Stokes Technology Evangelist at Percona Author of MySQL & JSON - A Practical Programming Guide Over a decade on the Oracle MySQL Community Team Started with MySQL 3.29 [email protected] @Stoker https://speakerdeck.com/stoker
or aggregation function is a function where multiple values are processed together to form a single summary statistic. Common aggregate functions include: • Average (i.e., arithmetic mean) • Count • Maximum • Median • Minimum • Mode • Range • Sum 7 https://en.wikipedia.org/wiki/Aggregate_function#:~:text=In%20database%20management%2C%20an%20aggregate,Sum
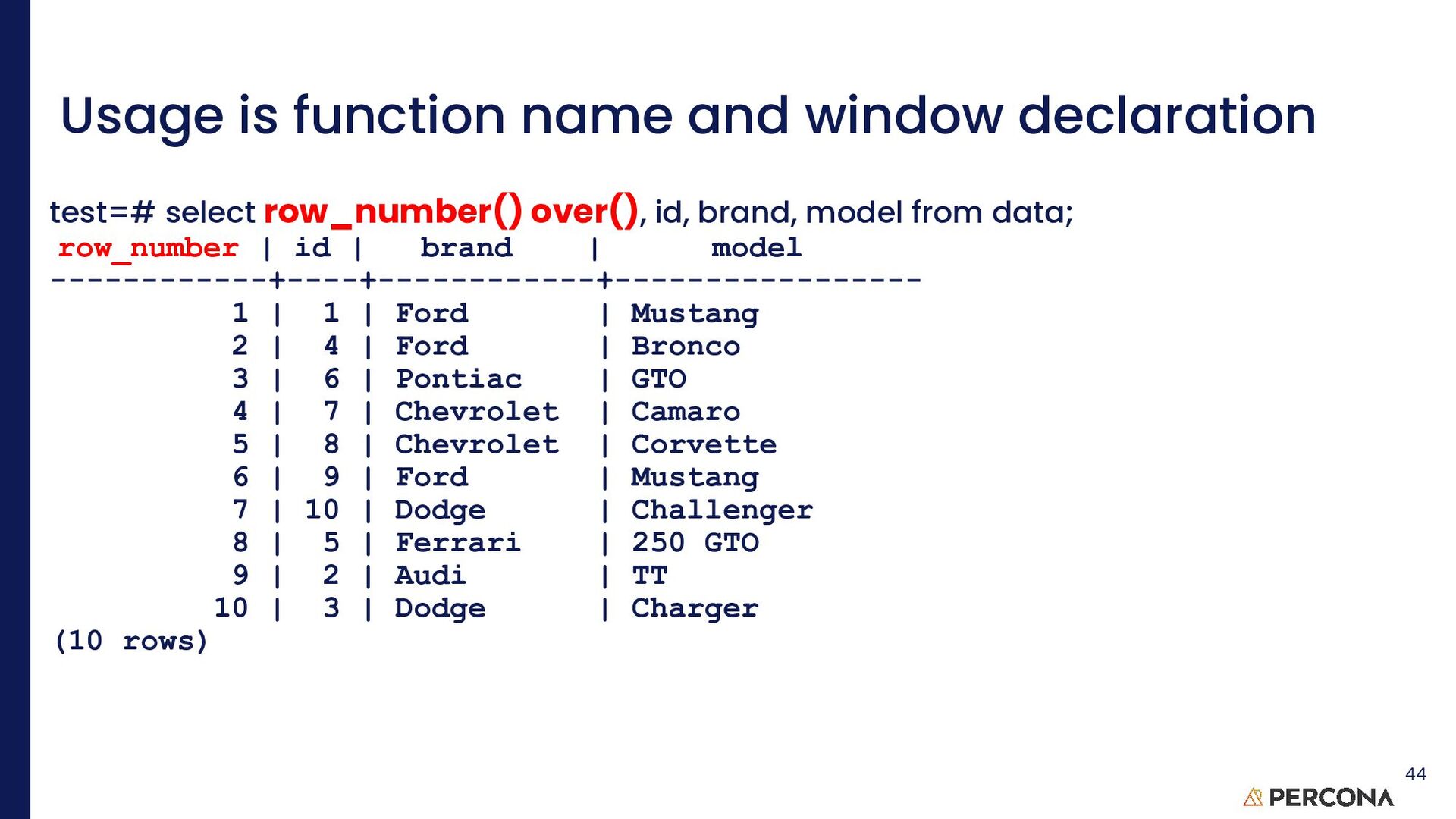
analytic function[1] is a function which uses values from one or multiple rows to return a value for each row. (This contrasts with an aggregate function, which returns a single value for multiple rows.) Window functions have an OVER clause; any function without an OVER clause is not a window function, but rather an aggregate or single-row (scalar) function.[2] 8 https://en.wikipedia.org/wiki/Window_function_(SQL)
Sanity • Presenting numbers is often tough ◦ Learning the ‘stuff’ to present numbers from a Structured Query Language Database is tougher ◦ Practice helps ◦ Build in ‘sanity checks’ -> Do the numbers make sense? • Aggregate Functions are fairly straightforward • Window Function are not straightforward ◦ Syntax is odd ◦ Partitioning can be hard ◦ Functions inside Window Functions are not ‘intuitive’ ◦ You need lots of practice! Lots!
