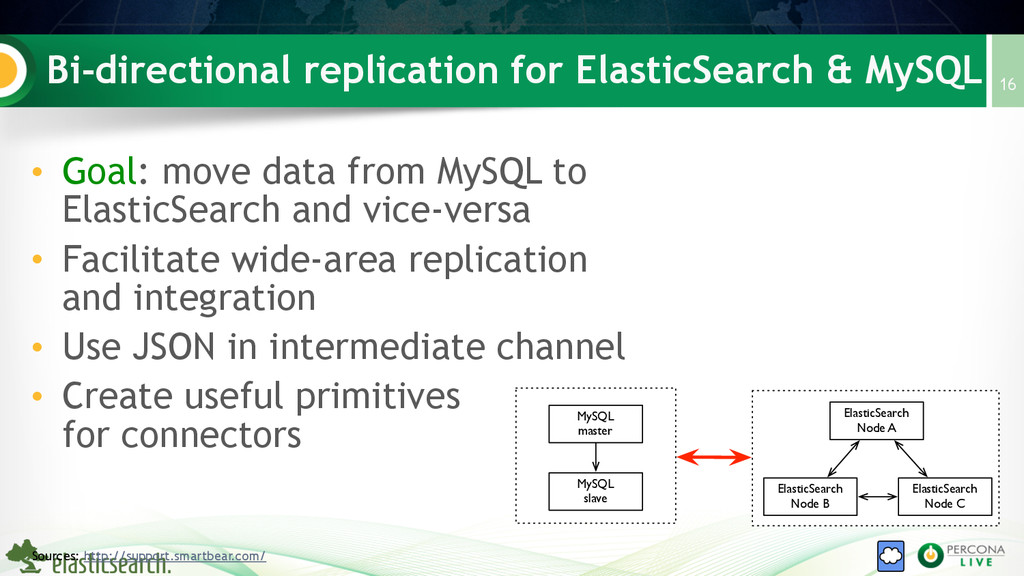
ElasticSearch is the premier solution for full-text search of structured documents in the cloud. But we all know that MySQL is everybody's favorite database, whose durability and performance in the field is battle-tested and well-understood. In this presentation, we review common cases for bidirectional integration of ElasticSearch and MySQL, and look at techniques that enable developers to use ElasticSearch and MySQL more efficiently together. We'll look inside a MySQL "River" (ElasticSearch indexing plugin) for ElasticSearch that allows binlog updates to propagate to ElasticSearch in real time, as well as an ElasticSearch plugin that allows ElasticSearch document updates to be applied to MySQL tables in real time. We'll pay special attention to the features and characteristics that make ElasticSearch and MySQL great in their own way, and why they will both have a place in your "cloud stack" for years to come.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}