Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
深層強化学習で東方AI 第一章 DQNの基本
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Ryosuke Uchiyama
October 07, 2021
Technology
300
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
深層強化学習で東方AI 第一章 DQNの基本
Ryosuke Uchiyama
October 07, 2021
More Decks by Ryosuke Uchiyama
See All by Ryosuke Uchiyama
AWSでサーバレスな書籍管理アプリを作る
step63r
0
58
PythonでSlack通知botを作る
step63r
0
22
ChatGPT実践
step63r
1
380
IoT実践! 行先予定表を電子ペーパーで作る
step63r
0
31
React x Socket.ioで人狼サーバを作る 第一章 フロントエンド実装
step63r
0
25
Build 2021 プレイバック
step63r
0
38
WPFで実践アプリ開発! 第四章 機能の実装 Part 2
step63r
0
53
WPFで実践アプリ開発! 第三章 機能の実装 Part 1
step63r
0
130
WPFで実践アプリ開発! 第二章 UI
step63r
0
170
Other Decks in Technology
See All in Technology
_NIKKEI_Tech_Talk__勉強会は熱量では続かない___17回続いた輪読会の設計術.pdf
_awache
1
100
VPCセキュリティ対応の最新事情
nagisa53
1
240
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
880
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
110
kaonavi Tech Night#1
kaonavi
0
150
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
2026年のソフトウェア開発を考える(2026/07版) / Agentic Software Engineering 2026-07 Findy Edition
twada
PRO
24
10k
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
750
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
2
530
キャリアLT会#3
beli68
2
230
