blocks What a model switch really costs — and what happens to the model's hidden reasoning when you cross the boundary. Grounded in measurement: every number captured on the wire from Claude Code 2.1.150 (sonnet-4-6 + haiku-4-5).
are model-scoped — a switch can't reuse what you already paid for 2 Same prompt, different model — the system prompt + the tokenizer differ 3 What a thinking block is — the model's reasoning, sealed in a signature 4 What thinking costs — output at generation, input on replay 5 Crossing the model boundary — the reasoning is kept-and-billed, or stripped 6 Inside real Claude Code — the one field that keeps it all COLOR KEY — highlight colors used on every log slide ahead structure / byte 0 warm · cheap (0.1×) write (2×) cold · expensive
why switching the model throws away the cache you already paid for — even with byte- identical input. ▸ Read a thinking block on the wire: what's in it, why the reasoning is sealed, and how big the signature gets. ▸ Predict the bill for a switch: the cold write plus the replayed thinking the new model now charges as input. ▸ Spot the trap in a “cheaper model” router or sub-agent before you ship it. ▸ Know what's safe to touch — and that editing or stripping thinking blocks in a proxy is a 400 or a re- key.
a cache entry belongs to one model; another model can't read it. thinking block the model's reasoning — a separate content block, emitted before the answer. signature an encrypted carrier of the full thinking; you can carry it, not open it. replay re-sending the prior thinking blocks back to the model on the next turn. display what you see of thinking: “summarized” (a paraphrase) or “omitted” (nothing). context_management the request field Claude Code uses to keep all thinking (keep:“all”).
prefix, per model, every turn. Act I: the server is stateless, so the client re-sends the whole conversation; a prompt cache makes the repeat cheap (read 0.1× vs. write 2×). Two details we deferred: that cache is tied to the model, and the prefix carries the model's thinking blocks. Change the model — or touch those blocks — and the economics shift. WHY This act picks up exactly there: what a model switch costs, and what happens to the reasoning riding in your prefix.
to ONE model. Another model cannot read it — not even for byte-identical input. The cache key includes the model, so a switch is always a cold start on the new model, no matter how much the prompts overlap. WHY This is the single reason a model switch is expensive. Everything else in this part is a consequence of it. [measured] §21
