for semi-structured, dynamic data but should be avoided when data is highly structured, requires strict integrity, or is queried frequently in a predictable way. Normalized tables, generated columns, or key-value tables are often better for performance, maintainability, and data integrity. Evaluate your use case carefully, and use JSON/JSONB only when its flexibility outweighs the drawbacks. While JSON and JSONB in PostgreSQL are powerful for handling semi-structured data, there are scenarios where using them may not be the best choice. 3
Overhead: • Query Performance: JSON/JSONB queries (especially with JSON) are generally slower than queries on normalized relational columns due to parsing and extraction overhead. • Indexing: While JSONB supports GIN indexes, they are less efficient than BTREE indexes on regular columns for simple lookups or range queries. • Write Performance: JSONB’s binary format and indexing can slow down inserts and updates compared to native columns, especially for large documents. 4
of Data Integrity: • No Schema Enforcement: JSON/JSONB does not enforce a schema, increasing the risk of inconsistent or invalid data (e.g., missing keys or wrong data types, spelling). { json-schema.org} • No Referential Integrity: You cannot use foreign keys with JSON/JSONB fields, making it harder to maintain relationships compared to normalized tables. • Validation Overhead: Ensuring data validity requires application-level logic or complex CHECK constraints, unlike native column constraints. 5
Inefficiency: • JSON: Stores data as text, including whitespace, making it less space-efficient. • JSONB: While more compact, it still requires more storage than native columns for structured data (e.g., an INTEGER column is smaller than a JSONB field storing the same integer). • Large Documents: Storing large JSON documents can bloat tables and degrade performance. 6
Complexity: • JSON/JSONB queries using operators (->, ->>, #>>) or JSON Path can be harder to write and maintain than standard SQL queries on relational tables. • Joins involving JSONB fields are less intuitive and may require subqueries or unnesting, complicating query design. 7
Type Safety: • JSON/JSONB fields store data as text or binary, requiring explicit casting (e.g., ::INTEGER) for type-specific operations, which can lead to runtime errors if data types are inconsistent. • Native columns enforce types at the database level, reducing errors. 8
