Presented at Percona Live, April 4, 2014
Fast failover is not just an option for building reliable systems in the cloud - it is a requirement. Unfortunately, it seems like every storage solution out there (whether it's SQL or NoSQL) has its own proprietary monitoring and failover mechanism. In this presentation, we explore Zookeeper as a mechanism for fast, application-driven failover for both MySQL and Redis in the cloud. By using Zookeeper and client-level integration, we can avoid the "magic" of network-level failover (such as elastic IPs) as well as the latency and complexity of proxy-level solutions. We demonstrate that Zookeeper is a practical cross-platform strategy from any language, with examples of failover in Ruby, Java, and Node.js applications.
{kind=link}
{kind=link}
{kind=link}
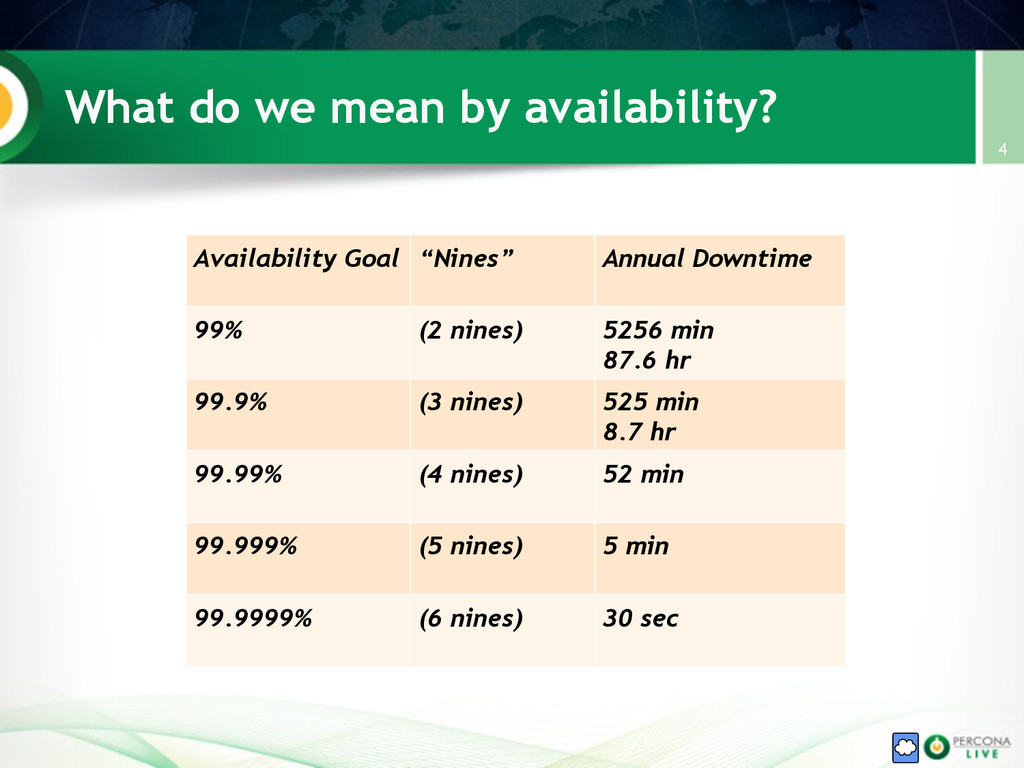{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
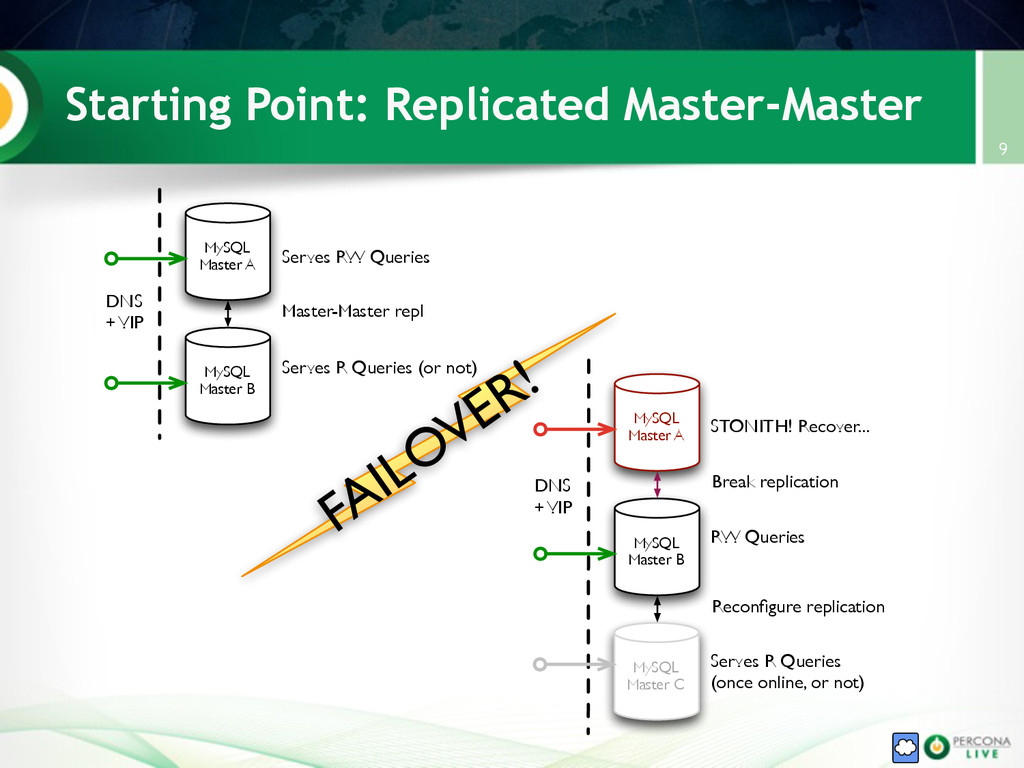{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
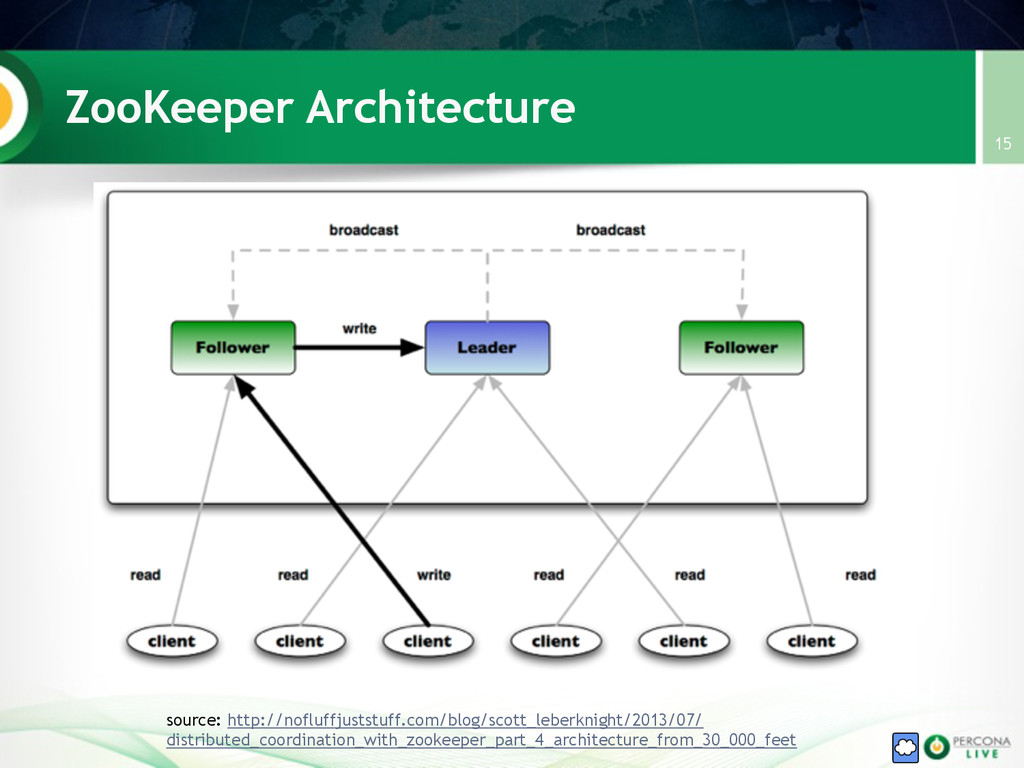{kind=link}
{kind=link}
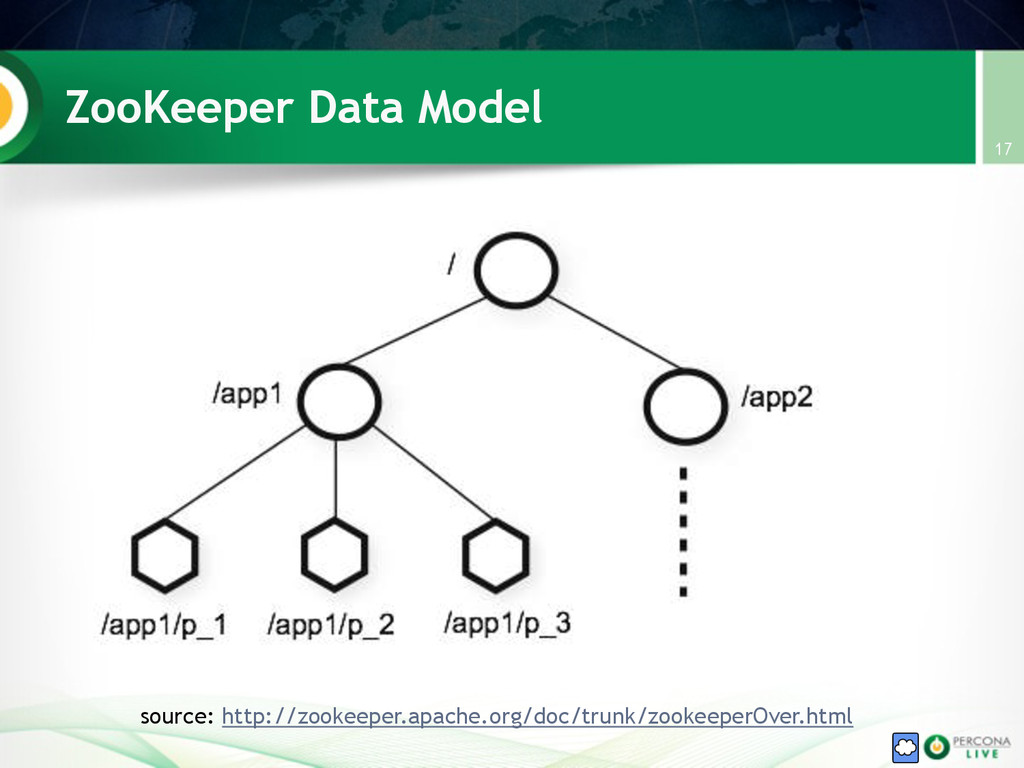{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}