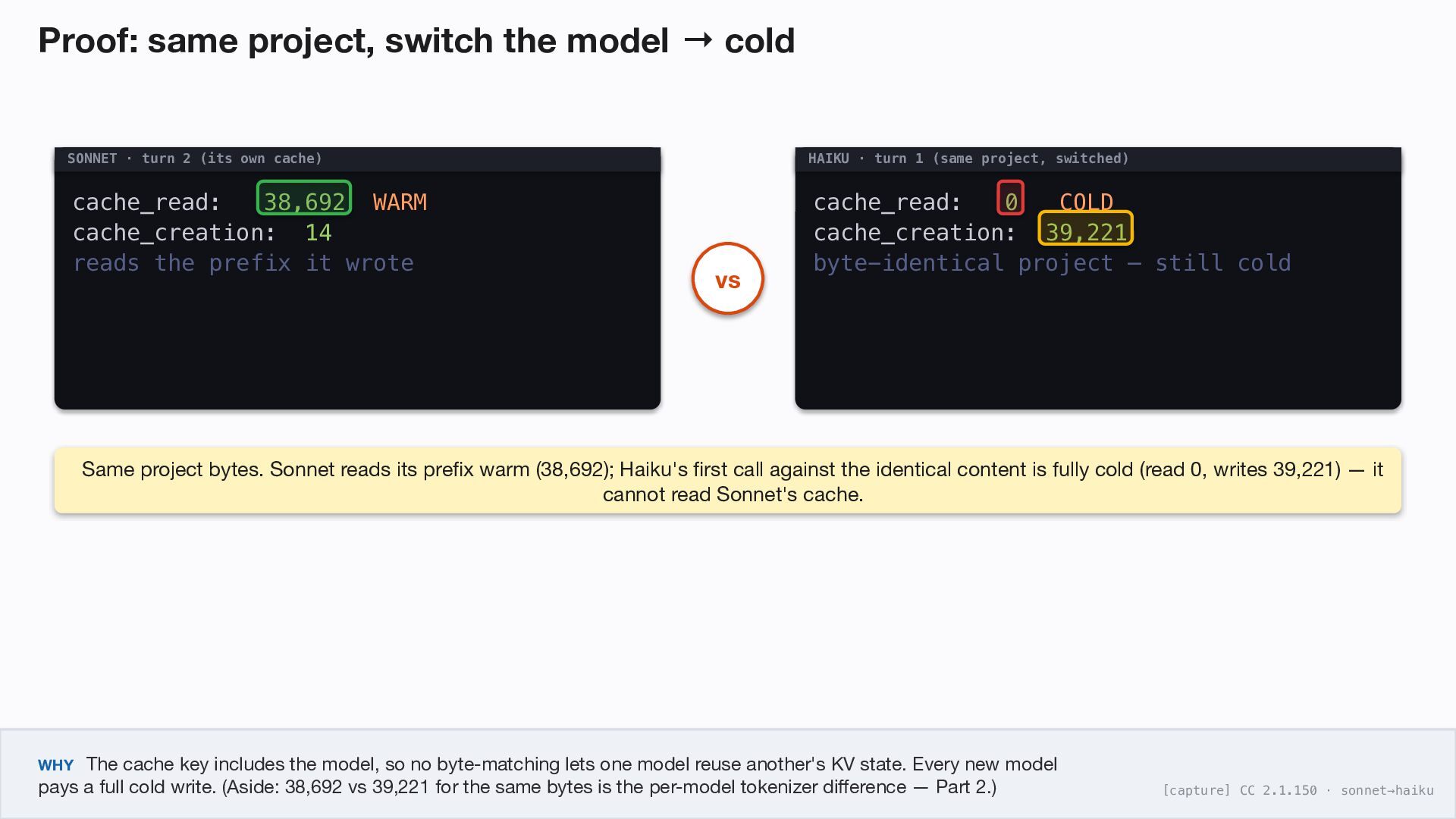
turn 2 (its own cache) cache_read: 38,692 WARM cache_creation: 14 reads the prefix it wrote HAIKU · turn 1 (same project, switched) cache_read: 0 COLD cache_creation: 39,221 byte-identical project — still cold vs Same project bytes. Sonnet reads its prefix warm (38,692); Haiku's first call against the identical content is fully cold (read 0, writes 39,221) — it cannot read Sonnet's cache. WHY The cache key includes the model, so no byte-matching lets one model reuse another's KV state. Every new model pays a full cold write. (Aside: 38,692 vs 39,221 for the same bytes is the per-model tokenizer difference — Part 2.) [capture] CC 2.1.150 · sonnet→haiku
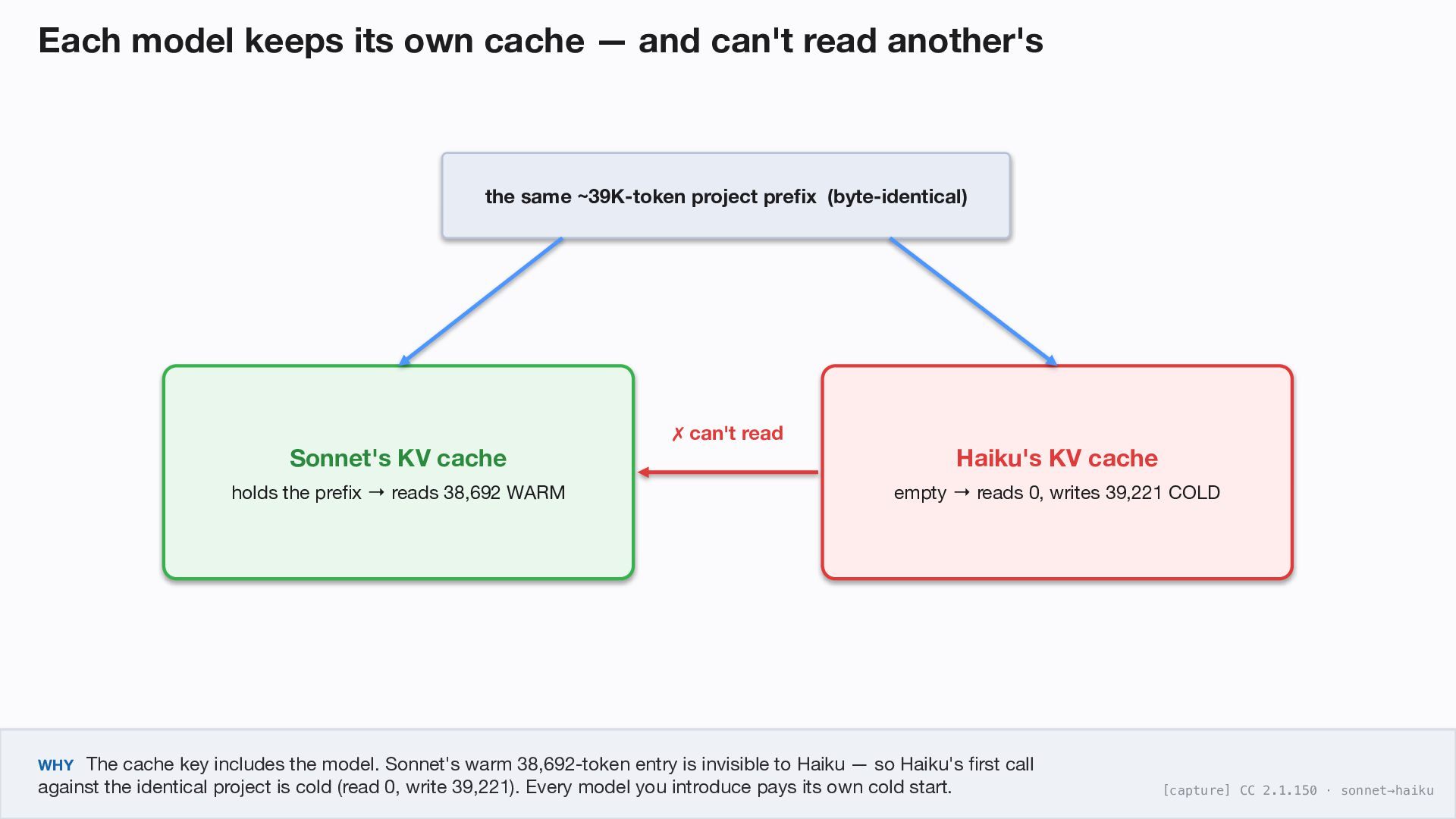
another's the same ~39K-token project prefix (byte-identical) Sonnet's KV cache holds the prefix reads 38,692 WARM → Haiku's KV cache empty reads 0, writes 39,221 COLD → can't read ✗ WHY The cache key includes the model. Sonnet's warm 38,692-token entry is invisible to Haiku — so Haiku's first call against the identical project is cold (read 0, write 39,221). Every model you introduce pays its own cold start. [capture] CC 2.1.150 · sonnet→haiku
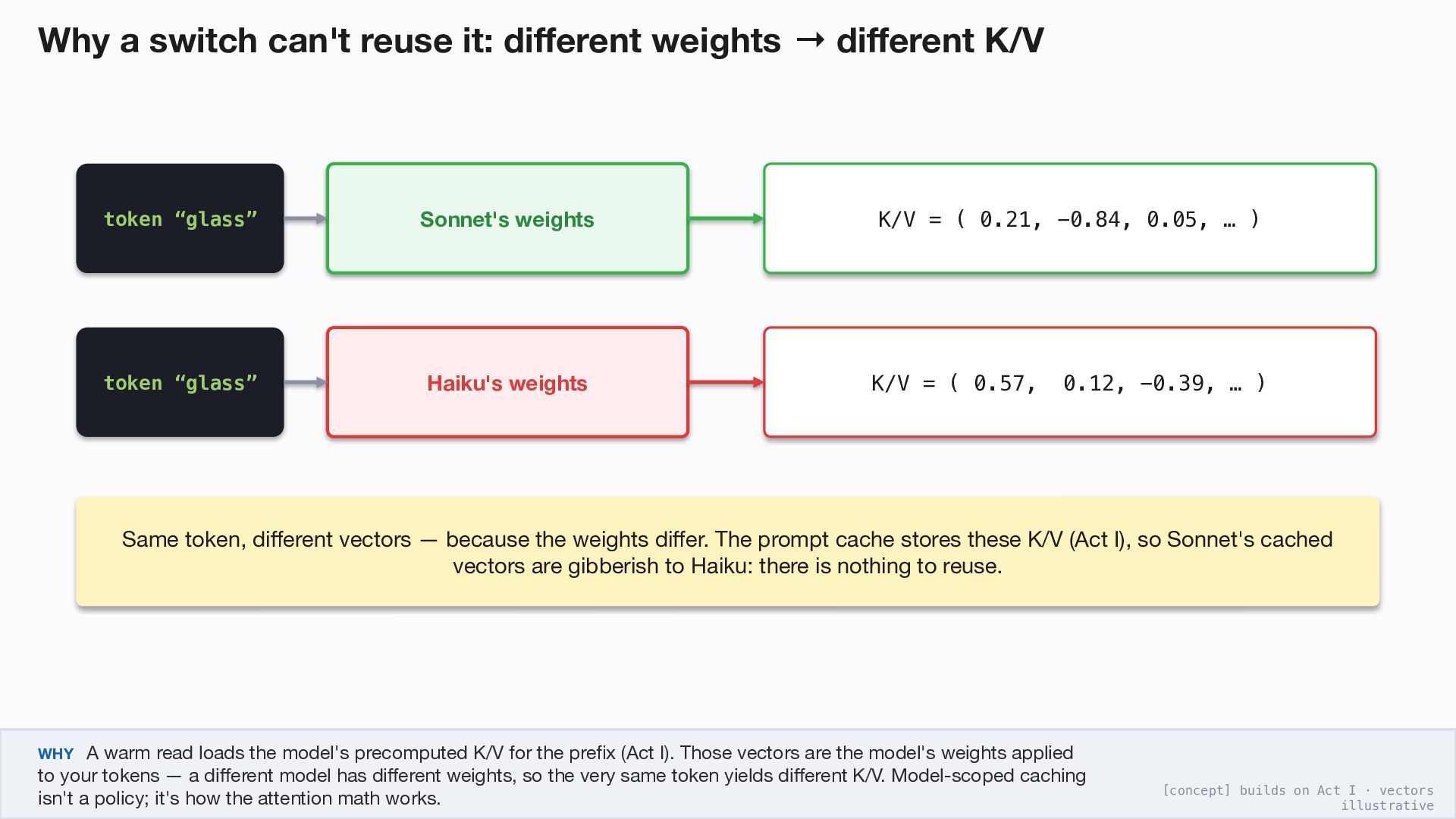
→ token “glass” Sonnet's weights K/V = ( 0.21, -0.84, 0.05, … ) token “glass” Haiku's weights K/V = ( 0.57, 0.12, -0.39, … ) Same token, different vectors — because the weights differ. The prompt cache stores these K/V (Act I), so Sonnet's cached vectors are gibberish to Haiku: there is nothing to reuse. WHY A warm read loads the model's precomputed K/V for the prefix (Act I). Those vectors are the model's weights applied to your tokens — a different model has different weights, so the very same token yields different K/V. Model-scoped caching isn't a policy; it's how the attention math works. [concept] builds on Act I · vectors illustrative
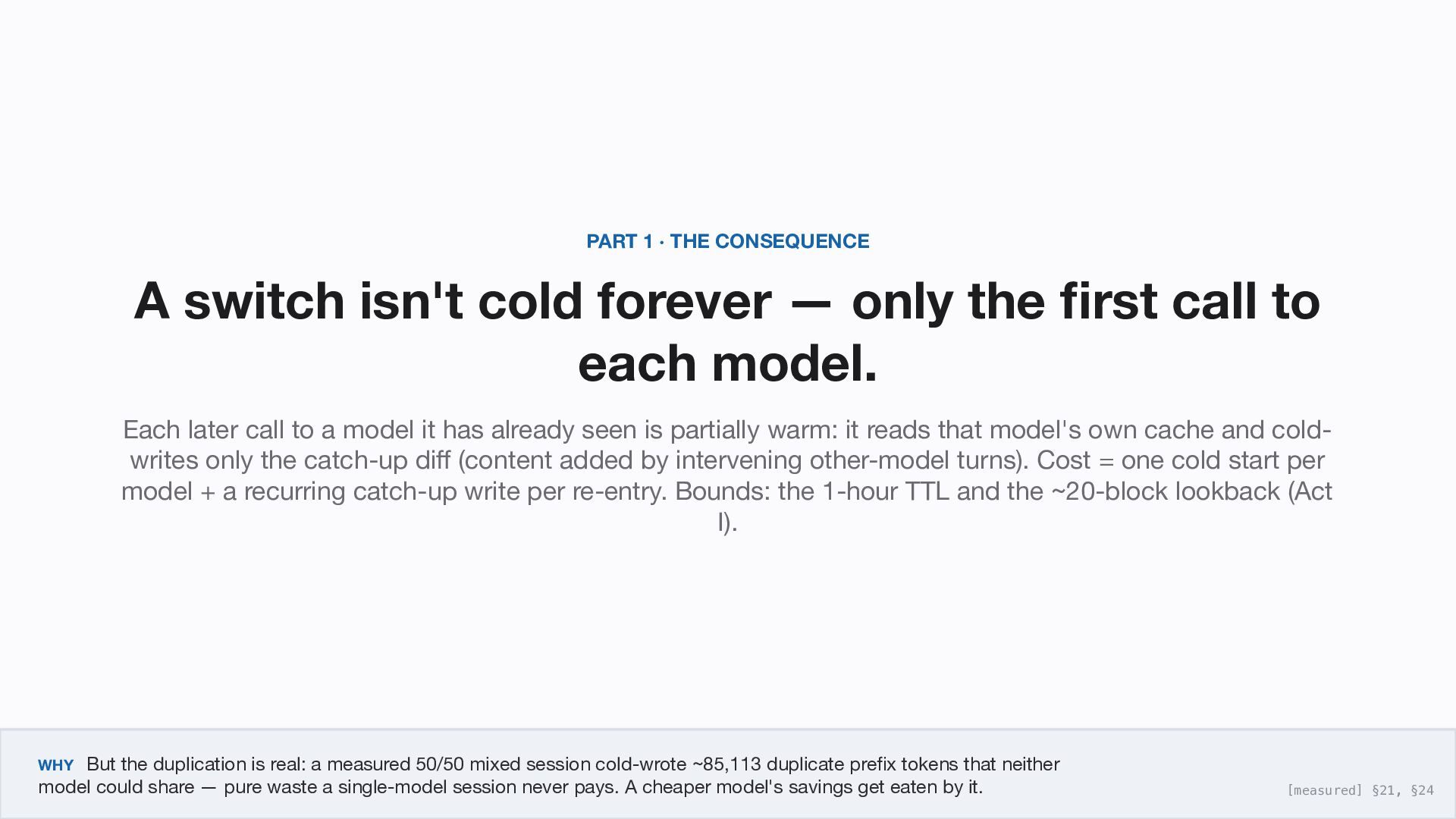
— only the first call to each model. Each later call to a model it has already seen is partially warm: it reads that model's own cache and cold- writes only the catch-up diff (content added by intervening other-model turns). Cost = one cold start per model + a recurring catch-up write per re-entry. Bounds: the 1-hour TTL and the ~20-block lookback (Act I). WHY But the duplication is real: a measured 50/50 mixed session cold-wrote ~85,113 duplicate prefix tokens that neither model could share — pure waste a single-model session never pays. A cheaper model's savings get eaten by it. [measured] §21, §24