Data is Highly Structured: • If the JSON data has a fixed structure (e.g., always contains name, age, and email), it’s better to use regular columns for faster queries, indexing, and data integrity. • JSON/JSONB is best for semi-structured or dynamic data where the schema varies. 9
and Migration Challenges: • JSON/JSONB data can complicate database migrations or schema evolution, as tools may not handle JSON schema changes as gracefully as relational schemas. • Backups of large JSONB columns can be slower and consume more space. 10
and Maintenance: • JSON/JSONB data is less transparent than relational data, making it harder to debug or inspect without specialized tools or functions (e.g., jsonb_pretty). Yes, JSON is supposed to be easily human readable but … • Developers unfamiliar with JSON operators may find it harder to work with compared to standard SQL. 11
Tooling Support: • Some ORMs and database tools have limited support for JSON/JSONB, making integration more complex compared to native columns. • Generating reports or analytics from JSON data may require additional processing. 12
for Convenience: • Using JSON/JSONB as a catch-all for data storage can lead to “schema-less chaos,” where the lack of structure makes it hard to maintain or query data effectively. • It may tempt developers to avoid proper database design, leading to long-term technical debt. 13
has clear relationships (e.g., users, orders, and products), use normalized tables with foreign keys for better performance and integrity. • Frequent Queries on Specific Fields: Extract frequently queried JSON fields into regular columns or use generated columns (as discussed previously) to improve performance. • Small, Fixed Data: Simple key-value pairs (e.g., user_id, status) are better stored as native columns than JSON. • High Write Throughput: In write-heavy applications, JSONB’s overhead (e.g., parsing, indexing) can impact performance compared to native columns. • Strict Data Validation Needs: If data requires strict validation (e.g., NOT NULL, range constraints), native columns with constraints are more reliable. • Analytics or Reporting: JSON/JSONB is less efficient for aggregations or joins compared to normalized tables, especially in data warehouses. 14