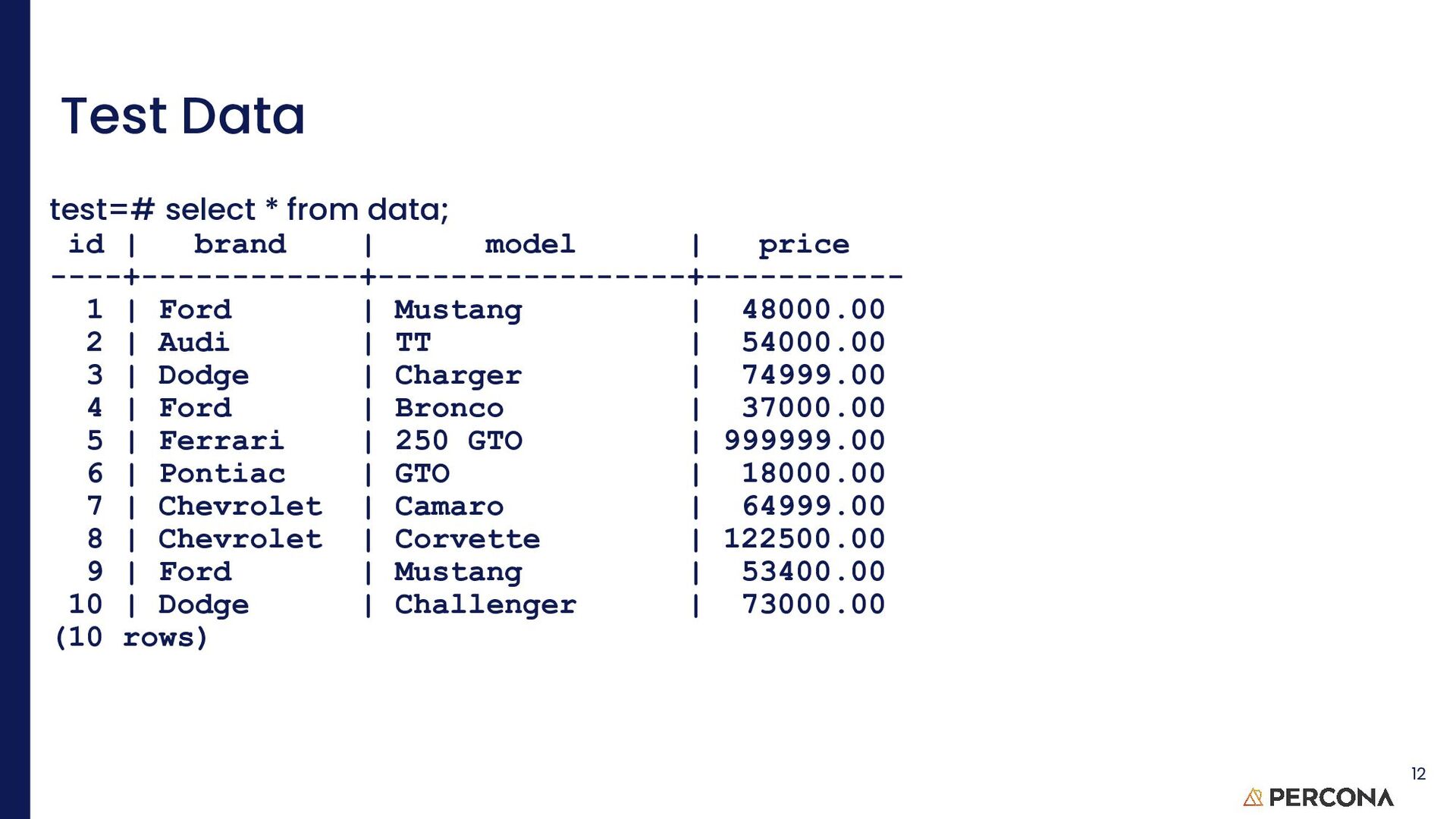
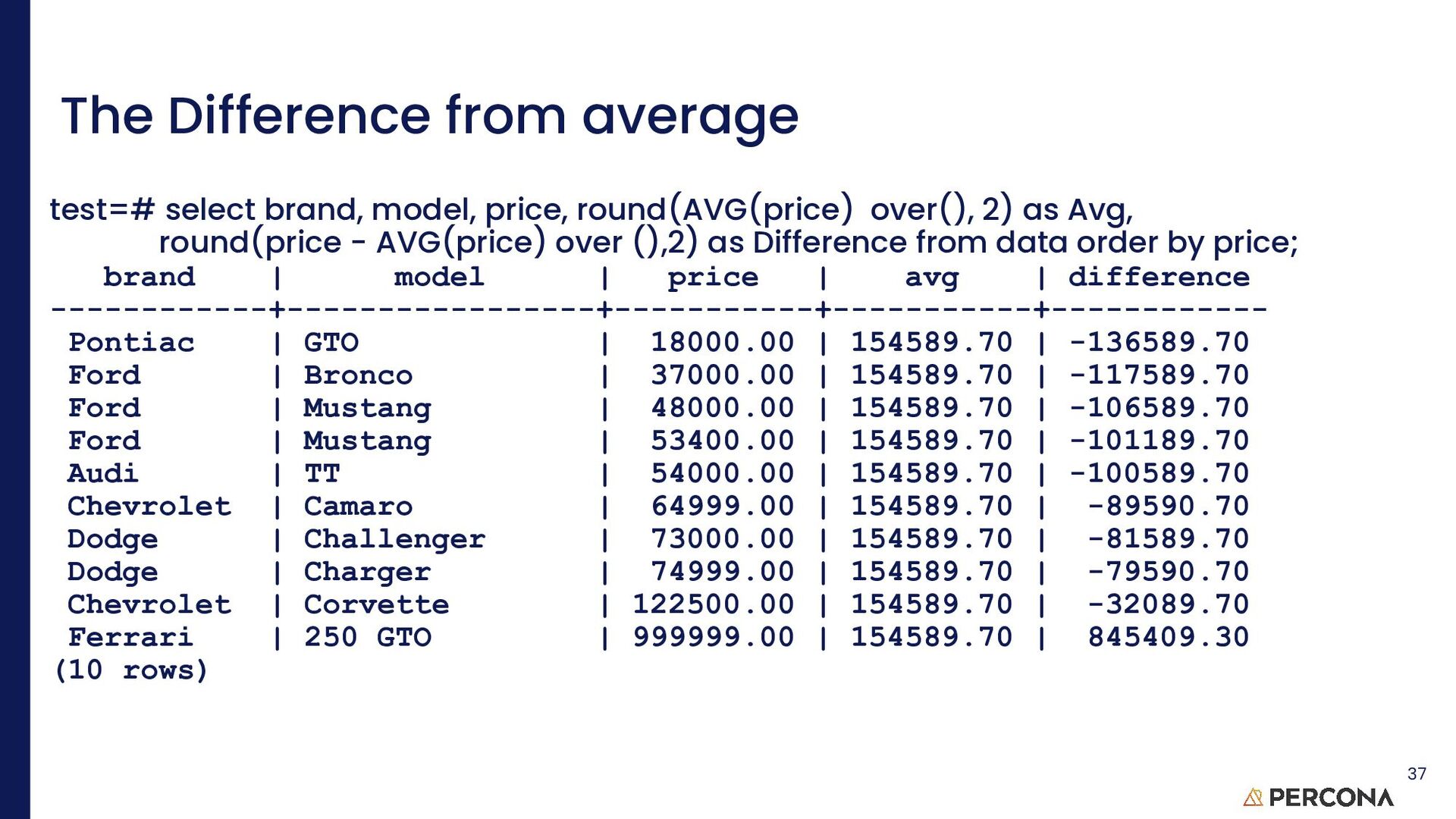
limited. test=# select count(id) as "# records", sum(price), round(avg(price),2), max(price) from data; # records | sum | round | max -----------+------------+-----------+----------- 10 | 1545897.00 | 154589.70 | 999999.00 (1 row) 13 It is easy to use aggregate functions to generate information on a column
clarity test=# select brand, count(brand), sum(price), round(avg(price),2), max(price) from data group by brand; brand | count | sum | round | max ------------+-------+-----------+-----------+----------- Ford | 3 | 138400.00 | 46133.33 | 53400.00 Dodge | 2 | 147999.00 | 73999.50 | 74999.00 Audi | 1 | 54000.00 | 54000.00 | 54000.00 Chevrolet | 2 | 187499.00 | 93749.50 | 122500.00 Pontiac | 1 | 18000.00 | 18000.00 | 18000.00 Ferrari | 1 | 999999.00 | 999999.00 | 999999.00 (6 rows) 14 GROUP BY can be used to put related information together.