system[2] · sonnet vs haiku · diffed 1 system[2] // the ~27K agent prompt — identical across models except two lines 2 …26,619 chars identical… 3 SONNET 4.6: 4 "You are powered by the model named Sonnet 4.6 … claude-sonnet-4-6." 5 "Assistant knowledge cutoff is August 2025." 6 HAIKU 4.5: 7 "You are powered by the model named Haiku 4.5 … claude-haiku-4-5." 8 "Assistant knowledge cutoff is February 2025." Sonnet's two lines — the model-id line and an Aug-2025 knowledge cutoff. Haiku's two lines — model id + a Feb-2025 cutoff (~11 months older). WHY Out of system[2]'s ~26,900 chars, exactly two lines differ by model. They sit inside the cached system span, so by prefix-match they'd re-key it — but that's moot: the model-scoped key (Part 1) already made the switch cold. Same wall, not a second cause. [capture] CC 2.1.150 · sonnet vs haiku
4.8 tokenizes some text 64,316 tokens HAIKU 4.5 tokenizes the SAME text 83,004 tokens vs Identical bytes, different token counts — each model has its own tokenizer, and the size of the gap depends on the pair. Opus 4.7/4.8 introduced a leaner tokenizer, so Opus Haiku is ~1.29× (29% more); but Sonnet 4.6 and Haiku 4.5 tokenize almost identically — live this → session the same project was 38,692 tokens on Sonnet vs 39,221 on Haiku (only ~1.4%). WHY Not a reason the cache can't carry — a separate cost effect that rides along with every switch. More tokens = more to write and read, on top of the cold start. The gap can be large or near-zero depending on the two models, and Anthropic publishes no ratio — so measure it with count_tokens per model. [measured] §23 · live confirm: sonnet 38,692 / haiku 39,221
immediately — given a hard prompt they first emit a run of intermediate tokens, working it out step by step, then write the reply. ▸ That working-out is the “thinking” (a.k.a. reasoning / chain of thought) — a scratch pad, like the “let me think…” pass a person makes before answering. ▸ It buys accuracy — spending tokens on reasoning measurably helps multi-step work (math, code, planning). It's test-time compute: trade tokens for a better answer. ▸ Adaptive thinking — the model decides per request whether and how hard to think: a trivial lookup gets none; a hard puzzle gets thousands of tokens. WHY Thinking is its own content block, emitted before the text answer — the wire keeps the model's private working-out separate from the words meant for you. That separate block is what a model switch has to make a decision about. [docs] primer
