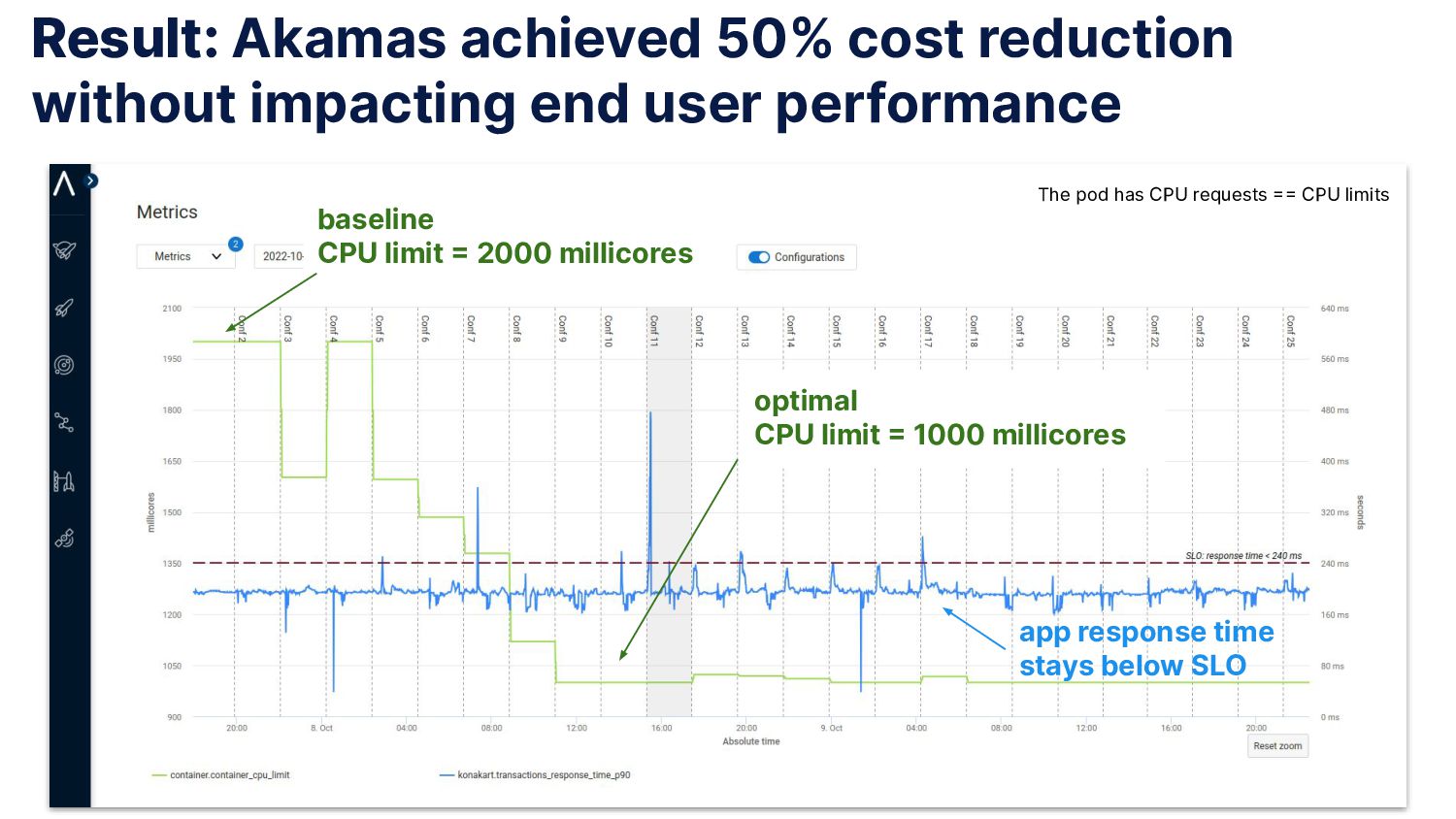
How you can use AI to optimize Kubernetes workloads to reduce resources and costs without impacting application performance and reliability. Identify the workload optimal configurations in terms of CPU and memory resources (requests and limits) and HPA scaling thresholds.