with foreign keys for structured data to ensure integrity and optimize performance. ◦ Example: Instead of storing {"address": {"street": "123 Main", "city": "Boston"}} in JSONB, create an addresses table with street and city columns. 2. Generated Columns: ◦ Extract frequently accessed JSONB fields into generated columns for simpler queries and better performance (as covered in the previous response). ◦ Example: email TEXT GENERATED ALWAYS AS (data ->> 'email') STORED. 3. Key-Value Tables: ◦ For simple key-value pairs, use a table with key and value columns instead of JSON. ◦ Example: A user_settings table with columns user_id, key, and value. 4. Separate Columns: ◦ If JSON fields are consistently present, store them as native columns (e.g., theme TEXT, font_size INTEGER) for faster queries and type safety. 5. Dedicated NoSQL Databases: ◦ For truly unstructured or document-heavy workloads (e.g., large, deeply nested JSON), consider a NoSQL database like MongoDB, which is optimized for such data. 15
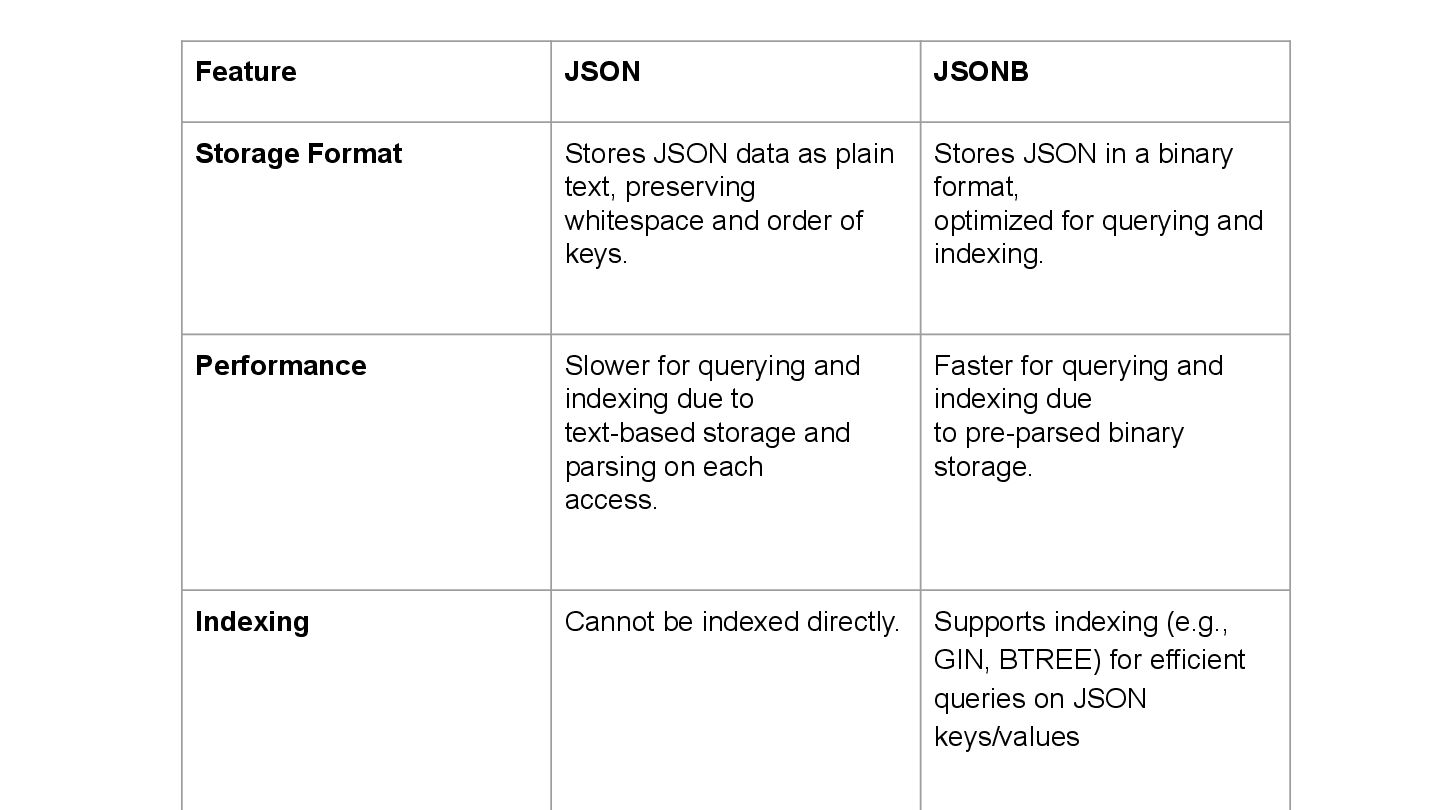
text, preserving whitespace and order of keys. Stores JSON in a binary format, optimized for querying and indexing. Performance Slower for querying and indexing due to text-based storage and parsing on each access. Faster for querying and indexing due to pre-parsed binary storage. Indexing Cannot be indexed directly. Supports indexing (e.g., GIN, BTREE) for efficient queries on JSON keys/values 18
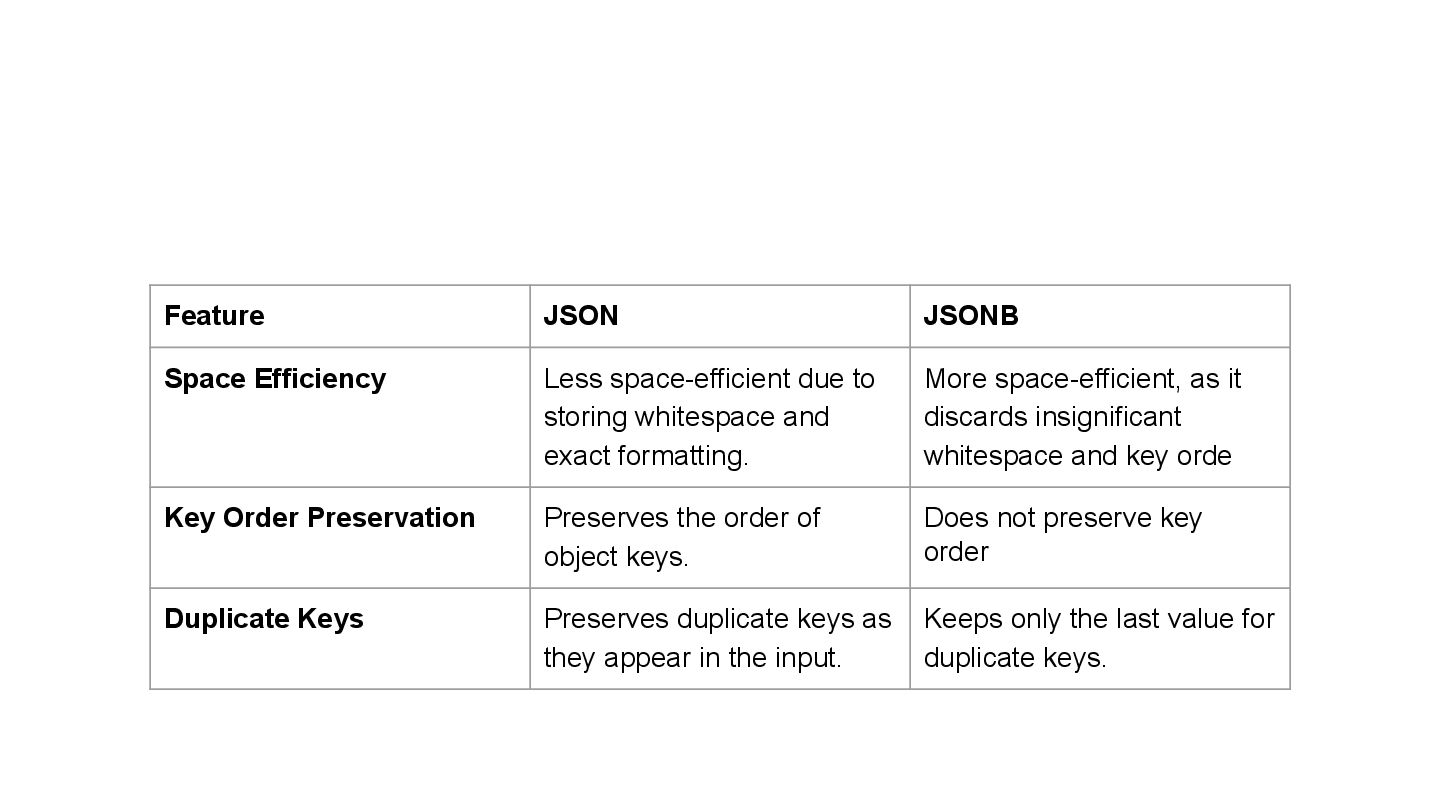
whitespace and exact formatting. More space-efficient, as it discards insignificant whitespace and key orde Key Order Preservation Preserves the order of object keys. Does not preserve key order Duplicate Keys Preserves duplicate keys as they appear in the input. Keeps only the last value for duplicate keys. 19
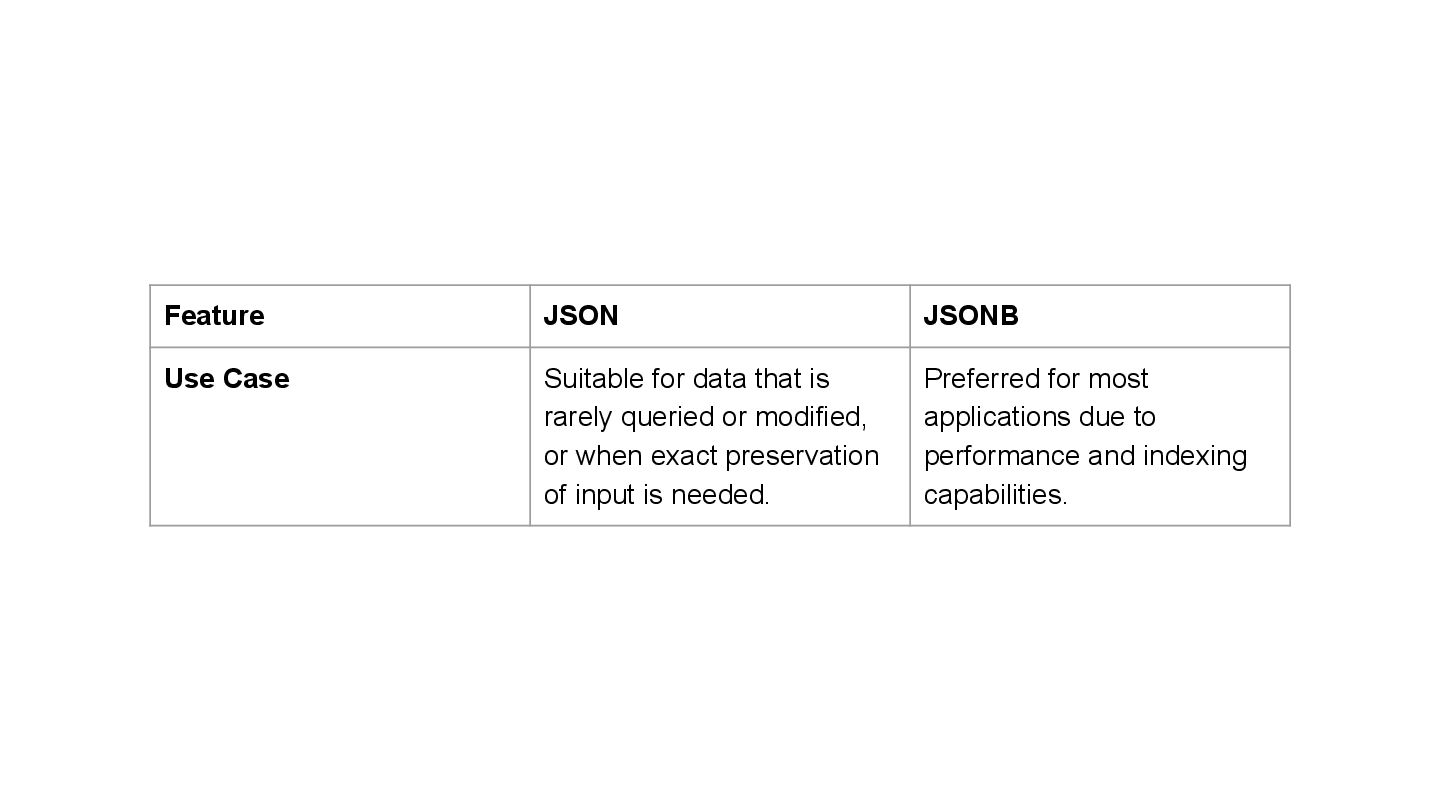
rarely queried or modified, or when exact preservation of input is needed. Preferred for most applications due to performance and indexing capabilities. Recommendation: Use JSONB unless you have a specific need to preserve the exact JSON input (e.g., for auditing or logging purposes). 20
JSON: ◦ JSONB is almost always the better choice due to its performance, indexing support, and efficient storage. Use JSON only for specific cases where you need to preserve the exact input format. 21
Use JSON/JSONB for semi-structured or dynamic data that doesn’t fit well into a rigid relational schema (e.g., user preferences, metadata, or nested data). • Avoid using JSON/JSONB for data that can be effectively modeled with relational tables, as this ensures better query performance and enforces data integrity. 22