response · assistant content blocks · claude-sonnet-4-6 1 content[0]: thinking ◀ the reasoning, emitted FIRST 2 thinking: "The classic water-jug problem. Let me solve it…" (747 ch) 3 signature: "EsYICmUIDxgC … W7XUzxgYAQ==" (1,468 ch) 4 content[1]: text ◀ the answer the user sees 5 text: "**State notation:** (3L jug, 5L jug)…" (574 ch) 6 usage: output_tokens 754 (of which thinking_tokens 479) The thinking block comes first — the model's private working-out, a separate typed block before the answer. Billed as output (479 tok) — at generation, thinking is output. It becomes input on replay (Part 4). WHY A reasoning model emits its thinking as its own block, before the text answer. Sonnet's default display is summarized, so you get a 747-char summary plus a 1,468-char encrypted signature. At generation it's billed as output (479 of the 754 tokens). [capture] CC 2.1.150 · claude-sonnet-4-6
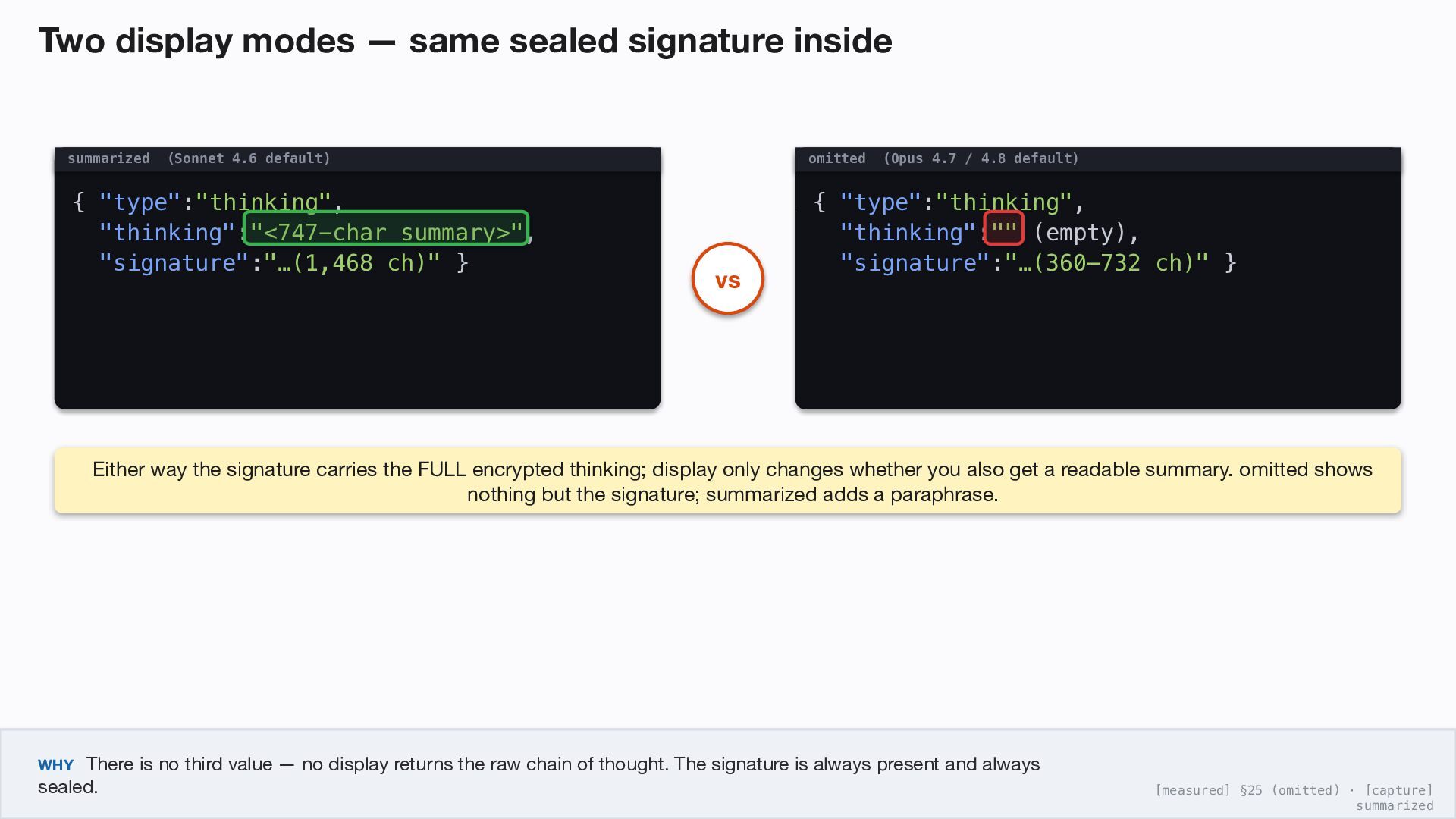
4.6 default) { "type":"thinking", "thinking":"<747-char summary>", "signature":"…(1,468 ch)" } omitted (Opus 4.7 / 4.8 default) { "type":"thinking", "thinking":"" (empty), "signature":"…(360–732 ch)" } vs Either way the signature carries the FULL encrypted thinking; display only changes whether you also get a readable summary. omitted shows nothing but the signature; summarized adds a paraphrase. WHY There is no third value — no display returns the raw chain of thought. The signature is always present and always sealed. [measured] §25 (omitted) · [capture] summarized
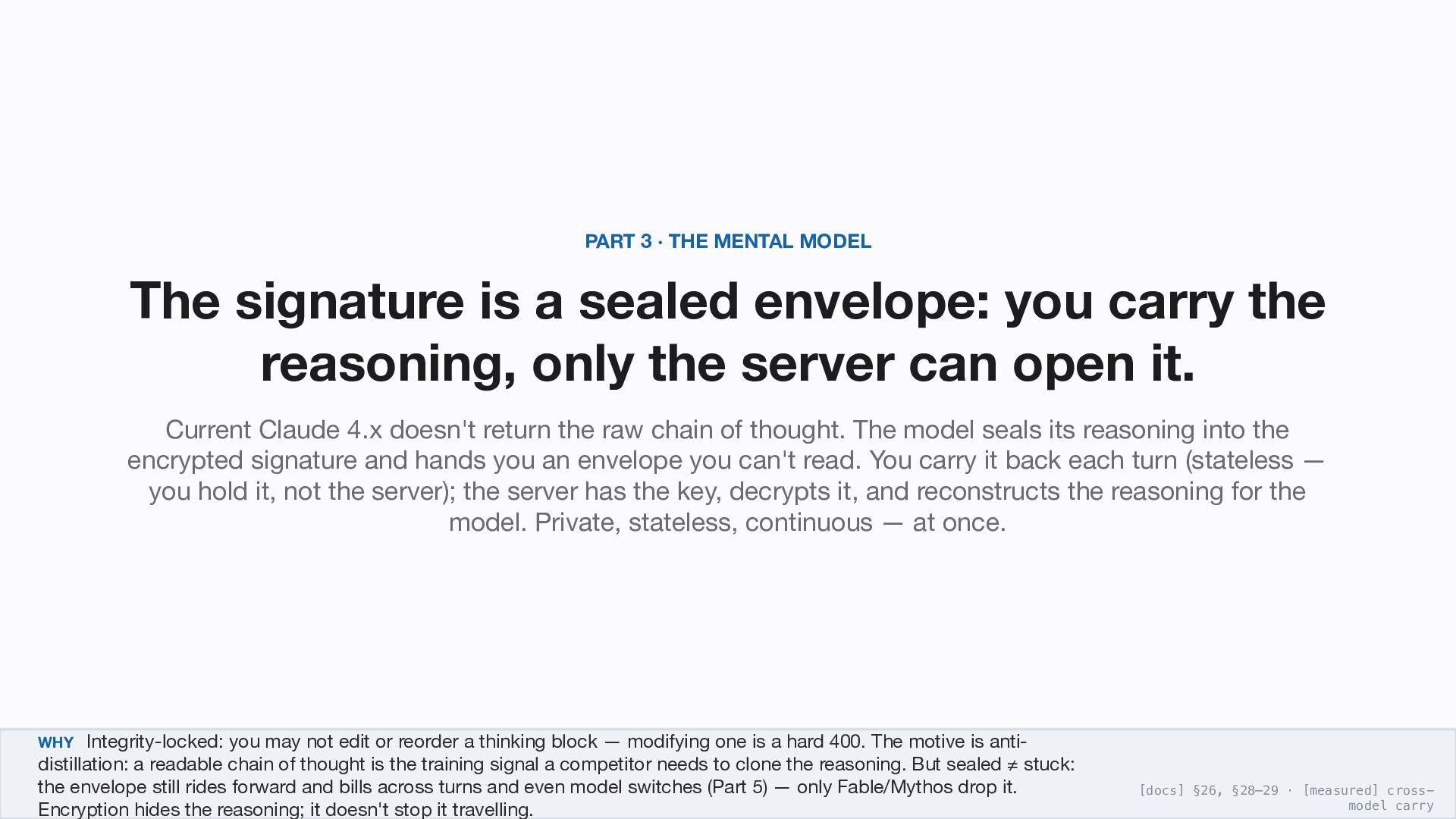
sealed envelope: you carry the reasoning, only the server can open it. Current Claude 4.x doesn't return the raw chain of thought. The model seals its reasoning into the encrypted signature and hands you an envelope you can't read. You carry it back each turn (stateless — you hold it, not the server); the server has the key, decrypts it, and reconstructs the reasoning for the model. Private, stateless, continuous — at once. WHY Integrity-locked: you may not edit or reorder a thinking block — modifying one is a hard 400. The motive is anti- distillation: a readable chain of thought is the training signal a competitor needs to clone the reasoning. But sealed ≠ stuck: the envelope still rides forward and bills across turns and even model switches (Part 5) — only Fable/Mythos drop it. Encryption hides the reasoning; it doesn't stop it travelling. [docs] §26, §28–29 · [measured] cross- model carry