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
480
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
How to Ace a Technical Interview
jacobian
281
24k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
The World Runs on Bad Software
bkeepers
PRO
72
12k
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
Paper Plane (Part 1)
katiecoart
PRO
1
9.8k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Side Projects
sachag
455
43k
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Transcript
深層強化学習で東方AI 第一章 DQNの基本 Ryosuke Uchiyama step63r
深層強化学習について
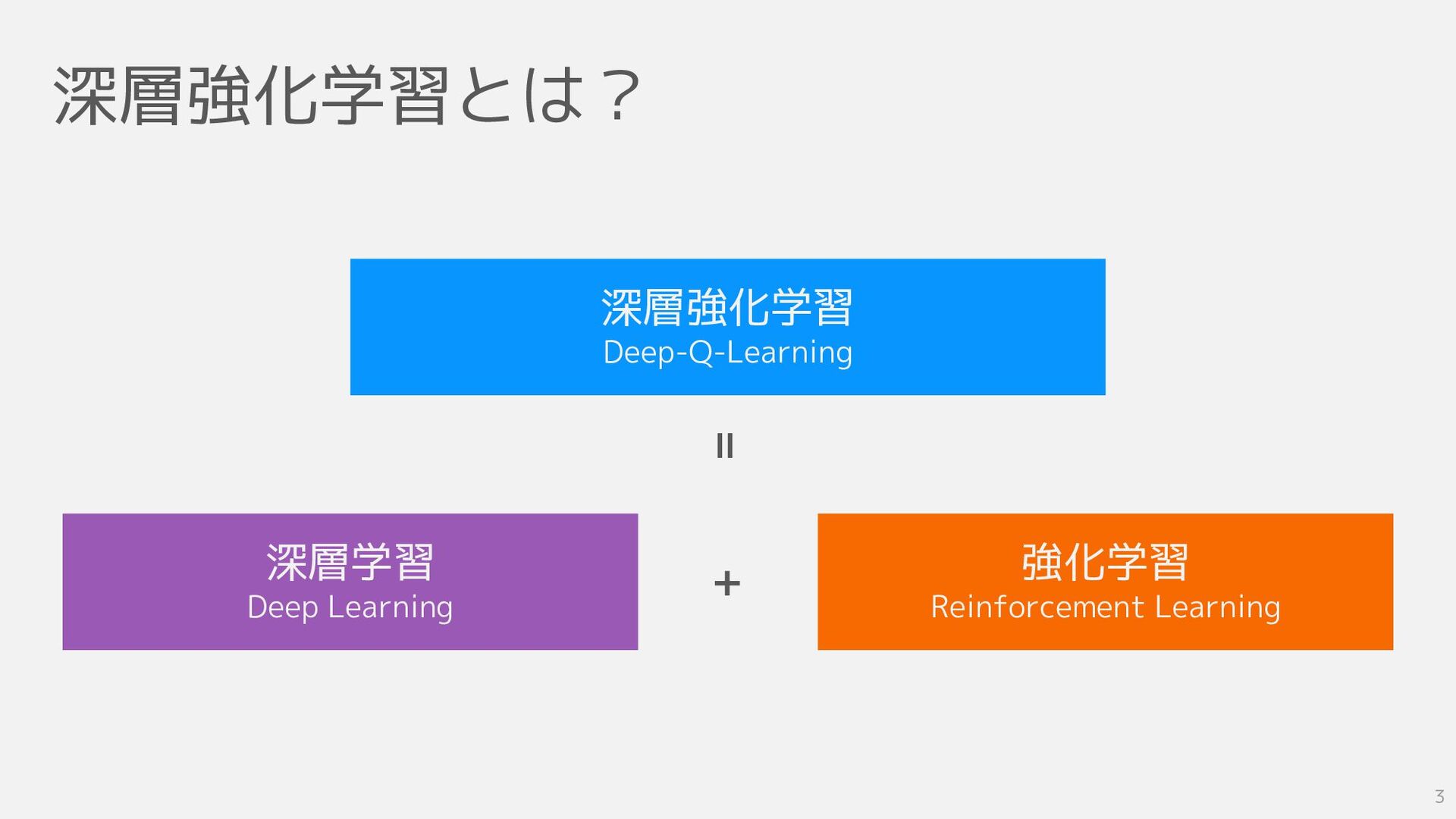
深層強化学習とは? 深層強化学習 Deep-Q-Learning 深層学習 Deep Learning = + 強化学習 Reinforcement
Learning 3
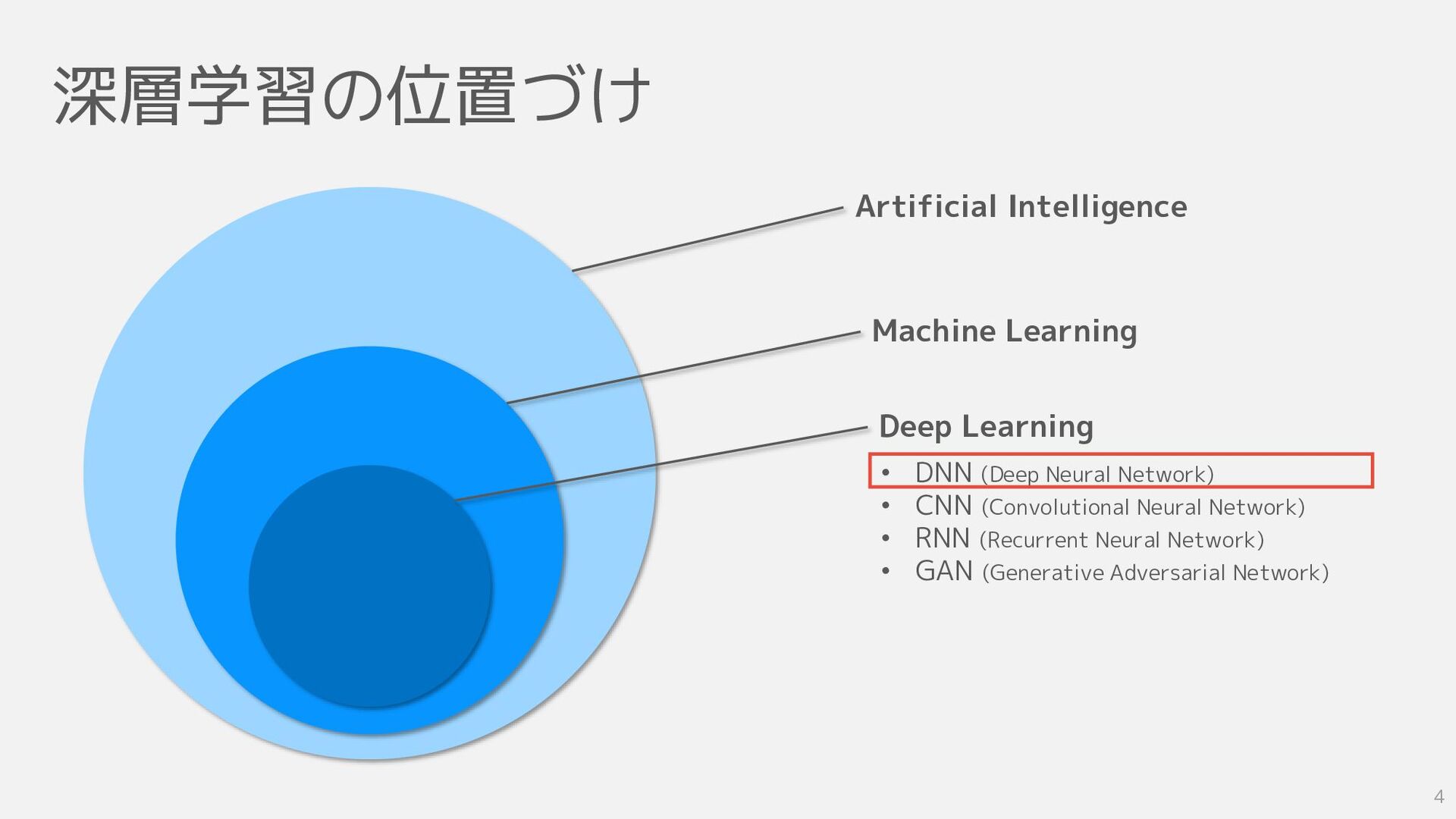
深層学習の位置づけ Artificial Intelligence Machine Learning Deep Learning • DNN (Deep
Neural Network) • CNN (Convolutional Neural Network) • RNN (Recurrent Neural Network) • GAN (Generative Adversarial Network) 4
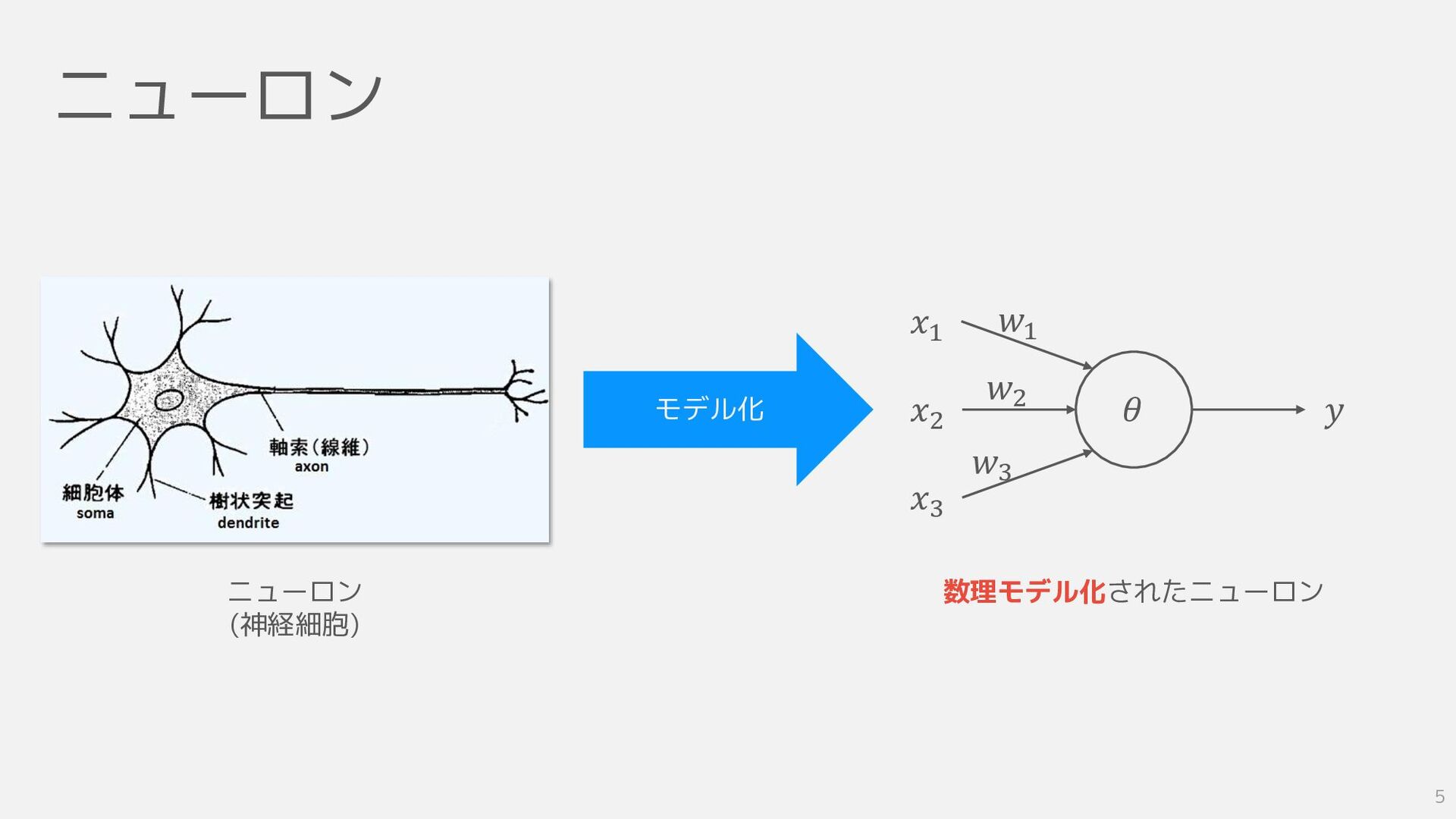
ニューロン ニューロン (神経細胞) モデル化 𝜃 𝑦 𝑥2 𝑥1 𝑥3 𝑤2
𝑤1 𝑤3 数理モデル化されたニューロン 5
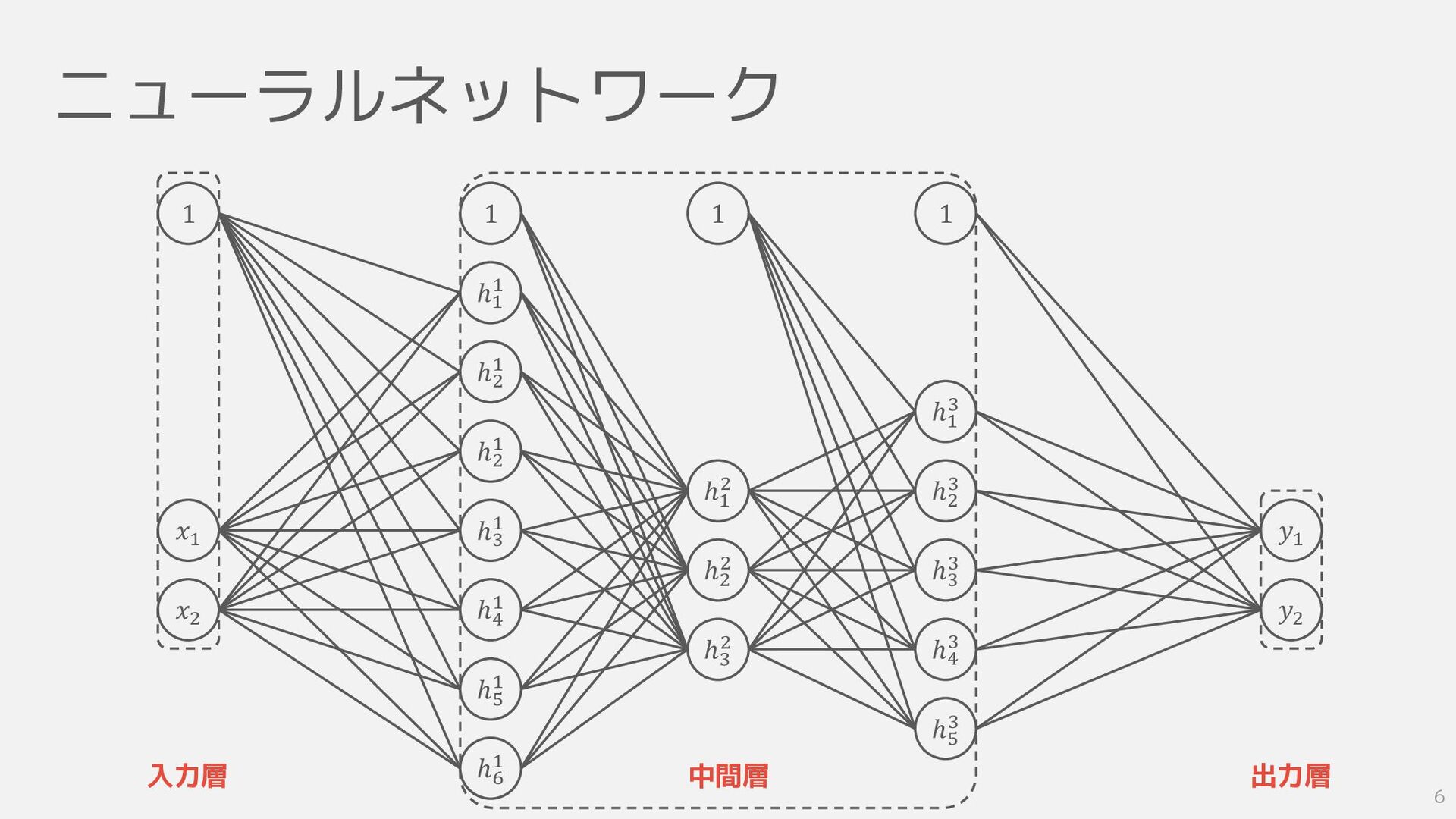
ニューラルネットワーク 1 ℎ1 1 ℎ2 1 ℎ2 1 ℎ3 1
ℎ4 1 ℎ5 1 ℎ6 1 1 1 ℎ2 2 ℎ1 2 ℎ3 2 ℎ3 3 ℎ2 3 ℎ4 3 ℎ1 3 ℎ5 3 𝑥1 𝑥2 𝑦1 𝑦2 1 入力層 中間層 出力層 6
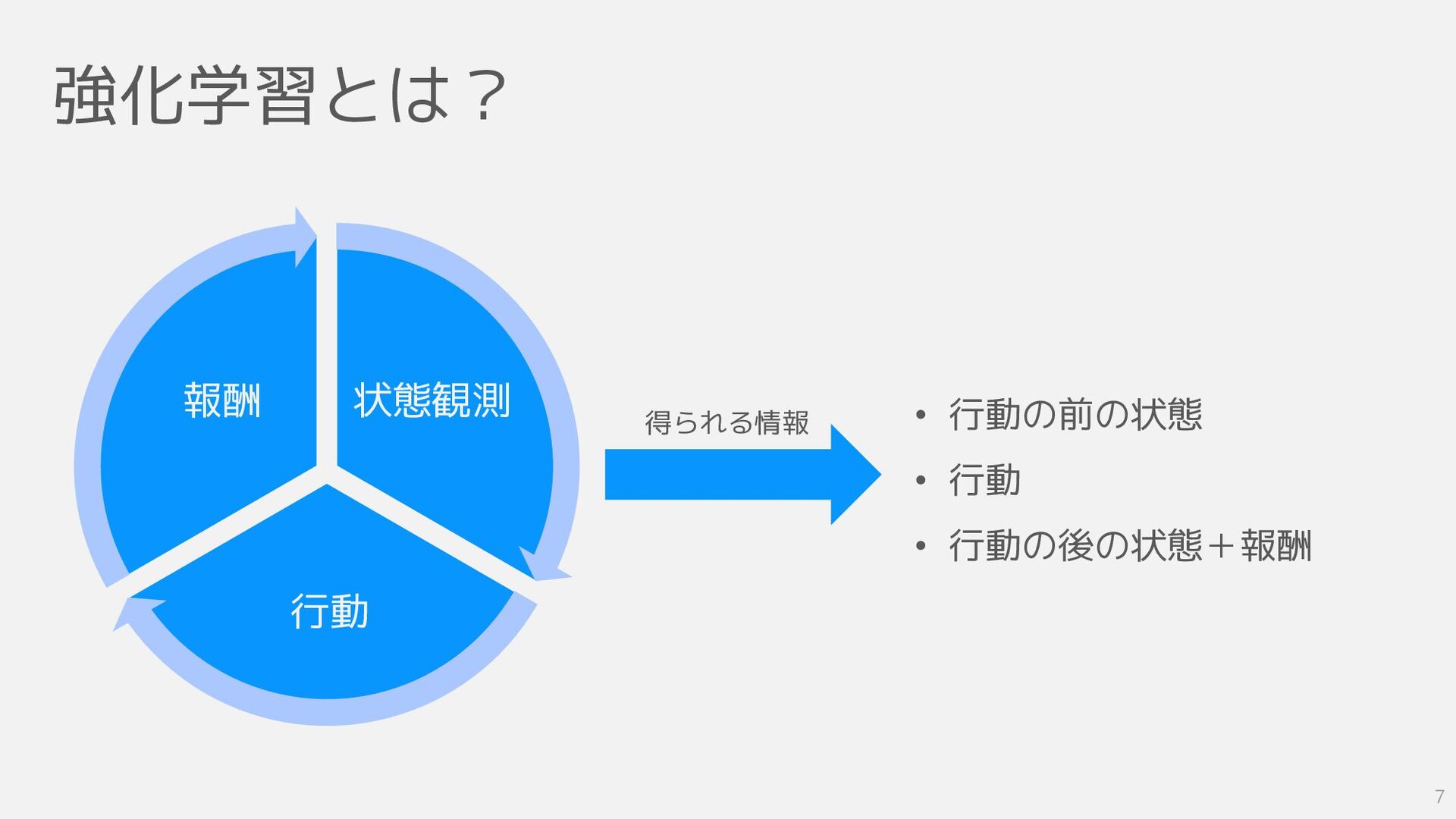
強化学習とは? 状態観測 行動 報酬 得られる情報 • 行動の前の状態 • 行動 •
