三層で整える LLMが忘れる前提で、外側に三層を積み上げることにした。 01 P U R P O S E 目的層 — 何のために動くか 四半期KPIを明文化して、判断基準のトップに置く。 — AGENTS.md × 至上命題 — 全スキル冒頭に再掲 02 DATA データ層 — 何を読ませるか AIが読みやすい形に整えた3系統のデータソース。 — data/ ( スプレッドシート事前格納) — BigQuery × toolbox MCP — Amplitude MCP 03 AG E N T エージェント層 — どう動き続けるか 文脈を保ち・記憶を残し・学び続けるための仕組み。 — SubAgent 分業 — ナレッジグラフ — retro 自動 + 人間
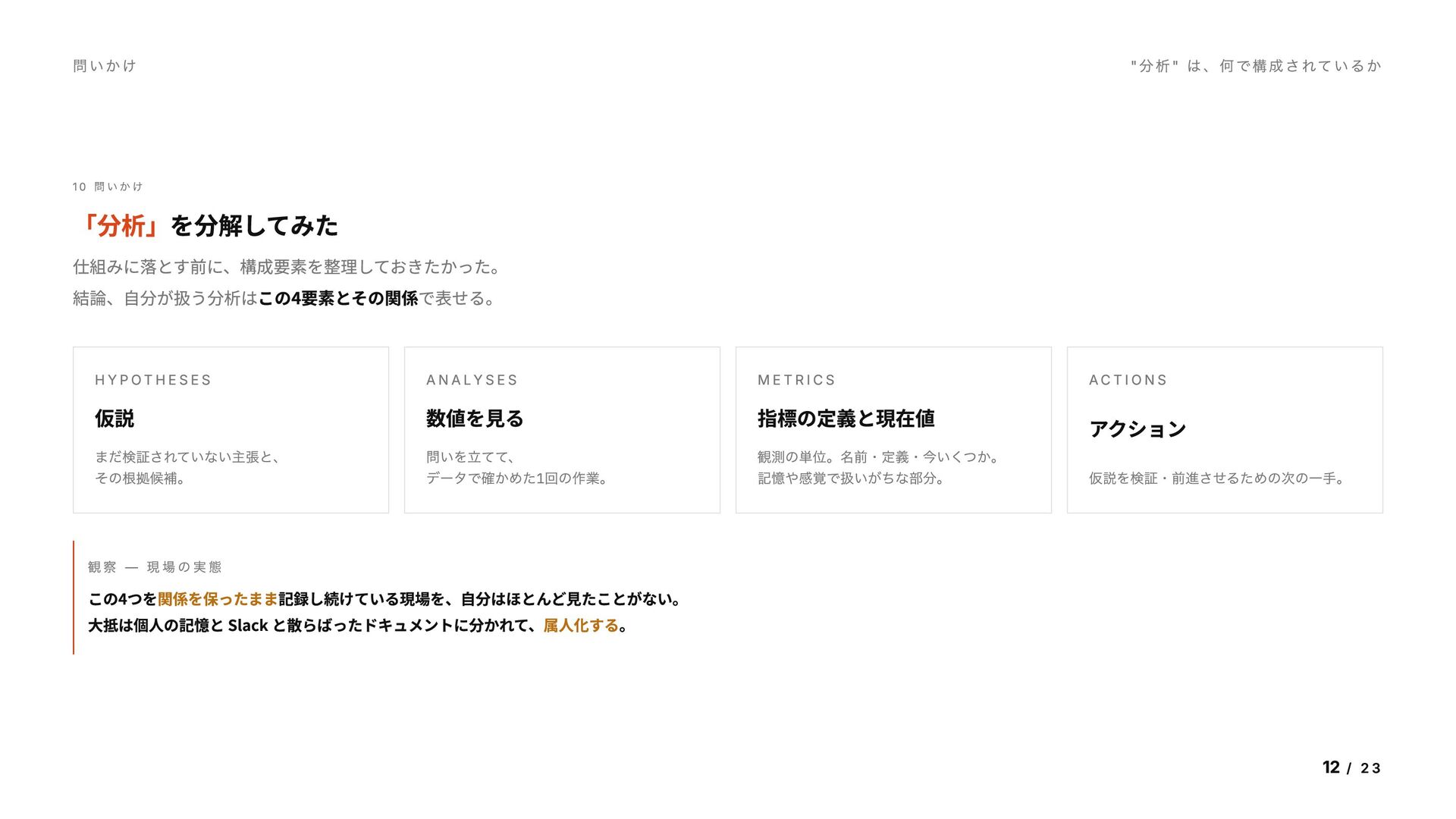
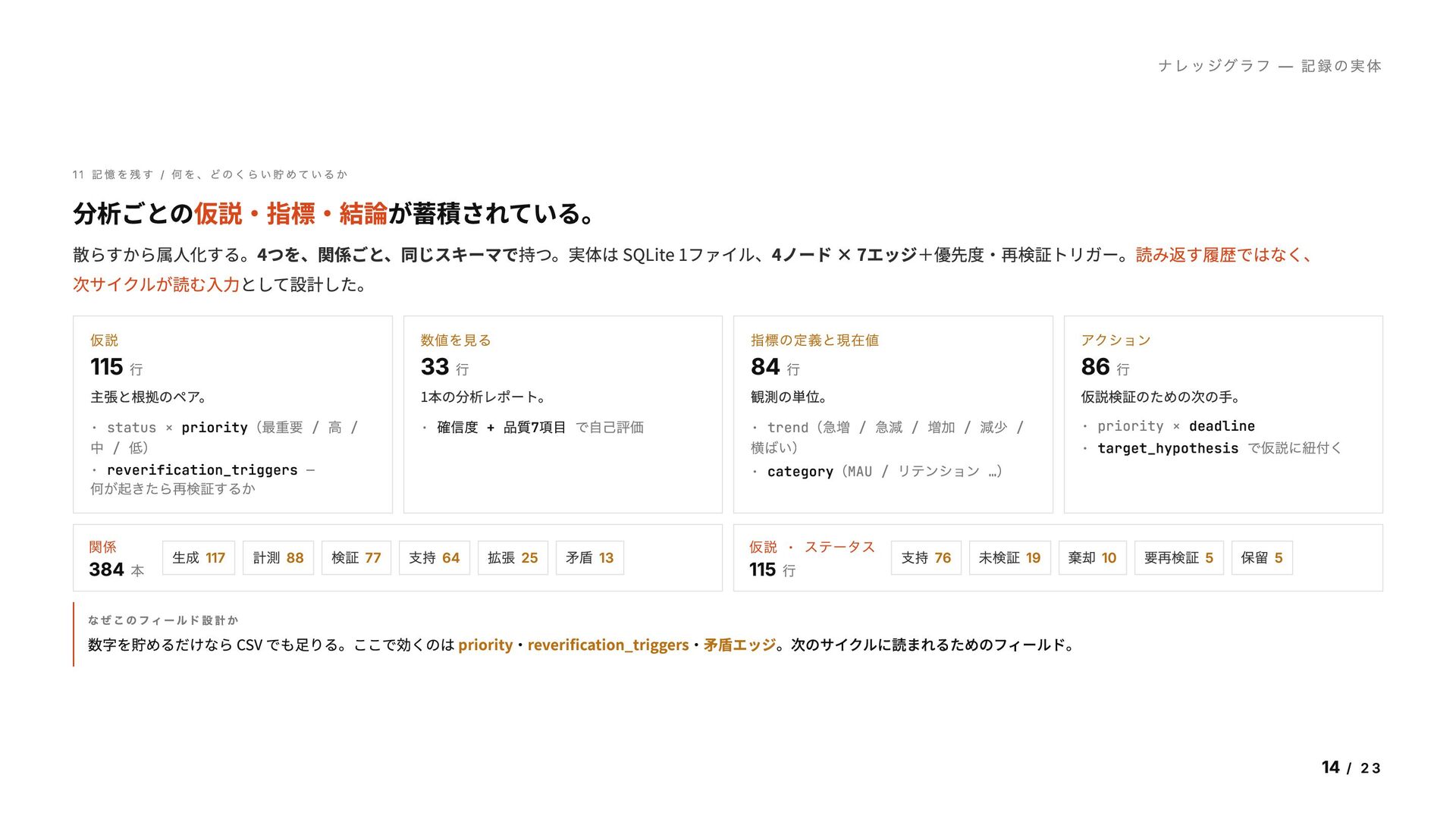
「分析」を分解してみた 仕組みに落とす前に、構成要素を整理しておきたかった。 結論、自分が扱う分析はこの4要素とその関係で表せる。 H Y P OT H E S E S 仮説 まだ検証されていない主張と、 その根拠候補。 A N A LY S E S 数値を見る 問いを立てて、 データで確かめた1 回の作業。 M E T R I C S 指標の定義と現在値 観測の単位。名前・定義・今いくつか。 記憶や感覚で扱いがちな部分。 AC T I O N S アクション 仮説を検証・前進させるための次の一手。 観察 — 現場の実態 この4つを関係を保ったまま記録し続けている現場を、自分はほとんど見たことがない。 大抵は個人の記憶と Slack と散らばったドキュメントに分かれて、属人化する。
8 TA K E AWAY S 0 1 目的・データ・エージェントの三層で、 長時間動かせる状態を作った。 0 2 retro は自動 + 人間の2系統。 AIが知らないことがある前提で設計する。 0 3 新人分析官までは作れた。次は「提案できる中堅」 の設計へ。 D O N E 一晩中、動き続ける基盤はもうできた。 N E XT 朝起きた自分に、意思決定まで届ける。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}