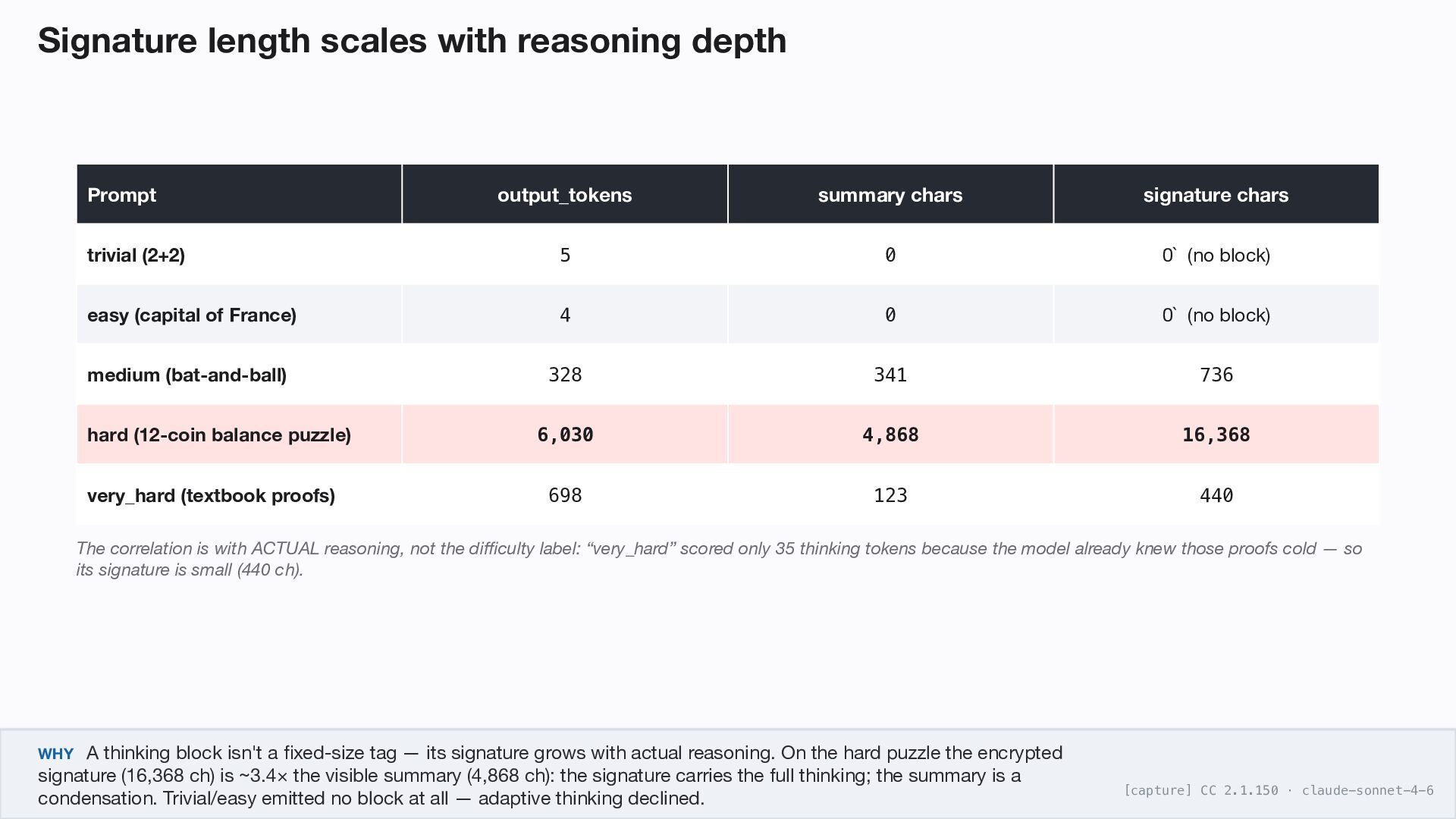
signature chars trivial (2+2) 5 0 0` (no block) easy (capital of France) 4 0 0` (no block) medium (bat-and-ball) 328 341 736 hard (12-coin balance puzzle) 6,030 4,868 16,368 very_hard (textbook proofs) 698 123 440 The correlation is with ACTUAL reasoning, not the difficulty label: “very_hard” scored only 35 thinking tokens because the model already knew those proofs cold — so its signature is small (440 ch). WHY A thinking block isn't a fixed-size tag — its signature grows with actual reasoning. On the hard puzzle the encrypted signature (16,368 ch) is ~3.4× the visible summary (4,868 ch): the signature carries the full thinking; the summary is a condensation. Trivial/easy emitted no block at all — adaptive thinking declined. [capture] CC 2.1.150 · claude-sonnet-4-6
AT GENERATION · turn 1 output_tokens: 754 thinking_tokens: 479 thinking counts as OUTPUT (5×) ON REPLAY · turn 2 cache_read: 30,157 warm prefix cache_creation: 779 catch-up + block the same block now counts as INPUT The thinking the model wrote (billed as output at generation) rides back next turn as input — part of the 779-token catch-up write, then read warm on later turns. display never changes this. WHY Thinking bills the same under omitted, summarized, or full — display is visibility-only. The only lever on the replay cost is whether the block is read warm (0.1×) or freshly written (2×). [capture] CC 2.1.150
display what you see default models summarized a separate model's paraphrase + the signature Opus 4.6, Sonnet 4.6, earlier 4.x omitted empty thinking text — the signature only Opus 4.7 / 4.8, Fable 5, Mythos 5 WHY Only two values exist, and neither returns the verbatim chain of thought. display is visibility-only: it changes what YOU see, not the billing and not the signature (which always carries the full encrypted thinking). [docs] §31–32
the protected form — not a workaround. Switching display to summarized doesn't bypass anything: the summary is a separate model's paraphrase, never seen by the reasoning model, and on the hard turn it was 4,868 chars while the sealed signature was 16,368 — the full thinking is materially larger than what you're allowed to see. No display value exposes the raw chain of thought. WHY The motive is anti-distillation: “summarized thinking provides the full intelligence benefits while preventing misuse.” The readable text became a carry-but-don't-inspect signature so a competitor can't harvest the reasoning to clone it. [docs] §29, §33