• Use GIN indexes for JSONB to optimize queries on keys, values, or nested structures. • Use BTREE or expression-based indexes for specific JSONB fields if you frequently query them. • Avoid over-indexing, as GIN indexes can increase storage and write overhead. 23
Ensure JSON data is valid before inserting it to avoid errors during querying. • Use application-level validation or PostgreSQL’s CHECK constraints to enforce JSON schema rules. 24
PostgreSQL’s JSON operators (->, ->>, #> , #>>) for precise access to JSON data. • Avoid overusing JSON for complex queries that could be better handled by normalized tables. • Combine JSON queries with relational queries to leverage the strengths of both. 25
• Avoid storing excessively large JSON documents, as they can degrade performance and increase storage requirements. • Extract frequently accessed fields into separate columns if they are queried often. • Do not overly embed 26
Use EXPLAIN to analyze query performance, especially when querying JSONB data. • Regularly vacuum and analyze tables with JSONB to maintain index efficiency. 27
Schemas: • JSONB is ideal for cases where the schema evolves over time (e.g., product attributes in an e-commerce database). • However, document schema changes to maintain clarity and avoid query errors. 28
JSON/JSONB does not enforce referential integrity. If relationships between data are critical, use foreign keys in relational tables instead of embedding related data in JSON. 29
id SERIAL PRIMARY KEY, name TEXT NOT NULL, preferences JSONB -- Using JSONB for flexibility and performance ); CREATE TABLE audit_logs ( id SERIAL PRIMARY KEY, log_entry JSON -- Using JSON to preserve exact input ); 31
JSONB UPDATE users SET preferences = preferences || '{"theme": "light"}' WHERE name = 'Alice'; -- Add a new field to JSONB UPDATE users SET preferences = jsonb_set(preferences, '{language}', '"en"', true) WHERE name = 'Alice'; 34
preferences column CREATE INDEX idx_users_preferences ON users USING GIN (preferences); -- Create a GIN index on a specific JSONB key CREATE INDEX idx_users_theme ON users USING GIN ((preferences -> 'theme')); 35
SELECT name, jsonb_path_query(preferences, '$.settings.font_size') AS font_size FROM users WHERE jsonb_path_exists(preferences, '$.settings.font_size > 12'); 36