test=# select brand, price, sum(price) OVER () from data order by brand; brand | price | sum ------------+-----------+------------ Audi | 54000.00 | 1545897.00 Chevrolet | 64999.00 | 1545897.00 Chevrolet | 122500.00 | 1545897.00 Dodge | 74999.00 | 1545897.00 Dodge | 73000.00 | 1545897.00 Ferrari | 999999.00 | 1545897.00 Ford | 53400.00 | 1545897.00 Ford | 37000.00 | 1545897.00 Ford | 48000.00 | 1545897.00 Pontiac | 18000.00 | 1545897.00 (10 rows) 18 OVER() without anything in the brackets tells the database instance to apply the calculation over the ENTIRE column. Here, sum is for all the values is the price column
select brand, count(id) over(), sum(price) over () from data order by brand; brand | count | sum ------------+-------+------------ Audi | 10 | 1545897.00 Chevrolet | 10 | 1545897.00 Chevrolet | 10 | 1545897.00 Dodge | 10 | 1545897.00 Dodge | 10 | 1545897.00 Ferrari | 10 | 1545897.00 Ford | 10 | 1545897.00 Ford | 10 | 1545897.00 Ford | 10 | 1545897.00 Pontiac | 10 | 1545897.00 (10 rows) 19 Here are two WFs where we are counting all the columns with an ‘id’ value and another that is summing all the ‘price’ values.
brand, price, sum(price) OVER w from data window w as (); brand | price | sum ------------+-----------+------------ Ford | 48000.00 | 1545897.00 Audi | 54000.00 | 1545897.00 Dodge | 74999.00 | 1545897.00 Ford | 37000.00 | 1545897.00 Pontiac | 18000.00 | 1545897.00 Chevrolet | 64999.00 | 1545897.00 Chevrolet | 122500.00 | 1545897.00 Ford | 53400.00 | 1545897.00 Dodge | 73000.00 | 1545897.00 Ferrari | 999999.00 | 1545897.00 (10 rows) 20 We can also move the definition of the window away from the SELECT portion of the query, often provides better readability.