prior reasoning kept-and- billed, or dropped? Carrying thinking forward within one model is ordinary context. But a model switch forces a choice: the blocks are either re-rendered into the new model's prompt and billed as input (a cost), or stripped before they arrive (a behavioral change — the new model loses the chain of thought). The API never tells you which. WHY The test: send the same request twice — blocks kept vs. removed — and diff the prompt-token count. More tokens when kept rendered & billed; identical dropped. ⇒ ⇒ [measured] §34
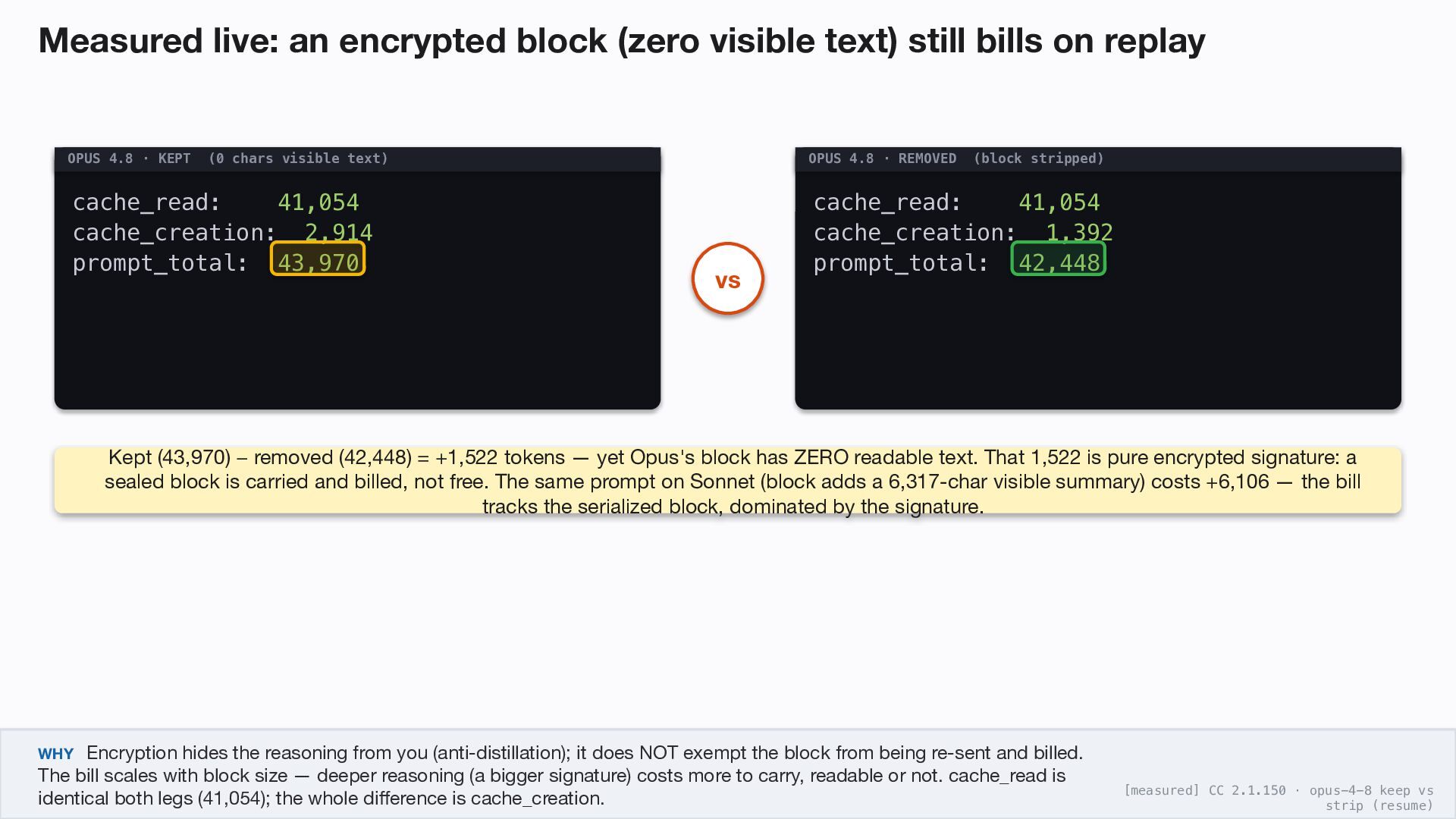
on replay OPUS 4.8 · KEPT (0 chars visible text) cache_read: 41,054 cache_creation: 2,914 prompt_total: 43,970 OPUS 4.8 · REMOVED (block stripped) cache_read: 41,054 cache_creation: 1,392 prompt_total: 42,448 vs Kept (43,970) − removed (42,448) = +1,522 tokens — yet Opus's block has ZERO readable text. That 1,522 is pure encrypted signature: a sealed block is carried and billed, not free. The same prompt on Sonnet (block adds a 6,317-char visible summary) costs +6,106 — the bill tracks the serialized block, dominated by the signature. WHY Encryption hides the reasoning from you (anti-distillation); it does NOT exempt the block from being re-sent and billed. The bill scales with block size — deeper reasoning (a bigger signature) costs more to carry, readable or not. cache_read is identical both legs (41,054); the whole difference is cache_creation. [measured] CC 2.1.150 · opus-4-8 keep vs strip (resume)
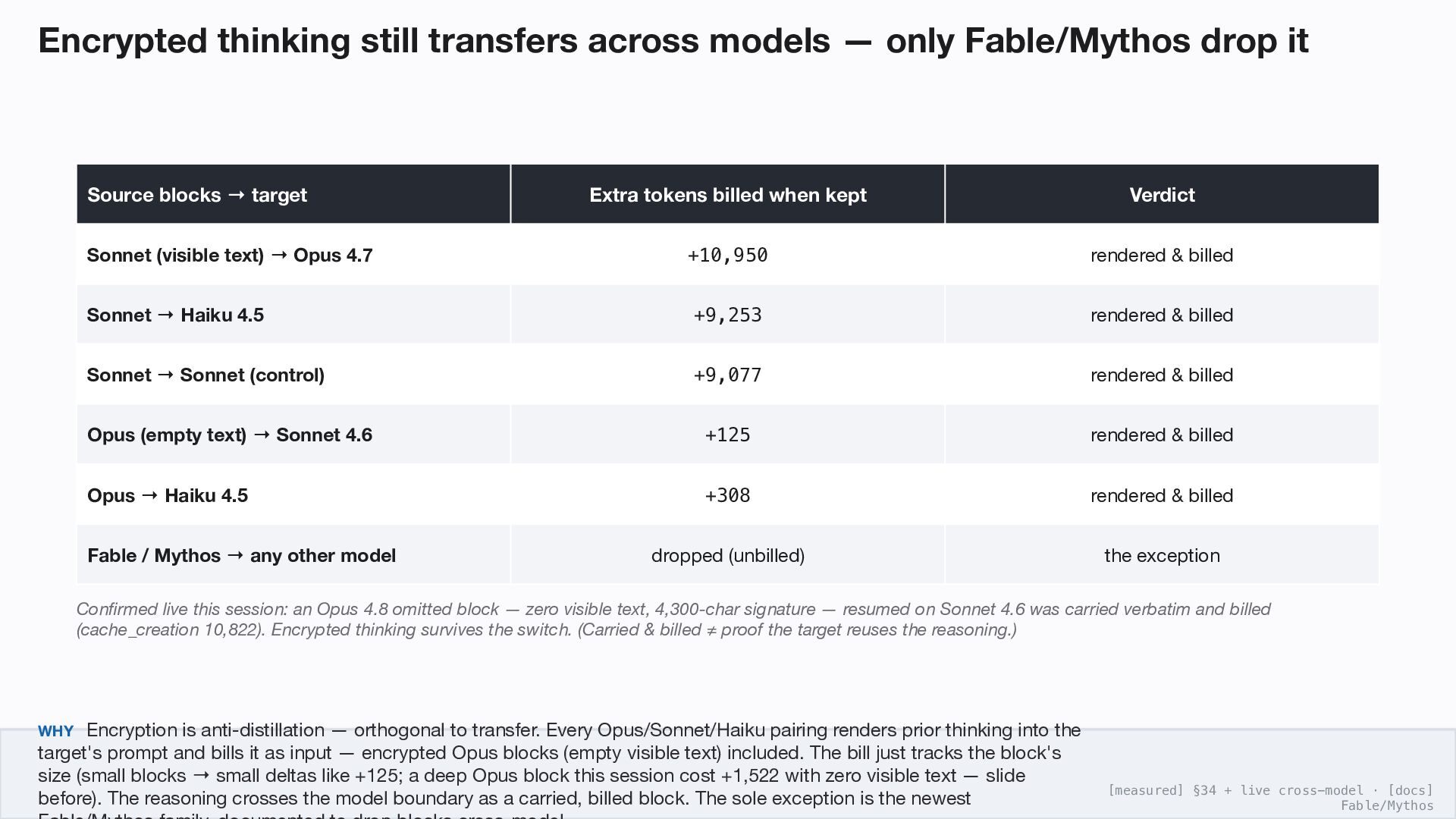
it Source blocks target → Extra tokens billed when kept Verdict Sonnet (visible text) Opus 4.7 → +10,950 rendered & billed Sonnet Haiku 4.5 → +9,253 rendered & billed Sonnet Sonnet (control) → +9,077 rendered & billed Opus (empty text) Sonnet 4.6 → +125 rendered & billed Opus Haiku 4.5 → +308 rendered & billed Fable / Mythos any other model → dropped (unbilled) the exception Confirmed live this session: an Opus 4.8 omitted block — zero visible text, 4,300-char signature — resumed on Sonnet 4.6 was carried verbatim and billed (cache_creation 10,822). Encrypted thinking survives the switch. (Carried & billed ≠ proof the target reuses