ensure valid JSON structure ALTER TABLE users ADD CONSTRAINT valid_preferences CHECK ( preferences ? 'theme' AND -- Ensure 'theme' key exists preferences ->> 'theme' IN ('light', 'dark') ); It is less costly to keep the bad data out than trying to clean it up later! 38
SELECT DISTINCT preferences ->> 'theme' AS theme FROM users; -- Count orders by product_id in JSONB SELECT jsonb_array_elements(order_details -> 'items') ->> 'product_id' AS product_id, COUNT(*) FROM orders GROUP BY product_id; 39
than relational queries for large datasets. Normalize data when performance is critical. • PostgreSQL Version: Some features (e.g., JSON Path) require PostgreSQL 12 or later. Ensure your database version supports the features you need. 40
from JSONB columns is an excellent way to improve query performance, simplify queries, and make frequently accessed JSONB fields more accessible as regular columns. Generated columns (introduced in PostgreSQL 12) allow you to define a column whose value is computed from other columns, such as a JSONB field, and keep it synchronized automatically. 42
is defined using the GENERATED ALWAYS AS clause and can extract specific fields from a JSONB column using operators like -> or ->>. • The column’s value is computed automatically when a row is inserted or updated, and it’s stored on disk (for STORED generated columns, the only type supported in PostgreSQL). • Generated columns can be indexed, queried like regular columns, and used in constraints, making them ideal for frequently accessed JSONB fields. 43
for Frequently Accessed Fields: ◦ Create generated columns for JSONB fields that are queried often to avoid repetitive JSONB extraction in queries. ◦ Example: Extract a user’s email or theme preference from a JSONB preferences column. 44
JSONB values as TEXT for most cases, as it’s compatible with string-based queries and indexing. • Use -> if you need to preserve the JSONB type (e.g., for nested objects or arrays), but note that this is less common for generated columns. 45
on generated columns to optimize queries, especially for filtering or sorting. • This is more efficient than indexing the entire JSONB column or using expression indexes on JSONB fields. 46
type matches the generated column’s type (e.g., TEXT, INTEGER, BOOLEAN). • Use explicit casting (e.g., ::INTEGER) in the generation expression if the JSONB field might contain varying types. 47
fields that are queried frequently, as each generated column increases storage and write overhead. • For rarely accessed fields, query the JSONB column directly 48