行動の後の状態+報酬 7
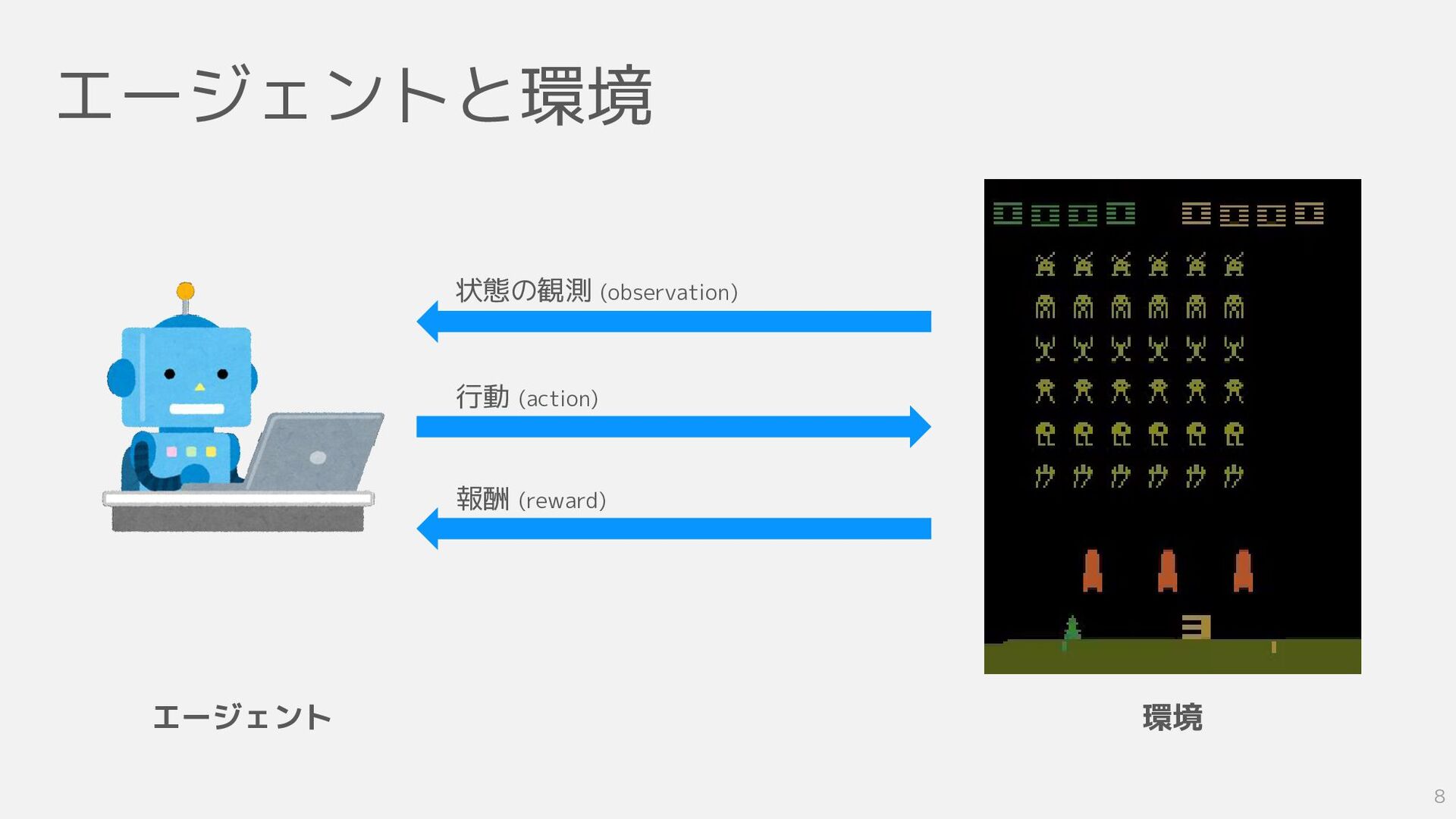
エージェントと環境 環境 エージェント 状態の観測 (observation) 行動 (action) 報酬 (reward) 8
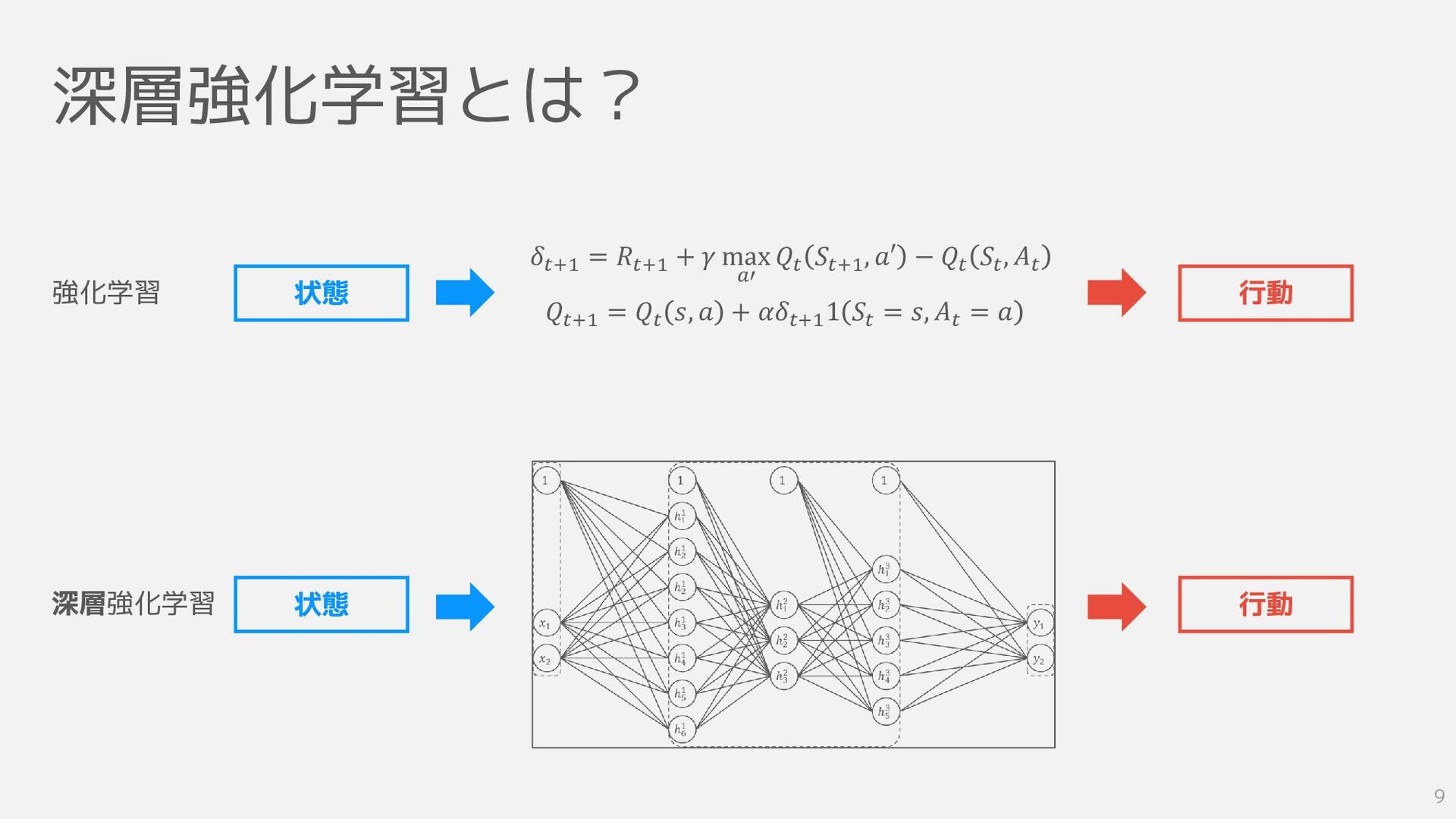
深層強化学習とは? 強化学習 深層強化学習 状態 状態 行動 行動 𝛿𝑡+1 = 𝑅𝑡+1
+ 𝛾 max 𝑎′ 𝑄𝑡 𝑆𝑡+1 , 𝑎′ − 𝑄𝑡 𝑆𝑡 , 𝐴𝑡 𝑄𝑡+1 = 𝑄𝑡 𝑠, 𝑎 + 𝛼𝛿𝑡+1 1 𝑆𝑡 = 𝑠, 𝐴𝑡 = 𝑎 9
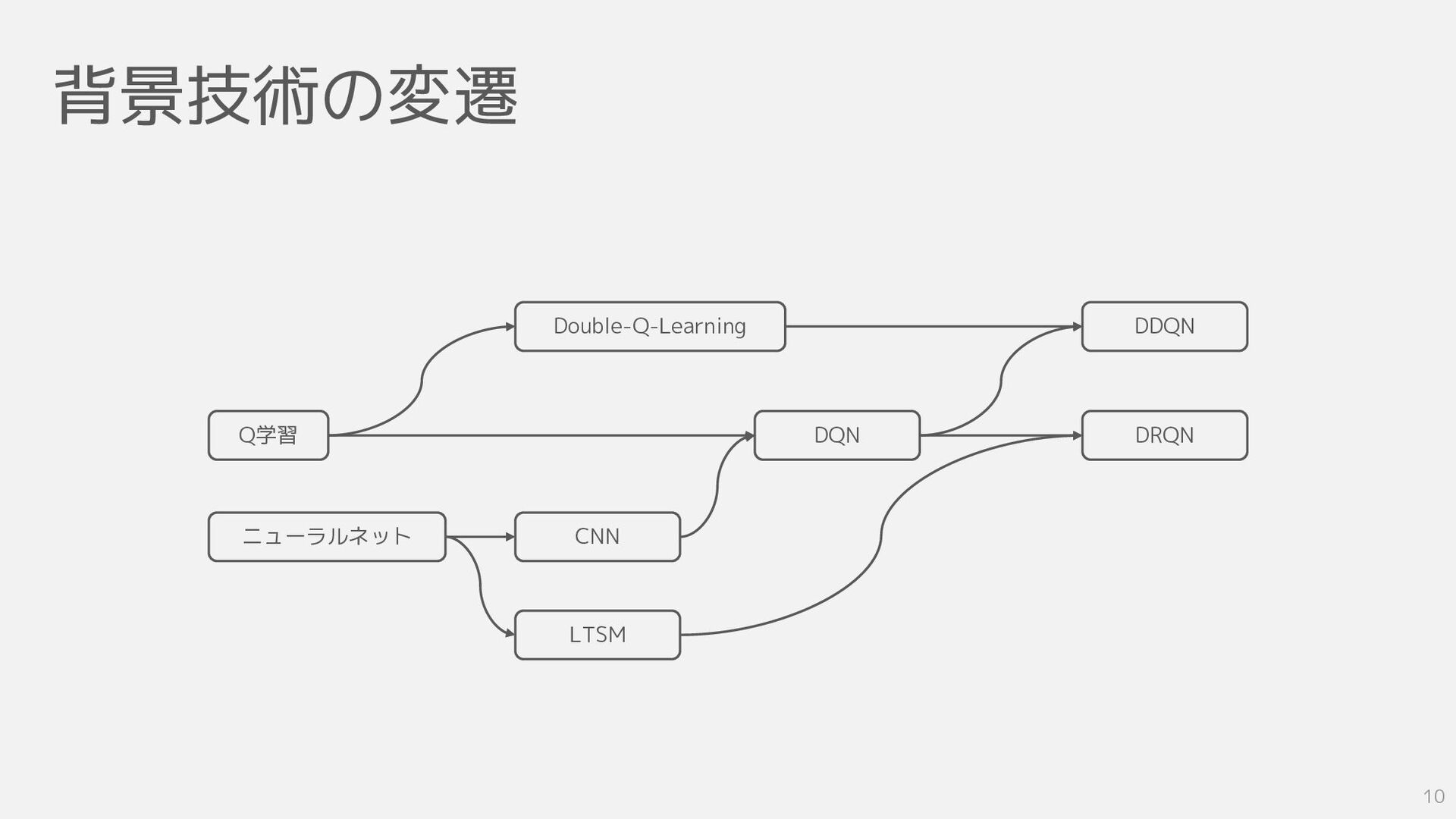
背景技術の変遷 10 Q学習 ニューラルネット CNN LTSM DQN Double-Q-Learning DRQN DDQN
Demo OpenAI Gym攻略
OpenAI Gym 12 あらゆる環境を統一インターフェイスで操作するための強化学習ツールキット http://gym.openai.com/envs/ カテゴリ 内容 Algorithms 文字列の入力と出力から、それを実現するアルゴリズムを学習する環境 Atari
Atariゲームのスコアを競う環境 Box2D 2D物理エンジンで開発された連続的な制御タスクを行う環境 Classic Control 強化学習の教科書に登場するさまざまな古典的な制御タスクを行う環境 MuJoCo 3D物理エンジンで開発された連続的な制御タスクを行う環境 Robotics ロボットアームやロボットハンドなどの環境 Toy text 単純なテキストベースの古典的タスクを行う環境 ¥ ¥
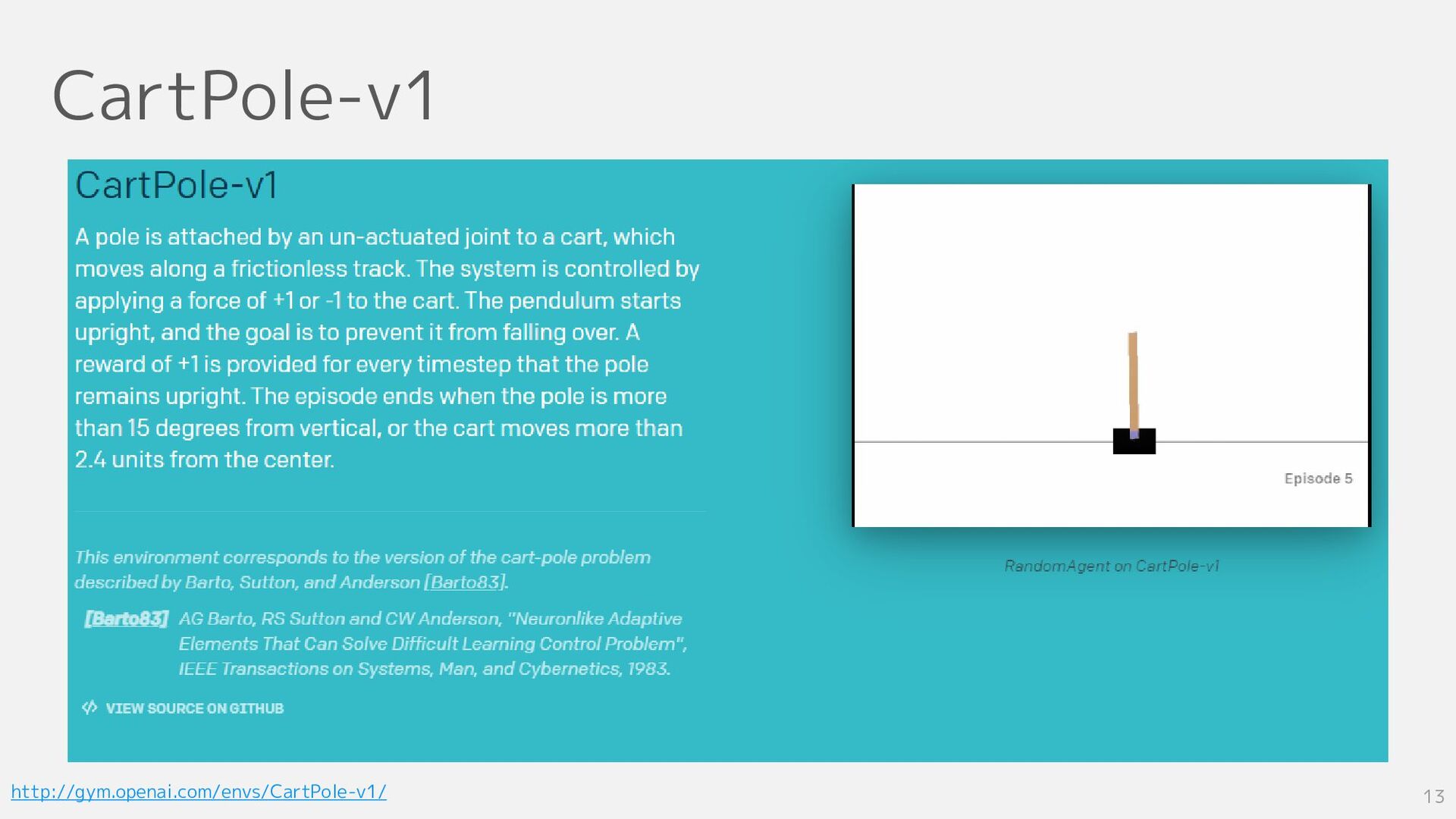
CartPole-v1 13 http://gym.openai.com/envs/CartPole-v1/
環境構築 PS> C:¥Users¥[yourname]¥AppData¥Local¥Programs¥Python¥Python36¥python.exe –m venv .env PS> .¥.env¥Scripts¥activate (.env) PS>
.¥.env¥Scripts¥python.exe –m pip install --upgrade pip (.env) PS> pip install gym==0.19.0 (.env) PS> pip install --no-index –f https://github.com/Kojoley/atari-py/releases atari_py (.env) PS> pip install pyglet (.env) PS> pip install stable-baselines[mpi]==2.10.0 (.env) PS> pip install tensorflow==1.14.0 (.env) PS> pip install pyqt5 (.env) PS> pip install imageio 14 1. Python 3.6.8 をインストールする 2. Visual Studio 2015 C++ ビルドツール をインストールする (VS2017版が入っている場合アンインストールしてから) 3. Microsoft MPI v10.1.2 をインストールする 4. 