the reasoning.) WHY Encryption is anti-distillation — orthogonal to transfer. Every Opus/Sonnet/Haiku pairing renders prior thinking into the target's prompt and bills it as input — encrypted Opus blocks (empty visible text) included. The bill just tracks the block's size (small blocks small deltas like +125; a deep Opus block this session cost +1,522 with zero visible text — slide → before). The reasoning crosses the model boundary as a carried, billed block. The sole exception is the newest [measured] §34 + live cross-model · [docs] Fable/Mythos
thinking; Haiku and older strip it. “On Opus 4.5+ and Sonnet 4.6+, previous thinking blocks are kept; on earlier Opus/Sonnet models and all Haiku models, all previous thinking blocks are ignored and stripped from context.” The trigger is a normal (non-tool-result) user turn. Inside tool loops, thinking is kept either way. WHY This is the DEFAULT API rule — and it seems to clash with the matrix (Haiku billed there). The catch: that matrix was measured with the blocks kept (the keep:“all” Claude Code always sends — Part 6). Without keep:“all” a strip-model like Haiku silently drops prior thinking: cheaper, but it loses the thread. [docs] §35
miss — model-scoped caches (Part 1): Sonnet cold-writes its whole prefix. ▸ Sonnet keeps and bills the thinking Haiku had been ignoring — reasoning that was “free” on Haiku now costs input tokens on Sonnet's cold write. ▸ Any prefix-leanness from Haiku's strip evaporates the moment Sonnet serves a turn. WHY A cheaper per-token model can still cost more end-to-end once you count the cold write plus the newly-billed thinking. The direction of the switch matters. [measured + inferred] §38
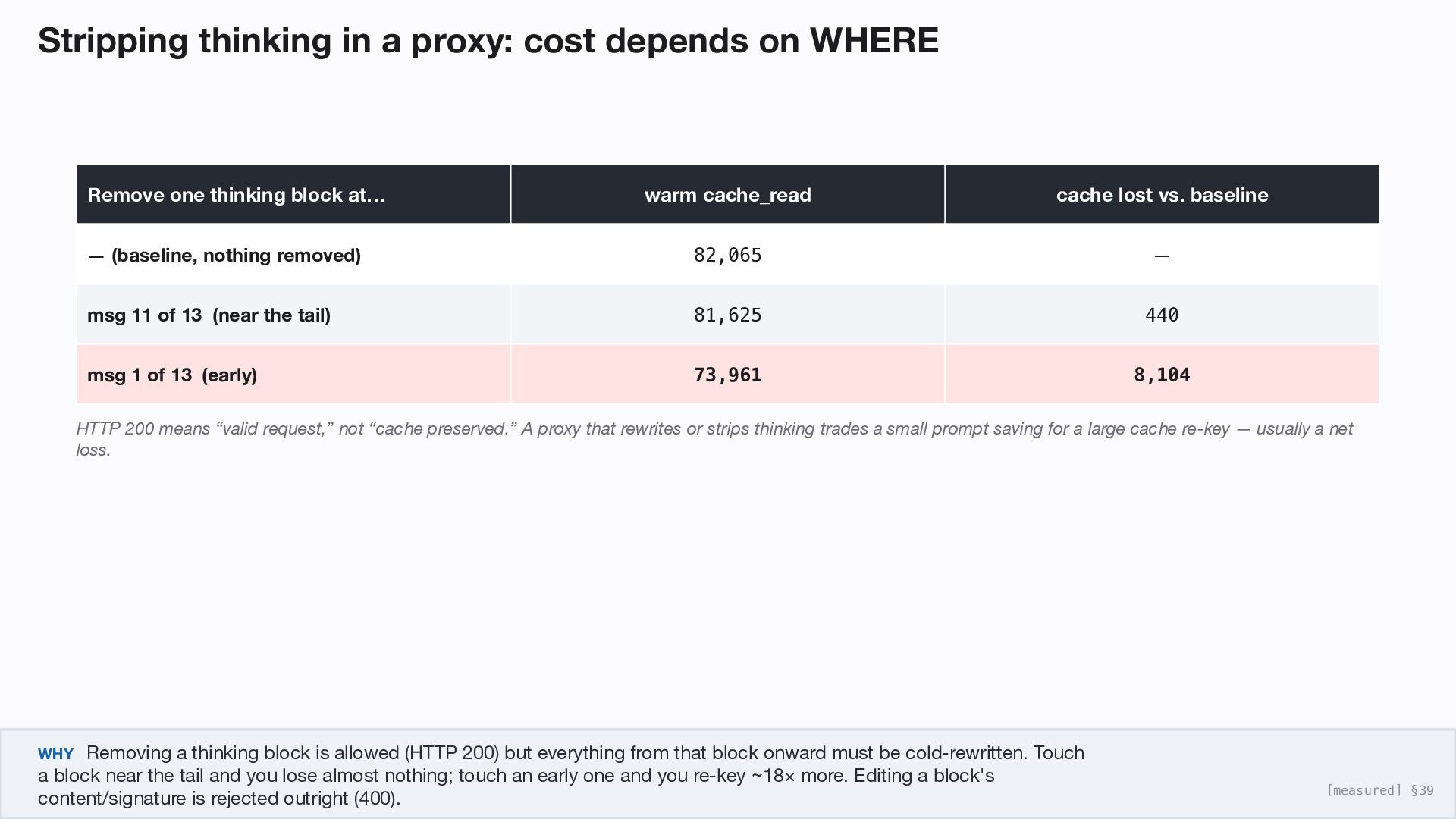
one thinking block at… warm cache_read cache lost vs. baseline — (baseline, nothing removed) 82,065 — msg 11 of 13 (near the tail) 81,625 440 msg 1 of 13 (early) 73,961 8,104 HTTP 200 means “valid request,” not “cache preserved.” A proxy that rewrites or strips thinking trades a small prompt saving for a large cache re-key — usually a net loss. WHY Removing a thinking block is allowed (HTTP 200) but everything from that block onward must be cold-rewritten. Touch a block near the tail and you lose almost nothing; touch an early one and you re-key ~18× more. Editing a block's content/signature is rejected outright (400). [measured] §39