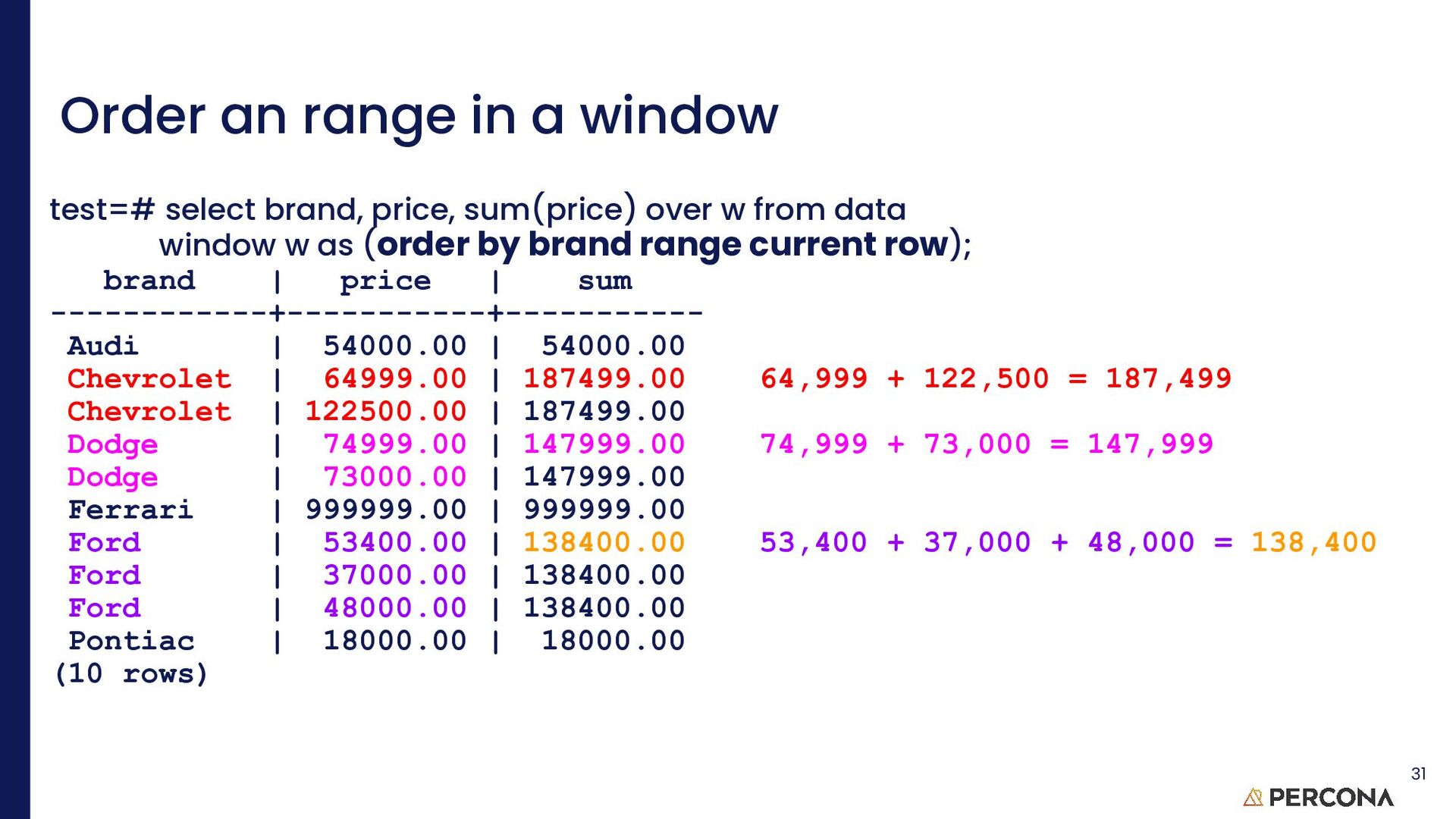
test=# select brand, price, sum(price) over w from data window w as (rows current row); brand | price | sum ------------+-----------+----------- Ford | 48000.00 | 48000.00 Audi | 54000.00 | 54000.00 Dodge | 74999.00 | 74999.00 Ford | 37000.00 | 37000.00 Pontiac | 18000.00 | 18000.00 Chevrolet | 64999.00 | 64999.00 Chevrolet | 122500.00 | 122500.00 Ford | 53400.00 | 53400.00 Dodge | 73000.00 | 73000.00 Ferrari | 999999.00 | 999999.00 (10 rows) 21 Clarity is of prime importance so when in doubt, spell it out!