作業フォルダで以下のコマンドを順に打つ
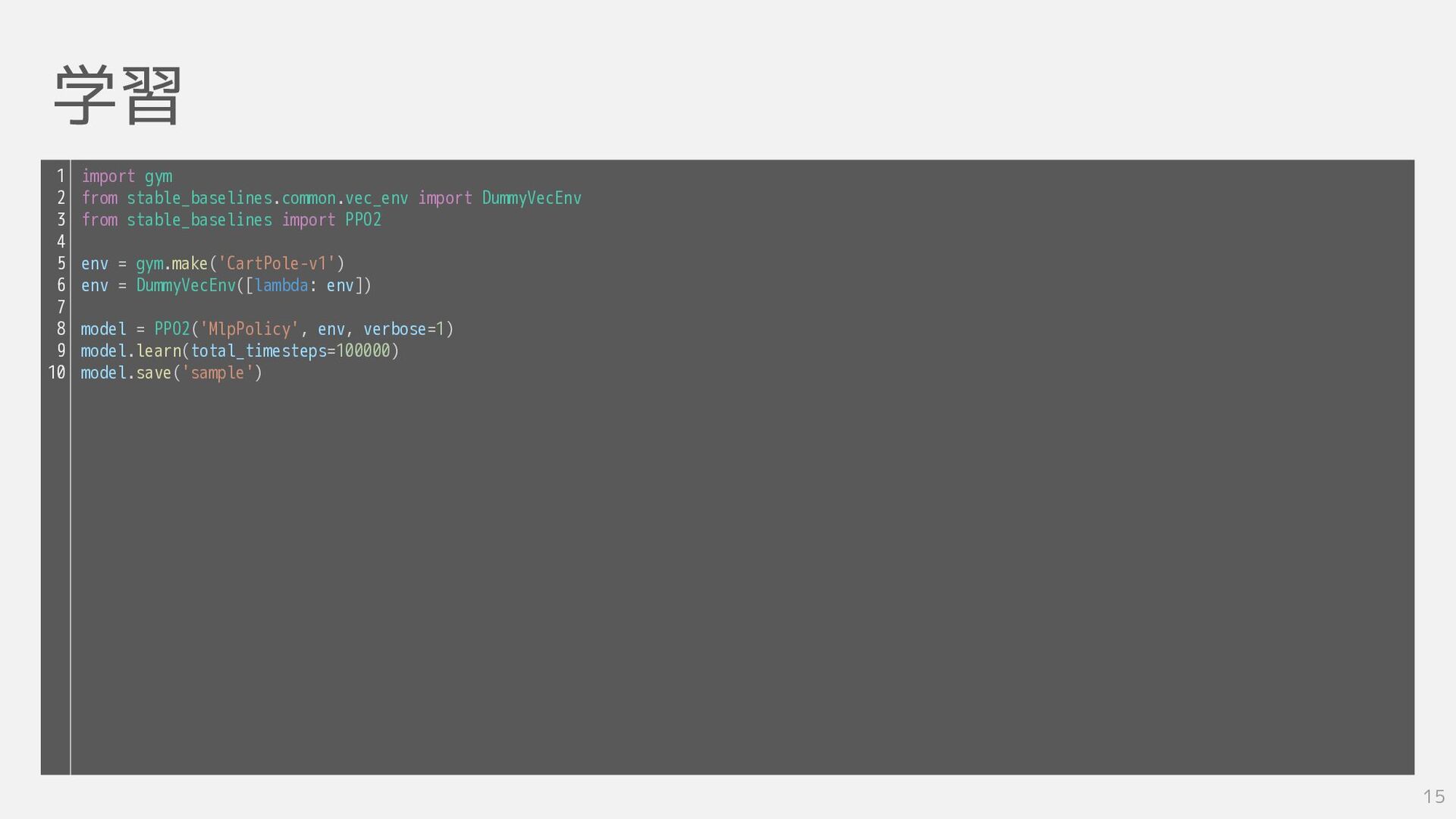
学習 15 import gym from stable_baselines.common.vec_env import DummyVecEnv from stable_baselines
import PPO2 env = gym.make('CartPole-v1') env = DummyVecEnv([lambda: env]) model = PPO2('MlpPolicy', env, verbose=1) model.learn(total_timesteps=100000) model.save('sample') 1 2 3 4 5 6 7 8 9 10
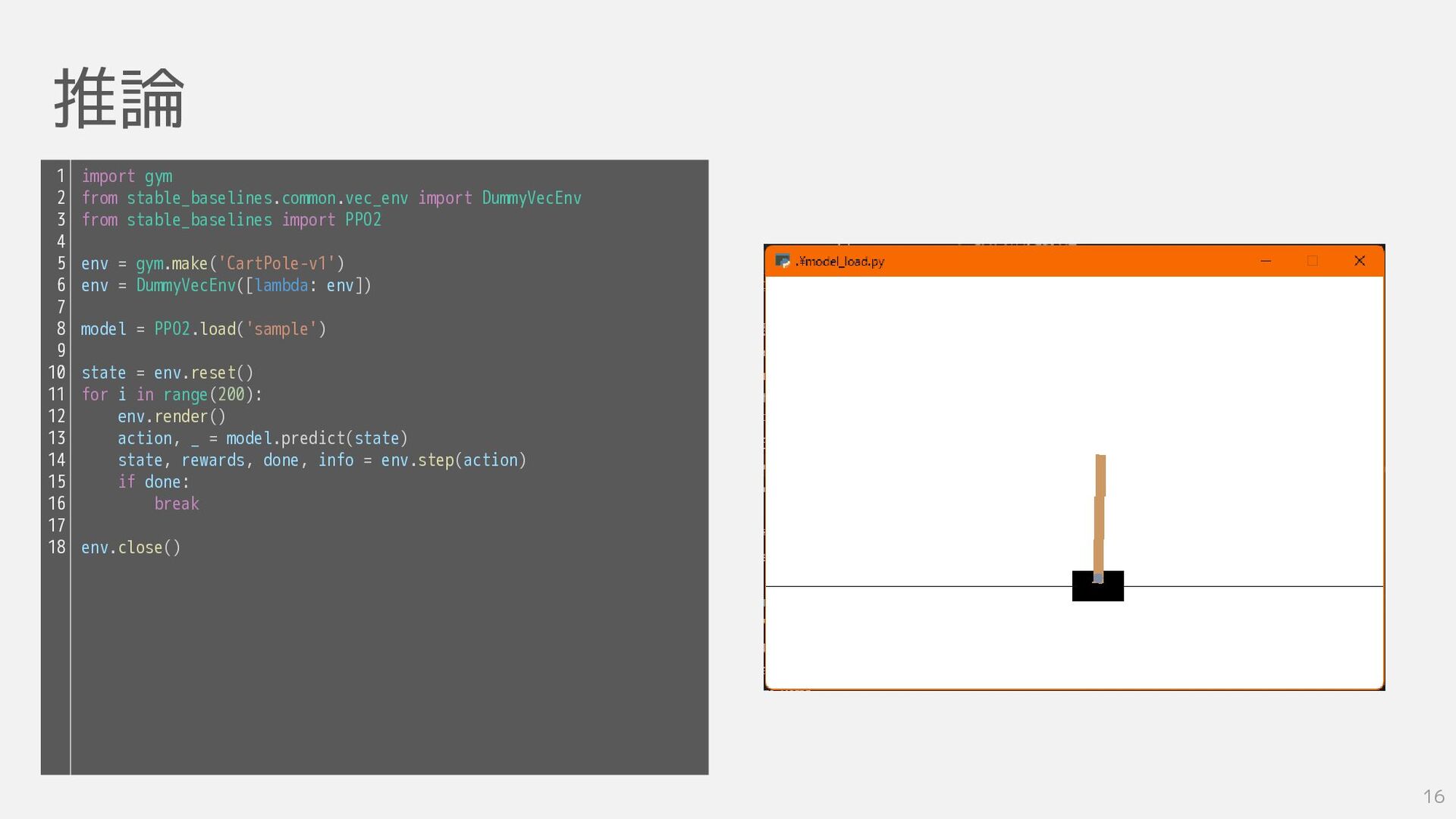
推論 16 import gym from stable_baselines.common.vec_env import DummyVecEnv from stable_baselines
import PPO2 env = gym.make('CartPole-v1') env = DummyVecEnv([lambda: env]) model = PPO2.load('sample') state = env.reset() for i in range(200): env.render() action, _ = model.predict(state) state, rewards, done, info = env.step(action) if done: break env.close() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
Demo Atari攻略
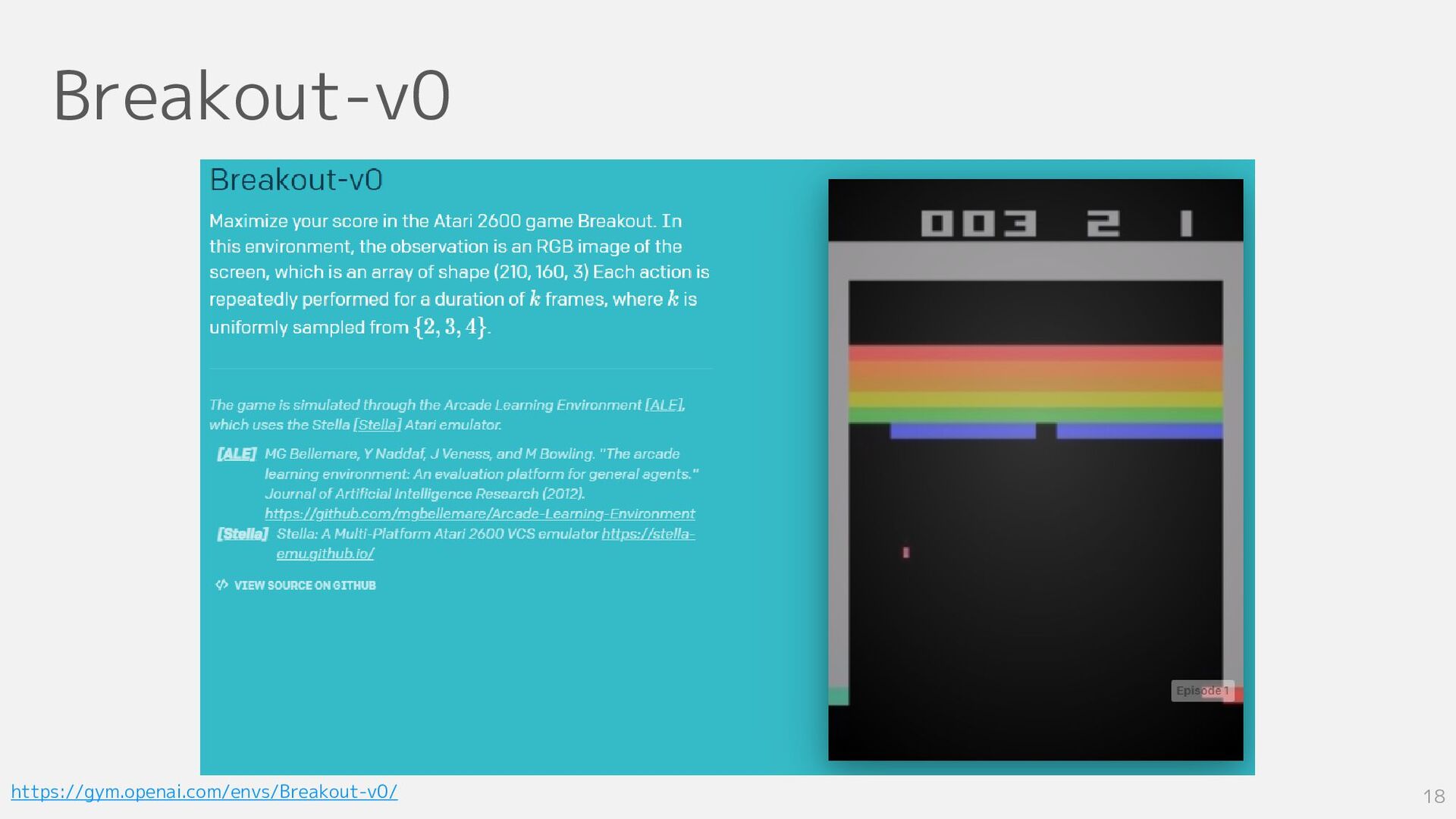
Breakout-v0 18 https://gym.openai.com/envs/Breakout-v0/
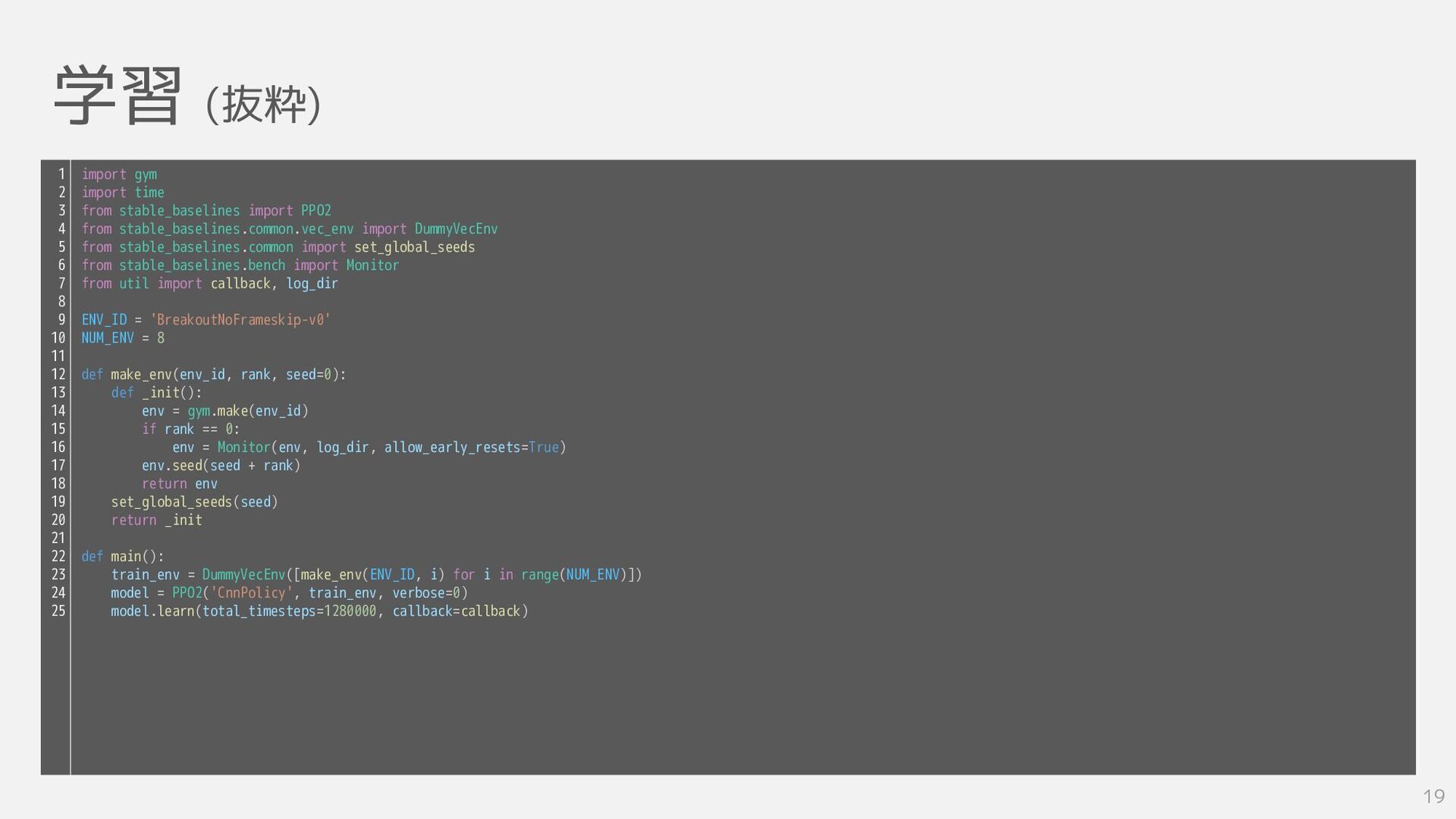
学習 (抜粋) 19 import gym import time from stable_baselines import