or NOT NULL constraints to enforce data integrity on extracted JSONB fields. • Example: Ensure a generated theme column is either 'light' or 'dark'. 49
so they increase table size. Evaluate the trade-off between storage and query performance. • Use pg_column_size to measure the impact of adding generated columns. 50
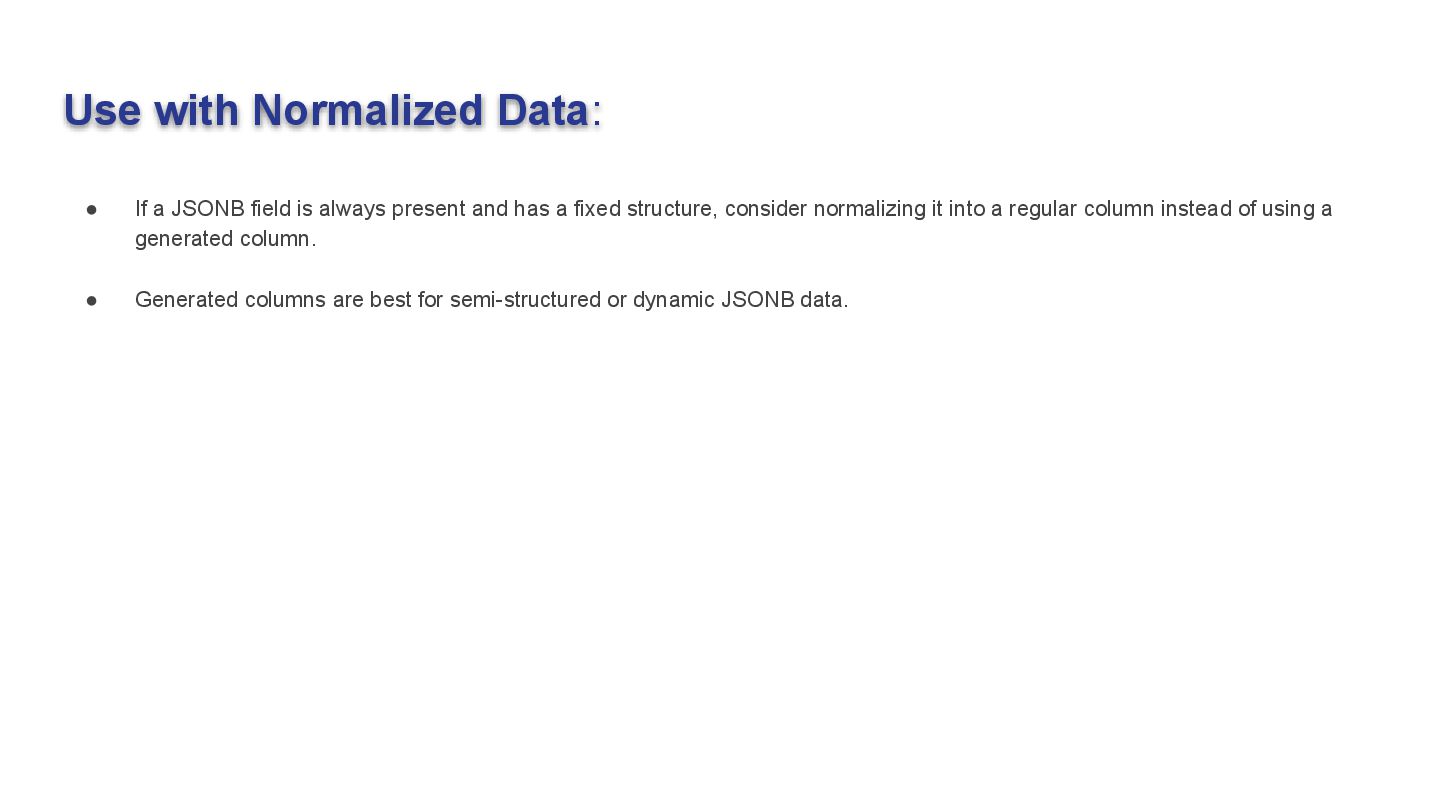
always present and has a fixed structure, consider normalizing it into a regular column instead of using a generated column. • Generated columns are best for semi-structured or dynamic JSONB data. 51
queries on generated columns are faster than equivalent JSONB queries. ◦ Compare with direct JSONB queries or expression indexes to ensure the generated column is worthwhile. 52
SERIAL PRIMARY KEY, name TEXT NOT NULL, preferences JSONB, theme TEXT GENERATED ALWAYS AS (preferences ->> 'theme') STORED, email_notifications BOOLEAN GENERATED ALWAYS AS ((preferences ->> 'email_notifications')::BOOLEAN) STORED ); • The theme column extracts the theme field as TEXT. • The email_notifications column extracts a boolean field with explicit casting. 53
email_notifications FROM users WHERE theme = 'dark'; -- Combine with JSONB queries for other fields SELECT name, theme, preferences ->> 'font_size' AS font_size FROM users WHERE email_notifications = true; • Queries on theme and email_notifications are faster and simpler than preferences ->> 'theme'. demo=# SELECT name, theme, email_notifications FROM users WHERE theme = 'dark'; name | theme | email_notifications -------+-------+--------------------- Alice | dark | t (1 row) 55
CREATE INDEX idx_users_theme ON users (theme); -- Create a unique index on a generated column CREATE UNIQUE INDEX idx_users_email ON users ((preferences ->> 'email')) -- For a hypothetical email field • Indexes on generated columns improve performance for filtering, sorting. 57
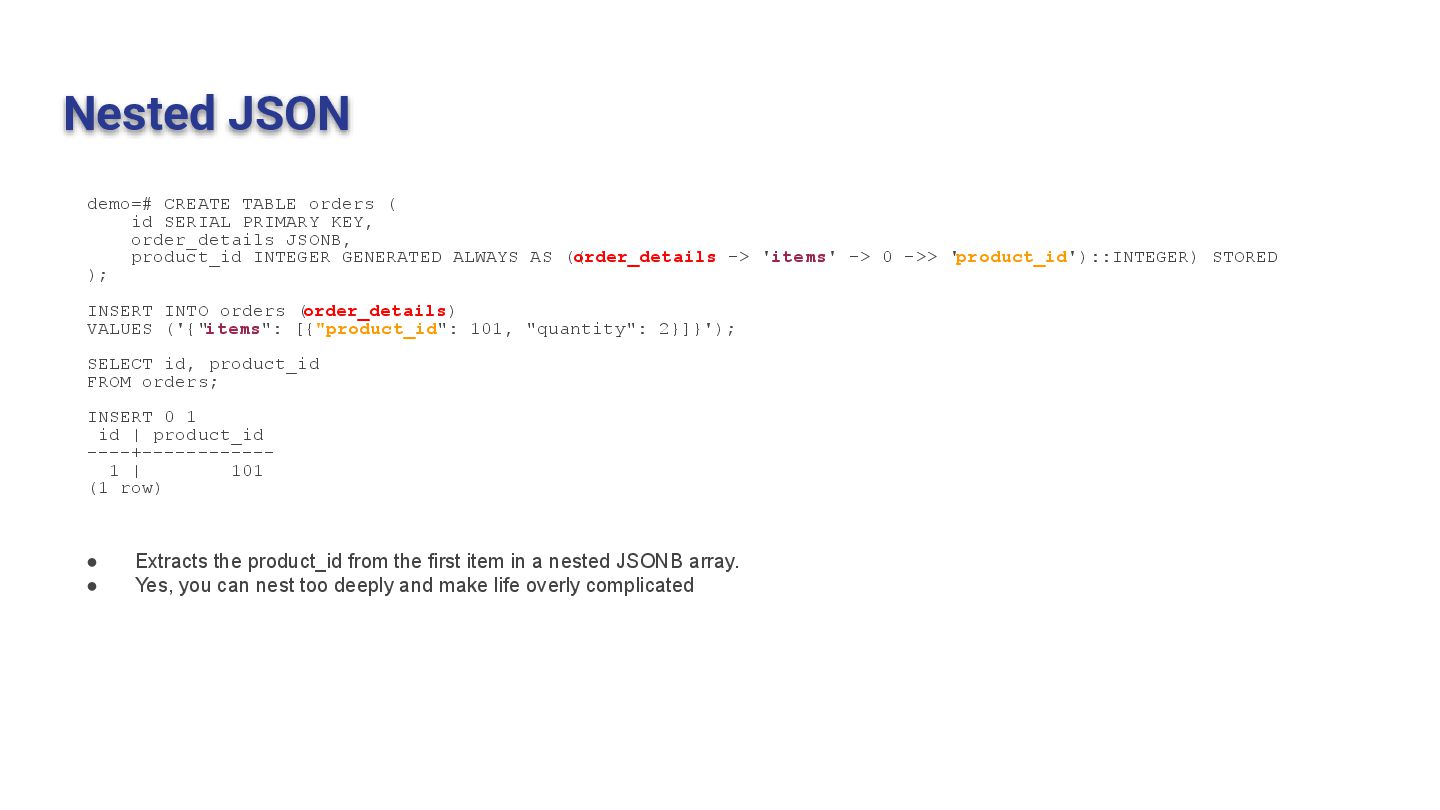
KEY, order_details JSONB, product_id INTEGER GENERATED ALWAYS AS (( order_details -> 'items' -> 0 ->> 'product_id')::INTEGER) STORED ); INSERT INTO orders ( order_details) VALUES ('{"items": [{"product_id": 101, "quantity": 2}]}'); SELECT id, product_id FROM orders; INSERT 0 1 id | product_id ----+------------ 1 | 101 (1 row) • Extracts the product_id from the first item in a nested JSONB array. • Yes, you can nest too deeply and make life overly complicated 60
