (n)-[forward_relationship*0!..]!->(sink!#{forward_type(options)})" end](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![intercept ["graph_update"] def handle_out(event = "graph_update", %{nodes: nodes, relationships: relationships},](https://files.speakerdeck.com/presentations/de3a19fc1f4e4e64a9c023e08f3f8186/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}