PPO2 from stable_baselines.common.vec_env import DummyVecEnv from stable_baselines.common import set_global_seeds from stable_baselines.bench import Monitor from util import callback, log_dir ENV_ID = 'BreakoutNoFrameskip-v0' NUM_ENV = 8 def make_env(env_id, rank, seed=0): def _init(): env = gym.make(env_id) if rank == 0: env = Monitor(env, log_dir, allow_early_resets=True) env.seed(seed + rank) return env set_global_seeds(seed) return _init def main(): train_env = DummyVecEnv([make_env(ENV_ID, i) for i in range(NUM_ENV)]) model = PPO2('CnnPolicy', train_env, verbose=0) model.learn(total_timesteps=1280000, callback=callback) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
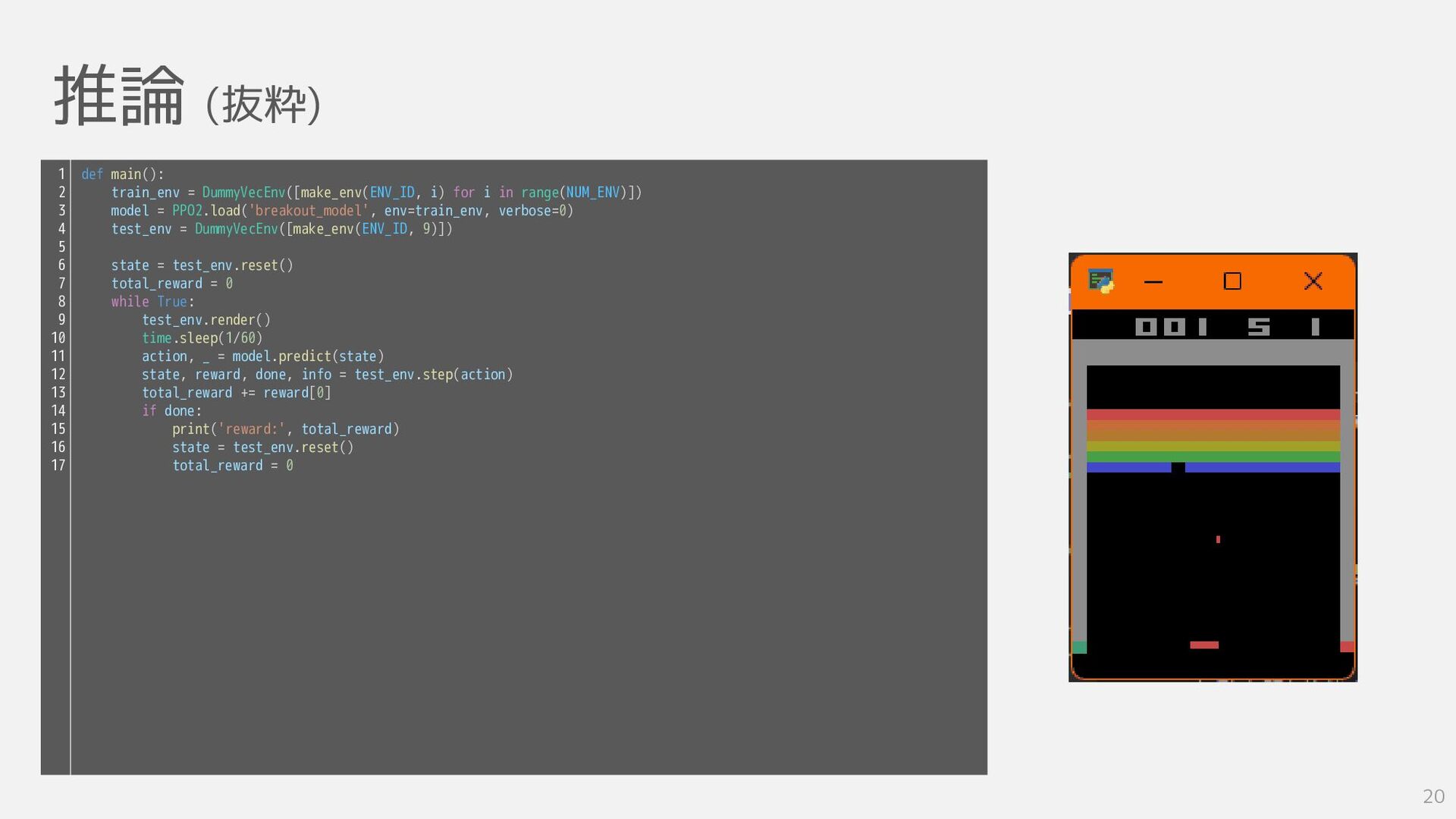
推論 (抜粋) 20 def main(): train_env = DummyVecEnv([make_env(ENV_ID, i) for
i in range(NUM_ENV)]) model = PPO2.load('breakout_model', env=train_env, verbose=0) test_env = DummyVecEnv([make_env(ENV_ID, 9)]) state = test_env.reset() total_reward = 0 while True: test_env.render() time.sleep(1/60) action, _ = model.predict(state) state, reward, done, info = test_env.step(action) total_reward += reward[0] if done: print('reward:', total_reward) state = test_env.reset() total_reward = 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
精度改善(1) 前処理 21 Atariラッパー 内容 NoopResetEnv ゲーム開始の初期状態にバラツキを与える FireResetEnv 環境リセット後の初回動作を "FIRE"