over w from data window w as (rows unbounded preceding); brand | price | sum ------------+-----------+------------ Ford | 48000.00 | 48000.00 Audi | 54000.00 | 102000.00 Dodge | 74999.00 | 176999.00 Ford | 37000.00 | 213999.00 Pontiac | 18000.00 | 231999.00 Chevrolet | 64999.00 | 296998.00 Chevrolet | 122500.00 | 419498.00 Ford | 53400.00 | 472898.00 Dodge | 73000.00 | 545898.00 Ferrari | 999999.00 | 1545897.00 (10 rows) 22
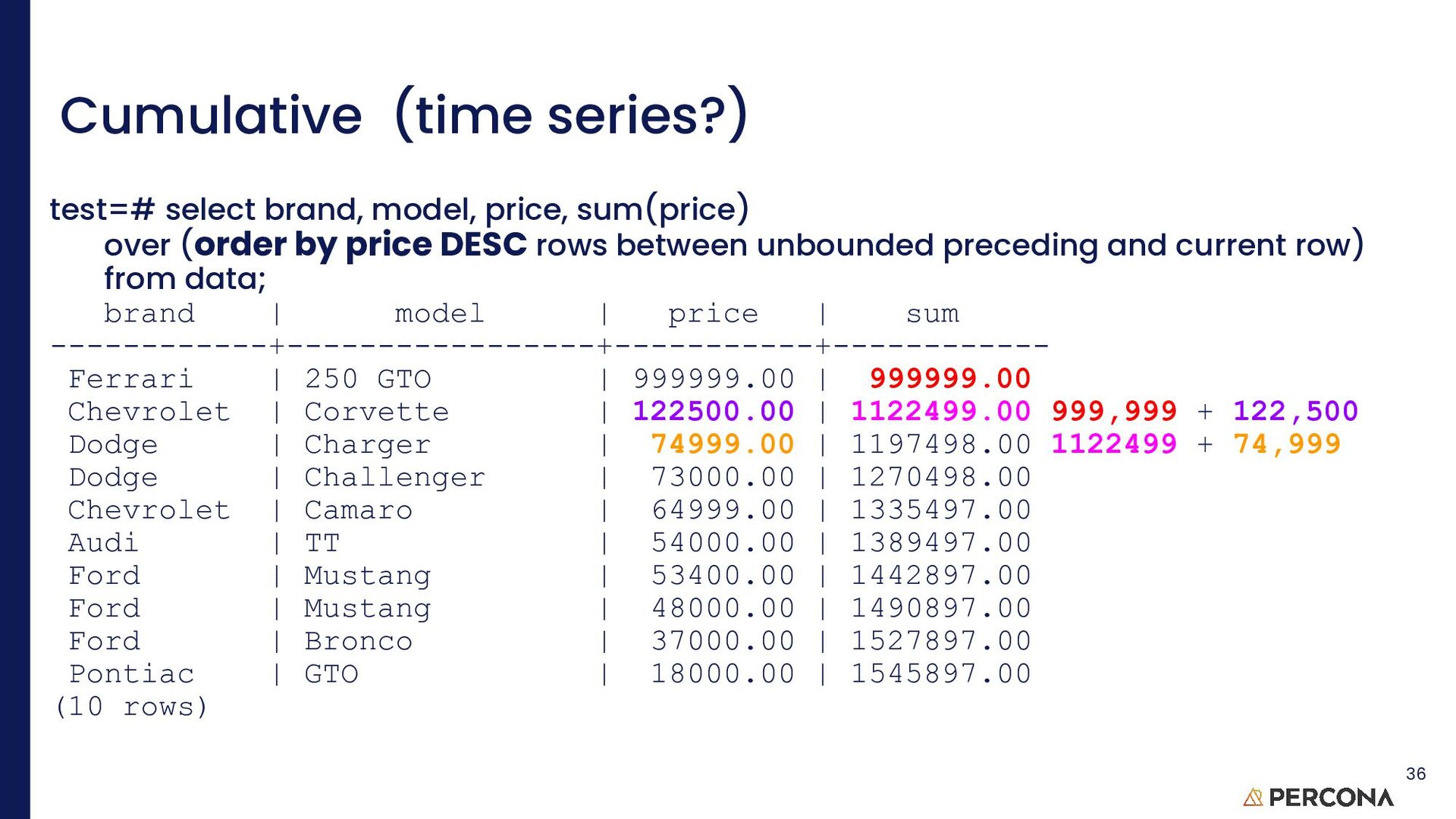
row test=# select brand, price, sum(price) over w from data window w as (rows between unbounded preceding and current row); brand | price | sum ------------+-----------+------------ Ford | 48000.00 | 48000.00 Audi | 54000.00 | 102000.00 Dodge | 74999.00 | 176999.00 Ford | 37000.00 | 213999.00 Pontiac | 18000.00 | 231999.00 Chevrolet | 64999.00 | 296998.00 Chevrolet | 122500.00 | 419498.00 Ford | 53400.00 | 472898.00 Dodge | 73000.00 | 545898.00 Ferrari | 999999.00 | 1545897.00 (10 rows) 25 rows unbounded preceding = rows between unbounded preceding and current row Obvious, eh? This is why practice is needed