POST /v1/messages · captured on both turns 1 "thinking": { "type":"adaptive" }, 2 "context_management": { 3 "edits": [ { 4 "type":"clear_thinking_20251015", 5 "keep":"all" ◀ overrides the default strip 6 } ] 7 } keep: “all” — Claude Code sends this on every turn, so the default Haiku strip never fires: every model keeps thinking. WHY Claude Code always sends context_management with keep:“all”. That overrides Haiku's default strip and forces retention — so inside real Claude Code every model keeps (and bills) prior thinking. The default-strip path appears only in raw API usage that omits this field. [capture] CC 2.1.150 · present on both turns
⚠ A complexity router (or a sub-agent on a cheaper tier) looks cheaper per token — but each switch cold-writes the whole prefix at 2× on the new model AND, because Claude Code keeps thinking on every model, bills all the replayed reasoning as fresh input. The per-token discount is eaten by cache duplication. FIX ✓ Keep a session on one model; switch only at natural boundaries where the prefix is small. If you must route, weigh the cold write + replay-bill against the per-token savings — it rarely pays for short detours. WHY Measured: a 50/50 mixed session cold-wrote ~85,113 duplicate prefix tokens neither model could share — pure waste a single-model session never pays. [measured] §21, §38
cache is model-scoped: switch the model and you pay a full cold write — identical bytes don't help. ✓ Thinking is a sealed envelope: the model's reasoning rides in an encrypted signature you carry but can't open, edit, or reorder. ✓ A switch replays-and-bills that reasoning: across Opus/Sonnet/Haiku the prior thinking — even an encrypted, zero-text block — is rendered into the new prompt and billed; only the Fable/Mythos family drops it. (Haiku strips by default, but Claude Code's keep:“all” makes every model keep it.) Switch = cold write + replay-bill. Treat a model change as a cost event, not a free knob.
Default to one model per session; let the prefix stay warm. ✓ Before adding a router or cheaper-tier sub-agent, price the cold write + thinking replay — not just the per-token rate. ✓ Don't hand-edit or strip thinking blocks in a proxy — edits 400, removals re-key from that block onward (HTTP 200 ≠ cache preserved). ✓ Remember display is cosmetic: summarized vs. omitted changes what you see, never the bill. Next — Act III: the cost-reduction ecosystem (Headroom, Caveman, routers) and what routing actually costs inside Claude Code.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}