とし強制的にゲームを開始する MaxAndSkipEnv 4フレームごとに行動を選択し、4フレーム連続で同じ行動を採るようにする ClipRewardEnv 各ステップで獲得する報酬を [-1, 0, 1] にクリッピングする WarpFrame 画面イメージを 84x84 のグレースケールに変換する FrameStack 直近4フレームの画面イメージを環境の状態として利用する ScaledFloatFrame 環境の状態を 255.0 で割って正規化する EpisodicLifeEnv ライフを持つAtari環境で、1ライフ減ったときエピソード完了とする Commonラッパー 内容 ClipActionsWrapper 行動空間の low と high で行動をクリッピングする TimeLimit 1エピソードの最大ステップ数を指定する VecEnvラッパー 内容 VecNormalize 状態と報酬を正規化するために、移動平均と標準偏差を計算する VecFrameStack 連続した複数の状態をスタックする
精度改善(2) ハイパーパラメータ調整 22 ハイパーパラメータ PPO2の引数 内容 Horizon n_steps 方策更新前に収集する経験の数(ステップ数) MiniBatch
nminibatches 勾配降下に使うミニバッチのサイズ Epoch noptepochs 収集した経験を勾配降下にかける回数 Clipping parameter (ε) cliprange 旧方策と新方策の比率に対する許容限界 Discount (γ) gamma 将来の報酬割引率 GAE parameter lam GAEのバイアスと分散のトレードオフ 価値関数係数 vf_coef 損失計算の価値関数係数 エントロピー係数 ent_coef 損失計算のエントロピー係数 学習率 lr 勾配降下の初期の学習率
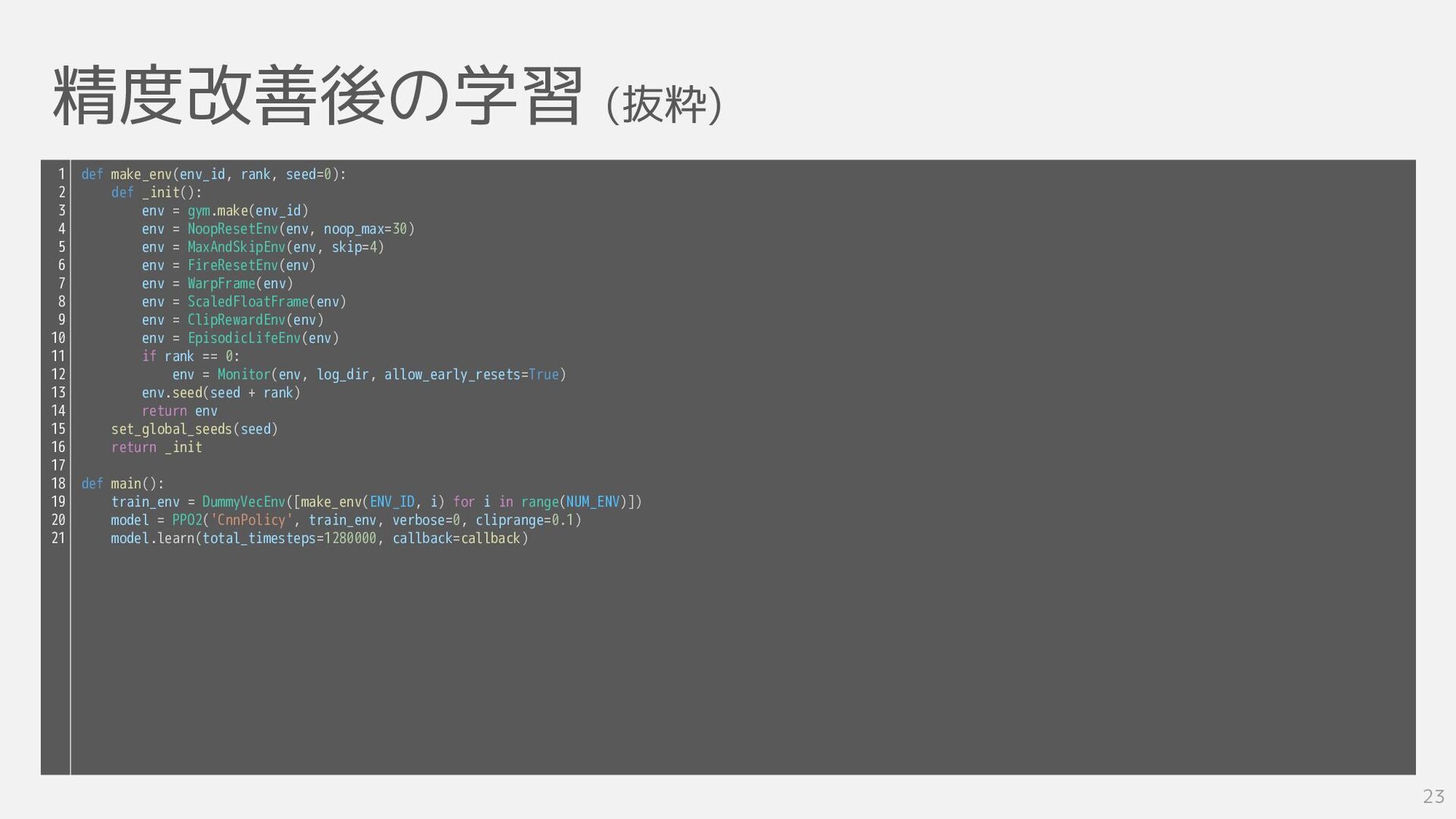
精度改善後の学習 (抜粋) 23 def make_env(env_id, rank, seed=0): def _init(): env
= gym.make(env_id) env = NoopResetEnv(env, noop_max=30) env = MaxAndSkipEnv(env, skip=4) env = FireResetEnv(env) env = WarpFrame(env) env = ScaledFloatFrame(env) env = ClipRewardEnv(env) env = EpisodicLifeEnv(env) if rank == 0: env = Monitor(env, log_dir, allow_early_resets=True) env.seed(seed + rank) return env set_global_seeds(seed) return _init def main(): train_env = DummyVecEnv([make_env(ENV_ID, i) for i in range(NUM_ENV)]) model = PPO2('CnnPolicy', train_env, verbose=0, cliprange=0.1) model.learn(total_timesteps=1280000, callback=callback) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
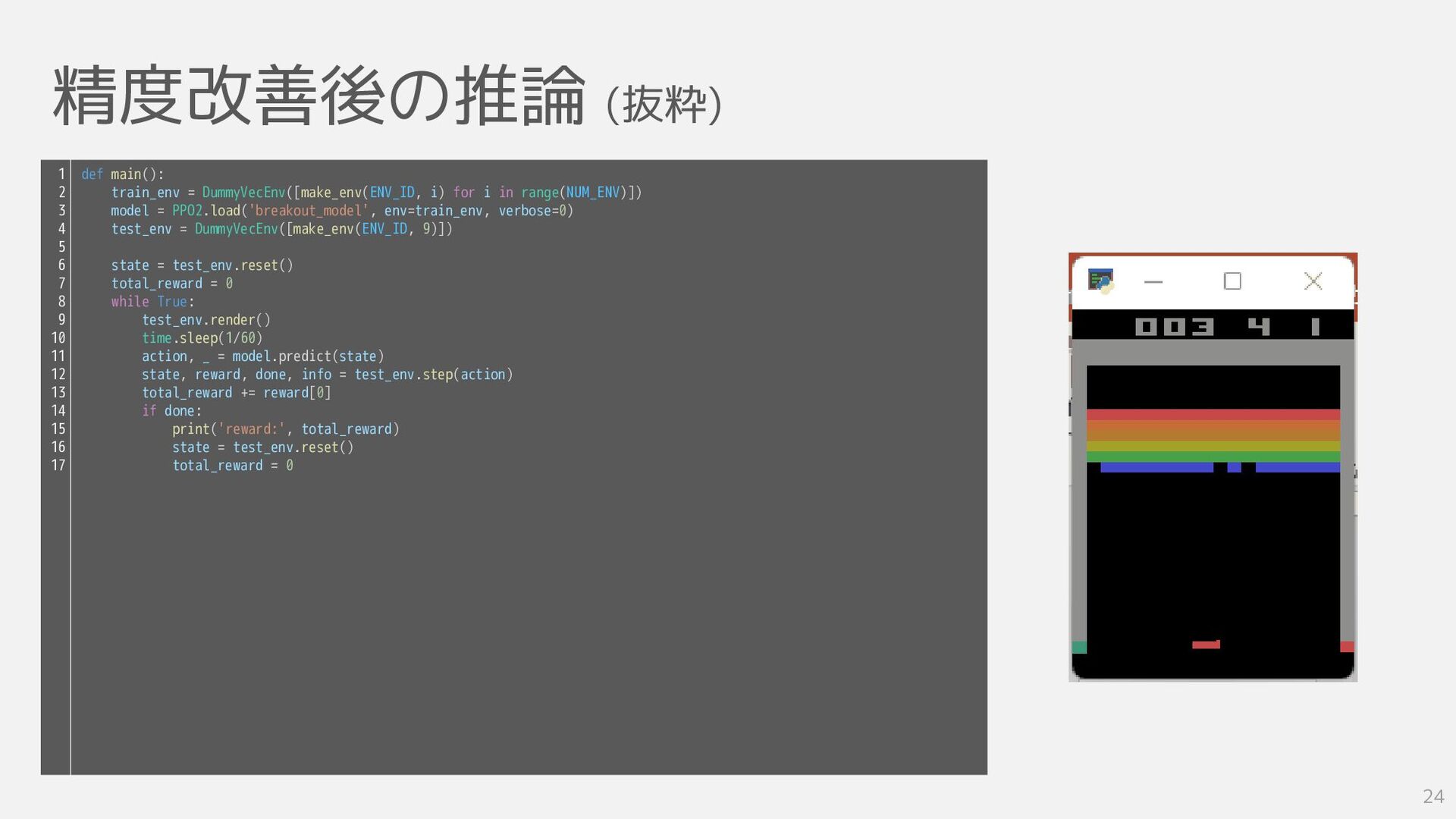
精度改善後の推論 (抜粋) 24 def main(): train_env = DummyVecEnv([make_env(ENV_ID, i) for
i in range(NUM_ENV)]) model = PPO2.load('breakout_model', env=train_env, verbose=0) test_env = DummyVecEnv([make_env(ENV_ID, 9)]) state = test_env.reset() total_reward = 0 while True: test_env.render() time.sleep(1/60) action, _ = model.predict(state) state, reward, done, info = test_env.step(action) total_reward += reward[0] if done: print('reward:', total_reward) state = test_env.reset() total_reward = 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
東方Projectについて
東方Projectとは 26 • ZUN氏が運営する個人サークル「上海アリス幻樂団」によって制作されている、弾幕シューティングゲーム を中心とした作品群 東方Project 25年記念サイト より
東方AIとその歴史 2002 STG AI登場以前 紅魔郷 妖々夢 永夜抄 花映塚 文花帖 風神録
地霊殿 2009 STG AI登場 星蓮船 ダブルスポイラー 2011 知見の公開化 妖精大戦争 神霊廟 輝針城 弾幕アマノジャク 紺珠伝 2016 Deep Learning 天空璋 秘封ナイトメアダイアリー 鬼形獣 虹龍洞 画像処理 ルールベース 機械学習 27
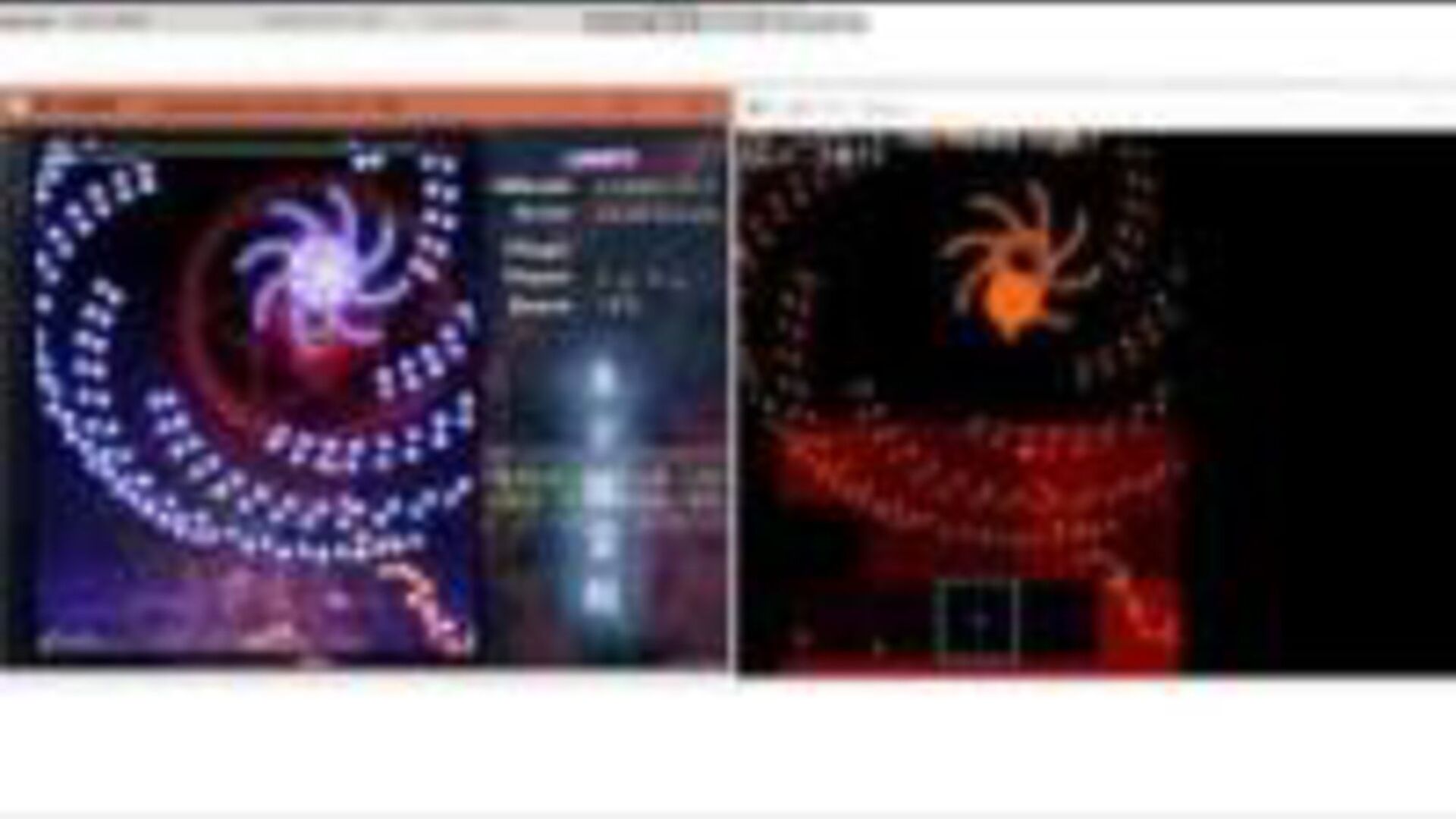
東方地霊殿AI 28
方針
今回の攻略対象 30 ゲームオーバーになっても最初からやり直すことなくプレ イを続行できるモード。 東方紺珠伝 東方Project 第15弾 2015年8月14日 リリース 特徴:完全無欠モード
機械学習にうってつけ!