following test=# select brand, price, sum(price) over w from data window w as (rows between current row and unbounded following); brand | price | sum ------------+-----------+------------ Ford | 48000.00 | 1545897.00(1,497,897 + 48,000) = 1,545,897 Audi | 54000.00 | 1497897.00 Dodge | 74999.00 | 1443897.00 Ford | 37000.00 | 1368898.00 Pontiac | 18000.00 | 1331898.00 Chevrolet | 64999.00 | 1313898.00 Chevrolet | 122500.00 | 1248899.00 Ford | 53400.00 | 1126399.00 Dodge | 73000.00 | 1072999.00 Ferrari | 999999.00 | 999999.00 (10 rows) 26 rows between unbounded preceding and current row is the opposite of rows between current row and unbounded following
round(avg(price),2) as avg from data group by rollup(brand) order by brand; brand | count | sum | avg ------------+-------+------------+----------- Audi | 1 | 54000.00 | 54000.00 Chevrolet | 2 | 187499.00 | 93749.50 Dodge | 2 | 147999.00 | 73999.50 Ferrari | 1 | 999999.00 | 999999.00 Ford | 3 | 138400.00 | 46133.33 Pontiac | 1 | 18000.00 | 18000.00 | 10 | 1545897.00 | 154589.70 This is the rollup line (7 rows) 33 NULL hiding here
test=# select brand, model, price, price - LEAD(price,1) over (order by price desc) as Increment from data order by price; brand | model | price | increment ------------+-----------------+-----------+----------- Pontiac | GTO | 18000.00 | Ford | Bronco | 37000.00 | 19000.00 37,000 - 18,000 Ford | Mustang | 