Akamas Lightning talk at KubeCon NA 2023
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
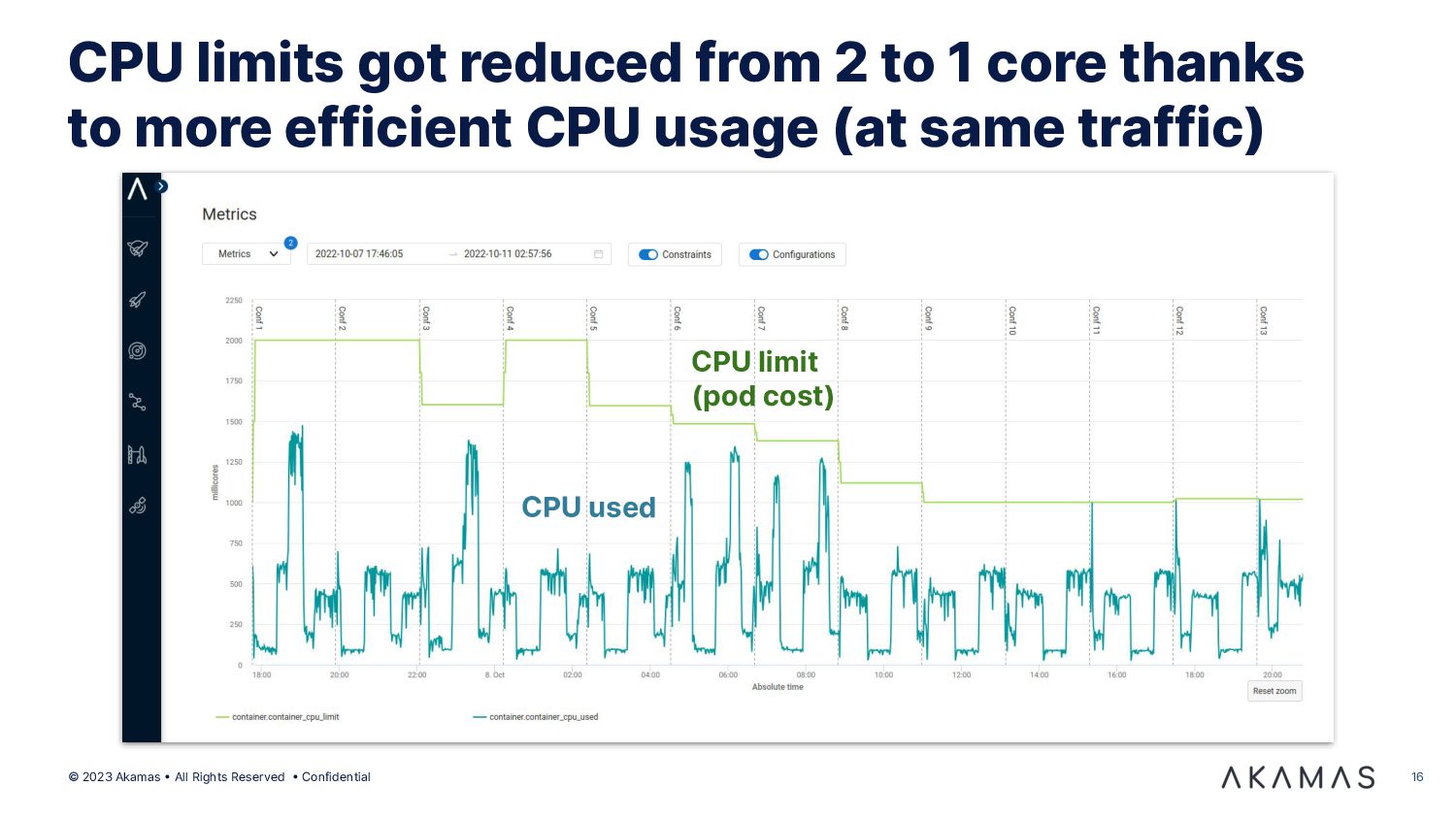{kind=link}