開発環境 31 • Python 3.9.7 / PyTorch 1.9.1+cu111 / CUDA
11.4 / CuDNN 8.2.4 • クライアントは東方紺珠伝のスクショを撮ってサーバに送信する • クライアント⇔サーバ間はソケット通信 • サーバはクライアントに評価結果(次の行動)を返す • クライアントは評価結果に基づいたキーを押下 • エピソード終了条件を満たすまで以上繰り返し
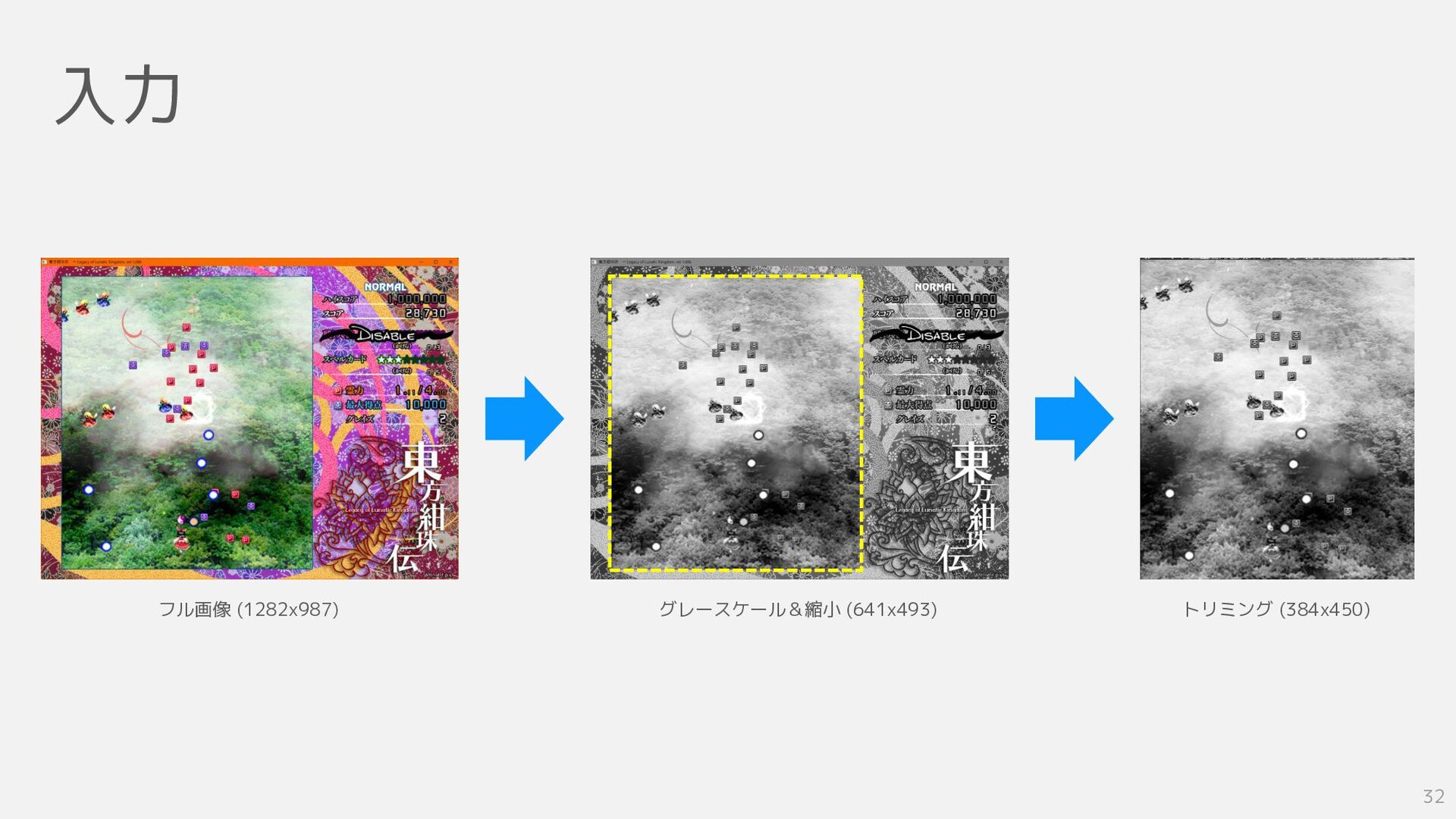
入力 32 フル画像 (1282x987) グレースケール&縮小 (641x493) トリミング (384x450)
ネットワーク構造 33 次回検討
報酬・被弾処理 34 テンプレートマッチングにより特定の画像パターンを検出する Chapter Finish Spell Card Bonus 攻略失敗 テンプレート
しきい値 報酬 +100 +500 -100 検討中 検討中 検討中
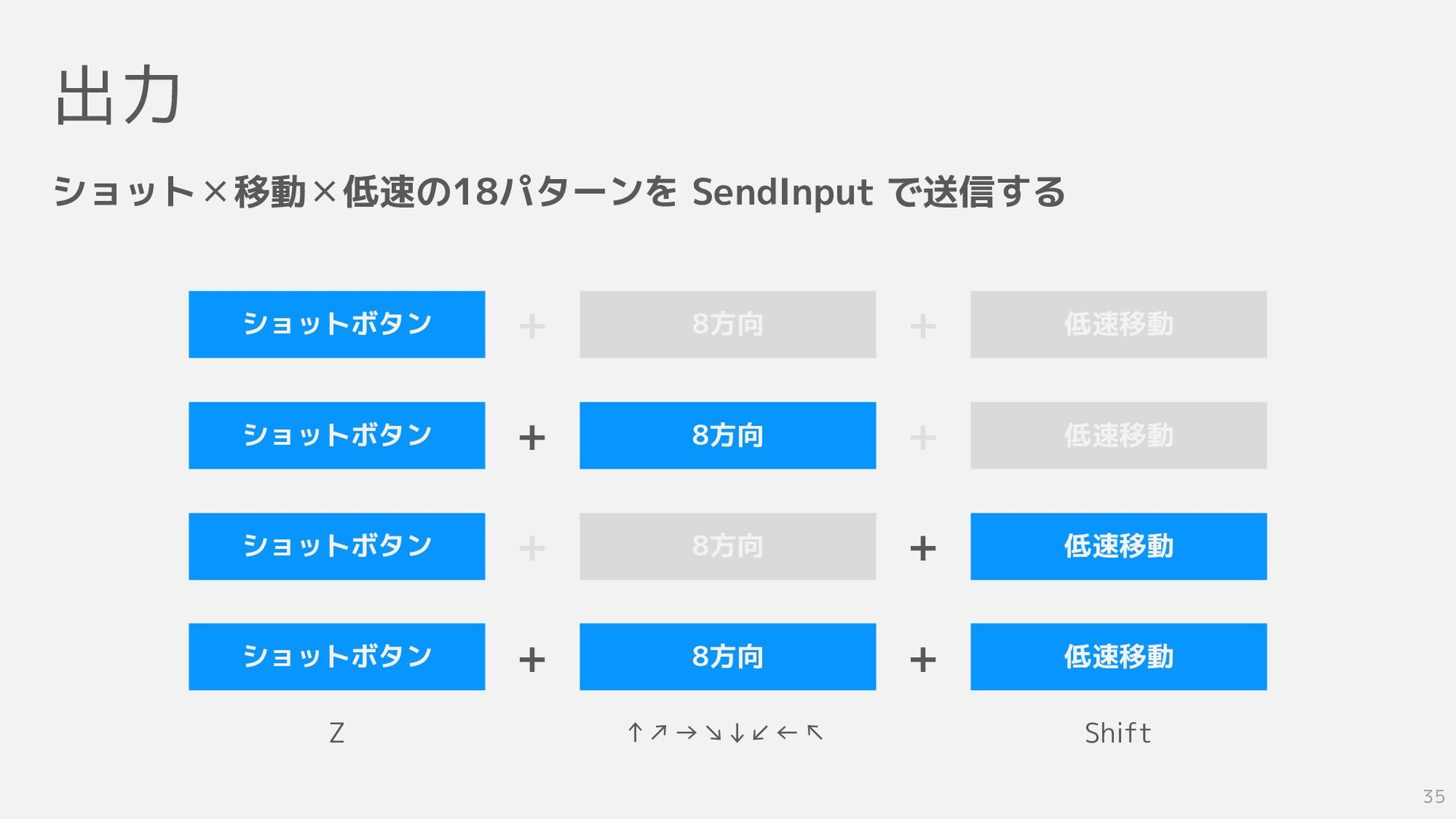
出力 35 ショット✕移動✕低速の18パターンを SendInput で送信する ショットボタン ショットボタン ショットボタン ショットボタン 8方向
8方向 8方向 8方向 低速移動 低速移動 低速移動 低速移動 + + + + + + + + Z ↑↗→↘↓↙←↖ Shift
None
拾 壱 月 度
Appendix
参考文献 • 能登 (@ntddk). 『深層強化学習による東方AI』. 第13回 博麗神社例大祭, 2016年, 23頁 •
Qiita. 「東方ProjectをDeepLearningで攻略した…かった。」. https://qiita.com/imenurok/items/c6aa868107091cfa509c, (2021/09/26) • SlideShare. 「東方ゲームAIとその歴史」. https://www.slideshare.net/ide_an/ai-86452530, (2021/09/26) • 伊藤多一ほか. 『現場で使える!Python深層強化学習入門 強化学習と深層学習による探索と制御』. 翔泳社, 2019年, 328頁 • 牧野浩二, 西崎博光. 『TensorFlowによる深層強化学習入門 ―OpenAI Gym+PyBullet によるシミュレーション―』. オーム社, 2021年, 280頁 • 布留川英一. 『OpenAI Gym/Baselines 深層学習・強化学習 人工知能プログラミング 実践入門』. ボーンデジタル, 2020年, 312頁 • aaa 39
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![環境構築 PS> C:¥Users¥[yourname]¥AppData¥Local¥Programs¥Python¥Python36¥python.exe –m venv .env PS> .¥.env¥Scripts¥activate (.env) PS>](https://files.speakerdeck.com/presentations/9ca203a7e34c45e89c6b0d6d15da4e57/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}