FROM users WHERE theme = 'dark'; -- Equivalent query using JSONB directly EXPLAIN ANALYZE SELECT name FROM users WHERE preferences ->> 'theme' = 'dark'; • The generated column query typically uses a simpler plan and may leverage an index directly. 61
SELECT pg_column_size(theme) AS theme_size, pg_column_size(email_notifications) AS notifications_size, pg_column_size(preferences) AS preferences_size FROM users; • Helps evaluate the storage overhead of generated columns. 62
updated; you must update the source JSONB column. • Only STORED generated columns are supported (not VIRTUAL, hopefully in PG 18). • Complex expressions in generated columns may slow down inserts/updates. 63
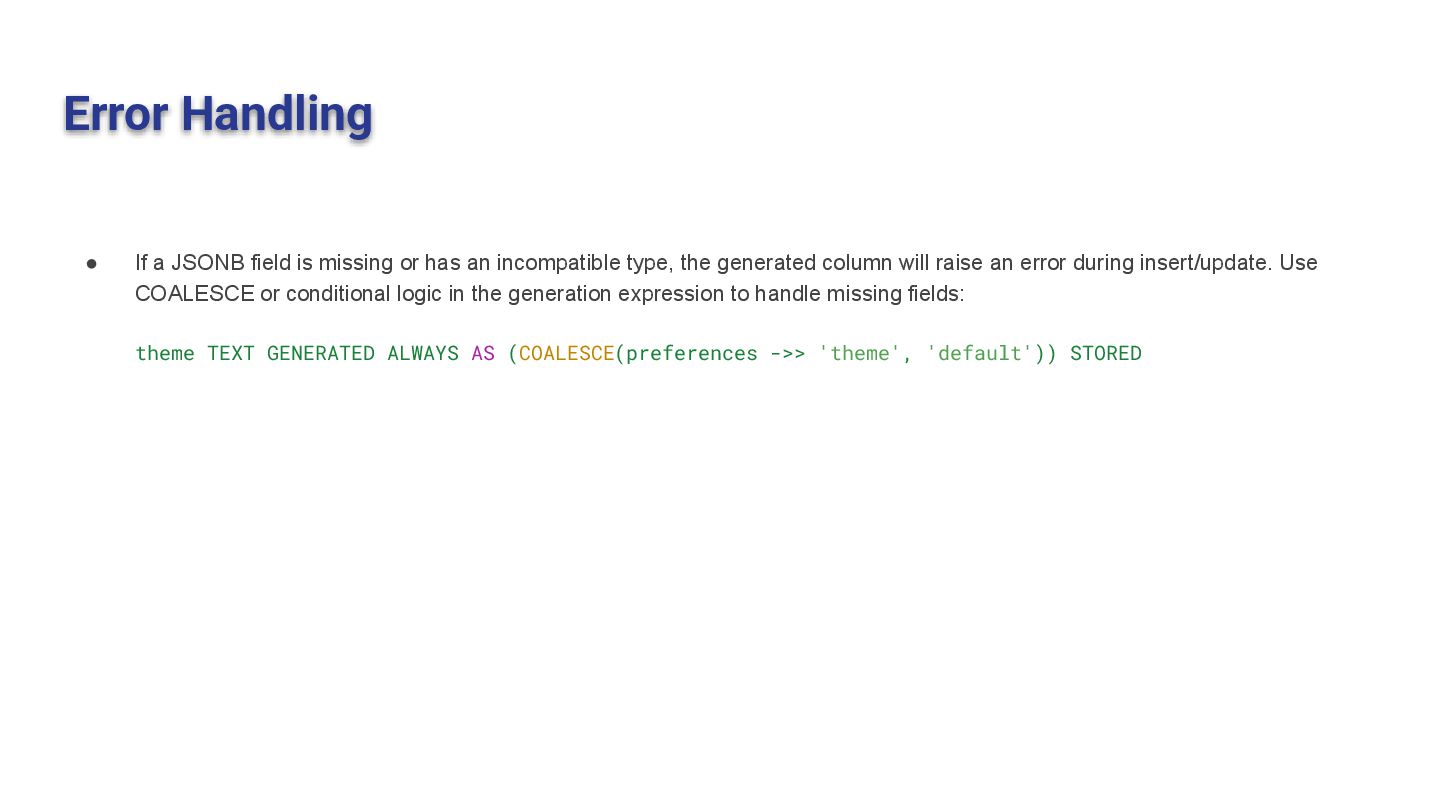
has an incompatible type, the generated column will raise an error during insert/update. Use COALESCE or conditional logic in the generation expression to handle missing fields: theme TEXT GENERATED ALWAYS AS (COALESCE(preferences ->> 'theme', 'default')) STORED 64
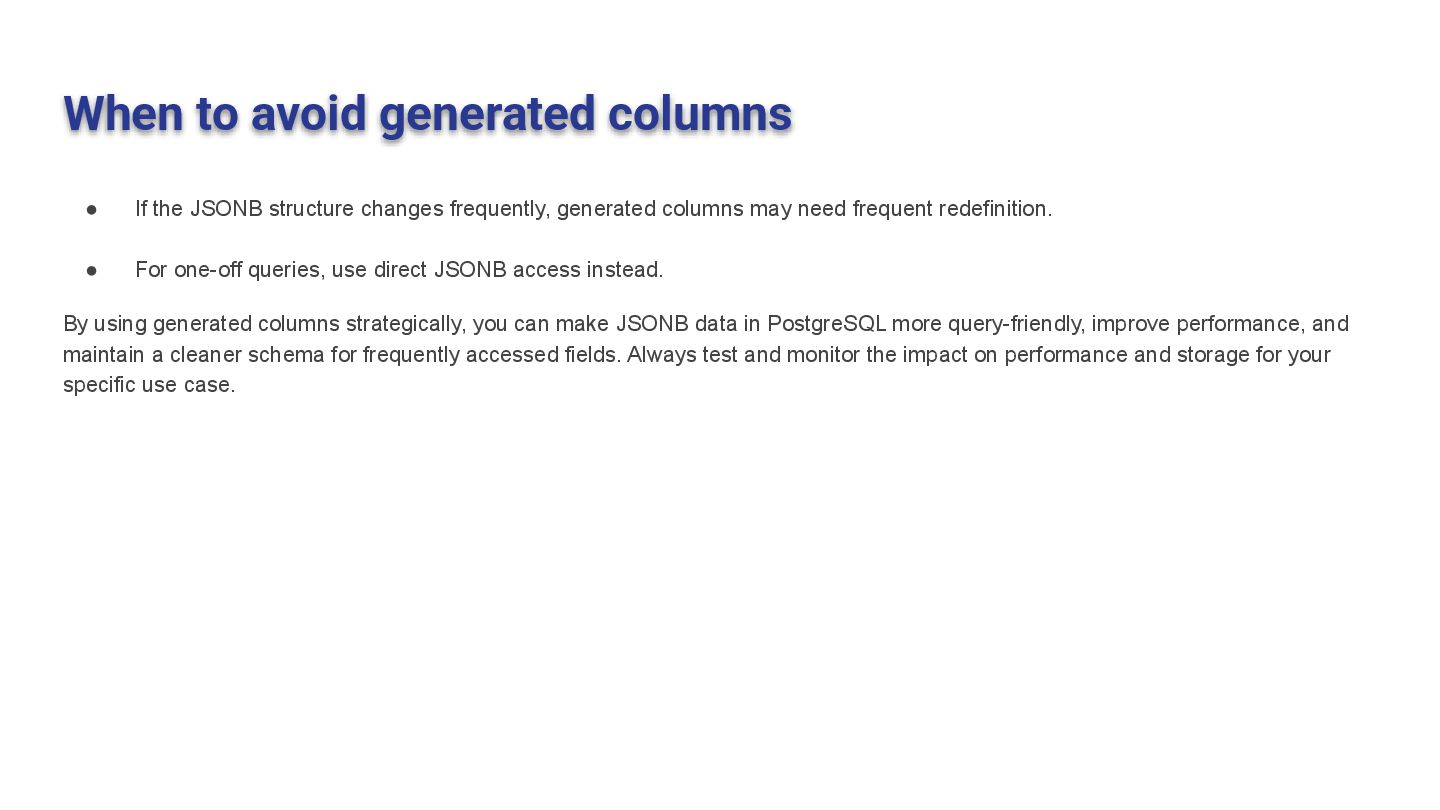
changes frequently, generated columns may need frequent redefinition. • For one-off queries, use direct JSONB access instead. By using generated columns strategically, you can make JSONB data in PostgreSQL more query-friendly, improve performance, and maintain a cleaner schema for frequently accessed fields. Always test and monitor the impact on performance and storage for your specific use case. 65
->> 'email' FROM users WHERE data ->> 'status' = 'active'; -- Better with generated or native column: CREATE TABLE users2 ( id SERIAL PRIMARY KEY, data JSONB, status TEXT GENERATED ALWAYS AS (data ->> 'status') STORED ); SELECT email FROM users WHERE status = 'active'; 66
strategies to address the drawbacks: • Use Generated Columns: Extract key fields for better performance (see previous response). • Index Strategically: Use GIN or BTREE indexes on JSONB fields or generated columns. • Validate Data: Implement CHECK constraints or application-level validation to ensure data consistency. • Normalize When Possible: Move fixed-structure JSON fields to regular columns during schema evolution. • Monitor Performance: Use EXPLAIN ANALYZE to identify slow JSONB queries and optimize them. 68
