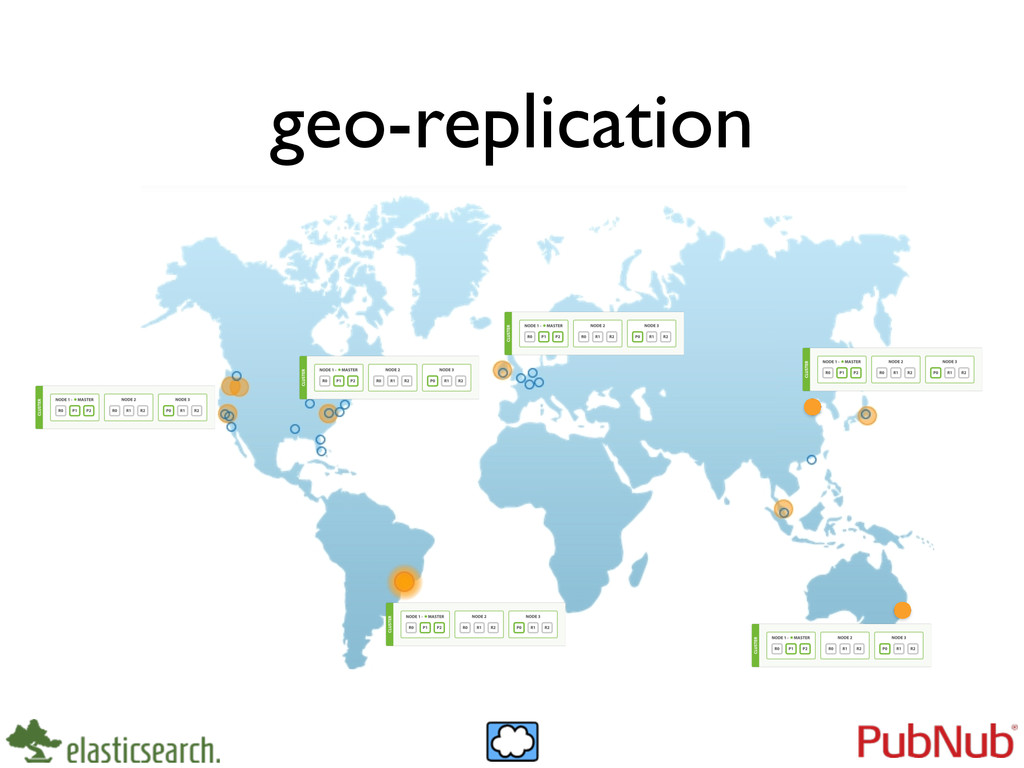
ElasticSearch is a phenomenal data store -- its easy approach to scalability using symmetric nodes has dramatically improved the way we operate scalable persistence services. With this huge success, we find that some challenges still remain -- especially in operating ElasticSearch across geographically distant clusters for fault-tolerance and disaster recovery. In this talk, I'd like to share a set of new, open source ElasticSearch plugins I'm building that use the PubNub fault-tolerant global data stream network as a medium for cross-cluster document replication and indexing. This includes a storage event listener for document change propagation and a new ElasticSearch River for indexing. I'd love to get feedback on these use cases and plugin design and implementation and also hear about some of the geo-replication challenges other folks might be facing. I'll have the code up on GitHub with a HOWTO and a downloadable demo bundle that folks can try if they'd like to follow along during the presentation.
Presenter: Sunny Gleason is founder and Cloud Guy at SunnyCloud, a company that provides Cloud, Web &Mobile application development, hosting and operations to businesses in the cloud. He specializes in real-time protocols and scalable persistence solutions. Before all that, Sunny was a Platform Engineer developing Cloud Computing solutions at Ning andAmazon.com.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}