#! /usr/bin/env ruby require "rubygems" require "mysql" firstnames = [ "Suchit", "Charvi", "Seema", "Atul", "Rahul", "Thoughtworks", "temp1", "somename ", "othername", "somethingelse" ] lastnames = [ "", "puri", "verma", "gupta", "agarwal", "arora", "empty", "somesirname", "name2", "name3" ] middlenames = [ "kumar", "m1", "m2", "m3", "m4", "m5", "m6", "m7", "m8", "m9" ] limit = 100000 my = Mysql.new("192.168.1.3", "root", "password") my.query("use test;") # my.query("truncate table mass_insert;") limit.times do |i| # # Random data insert # first = firstnames[rand(firstnames.count-1)] middle = middlenames[rand(middlenames.count-1)] last = lastnames[rand(lastnames.count-1)] email = "#{first}#{middle}#{last}@email.com".downcase my.query("INSERT INTO `mass_insert` " + "(`first_name`,`middle_name`,`last_name`,`email`) VALUES " + "('#{first}','#{middle}','#{last}','#{email}');" )
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![22 { age: {$mod: [2, 1]} } // to retrieve](https://files.speakerdeck.com/presentations/516d4ea019eb01307dd222000a9f27e2/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![35 [ReplSetHealthPollTask] replSet info suchitp:40000 is down (or slow to](https://files.speakerdeck.com/presentations/516d4ea019eb01307dd222000a9f27e2/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
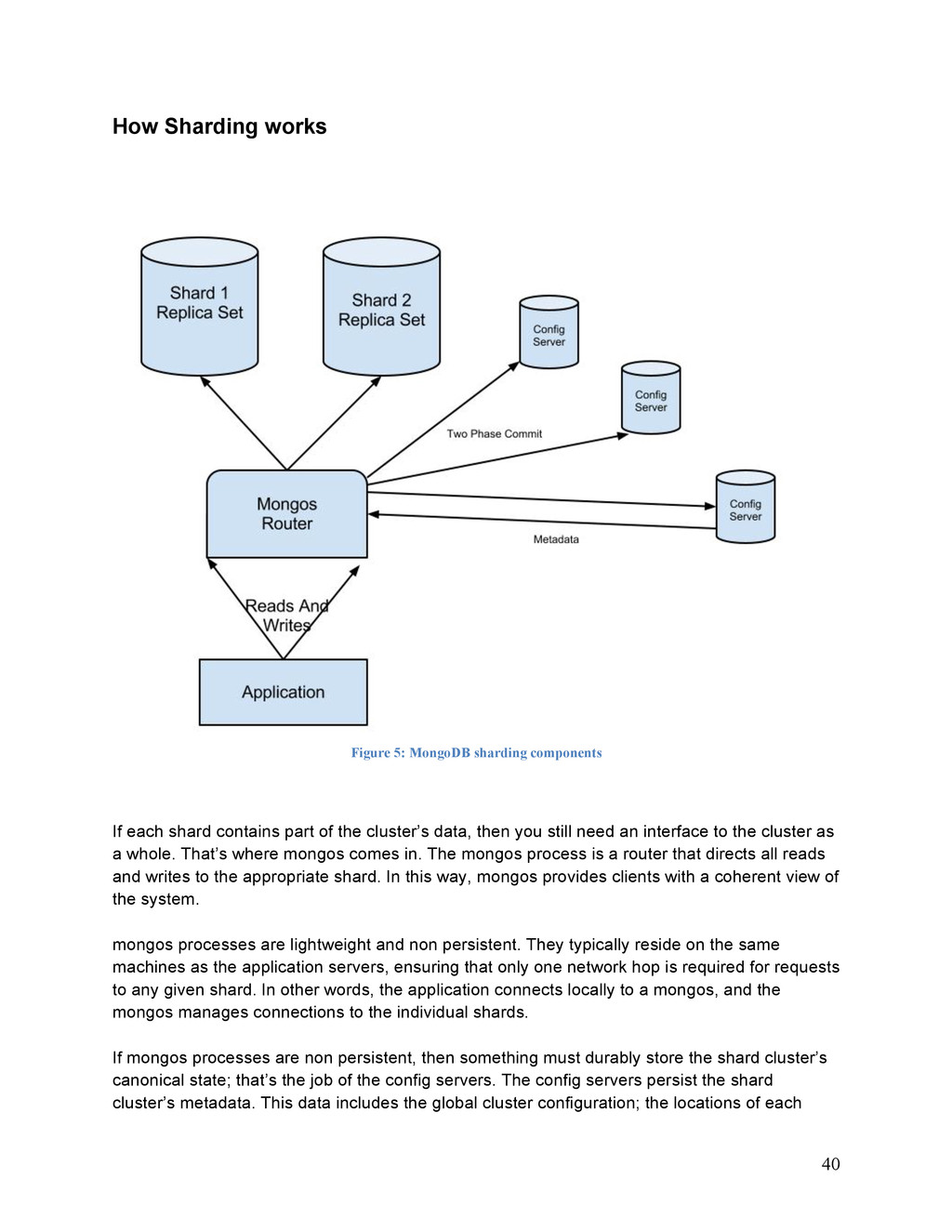{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}