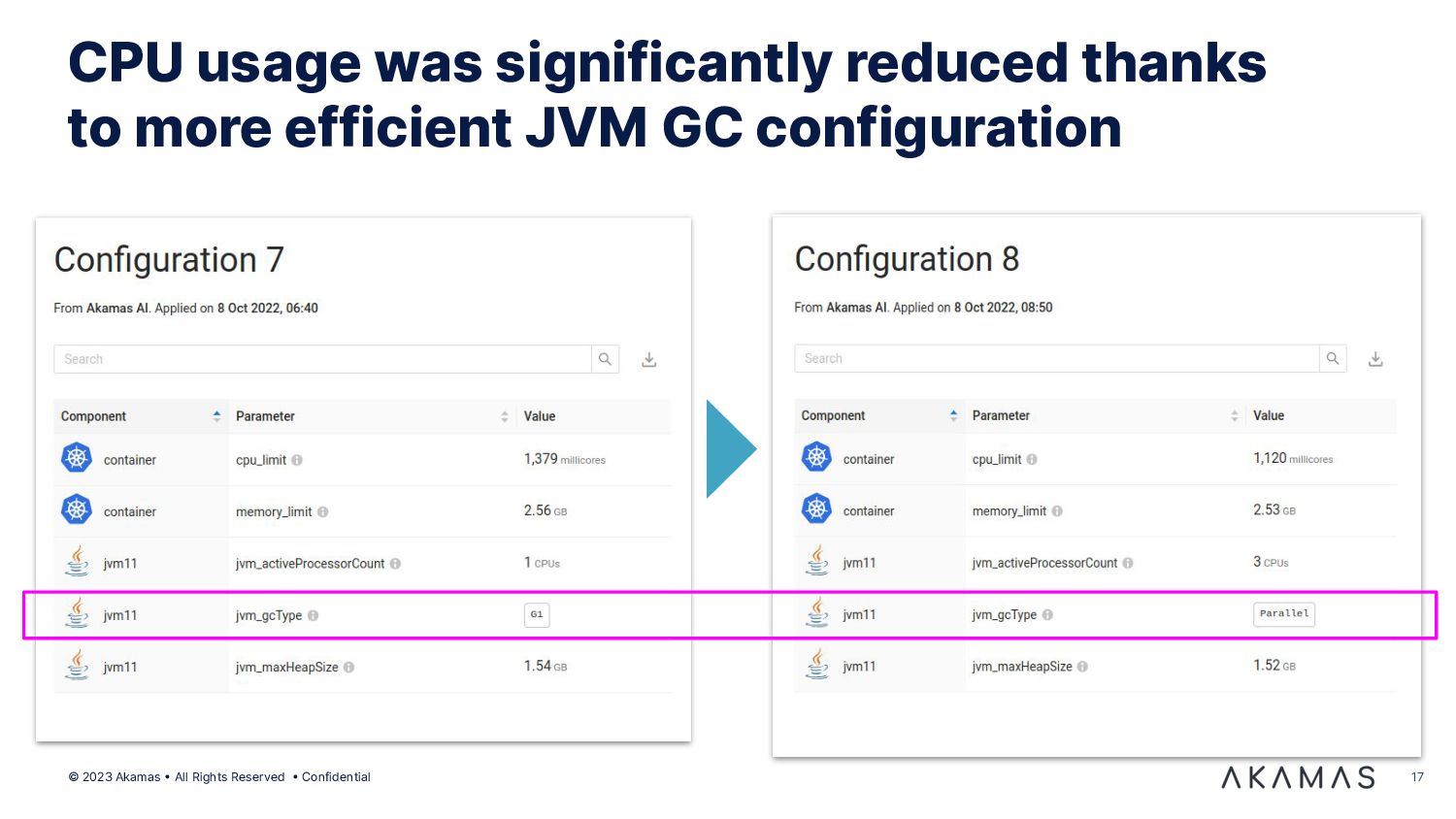{kind=link}
{kind=link}
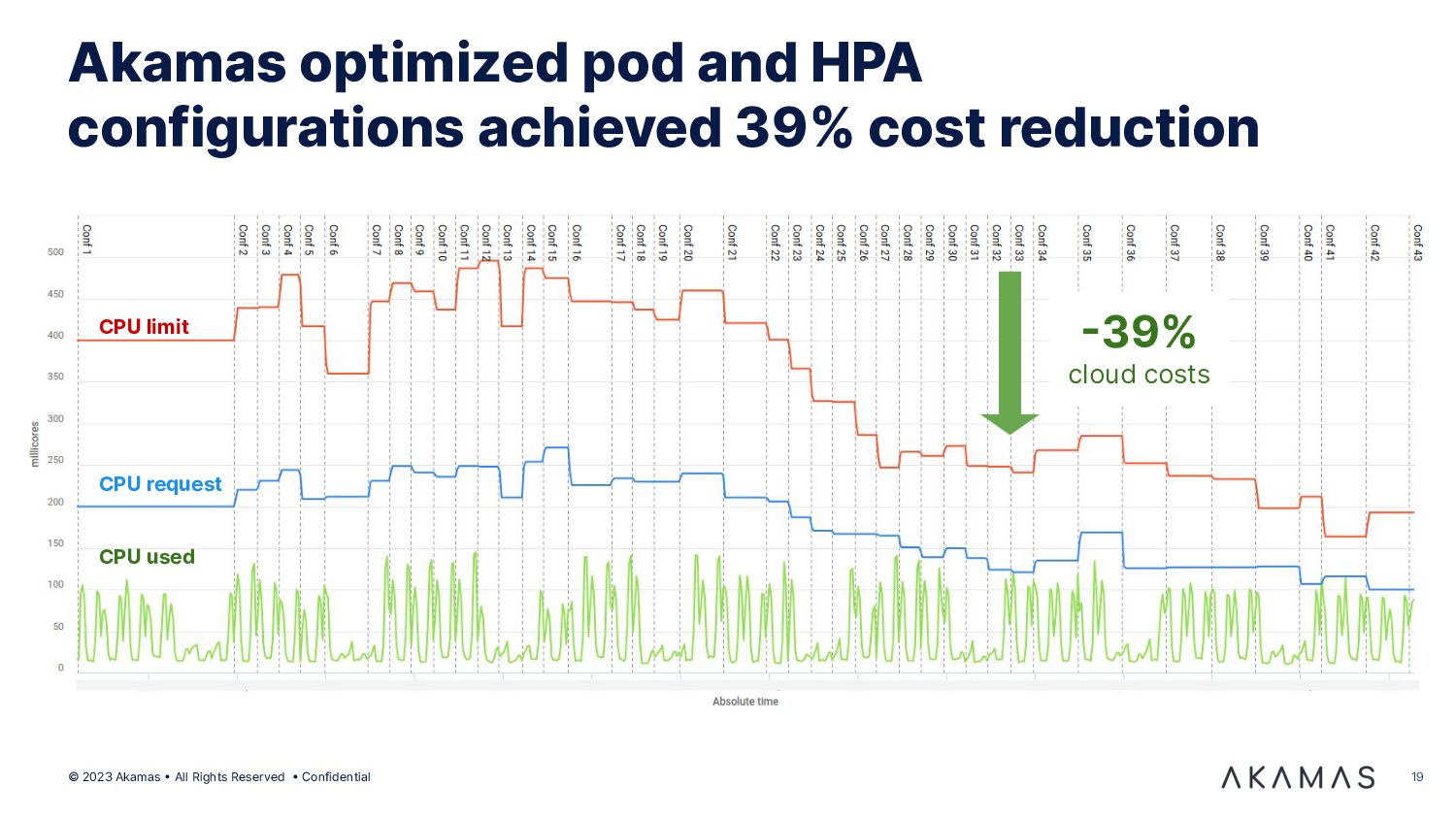{kind=link}