disks were e-x-p-e-n-s-i-v-e And slow The only programming language from the 1970s still around because it is powerful and flexible. The SQL standard may be interpreted and implemented differently by each vendor. Changing data structures can be costly in time, errort, and sanity. Rolling back can be a nightmare and adding new items can be disastrous. Before using a RDMS, it is necessary to define data structures, and this is an area that is difficult for many Traditional Relational Databases Designed for sets of data Structured Query Language Require prerequisites Love stability 70
Remember ASCII, EBCDIC, or XML Free form +flexible -no rigor imposed (required fields or values) Easy to read Easy to parse JSON - JavaScript Object Notation 71
documents. Implementation dependant, often requires passing arguments to the server in JSON There are very few constraints on what you put into the document, hard to perform constraint checks, and traditional database performance tricks like indexing get tricky. No need to define data structure, just write and go Document Databases Designed for ease of use Query Language Require no prerequisites Embrace chaos 72
input text, which processing functions must reparse on each execution demo=# create table nob (id int, data json); CREATE TABLE demo=# insert into nob (id,data) values (1,'{ "foo" : "bar", "x" : 1, "x" : 2}'); INSERT 0 1 demo=# select * from nob where id = 1; id | data ----+------------------------------------ 1 | { "foo" : "bar", "x" : 1, "x" : 2} (1 row) demo=# 78
makes it slightly slower to input due to added conversion overhead, but significantly faster to process, since no reparsing is needed. demo=# create table yesb (id int, data jsonb); CREATE TABLE demo=# insert into yesb (id,data) values (1,'{ "foo" : "bar", "x" : 1, "x" : 2}'); INSERT 0 1 demo=# select * from yesb where id = 1; id | data ----+------------------------ 1 | {"x": 2, "foo": "bar"} (1 row) demo=# Note the ‘second “x” is the only “x” JSONB data can be indexed 79
"bar", "x" : 1, "x" : 2, "x": true}'); INSERT 0 1 demo=# select * from nob where id = 2; id | data ----+--------------------------------------------- 2 | { "x" : "bar", "x" : 1, "x" : 2, "x": true} (1 row) demo=# insert into yesb (id,data) values (2,'{ "x" : "bar", "x" : 1, "x" : 2, "x": true}'); INSERT 0 1 demo=# select * from yesb where id = 2; id | data ----+------------- 2 | {"x": true} (1 row) 80
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Q&A Dave Stokes [email protected] DBeaver.com - The professional data management](https://files.speakerdeck.com/presentations/2d437fee916747daac14101858fac8f1/slide_82.jpg){kind=link}