48000.00 | 11000.00 48,000 - 37,000 Ford | Mustang | 53400.00 | 5400.00 Audi | TT | 54000.00 | 600.00 Chevrolet | Camaro | 64999.00 | 10999.00 Dodge | Challenger | 73000.00 | 8001.00 Dodge | Charger | 74999.00 | 1999.00 Chevrolet | Corvette | 122500.00 | 47501.00 Ferrari | 250 GTO | 999999.00 | 877499.00 (10 rows) 38 There is also a LAG function that works with subsequent values
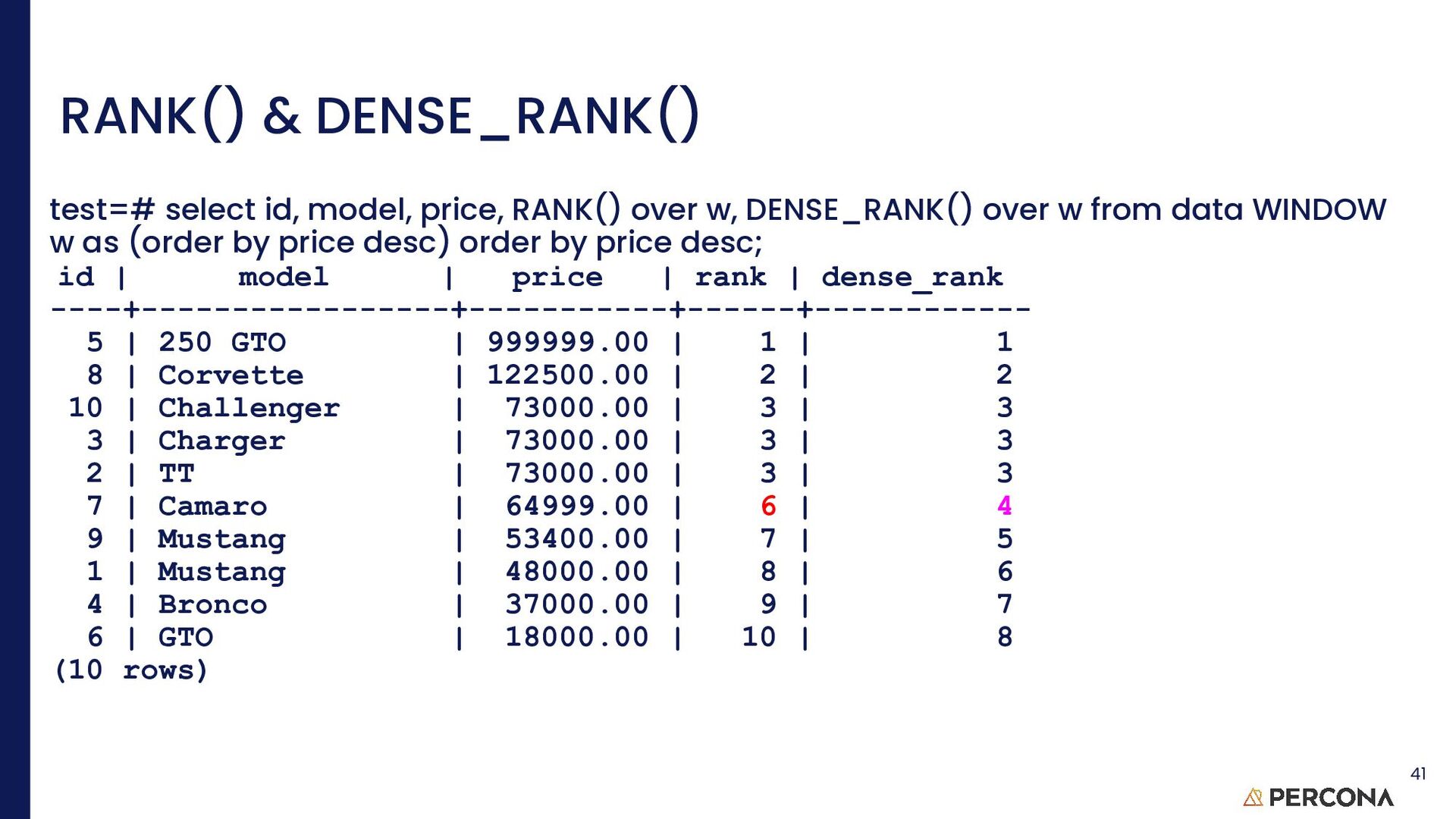
value DENSE_RANK() Rank of current row within its partition, without gaps FIRST_VALUE() Value of argument from first row of window frame LAG() Value of argument from row lagging current row within partition LAST_VALUE()Value of argument from last row of window frame LEAD() Value of argument from row leading current row within partition NTH_VALUE() Value of argument from N-th row of window frame NTILE()Bucket number of current row within its partition. PERCENT_RANK() Percentage rank value RANK() Rank of current row within its partition, with gaps ROW_NUMBER() Number of current row within its partition 43
{kind=link}
![SQL Window Function Analytics and more [email protected] @Stoker](https://files.speakerdeck.com/presentations/b6a95ee6317b419998649c8a6716fd20/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}