{kind=link}
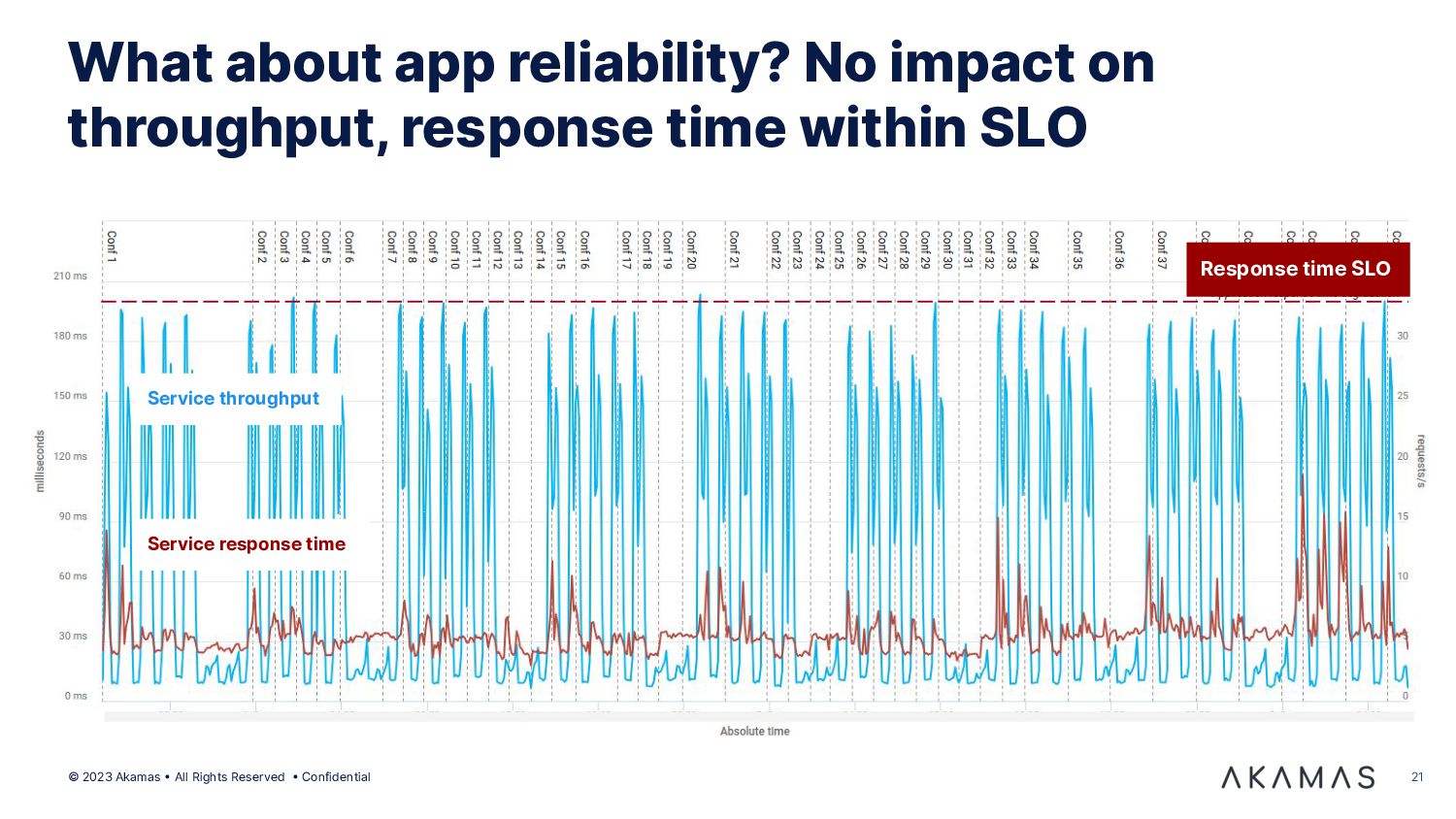{kind=link}
{kind=link}
![Contacts [email protected] @AkamasLabs @akamaslabs Italy HQ Via Schiaffino 11 Milan,](https://files.speakerdeck.com/presentations/086b91d5f7f742359d8da2eed1580bd2/slide_22.jpg){kind=link}